 基于人工智能的自监督学习详解
基于人工智能的自监督学习详解
自监督学习让 AI 系统能够从很少的数据中学习知识,这样才能识别和理解世界上更微妙、更不常见的表示形式。
近年来,AI 产业在开发“可以从大量经过细致标记的数据中学习的 AI 系统”这个研究领域上取得了巨大进步。这种监督学习的范式在训练专业模型方面有着非常好的成绩,这类模型在完成它们针对训练的任务时表现颇为出色。不幸的是,只靠监督学习,人工智能领域的前景是有局限的。
监督学习是构建更智能的通用模型道路上面临的一个瓶颈。这种通用模型可以无需大量标记数据就执行多种任务并获得新技能。实际上,想要标记世界上的所有事物是不可能做到的。还有一些任务根本没有足够的标记数据,例如针对一些资源匮乏的语言的翻译系统。如果 AI 系统能够超越训练数据集所指定内容的范畴,对现实做出更深入、更细致的理解,那么它们就会有更多用途,并最终发展出更接近人类的 AI 智能。
在婴儿时期,我们主要通过观察来了解世界是如何运转的。我们学习诸如事物恒久性和重力之类的概念,从而形成了关于世界中各种事物的通用预测模型。随着我们成长,我们开始观察世界,对其采取行动,再次观察并建立假设,以通过尝试和错误来解释我们的行为是如何改变环境的。
一个可行的假设是,关于世界的通行知识,或者说常识,构成了人类和动物具备的生物智能的主要基础。这种常识能力对于人类和动物来说都是天然存在的,但是自 AI 研究起步以来,它一直都是一项未解决的挑战。从某种意义上说,常识就是人工智能领域的暗物质。
常识可以帮助人们学习新技能,而无需为每项任务都做大量的教学指导。例如,我们只需向小孩子展示几张母牛的画像,他们最后就能识别出他们看到的任何母牛。相比之下,受监督学习训练的 AI 系统需要许多母牛图像的样本,即便如此也可能无法识别出特殊情况下的母牛(例如躺在沙滩上的牛)。
在几乎没有监督的情况下,人们是如何在大约 20 个小时的练习中学会驾驶汽车的呢?相比之下,全自动驾驶系统为什么需要动用我们最优秀的 AI 系统,接受来自人类驾驶员的数千小时数据的训练?简单的答案是,人类依赖的是他们之前获得的有关世界运作方式的背景知识。
我们如何让机器也能做到这一点呢?
