 如何在多模态的语境中利用Transformer强大的表达能力?
如何在多模态的语境中利用Transformer强大的表达能力?
曾几何时,多模态预训练已经不是一个新的话题,各大顶会诸多论文仿佛搭上Visual和BERT,就能成功paper+=1,VisualBERT、ViLBERT层出不穷,傻傻分不清楚。..。..这些年NLPer在跨界上忙活的不亦乐乎,提取视觉特征后和文本词向量一同输入到万能的Transformer中,加大力度预训练,总有意想不到的SOTA。
如何在多模态的语境中更细致准确地利用Transformer强大的表达能力呢?Facebook最新的 Transformer is All You Need 也许可以给你答案。
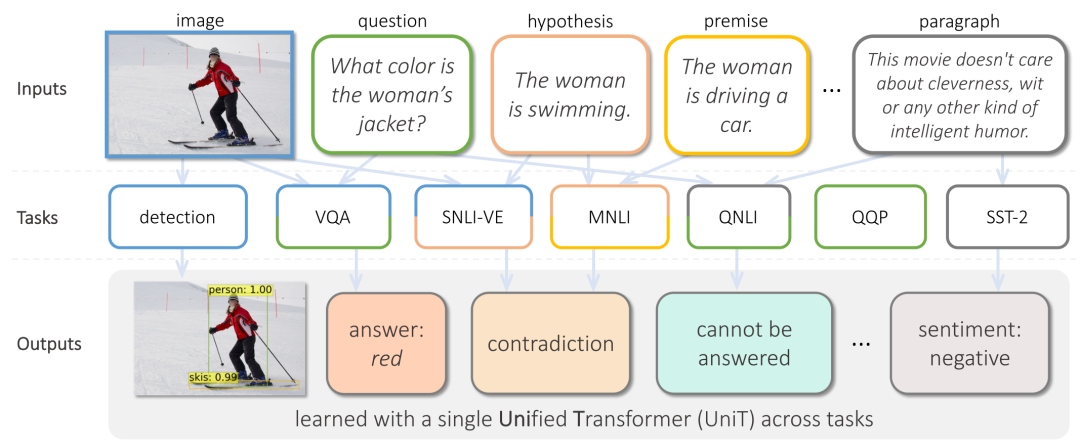
这篇貌似标题党的文章开宗明义,针对文本+视觉的多模态任务,用好Transformer就够了,与许多前作不同,这次提出的模型一个模型可以解决多个任务:目标检测、自然语言理解、视觉问答,各个模型板块各司其职、条理清晰:视觉编码器、文本编码器、特征融合解码器,都是建立在多层Transformer之上,最后添加为每个任务设计的处理器,通过多任务训练,一举刷新了多个任务的榜单。
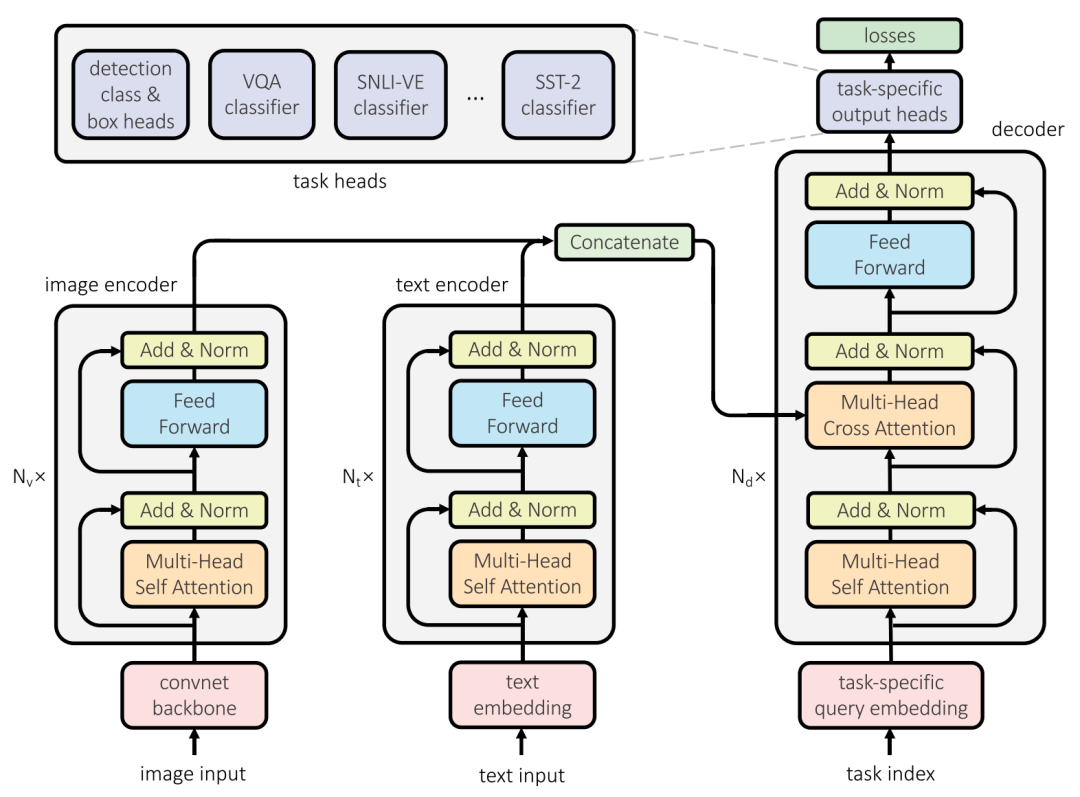
文本编码器用Transformer提取文本特征是个老生常谈的问题,从BERT石破天惊开始,纯文本领域近乎已被Transformer蚕食殆尽,所以该文也不能免俗,直接借用BERT的结构提取文本内容,区别在于,为了解决多个任务,在文本序列前添加了一个针对不同任务的参数向量,在最后输出隐藏状态到解码器时再去掉。
视觉编码器本文将Transformer强大的表达能力运用到视觉特征的提取中,由于图片像素点数量巨大,首先通过基于卷积神经网络的ResNet-50提取卷积特征,极大程度上地降低了特征数量,最终得到的feature map大小为,然后用全联接层调整单个特征的维度到,再利用多层Transformer中的注意力机制提取各个feature之间的关系,由于Transformer的输入是序列,文章将拉成一条长为的序列,另外和文本编码器类似,同样添加了与下游任务相关的。
其中是调整维度的全联接层,是多层Transformer编码器。
