 以AI为卖点的国产GPU新贵是泡沫吗?
以AI为卖点的国产GPU新贵是泡沫吗?
3月30日,“壁仞科技完成B轮融资,成立一年多累计融资超过47亿”的新闻刷爆了半导体圈。
2019年9月成立的壁仞科技在其官网上声称,从发展路径上,壁仞科技将首先聚焦云端通用智能计算,逐步在人工智能训练和推理、图形渲染、高性能通用计算等多个领域赶超现有解决方案,实现国产高端通用智能计算芯片的突破。据称该公司创始团队由国内外芯片和云计算领域核心专业人员、研发人员组成,在GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累和独到的行业洞见。
2020年6月成立的摩尔线程获得数十亿元融资,该公司致力于构建中国视觉计算及人工智能领域计算平台,研发全球领先的自主创新GPU知识产权,以及助力建立中国本土的高性能计算生态系统,其GPU产品线覆盖通用图形计算和高性能计算。据称其创始团队核心成员主要来自英伟达(NVIDIA)、微软(Microsoft)、英特尔(Intel)、AMD和Arm等,主要成员都在GPU驱动、编译、AI芯片、软件算法以及系统设计等领域超过10年以上经验。
2020年9月成立的沐曦集成电路完成数亿元PreA+轮融资,据称这家高性能通用GPU芯片设计公司的创始团队主要来自AMD等国际公司,拥有从40nm到7nm制程GPU芯片的设计和量产经验。
2019年11月成立的芯瞳半导体创始团队来自西邮GPU研发团队,这家专注于计算机图形和高性能计算的芯片设计初创公司将在南京投资1.5亿元,开发高性能、高可靠和高稳定性的国产自主GPU和人工智能芯片。
于2018年12月在上海成立的瀚博半导体已经完成总计5000万美元的A轮融资,其核心员工平均拥有15年以上的相关芯片和软件设计经验,目前有员工150多人。其产品注重计算机视觉及视频处理的优化,可提供丰富的特性和高效的性能/功耗,适用多个人工智能领域。
2017年11月成立的登临科技最近完成A+轮融资,其首款GPU+(软件定义的片内异构通用AI处理器)产品已成功回片通过测试。成立三年以来,登临致力于完全自主研发的多场景AI 计算平台,其Goldwasser GPU+产品在现有市场主流GPU 架构上,创新性地采用软硬件协同的异构设计,相比传统GPU在AI计算性能和能效上均有明显提升。
成立于2015年12月的上海天数智芯最近完成12亿元的C轮融资,其7纳米通用(GPGPU)云端计算芯片BI于 2020 年 5 月流片、11 月回片并于12月成功 “点亮”。天数智芯将进一步加速面向5G需求的云端训练及推理芯片的研发,提供针对当前主流 GPGPU 生态产品选项,帮助人工智能在更多领域落地应用。
这些由来自英伟达或AMD等国际巨头的资深华人专家创办的国产GPU新贵们大都只有雄心壮志和发展宏图,还没有具体的产品和应用方案。在短时间内拿到这么大金额的VC投资,这是不是又一轮国产芯片的“泡沫”?