我们相信,自监督学习(self-supervised learning,SSL)是建立这种背景知识,并在 AI 系统中建立一种近似常识形式的最有前途的方法之一。
自监督学习让 AI 系统能够从很少的数据中学习知识,这样才能识别和理解世界上更微妙、更不常见的表示形式。自监督学习在自然语言处理(NLP)领域取得了显著的成就,包括 Collobert-Weston 2008 模型、Word2Vec、GloVE、fastText,以及最近的 BERT、RoBERTa、XLM-R 等成果。与仅以监督方式做训练的系统相比,以这种方式进行预训练的系统所提供的性能要高得多。
我们最新的研究项目 SEER 利用了 SwAV 等方法,在一个包含十亿张随机未标记图像的大型网络上做预训练,进而在各种视觉任务集上获得了最顶尖的准确性水平。这一进展表明,自监督学习也可以胜任复杂现实环境中的 CV 任务。
在这篇文章中,我们会向大家分享为什么自监督学习可能有助于解锁智能研究领域的暗物质,以及 AI 产业下一个前沿领域的细节。我们还将重点介绍关于 AI 系统中自监督学习和推理的一些最有希望的新方向,包括在不确定环境下用于预测的基于能量的模型、联合嵌入方法和潜在变量架构。
自监督学习是预测性学习
自监督学习是利用数据的基础结构来从数据本身获取监督信号的。一般来说,自监督学习使用的技术是根据输入的任何观察到的或非隐藏的部分,来预测输入的任何未观察到的或隐藏的部分(或属性)。例如,在 NLP 中很常见的例子是,我们可以隐藏句子的一部分,并从其余单词中预测隐藏的单词。我们还可以根据当前帧(观察到的数据)预测视频中的过去帧或未来帧(隐藏数据)。由于自监督学习使用的是数据本身的结构,因此它可以在多种共现模式(例如视频和音频)和大型数据集中利用各种监督信号,而无需依赖标记。
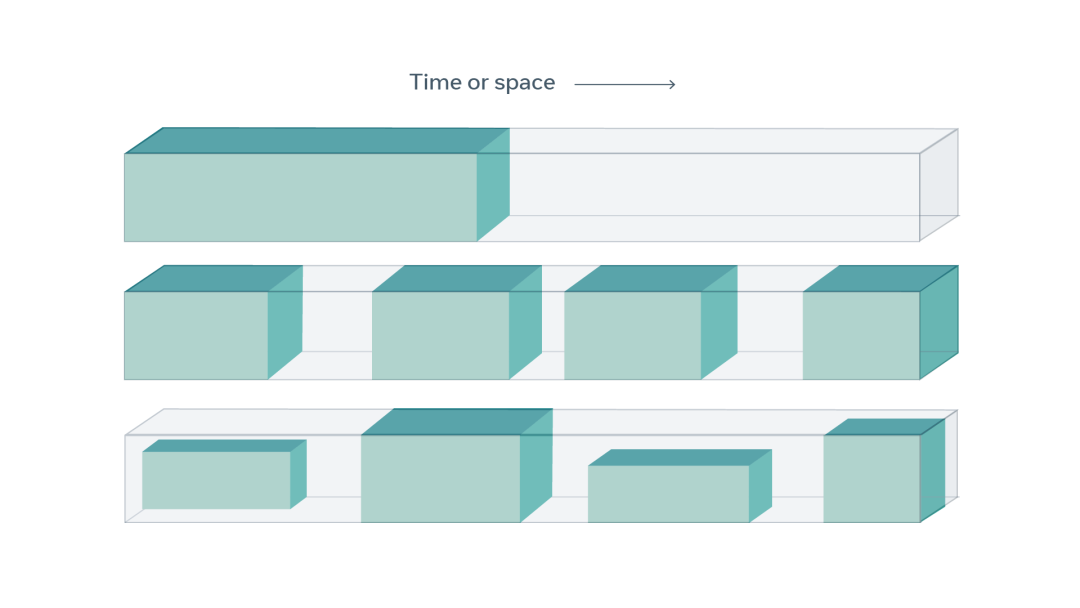
在自监督学习中,训练系统以从输入的可见部分(绿色)预测输入的隐藏部分(灰色)
由于自监督学习是由监督信号推动的,因此与之前使用的术语“无监督学习”相比,“自监督学习”这个术语更容易被接受。无监督学习是一个定义不清、具有误导性的术语,让人觉得这种学习根本用不到监督。实际上,自监督学习并不是无监督的,因为它使用的反馈信号比标准的监督学习和强化学习方法要多得多。