模态融合解码器多模态的关键之一就在于怎么同时利用多个模态,在本文中是通过Transformer的解码器实现的,这个解码器首先将任务相关的query做self-attention,再将结果与文本编码器和视觉编码器的结果做cross-attention,针对单一模态的任务,选取对应编码器的输出即可,针对多模态的任务,取两个编码器输出的拼接。
任务处理器(task-specific output head)之前多模态预训练模型往往只针对某一项任务,而本文提出的一个模型可以解决多个文本+视觉任务,与BERT可以解决多个文本任务类似,本文的模型在模态融合解码器的结果上添加为每个任务设计的处理器,这个处理器相对简单,用于从隐藏状态中提取出与特定任务相匹配的特征。
目标检测:添加box_head和class_head两个前馈神经网络从最后一层隐藏状态中提取特征用来确定目标位置和预测目标类型。
自然语言理解、视觉问答:通过基于全联接层的分类模型实现,将模态融合解码器结果的第一位隐藏状态输入到两层全联接层并以GeLU作为激活函数,最后计算交叉熵损失。
实验与总结本文提出的多模态预训练模型各个板块划分明确,通过多层Transformer分别提取特征,再利用解码器机制融合特征并完成下游任务,同时借助最后一层任务相关的处理器,可以通过一个模型解决多个任务,同时也让多任务预训练成为可能,并在实验中的各个数据集上得到了论文主要进行了两部分实验:
多任务学习:
这里的多任务涉及目标检测和视觉问答两个任务,在目标检测上运用COCO和VG两个数据集,在视觉问答上运用VQAv2数据集。对比了单一任务和多任务同时训练的结果,同时对比了不同任务共用解码器的结果。
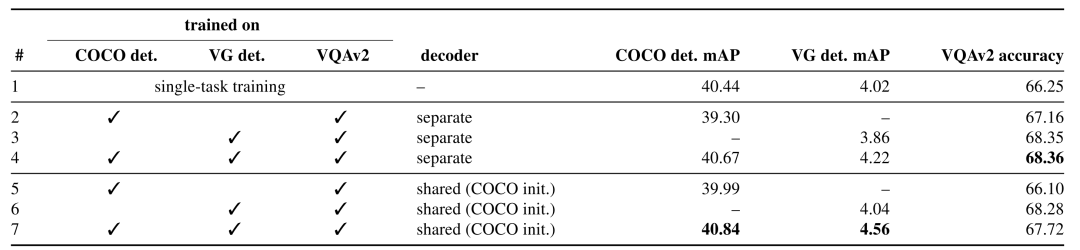
从结果中我们可以看出,单纯的使用多任务训练并不一定可以提高结果,不同任务间虽然相关但是却不完全相同,这可能是任务本身差异或者数据集的特性所导致,第二行和第五行可以很明显地看出COCO上的目标检测和VQAv2的视觉问答相结合后,结果有显著的下降,然而VG上的目标检测却能够和视觉问答很好地结合,通过三个数据集上的共同训练,可以得到最高的结果。
多模态学习:
这一实验中,为了体现所提出模型能够有效解决多个多种模态的不同任务,论文作者在之前COCO、VG、VQAv2的基础上,增加了单一文本任务GLUE的几个数据集(QNLI、QQP、MNLI、SST-2)和视觉推断数据集SNLI-VE,从数据集的数量上可以看出本文模型的全能性。与本文对比的有纯文本的BERT、基于Transformer的视觉模型DETR、多模态预训练模型VisualBERT。
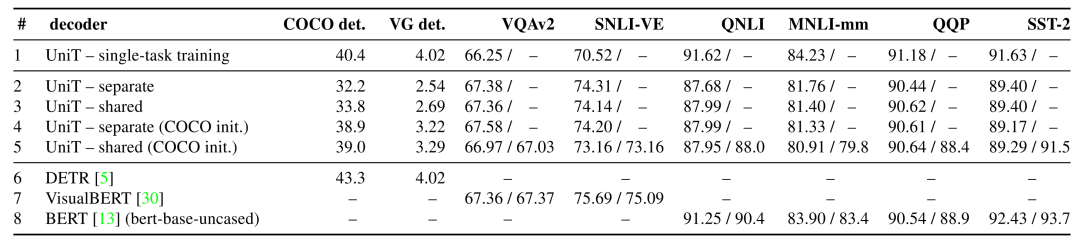
仔细看各个数据集上的结果,不难看出本文提出的模型其实并不能在所有数据集多上刷出SOTA,比如COCO上逊色于DETR,SNLI-VE逊色于VisualBERT,SST-2逊色于BERT,其他数据集上都有一定的提高,但是模型却胜在一个“全”字,模型的结构十分清晰明了,各个板块的作用十分明确,同时针对不同任务的处理器也对后续多模态任务富有启发性。
原文标题:【Transformer】没有什么多模态任务是一层Transformer解决不了的!
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
编码器
+关注
关注
45文章
3638浏览量
134417 -
Transforme
+关注
关注
0文章
12浏览量
8787 -
多模
+关注
关注
1文章
28浏览量
10850
原文标题:【Transformer】没有什么多模态任务是一层Transformer解决不了的!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
商汤日日新多模态大模型权威评测第一
使用ReMEmbR实现机器人推理与行动能力
未来AI大模型的发展趋势
利用OpenVINO部署Qwen2多模态模型
云知声山海多模态大模型UniGPT-mMed登顶MMMU测评榜首

【《大语言模型应用指南》阅读体验】+ 基础知识学习
科普讲座 | 让AIGC提高你的专业表达和创作能力

智源研究院揭晓大模型测评结果,豆包与百川智能大模型表现优异
阿里云通义大模型助力“小爱同学”强化多模态AI生成能力
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo
李未可科技正式推出WAKE-AI多模态AI大模型

基于Transformer的多模态BEV融合方案
什么是多模态?多模态的难题是什么?

自动驾驶和多模态大语言模型的发展历程

从Google多模态大模型看后续大模型应该具备哪些能力





 工商网监
工商网监
评论