要准确回答和预测这一轮国产GPU融资和创业的前景,还要先从GPU的发展历程、全球和中国市场现状,以及未来应用发展潜力来看。
编者注:以下内容参照维基百科和方正证券研究报告《GPU研究框架—行业深度报告》。
图形处理器(GPU)发展进程
对GPU比较熟悉的朋友可跳过这部分内容,直接到“全球GPU市场进入寡头垄断格局”部分。
图形处理器(Graphics Processing Unit,GPU)又称显示核心、显卡、视觉处理器、显示芯片或绘图芯片,是一种专门在PC、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。
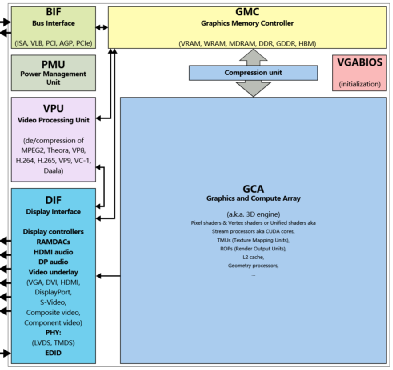
图形处理器(GPU)的构成。(来源:维基百科)
图形处理器是英伟达公司(NVIDIA)在1999年8月发布NVIDIA GeForce 256图形处理芯片时首先提出的概念。在此之前,电脑中处理图形输出的显示芯片很少被视为是一个独立的运算单元。而竞争对手ATI(后来被AMD收购)也提出了视觉处理器(Visual Processing Unit,VPU)的概念。图形处理器可让显卡减少对CPU的依赖,并分担部分原本由CPU所执行的任务,尤其是在进行三维绘图运算时,功效更加明显。GPU所采用的核心技术有硬件坐标转换与光源、立体环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。
GPU可单独与专用电路板组成显卡,或作为单独的芯片直接内嵌到主板上,或者内置于主板的北桥芯片中,现在也有内置于CPU组成SoC的。在2007年,90%以上的新型台式机和笔记本电脑都带有嵌入式图形芯片,但是在性能上往往低于独立显卡。但2009年以后,AMD和英特尔都各自大力发展内置于CPU的高性能集成式图形处理内核,其性能在2012年已经超过那些低端独立显卡,这使得不少低端的独立显卡逐渐失去市场需求。而在手持和移动设备领域,随着设备对图形处理能力的需求越来越高,像高通(Qualcomm)、Imagination、ARM等开始在GPU领域“大显身手”,但大都是以GPU内核的形式植入应用处理器MPU中。
传统的CPU(如Intel i5或i7处理器)内核数量较少,是为通用计算而设计的。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化可并行执行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它对数据分析、深度学习和机器学习算法尤其有用。GPU可让某些计算比传统CPU的处理速度快10倍至100倍。
AI加速让GPU和英伟达腾飞
人工智能加速器(AI accelerator)是一种专门的硬件加速器或计算机系统,旨在加速人工智能应用,尤其是人工神经网络、机器视觉和机器学习。AI加速器的典型应用包括机器人、物联网和其他数据密集型或传感器驱动任务的算法。它们通常由许多处理器内核设计而成,并且通常专注于低精度算术运算,采用新的数据流体系结构或存内计算架构。
GPU是用于处理图像和计算局部图像属性的专用硬件,而神经网络和图像处理的数学基础是相似的,都需要处理庞大的矩阵并行任务。自从2012年AI开始流行以来,GPU越来越多地用于机器学习任务。特别是2016年以来,GPU在处理AI任务中越来越流行,并朝着深度学习的方向发展。无论是数据中心的AI训练还是自动驾驶的边缘AI推理,GPU都可以从容应对。随着GPU在AI方面的普及,专注于GPU的英伟达自然也成为AI时代的宠儿,一改多年活在英特尔和AMD夹缝中的“underdog”形象,一跃成为市值超过英特尔的华尔街新贵。