自监督的语言与视觉学习
自监督学习对 NLP 产生了特别深远的影响,使我们能够在大型的未标记文本数据集上训练 BERT、RoBERTa、XLM-R 等模型,然后将这些模型用于下游任务。这些模型在自监督阶段进行预训练,然后针对特定任务(例如分类文本主题)进行微调。在自监督的预训练阶段,系统会显示一段简短的文本(通常包含 1,000 个单词),其中一些单词已被屏蔽或替换。系统经过训练可以预测被屏蔽或替换的单词。通过这种方式,系统学会了表示文本的含义,这样它就可以很好地填写“正确的”单词,或者说在上下文中有意义的单词。
预测输入的缺失部分是 SSL 预训练的更常见的任务之一。要完成诸如“()在非洲草原上追赶()”这样的句子,系统必须知道狮子或猎豹可以追捕羚羊或牛羚,但猫是在厨房而非热带草原中追逐老鼠的。训练的结果是,系统学会了如何表示单词的含义、单词在句子中的作用以及整段文本的含义。
但是,这些技术不能轻松扩展到新领域,例如 CV 上。尽管 SSL 取得了令人鼓舞的早期成果,但它尚未在计算机视觉方面带来我们在 NLP 领域中看到的那种改进(尽管这种情况将会改变)。
主要原因是,在图像的预测任务中表示不确定性要比在单词中表示不确定性困难得多。当系统无法准确预测缺失的单词时(是“狮子”还是“猎豹”?),系统可以对词汇表中所有可能的单词打出分数或概率:“狮子”“猎豹”和其他一些掠食者拿到高分,词汇表中其他单词的得分都较低。
规模这么大的训练模型还需要一种在运行时和内存方面都有很高效率,而又不影响准确性的模型架构。幸运的是,FAIR 在架构设计领域的最新创新催生了一个新的模型家族,名为 RegNets,可以完全符合这些需求。RegNet 模型都是 ConvNet,能够扩展到数十亿甚至可能是数万亿的参数,并且可以进行针对优化以适应不同的运行时和内存限制。
