 如何用上下文注意力来进行深度图像修复
如何用上下文注意力来进行深度图像修复
导读
使用上下文注意力来进行深度图像修复。
今天,我们将深入探讨深度图像修复的一个突破,上下文注意力。通过使用上下文注意力,我们可以有效地从遥远的空间位置借用信息来重建局部缺失的像素。这个想法实际上或多或少和上一篇的复制-粘贴是一样的。让我们看看是如何做到的。
回顾
在之前的文章中,我介绍了使用shift连接层将未缺失区域生成的特征作为参考来恢复缺失区域,可以让我们得到更好的修复结果。在这里,我们假设生成的特征是对ground truth的合理估计,并根据已知区域的特征与缺失区域内生成的特征之间的相似性来确定合适的参考。
动机
在图像修复任务中,CNN的结构不能有效地模拟缺失区域与遥远空间位置给出的信息之间的长距离相关性。熟悉CNN的人应该知道,在卷积层,核的大小和膨胀率控制着感受野,网络需要越深入,才能看到整个输入图像。这意味着,如果我们想捕捉图像的上下文,我们必须依赖于更深的层次,但我们丢失了空间信息,因为更深层次的特征的空间大小总是更小。因此,我们必须找到一种方法,在不用太加深网络的情况下,从遥远的空间位置借用信息(即理解图像的上下文)。
如果你还记得什么是膨胀卷积,你就会知道膨胀卷积是一种在早期的层中增加感受野而不添加额外参数的方法。然而,膨胀卷积有其局限性。它跳过连续的空间位置,以扩大感受野。请注意,跳过的连续空间位置对于填充缺失的区域也很关键。
介绍
这项工作与我们以前讨论过的网络架构、损失函数和相关技术类似。对于该体系结构,所提出的框架由两个生成器网络和两个判别器网络组成。这两个生成器在全卷积网络的基础上使用了膨胀卷积。一个生成器用于粗重建,另一个用于细化。这被称为标准的从粗到细的网络结构。这两个判别器同时在全局和局部看完整的图像。全局判别器以整个图像作为输入,而局部判别器以填充区域作为输入。对于损失函数,简单地说,他们还使用了对抗损失(GAN损失)和L1损失(为了像素级重建精度)。对于L1损失,他们使用一个spatially discounted L1 loss,其中为每个像素差分配一个权值,权值基于像素到其最近的已知像素的距离。对于GAN损失,他们使用WGAN-GP损失,而不是我们所介绍的标准的对抗损失。他们声称,这种WGAN对抗性损失也是基于L1距离度量,因此网络更容易训练,训练过程也更稳定。