深度学习框架和AI算法仍在不断发展中,这使得设计定制硬件变得异常困难。像现场可编程门阵列(FPGA)这类可重配置的器件可以比GPU更为灵活地跟随AI框架和软件而演进。微软率先使用FPGA芯片进行AI推理加速,FPGA在AI加速中的应用前景也促使Intel收购Altera,目的是将FPGA集成到服务器CPU中,使得CPU在执行通用计算任务的同时还能够实现AI加速。
尽管GPU和FPGA在执行AI相关任务上性能表现要比CPU更好,但基于特定域架构(DSA)理念而定制设计的ASIC可将效率再提高多达10倍。这种AI加速器采用优化内存使用和低精度算术之类的办法来加速计算,并提高计算吞吐量。Facebook、Amazon和Google等互联网巨头都在设计自己的AI ASIC,像Google的TPU等。
全球GPU市场进入寡头垄断格局
据权威调研机构预测,2020年全球GPU市场规模达254.1亿美元,预计2027年将达到1853.1亿美元,年复合增长率高达32.82%。按GPU的行业应用划分,市场可细分为电子、IT与电信、国防与情报、媒体与娱乐、汽车及其它。由于GPU在设计和工程应用中的广泛使用,预计汽车细分行业的年复合增长率最高。
在全球AI芯片市场,GPU约占1/3左右。高性能计算(HPC)领域历来都是GPU的重要市场,有数据预测到2023年将有10%的服务器配备GPU以加速AI工作负载,而这一数字在2018年还不到2%。随着HPC与AI的加速融合,GPU正在重新定义数据中心和高性能计算市场。
全球GPU已经进入了寡头垄断的格局。在传统GPU市场中,排名前三的Nvidia、AMD、Intel的营收几乎可以代表整个GPU行业的收入。在手机和平板GPU方面,联发科、海思麒麟和三星Exynos的GPU设计主要基于公版ARM Mali GPU或Imagination PowerVR微架构,而高通骁龙Adreno和苹果A系列则采用自研GPU微架构。
英伟达是GPU计算领域公认的全球领导者,其主要GPU产线“GeForce”和AMD的“Radeon”形成直接竞争。英伟达的四大业务增长驱动力分别是游戏、数据中心、专业视觉和自动驾驶,代表性GPU方案包括GeForce、DGX、EGX、HGX、Quadro、AGX。该公司2021财年营收为167亿美元,其中游戏、数据中心、专业视觉和自动驾驶业务在2020财年分别贡献47%、40%、6%和3%。继2014年毛利率达到50%之后,英伟达于2021财年毛利率突破60%。
2020年9月,NVIDIA宣布以400亿美元收购ARM。如果这宗并购成功,英伟达领先的AI计算平台和ARM庞大的处理器生态相结合,将缔造出AI时代的世界级计算公司。合并后的英伟达将把计算从云端、智能手机、PC、自动驾驶和机器人领域推进到边缘物联网,将AI计算拓展到全球市场。同时,英伟达计算平台的开发者将由200万扩大至超过1500万,从而形成全球最大的计算平台和生态社区。
国产GPU发展现状及市场潜力