但是,当我们预测视频中丢失的帧或图像中缺少的色块时,我们不知道如何有效地表示不确定性。我们无法列出所有可能的视频帧,也无法给每个可能的视频帧打出分数,因为它们的数量是无限的。尽管这一问题限制了视觉领域中 SSL 带来的性能改进,但诸如 SwAV 之类的新 SSL 技术开始打破视觉任务中的准确性记录。SEER 系统就是一个最佳证明,它使用了一个经过数十亿样本训练的大型卷积网络。
对预测中的不确定性建模
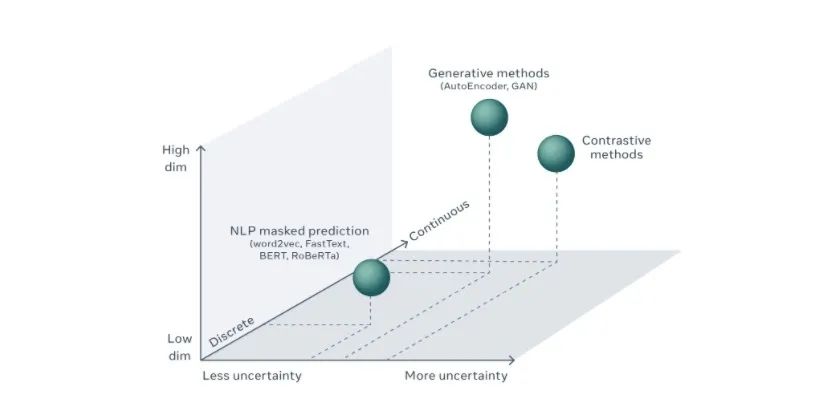
为了更好地理解这一挑战,我们首先需要了解与 NLP 相比,CV 中预测不确定性及其建模的方式。在 NLP 中,缺失单词的预测工作需要计算词汇表中每个可能单词的预测分数。虽然词汇量本身很大,并且预测缺失单词会带来一些不确定性,但系统可以生成词汇表中所有可能单词的列表以及该位置可能出现单词的概率估计。典型的机器学习系统会将预测问题视为分类问题,并使用巨大的所谓的 softmax 层来计算每个结果的分数,进而将原始分数转换为单词的概率分布以实现上述目的。使用这种技术,只要存在有限数量的可能结果,预测的不确定性就可以通过所有可能结果的概率分布来表示。
相比之下,在 CV 领域中,预测视频中“丢失”的帧、图像中缺少的块或语音信号中缺失片段的类似任务需要对高维连续对象做预测,而不是对离散结果做预测。给定的视频帧后面可以跟随的视频帧有无数种合理的可能。系统不可能明确表示所有可能的视频帧并为它们给出预测分数。实际上,我们可能永远也没有适当地表示高维连续空间(例如所有可能视频帧的集合)上概率分布的技术。
这似乎是一个棘手的问题。
自监督方法的统一视角
基于能量的模型(energy-based model,EBM)这一统一框架为 SSL 提供了一种思路。EBM 是一种可训练的系统,在给定两个输入 x 和 y 的情况下,它能告诉我们它们彼此之间的不相容程度。例如,x 可以是一段短视频剪辑,而 y 可以是另一个建议的视频剪辑。机器会告诉我们 y 在多大程度上是 x 的良好后续。为了指出 x 和 y 之间的不相容程度,机器会生成一个称为能量的数字。如果能量较低,则认为 x 和 y 相互趋于相容;否则,x 和 y 被认为是不相容的。
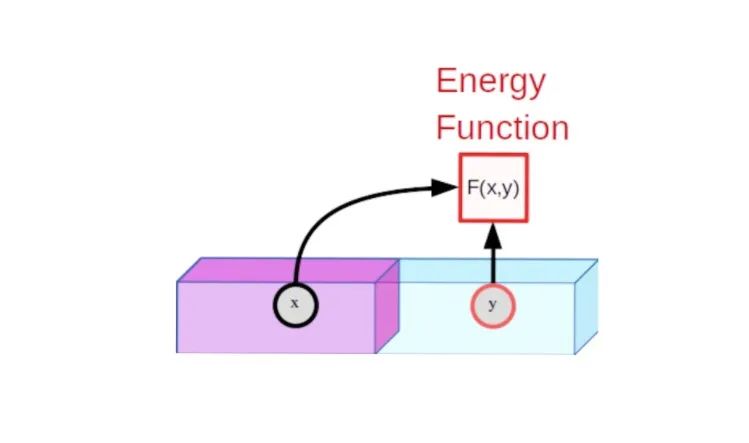