在这篇文章中,我将专注于提出的上下文注意力机制。因此,我简要地介绍了从粗到细的网络架构、WGAN对抗损失和上面的加权L1损失。
方案
本文提出了上下文注意力机制,有效地从遥远的空间位置借用上下文信息来重建缺失的像素。将上下文注意力应用到二次精细化网络中。第一个粗重建网络负责对缺失区域进行粗估计。与前面一样,使用全局和局部判别器来鼓励生成的像素获得更好的局部纹理细节。
贡献
图1,该模型在自然场景、人脸和纹理图像上的修复效果实例。
本文最重要的思想是上下文注意力,它允许我们利用来自遥远空间位置的信息来重建局部缺失的像素。其次,使用对抗性损失和加权L1损失提高了训练的稳定性。此外,本文提出的修复框架在自然场景、人脸、纹理等各种数据集上都获得了高质量的修复结果,如图1所示。
方法
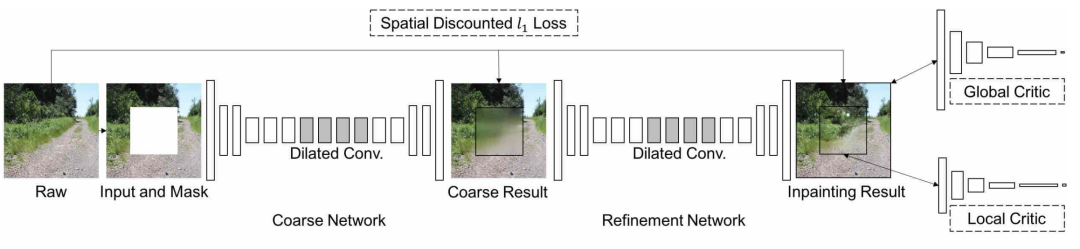
图2,所提出修复方法的网络架构
图2显示了所提出修复框架的网络架构,如前所述,它由两个生成器和两个鉴别器组成。
上下文注意力
以下是这篇文章的主要关注点。让我们来看看上下文注意力层是如何设计来借用遥远空间位置已知区域给出的特征信息来生成缺失区域内的特征的。
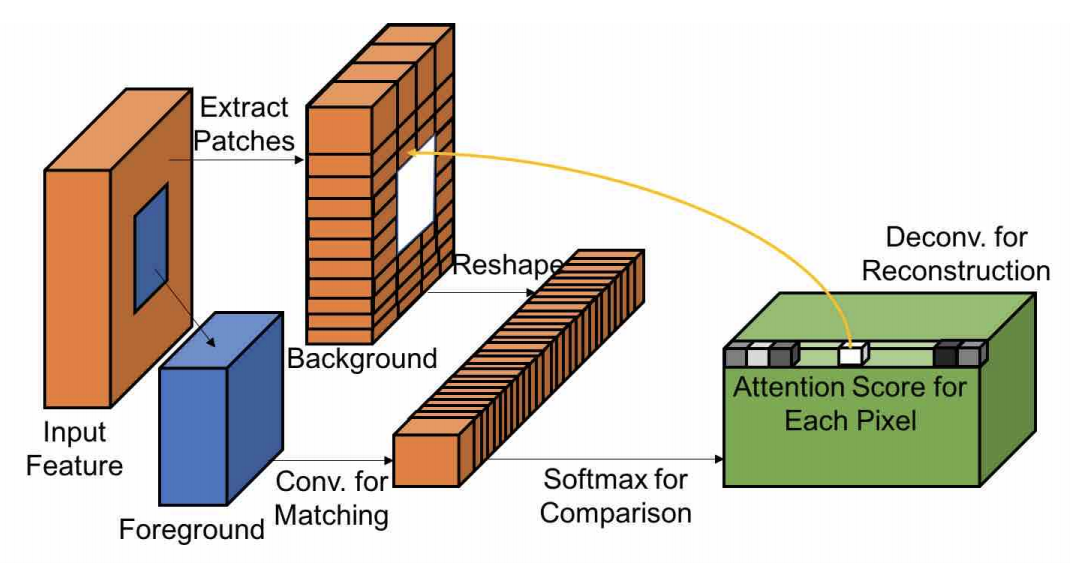
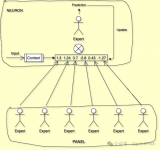
图3,上下文注意力层的图形说明图3显示了上下文注意层的图形说明。运算是可微且全卷积的。
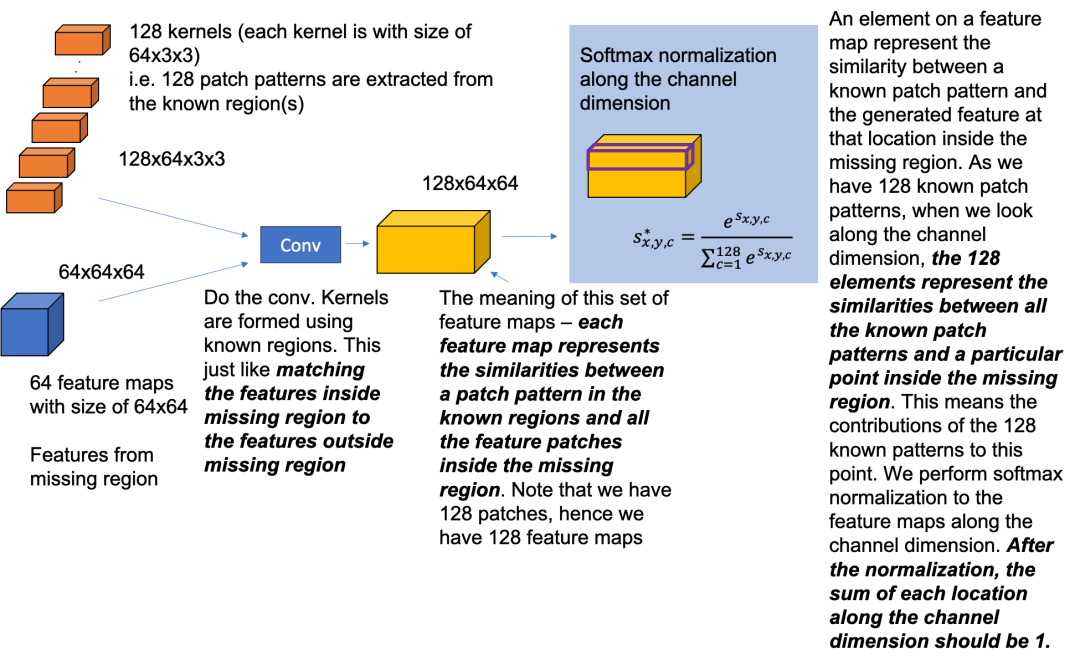
图4,更多关于注意力注意力层的具体例子图4是上下文注意层的一个更详细的示例。如图3所示,前景是指在缺失区域内生成的特征,背景是指从已知区域中提取的特征。与复制粘贴方法类似,我们首先要对缺失区域内生成的特征与缺失区域外的特征进行匹配。以图4为例,生成的缺失区域内的特征大小为64×64×64,假设缺失区域外的特征分为128个小特征patch,大小为64×3×3。注意,本例中特征的通道大小是64。然后,我们将128个小的feature patch与缺失区域内生成的feature进行卷积,得到大小为128×64×64的feature map。在本文中,该操作描述为:
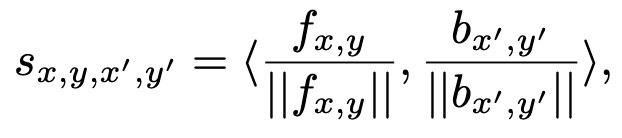