经过多年的探索和发展,国产CPU已经形成一定的气候,产业和生态也逐渐健全起来。以龙芯、兆芯和飞腾为代表的国产CPU开始围绕各自的核心产品发展和扩展生态,借助国家信创和独立自主发展半导体产业的东风而逐渐发展壮大。然而,国产GPU的发展却远远落后于国产CPU。直到2014年,景嘉微才成功研发出国内首款高性能、低功耗GPU芯片—JM5400。
究其原因,GPU自身依赖于CPU的属性是主要因素。GPU结构没有控制器,必须由CPU进行控制调用才能工作,否则GPU无法单独工作。所以,国产CPU较GPU先行一步是符合芯片产业发展逻辑的。再者,GPU技术开发难度很高。国内人才缺口也是国产GPU发展缓慢的原因之一。
然而,中国GPU市场规模和潜力非常大,庞大的整机制造能力意味着巨量的GPU采购。虽然近些年,计算机整机和智能手机产量增长都出现瓶颈,但由于这两类产品体量庞大,GPU的需求量大且单品价值非常高,市场规模依然非常可观。同时,服务器GPU伴随着整机出货的快速成长,需求量增长也较为迅速。据统计,2018年国内服务器出货量达到330.4万台,同比增长26%,其中互联网、电信、金融和服务业等行业的出货量增速均超过20%。另外,国内在物联网、车联网、人工智能等新兴计算领域,对GPU也存在海量的需求。
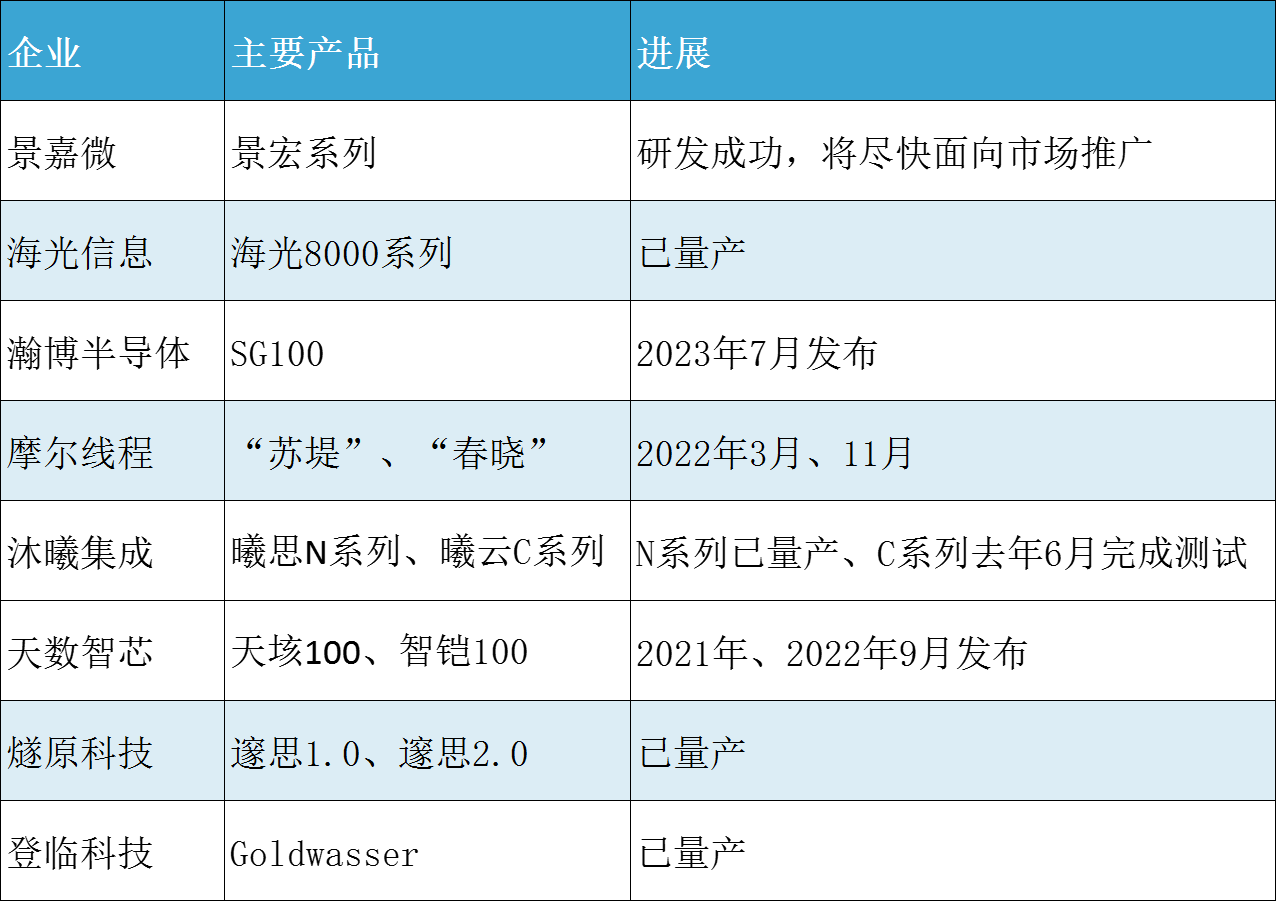
除本文开头提到的几家以AI为卖点的国产GPU初创公司外,还有一些国产GPU厂商已经在特定领域深耕多年,现正把握信创市场和“国产替代”的机遇扩展应用市场,加速国产GPU行业的发展。
景嘉微
长沙景嘉微成立于2006年4月,是目前唯一专注于国产GPU芯片设计的上市企业,其主要产品包括JM5400、JM7200和JM7201图形处理器,所面向的应用市场包括笔记本电脑、一体机、移动工作站、刀片式主板等桌面办公和工业控制领域。
2014年4月,景嘉微成功研发出国内首款高可靠、低功耗GPU芯片-JM5400,具有完全自主知识产权,打破了国外产品长期垄断中国GPU市场的局面。第一代GPU JM5400主要用于军用市场,替代原ATI M9、M54、M72等美系GPU芯片。
景嘉微的第二代GPU JM7200系列于2018年8月流片成功,并在2019年3月获得首个订单。相较于前代产品,JM7200在理论性能上有翻倍的提升,同时制程也提升至28纳米。但是JM7200在显存带宽、像素填充率、浮点性能等方面较2012年发布的采用完整版GK107核心的英伟达GT640还有相当差距。
2019年,该公司在JM7200基础上,推出了商用版本JM7201,以满足桌面系统高性能显示需求,并全面支持国产CPU和国产操作系统,从而推动国产计算机产业的生态构建进一步完善。JM7201对民用市场的桌面应用进行了优化,推出了标准MXM和标准PCIE显卡,在保证性能的同时,降低了功耗,并缩小了体积。
景嘉微GPU已完成与龙芯、飞腾、麒麟软件、统信软件、道、天脉等国内主要CPU和操作系统厂商的适配工作;与中国长城、超越电子等十余家国内主要计算机整机厂商建立合作关系并进行产品测试;与麒麟、长城、苍穹、宝德、超图、昆仑、中科方德、中科可控、宁美等多家软硬件厂商进行互相认证,共同构建国产化计算机应用生态。

景嘉微GPU产线。(来源:景嘉微和方正证券)
2018年12月,景嘉微定增募集10.88亿元,用于高性能通用图形处理器和面向消费电子领域的通用类芯片研发和产业化项目。其中,高性能通用图形处理器项目包括JM9231和JM9271两款GPU芯片,分别面向不同应用领域的中、高档系列产品。据公司2020年中报显示,下一代图形处理器研发处于后端设计阶段。景嘉微JM9系列是继JM5400和JM7200局部渲染计算内核之后,首次采用统一渲染结构的GPU,并且增加了可编程计算模块数量。JM9231和JM9271在性能表现上分别对标英伟达于2016年推出的GTX1050和GTX1080。