基于能量的模型(EBM)测量观测值 x 与建议的预测值 y 之间的相容性。如果 x 和 y 相容,则能量很小。如果它们不相容,则能量较大。
EBM 的训练过程包括两部分:(1)向其展示 x 和 y 相容的示例并对其进行训练以产生一个较低的能量(2)找到一种方法来确保对于特定 x,与 x 不相容的 y 值产生的能量比与 x 相容的 y 值更高。第一部分很简单,但第二部分就是困难所在。
为了进行图像识别,我们的模型将 x 和 y 这两个图像作为输入。如果 x 和 y 是同一图像的略有变形的版本,则用它们训练该模型以使其输出产生低能量。例如,x 可以是一辆汽车的照片,而 y 可以是同一辆汽车的照片,只是在一天中的不同时间从稍有不同的位置拍摄的,因此相比 x 中的汽车,y 中的汽车可以移动、旋转、更大、更小,或者显示的颜色和阴影略有不同。
联合嵌入,暹罗网络
一种特别适合这一用途的深度学习架构是所谓的暹罗网络或称联合嵌入(joint embedding)架构。这个想法可以追溯到 Geoff Hinton 实验室和 Yann LeCun 小组的论文(1990 年代初,这里和这里;2000 年代中,这里,这里,和这里)。它过去一直没得到很好的重视,但自 2019 年底以来重新成为了热门话题。联合嵌入架构由同一网络的两个相同(或几乎相同)的副本组成。一个网络用 x 输入,另一个网络用 y 输入。这些网络生成称为嵌入(embedding)的输出向量,分别表示 x 和 y。第三个模块将这些网络头对头连接起来,将能量计算为两个嵌入向量之间的距离。当模型看到同一图像的不同变形版本时,可以轻松调整网络参数,以使它们的输出靠得更近。这将确保网络生成对象的几乎相同的表示(或嵌入),而不管该对象的特定视图是什么样子。
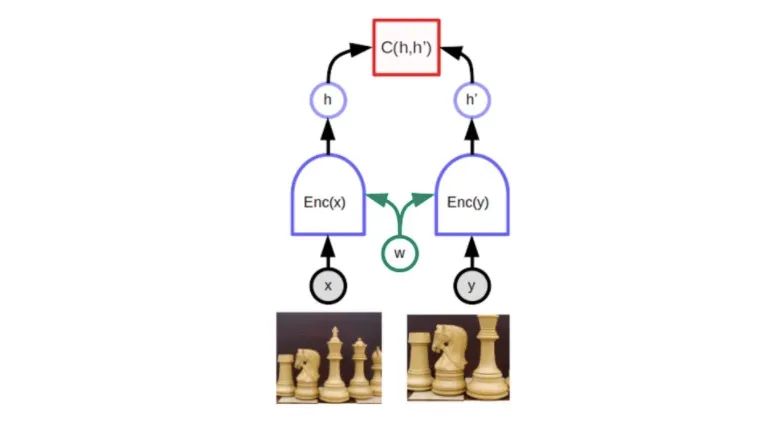
联合嵌入架构。顶部的函数 C 产生一个标量能量,该标量能量测量由共享相同参数(w)的两个相同的双胞胎网络生成的表示向量(嵌入)之间的距离。当 x 和 y 是同一图像的稍有不同的版本时,系统经过训练以生成一个低能量,这迫使模型为两个图像生成相似的嵌入向量。困难的部分是训练模型,以便为不同的图像生成高能量(即,不同的嵌入)。
