 基于视觉的手势识别系统的设计与研究
基于视觉的手势识别系统的设计与研究
手语识别的目的就是通过计算机提供一种有效的、准确的机制将聋哑人常用的手语手势识别出来,使得他们与健全人之间的交互变得更方便、快捷。同时,手语识别的应用还可以提供更自然的人机交互方式,方便聋哑人对计算机等常用信息设备的使用。目前手语识别可以分为基于视觉(图像)的识别系统和基于数据手套(佩戴式设备)的识别系统。基于视觉的手势识别系统采用常见的视频采集设备作为手势感知输入设备,价格便宜、便于安装。鉴于基于视觉的手势识别方法交互自然便利,适于普及应用,且更能反映机器模拟人类视觉的功能,所以目前是手势识别的研究重点。
手语识别的研究开始于1982年,Shantz和Poizner实现了一个合成美国手语的计算机程序。之后,中国、美国、日本、德国等许多国家都进行了自己国家的手语识别与合成研究,并取得了许多重要的研究成果。Triesch和Malsburg开发了一种弹性图模板匹配技术对复杂背景下的手形进行分类,在相对复杂的背景下的识别率达到86.2%。Davis和Shah将戴上指间具有高亮标记的视觉手套的手势作为系统的输入,可识别7种手势。Starner等在对美国手语中带有词性的40个词汇随机组成的短句子识别率达到99.2%。Yang等人采用7Hu不变矩特征量进行手语字母识别,最好识别率为90%。
本文采用SVMs (Support Vector Machines,支持向量机)作为手语识别的分类器,提出了一种基于视觉的手语字母识别方法。SVMs在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。采用SVMs作为图像分类器首先要解决的问题是:如何用典型视觉特征来表征图像的不同视觉特性。
在图像特征提取方面,为了能够同时表征图像的全局特性和局部特性,需要同时提取图像的全局特征和局部特征,并且这些特征中用以描述图像整体形状的特征应当具备平移、旋转和尺度不变性。SIFT(Scale Invariant Feature Transform)是一种对尺度空间、图像缩放、旋转甚至仿射不变的图像局部特征描述算子;而7Hu不变矩特征量具有平移、旋转和尺度不变性的特点,具有很好的稳定性,适合描述目标整体形状。
手语简介
手语是一种聋人使用的语言,是一种靠动作/视觉交际的特殊语言。中国手语包括30个手指字母,大约5500个基本手势词。手指语是从字母语言发展起来的,是汉语手语的一种,用一个指式代表一个汉语拼音字母,按照汉语拼音方案拼成普通话。而手势语则是由象形语言发展起来的。它充分利用人的手势、表情和身体动作形象地表达物体和行动的最基本特征。
中国文字改革委员会、教育部等单位于1963年联合公布实施汉语手指字母方案。方案中包括汉语拼音中26个单字母(A~ Z)和4个双字母(ZH、CH、SH、NG)如图1所示。
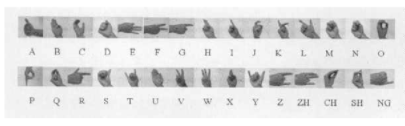
图1 中国手语字母表
SVMs
SVMs的主要思想是建立一个超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化。对于二维线性可分情况,令 H为把两类训练样本没有错误地分开的分类线,H1,H2分别为过各类中离分类线最近的样本且平行于分类线的直线,它们之间的距离叫做分类间隔。所谓最优分类线就是要求分类线不但能将两类正确分开,而且使分类间隔最大。在高维空间,最优分类线就成为最优分类面[8,9]。
设线性可分样本集为(xi,yi)),i=1,2,…,n,x∈Rd,即x是d维特征向量,y∈{+1,-1}是类别标号,d维空间线性判断函数的一般形式为g(x)=w×x+b,分类面方程为:w×x+b=0 (1)