JM9系列的推出将使公司GPU水平与国际龙头缩短至5年,大幅提升公司在GPU领域的竞争力。
芯动科技
2020年10月,位于武汉的芯动科技宣布与Imagination达成合作,将采用多晶粒(chiplet)和GDDR6高速显存等SoC创新技术,基于Imagination全新顶配BXT多核架构,开发“风华”系列GPU。
芯动科技“风华”系列显卡GPU。(来源:芯动科技)
在信创和算力安全方面,“风华”系列GPU内置物理不可克隆iUnique Security PUF信息安全加密技术,提升数据安全和算力抗攻击性,支持桌面电脑和数据中心GPU计算自主可控生态。这款GPU芯片自带浮点和智能3D图形处理功能,全定制多级流水计算内核,兼具高性能渲染和智能AI算力,还可级联组合多颗芯片合并处理能力,灵活性大大增加,适配国产桌面市场1080P/4K/8K高品质显示,支持VR/AR/AI,多路服务器云桌面、云游戏、云办公等应用场景。
IP和芯片定制开发服务商芯原
在科创板上市的芯原股份的GPU IP源于在2016年收购嵌入式GPU开发商图芯技术(Vivante)。芯原在GPU IP领域已经掌握了支持主流图形加速标准、自主可控指令集和可拓展性强等核心技术,广泛应用于IOT、汽车电子、PC等市场。芯原可拓展的Vivante GPU IP应用涵盖从低功耗的小型物联网MCU(GPU Nano IP系列)到面向汽车和计算机应用的强大SoC(GPU Arcturus图形IP),可满足各种芯片尺寸和功耗预算,是具有成本效益的优质图形处理器解决方案。
芯原的图形处理器技术支持业界主流的嵌入式图形加速标准Vulkan 1.0、OpenGL 3.2、OpenCL 1.2 EP/FP和OpenVX 1.2等,具有自主可控的指令集及专用编译器,支持每秒2500亿次的浮点运算能力及128个并行着色器处理单元。
芯原在图形处理器技术方面的研发包括高性能的通用图形处理器GC8400 IP,该IP适用于汽车电子,目前仍处IP设计验证阶段,拟达到每秒1万亿次的浮点运算能力双倍精密度,512个并行着色器处理单元。
兆芯
总部位于上海张江的兆芯是世界上第三家拥有X86授权的微处理器公司,掌握CPU、GPU、芯片组三大核心技术,且具备三大核心芯片及相关IP设计与研发能力。兆芯提供桌面整机、服务器、工业主板和系统级解决方案,在党政办公、交通、金融、能源、教育和网络安全方面有着广泛的应用。
兆芯KX-6000是国内第一款完整集成CPU、GPU、芯片组的SoC单芯片国产通用处理器,采用16纳米制程,集成高性能显卡,支持DP/HDMI/VGA输出,兼容DirectX、OpenGL、OpenCL等主流API,最高可同时输出3台显示器,分辨率可达4K。
未来,兆芯还会对KX系列处理器进行进一步升级,使用全新的CPU架构,将内存从DDR4升级为DDR5,将总线从PCIe3.0升级至PCIe4.0。内存和总线的升级分别可以提高显卡的带宽和CPU与GPU间的通讯速度。除了集成GPU外,兆芯还计划发布一款采用台积电28纳米工艺,TDP 70瓦的独立GPU芯片。
芯瞳半导体