困难在于当 x 和 y 是不同的图像时,如何确保网络生成高能量,即不同的嵌入向量。如果没有特定的方法,这两个网络可能会愉快地忽略它们的输入,并始终生成相同的输出嵌入。这种现象称为崩溃。当发生崩溃时,x 和 y 不匹配的能量不会比 x 和 y 匹配的能量更高。
有两种避免崩溃的技术:对比方法和正则化方法。
基于能量的 SSL 的对比方法
对比方法基于以下简单思想:构造不相容的 x 和 y 对,并调整模型的参数,以使相应的输出能量较大。
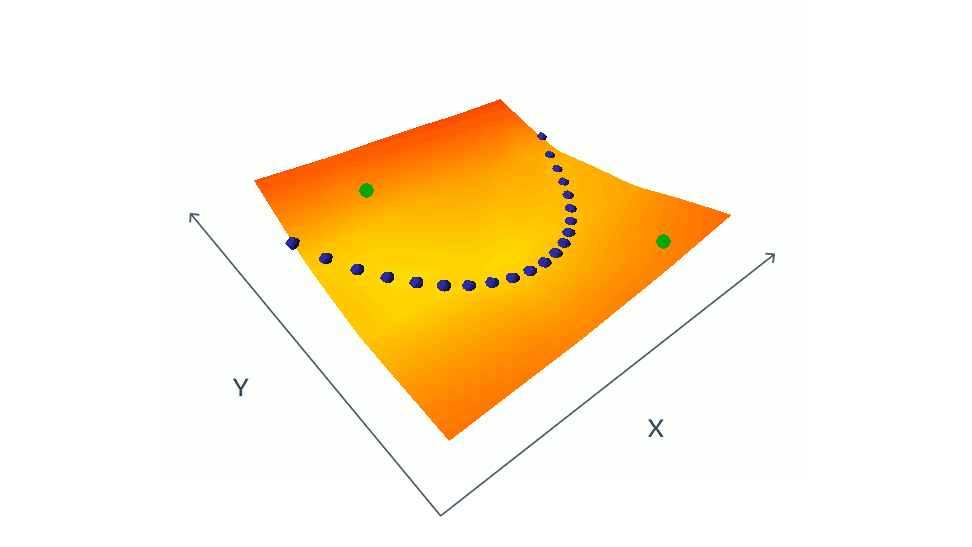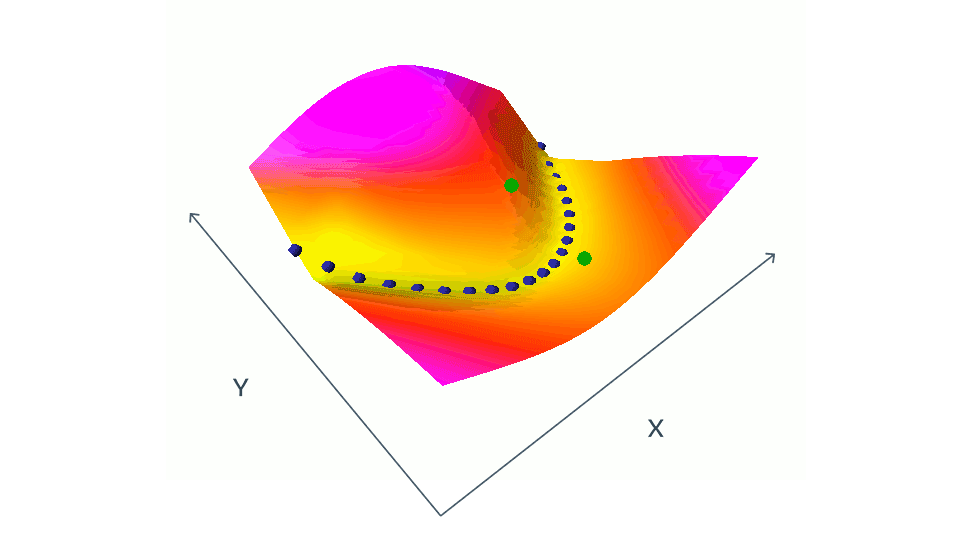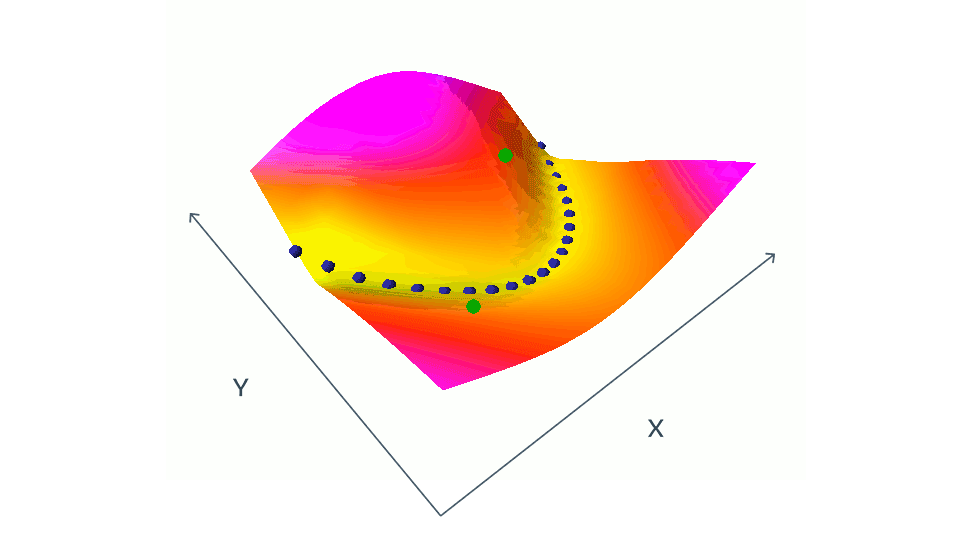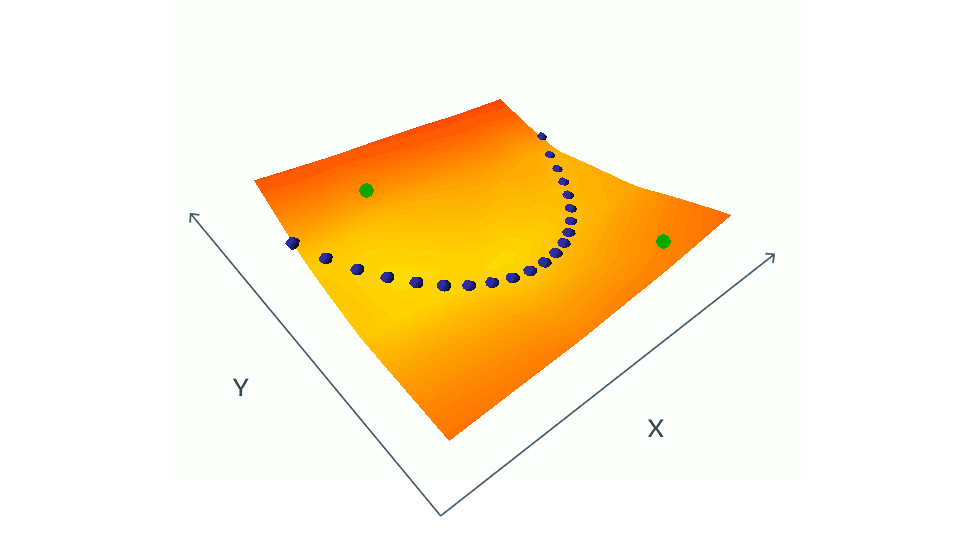
用对比方法训练 EBM 的方法包括同时降低训练集中相容的(x,y)对的能量(由蓝点表示),提高挑选出来的不相容的(x,y)对的能量(以绿点表示)。在这个简单的示例中 x 和 y 都是标量,但在实际情况下,x 和 y 可以是具有数百万个维度的图像或视频。找出让能量按照预期方式涨落的不相容对是一大挑战,需要庞大的计算资源。
通过屏蔽或替换某些输入词来训练 NLP 系统的方法属于对比方法的类别。但是它们不使用联合嵌入架构。取而代之的是,他们使用了一种预测架构,其中模型直接生成 y 的预测。模型从文本 y 的一个完整段开始,然后通过屏蔽某些单词来破坏它,以生成观察值。损坏的输入将输入到一个大型神经网络,该网络经过训练可以重现原始文本 y。未损坏的文本将被重建为自身(低重建错误),而已损坏的文本将被重建为自身的未损坏版本(较大的重建错误)。如果将重建错误解释为一种能量,它将具有所需的属性:“干净”文本的能量较低,而“损坏”文本的能量较高。
训练模型以恢复输入的损坏版本的一般性技术被称为降噪自动编码器。这个想法的早期形式可以追溯到 1980 年代,2008 年由蒙特利尔大学的 PascalVincent 和同事们复兴。这一理念被 Collobert 和 Weston 引入 NLP 领域,并由我们在谷歌的同行在 BERT 论文中发扬光大。