式中w为权向量,b为分类阈值。要求分类面对所有样本正确分类,就是要求它满足:
Yi[w×xi+b]-1≥0,i=1,2,…,n (2)
满足上述条件且使||w||2最小的分类面就叫做最优分类面, H1,H2上的训练样本点,也就是使式(2)中等号成立的样本点,称作支持向量。解这个最优化问题后得到的最优分类函数是:
![]()
在学习样本是线性不可分,但却是非线性可分的情况下,可以通过非线性变换把学习样本变换到高维空间,使其在高维空间里是线性可分的。用核函数 K(x,y)代替原来的点积(x·y),Mercer定理指出,核函数 K(x,y)通过与其相联系的非线性变换Φ隐含地把特征向量映射到高维特征空间,使得学习样本成为线性可分的。常用的核函数有:

图像特征选取
手语图像特征的选取,会直接影响到识别的效果,因此在表示图像的不同视觉特征时本文同时提取全局视觉特征和局部视觉特征。为了避免图像分割工具可能带来的问题,在特征提取时不进行图像分割。在研究中,将提取图像的以下特征:(1)7维不变矩特征量,作为图像整体形状描述的特征向量(2)用Gabor小波提取48维的纹理特征,以表示图像的整体结构属性[10];(3)提取一定数量的兴趣点及它们的SIFT特征[11],以表示图像的局部结构特征与所包含目标的大致形状。实验表明,全局和局部视觉特征可以有效的表示出图像的主要视觉特征。
Hu不变矩特征量
利用矩不变量进行形体识别是模式识别中的一种重要的方法, Hu在1961年首先提出了矩不变量的概念。Hu首先提出代数不变矩的概念,并给出了一组基于通用矩组合的代数矩不变量。这些矩具有平移、尺度和旋转不变性,被称为Hu’s矩。
对于连续灰度函数 f(x, y),它的(p + q)阶二维原点矩Mpq 的定义为:
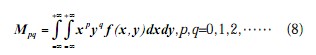
假设 f(x, y)为分段连续的有界函数,并且在x,y平面上有限区域内有非零值。根据唯一性定理,它的各阶矩存在且唯一地被 f(x, y)确定,反过来,f(x, y)也唯一地被它的各阶矩确定。
此外,还可以定义 f(x, y)的(p + q)阶中心矩μpq 为:
![]()
Hu首先提出了不变矩,他给出了连续函数矩的定义和关于矩的基本性质,证明了有关矩的平移不变性、旋转不变性以及比例不变性等性质,具体给出了具有平移不变性、旋转不变性和比例不变性的七个不变矩的表达式。
七个不变矩由二阶和三阶中心矩的线性组合构成,具体表达式如下:

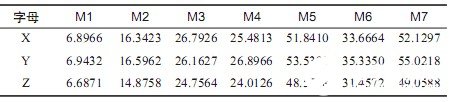
实验中,使用了全部的7Hu不变矩特征量作为手语图像整体形状描述的特征向量。形成特征空间(M1, M2, M3, M4, M5, M6, M7),如表1所示。
表1手语字母X,Y,Z的7Hu矩分量
SIFT特征
David G.Lowe在2004年总结了现有的基于不变量技术的特征检测方法,并正式提出了一种基于尺度空间的、对图像缩放、旋转甚至仿射变换保持不变性的图像局部特征描述算子-SIFT算子[6,11],即尺度不变特征变换。
SIFT算法首先在尺度空间进行特征检测,并确定关键点(Keypoints)的位置和关键点所处的尺度,然后使用关键点邻域梯度的主方向作为该点的方向特征,以实现算子对尺度和方向的无关性。
Lowe在图像二维平面空间和DoG(Difference of Gaussian)尺度空间中同时检测局部极值以作为特征点,以使特征具备良好的独特性和稳定性。DoG算子定义为两个不同尺度的高斯核的差分,其具有计算简单的特点,是归一化LoG (Laplacian of Gaussian)算子的近似。DoG算子如下式所示:
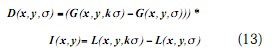
对于图像上的点,计算其在每一尺度下DoG算子的响应值,这些值连起来得到特征尺度轨迹曲线。特征尺度曲线的局部极值点即为该特征的尺度。尺度轨迹曲线上完全可能存在多个局部极值点,这时可认为该点有多个特征尺度。
一幅图像SIFT特征向量的生成算法总共包括4步:
(1)尺度空间极值检测,初步确定关键点位置和所在尺度。
(2)通过拟和三维二次函数以精确确定关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力[6,11]。
(3)利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性。
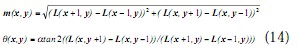
式(14)为(x,y)处梯度的模值和方向公式。其中L所用的尺度为每个关键点各自所在的尺度。
(4)生成SIFT特征向量。 首先将坐标轴旋转为关键点的方向,以确保旋转不变性。接下来以关键点为中心取8×8的窗口。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点。手语字母图像的SIFT特征提取如图2所示。
图2 (a)手语字母J原图 (b)对(a)提取SIFT特征向量
实验
本文从视频中采集了中国手语字母表中的30个手语字母的图像,30组,每组图像195幅,共5850幅图像作为实验图像。每组的前50幅作为正例训练样本,从其他29组中各选取5幅共145幅作为反例训练样本。每类图像除选作正例的50图像外,剩余的145幅作为测试图像。实验中首先提取图像的7维不变矩特征量,48维Gabor纹理特征,128维SIFT特征作为图像全局和局部特征描述。然后分别采用两种不同核函数(Linear kernel, Radical Basis Function)的SVMs分类器进行训练,对中国手语字母表中的30个手语字母图像的识别结果如表2所示。
表2 30个中国手语字母的识别结果
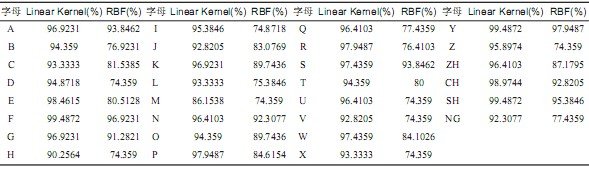
基于线性核函数的SVM平均识别率为95.556%,基于径向基核函数的SVM平均识别率为83.1282%。实验表明,采用径向基核函数的SVM识别率普遍低于采用线性核函数的SVM。
结语
本文提出了一种采用7Hu不变矩特征量等多种图像特征相融合的SVMs手语识别方法。实验表明,在手语识别中,采用图像全局和局部特征相结合的方法,可获得较高的识别率,为手语识别方法的早日推广应用提供了理论依据。
责任编辑:gt
-
计算机
+关注
关注
19文章
7488浏览量
87846 -
机器
+关注
关注
0文章
780浏览量
40710
发布评论请先 登录
相关推荐
车辆牌照识别系统的原理及算法研究
FPGA和Nios_软核的语音识别系统的研究
【UT4418申请】手势识别系统
基于BP神经网络的手势识别系统
嵌入式系统实时交互的手势识别方法是什么?
【创龙TLZ7x-EasyEVM评估板试用连载】基于ZYNQ的动态手势识别系统
介绍一个基于单片机的手势识别系统
基于MATLAB的车牌识别系统的研究
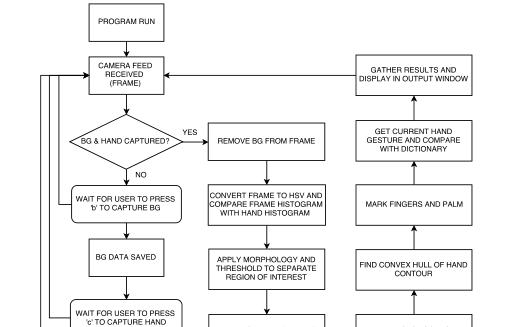
史上最牛高速手势识别系统解决方案
手势识别系统的程序和资料说明





 工商网监
工商网监
评论