西安芯瞳半导体致力于研发高性能的GPU芯片,公司创始团队在GPU领域有着超过10年的学术和工程经验,是一支软硬件全栈式支持的研发团队。其核心技术人员来自西邮GPU核心团队、Intel、Mstar、华为海思、中兴、RedHat、腾讯、ThoughtWorks等知名软硬件公司。
公司第一代GPU芯片(GenBu01)系列产品已完成与国产CPU和主流操作系统的适配工作,可应用于嵌入式计算及设备、办公电脑和工控显示设备等应用场景。与深圳中微信息联合发布基于芯瞳GenBu01的MXMGB01显卡,是支持国产固件BIOS、国产操作系统、国产CPU的纯国产化显示解决方案。
在研的高性能产品可应用于服务器、数据中心等大型设备。公司目前所发明的专利囊括了GPU芯片设计的多个技术核心方向,包括显存管理、芯片架构建模、图形管线架构、着色器设计等方面。
登临科技
登临科技花费三年时间研发的第一代产品 Goldwasser已在2020年三季度量产,该产品目前正在与互联网和安防等领域的龙头企业合作集成及业务测试。该公司采用自主创新的 Minsky体系结构(软件定义的异构人工智能计算平台),在提供兼容 CUDA/OpenCL 硬件加速能力的前提下,全面支持各类流行的人工智能网络框架及底层算子。相比英伟达公司目前主流云端推理产品 (T4),登临科技的产品在同样的工艺上,具有更小的芯片面积,在同样功耗的情况下,视不同 AI 网络可将计算效率提升 3-10 倍,同时也减低了芯片性能对外存吞吐的依赖。
英伟达和AMD感受到威胁了吗?
在AI加速计算、国产半导体自主创新和风投资本的多重驱动下,原本风平浪静的国产GPU突然风生水起,在本就躁动不安的中国半导体业界掀起一股风浪。这对半导体行业和国产GPU的产业发展肯定是好事,但笔者认为这股被资本追逐和掀起的风浪有点热过了头。即便有资深的GPU研发专家、雄厚的资本加持,从头开创一个产业去跟全球GPU巨头竞争是不太现实的。英伟达和AMD是否感受到威胁了呢?我认为除了一些技术管理人才流失和研发人员被挖之外,国产GPU短期内还无法撼动他们的地位。
国家信创市场需求和工业控制等特定领域对GPU的需求增长将给景嘉微等国产GPU厂商带来增长和扩大市场的机遇。至于以AI为主要应用市场的这些GPU新贵们,除了拿出真正可以对比的GPU芯片外,还需要在生态建设和AI场景落地方面下功夫,才能证明自己拿到这么多钱确实是“物有所值”,才能消除“泡沫”的嫌疑。
原文标题:国产GPU风生水起,英伟达和AMD感受到威胁了吗?
文章出处:【微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
gpu
+关注
关注
28文章
4799浏览量
129521 -
AI
+关注
关注
87文章
31904浏览量
270713
原文标题:国产GPU风生水起,英伟达和AMD感受到威胁了吗?
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CPU\GPU引领,国产AI PC进阶

国产GPU独角兽格兰菲启动IPO
GPU是如何训练AI大模型的
《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变


AI训练,为什么需要GPU?

青云科技联手摩尔线程,构建国产算力繁荣生态
大模型时代,国产GPU面临哪些挑战

国产GPU在AI大模型领域的应用案例一览

盘点国产GPU在支持大模型应用方面的进展





 工商网监
工商网监
评论