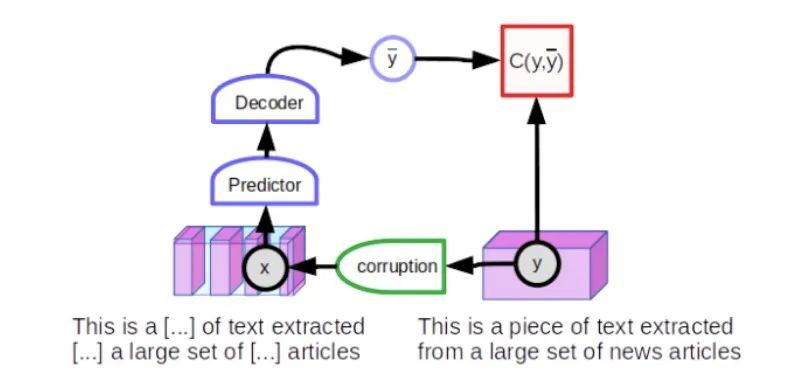
屏蔽语言模型是降噪自动编码器的一个实例,它本身是对比自监督学习的一个实例。变量 y 是一个文本段;x 是文本中某些单词被屏蔽的版本。网络经过训练可以重建未损坏的文本。
正如我们之前指出的,这种类型的预测架构只能对给定的输入生成单个预测。由于模型必须能够预测多个可能的结果,因此预测结果不是单个单词集,而是针对每个缺失单词位置的词汇表中各个单词的分数系列。
但是我们不能对图像使用这种技术,因为我们无法枚举所有可能的图像。存在解决这一问题的方法吗?简单的回答就是不存在。在这个方向上有一些有趣的想法,但是它们尚未产生与联合嵌入架构一样好的结果。一种有趣的途径是潜在变量(latent-variable)预测架构。
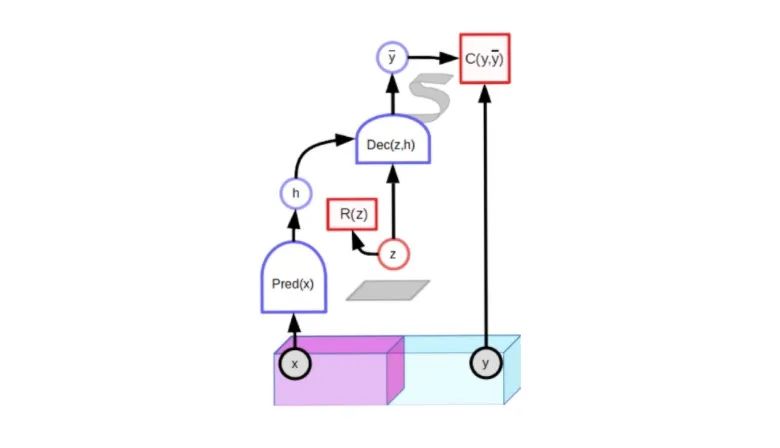
潜在变量预测架构。给定一个观测值 x,该模型必须能够生成一组由图中的 S 形色带表示的多个相容预测。当潜在变量 z 在一个用灰色正方形表示的集合内变化时,输出在该组合理的预测范围内变化。
潜在变量预测模型包含一个额外的输入变量(z)。之所以称其为潜在,是因为系统从未观察到它的值。对于经过适当训练的模型,由于潜在变量在给定的集合上变化,因此输出预测在与输入 x 相容的合理预测的集合上变化。
可以使用对比方法来训练潜在变量模型。生成对抗网络(GAN)就是一个很好的例子。批评者(或称鉴别器)可以被视为计算能量,该能量指示输入 y 是否看起来不错。生成器网络经过训练以生成对比样本,批评者被训练到对比样本以关联高能量。
但是对比方法有一大问题:它们的训练效率很低。在诸如图像之类的高维空间中,一张图像与另一张图像的区别可以有很多表现形式。找到涵盖所有可能与给定图像不同之处的对比图像集合几乎是不可能的任务。就像托尔斯泰名著《安娜·卡列尼娜》中的名言:“幸福的家庭都是相似的;不幸的家庭都有自己的不幸。”看来,这一规则也适用于任何高维对象系列。
怎样才能在不显著提高许多不相容对的能量的情况下,确保不相容对的能量高于相容对的能量呢?
基于能量的 SSL 的非对比方法
应用于联合嵌入架构的非对比方法可能是目前 SSL 视觉领域中最热门的话题。这个领域还有大片需要探索的未知事物,但它似乎很有希望。
联合嵌入的非对比方法包括 DeepCluster、ClusterFit、MoCo-v2、SwAV、SimSiam、Barlow Twins、来自 DeepMind 的 BYOL 等等。他们使用各种技巧,例如为一组相似的图像计算虚拟目标嵌入(DeeperCluster、SwAV、SimSiam),或者通过架构或参数向量来让两种联合嵌入架构出现细微差异(BYOL、MoCo)。BarlowTwins 则试图最小化嵌入向量各个分量之间的冗余。
从长远来看,也许更好的选择是设计潜在变量预测模型的非对比方法。主要的障碍是它们需要一种方法来最小化潜在变量的容量。容纳潜在变量变化的集合大小限制了消耗低能量的输出的大小。通过最小化这一大小,可以自动以正确的方式来排布能量。
这种方法的一个成功例子是变分自编码器(Variational Auto-Encoder,VAE),其将潜在变量设为“模糊”,从而限制了其容量。但是,尚未证明 VAE 可以为下游的视觉任务提供良好的表示。另一个成功的例子是稀疏建模(sparse modeling),但其用例仅限于简单的架构。似乎没有完美的方法可以限制潜在变量的容量。
未来几年我们面临的挑战可能是为潜在变量基于能量的模型设计非对比方法,这种方法应该能成功生成图像、视频、语音和其他信号的良好表示形式,并在不需要大量标记数据的情况下在下游监督任务中获得最佳性能。
推进视觉领域的自监督学习
最近,我们创建并开源了一种称为 SEER 的,具有十亿参数的自监督 CV 新模型,它已被证明可有效处理复杂的高维图像数据。它基于应用于卷积网络架构(ConvNet)的 SwAV 方法,可以用大量随机图像训练,而无需任何元数据或注释。ConvNet 足够大,可以从庞大而复杂的数据中捕获和学习每个视觉概念。在对 10 亿张随机、未标记和未整理的公共 Instagram 图像集合进行预训练,并在 ImageNet 上进行了监督微调之后,SEER 的表现超过了最先进的自监督系统,在 ImageNet 上的 top-1 准确度达到了 84.2%。
这些结果表明,我们可以将自监督的学习范式拓展到计算机视觉领域。
在 Facebook 应用自监督学习
在 Facebook,我们不仅在多个领域通过基础、开放的科学研究推进自监督学习技术,我们还将这项前沿工作应用到了生产中,以快速提高我们平台安全性产品中内容理解系统的准确度,
像我们的预训练语言模型 XLM 这样的自监督领域研究正在为 Facebook 上的许多重要应用程序提供动力——包括主动检测仇恨言论的系统。我们已经部署了 XLM-R,该模型利用了我们的
RoBERT 架构,以改进我们在 Facebook 和 Instagram 上针对多种语言的仇恨语音分类器,这样即使在训练数据很少的语言中我们也可以实现仇恨语音检测。
近年来,自监督学习的进展让我们倍感鼓舞,尽管要让这种方法帮助我们发现 AI 智能的暗物质还有很长的路要走。自监督是通往人类水平智能的道路上的重要一步,但这一步背后肯定有许多积累,所谓千里之行始于足下。因此,我们在努力与更大范围内的 AI 社区合作,以实现我们在未来的某一天创造出具有人类智能的机器的目标。我们的研究已公开发布并在顶级会议上发表。我们还组织了研讨会并发布了一些库,以帮助加快这一领域的研究。
编辑:lyn
-
AI
+关注
关注
87文章
30728浏览量
268887 -
人工智能
+关注
关注
1791文章
47183浏览量
238259 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:图灵奖得主 Yann LeCun 最新文章 :自监督学习,人工智能世界的“暗物质”
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时空引导下的时间序列自监督学习框架

嵌入式和人工智能究竟是什么关系?
人工智能、机器学习和深度学习存在什么区别






 工商网监
工商网监
评论