其中{fx,y}为前景patches的特征, {bx‘y’}为背景patches的特征。sx,y,x‘,y’是缺失区域特征和已知区域特征之间的相似性。实际上,这是一个标准的余弦相似度计算过程。当我们沿着通道维数看时,128个元素代表了所有已知patches和缺失区域内特定位置之间的相似性。这反映了128个已知patches对该位置的贡献。然后,我们沿着通道维度对特征映射执行Softmax归一化,如图4中的蓝色区域所示。在Softmax归一化后,沿通道尺寸的每个位置之和应为1。
与上一篇文章中提到的Shift-Net相比,你可以看到,这一次我们给每个已知特征的patch分配了权重,来表示重建的时候每个特征位置对于缺失区域的重要性(软分配),而不是对于缺失区域的每个位置找一个最相似的(硬分配)。这也是为什么提出的上下文注意力是可微的。
最后,以注意力特征图为输入特征,以已知的patches为核,通过反卷积的方法重建缺失区域内生成的特征。
注意力传播
注意力传播可以看作是注意特征图的微调。这里的关键思想是,邻近的像素通常有更接近的像素值。这意味着他们会考虑周围环境的注意力值来调整每个注意力分数。
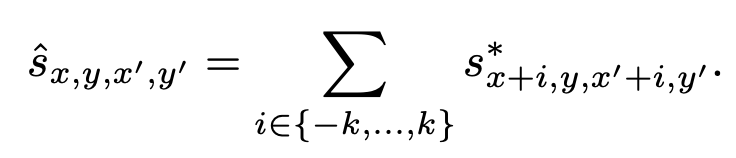
例如,如果我们考虑左邻居和右邻居的注意力值,我们可以使用上面列出的公式更新当前的注意力值。注意,k控制要考虑的邻居的数量。作者声称,这可以进一步提高修复结果,这也可以通过与单位矩阵卷积作为核来实现。关于注意力机制的另一点是,采用了两种技术来控制提取的已知特征块的数量。
(i) 以较大的步长提取已知的特征patch,以减少kernel数量。
(ii) 操作前先对特征图大小进行向下采样,获取注意力图后再进行上采样。
网络中的注意力
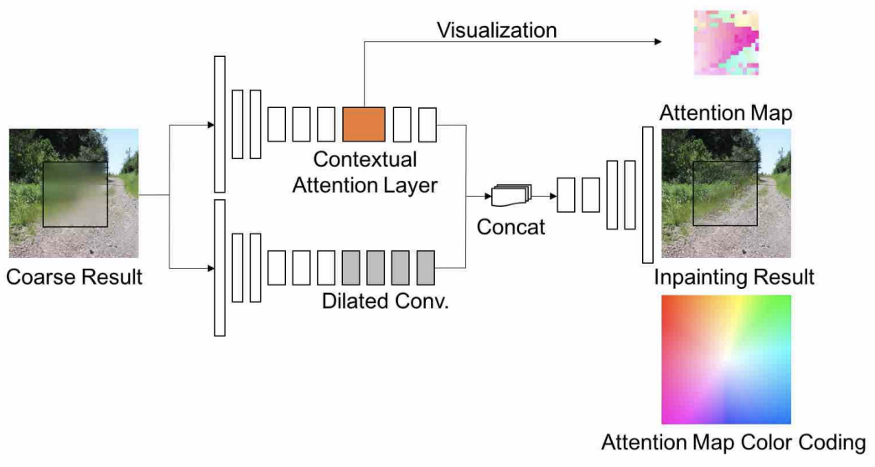
图5,在第二个细化网络中嵌入上下文注意力层的图解
图5显示了作者如何将建议的上下文注意层整合到第二个细化网络中。你可以看到,又引入了一个分支来应用上下文注意力,然后将两个分支连接起来以获得最终的修复结果。注意力图的颜色编码是注意力图的可视化方法。例如,白色意味着像素集中在自己身上,粉色是左下角区域,绿色是右上角区域,等等。你可以看到,这个例子有一个充满粉红色的注意力图。这意味着填充区域从左下角区域借用了很多信息。
实验
作者首先比较了我们之前介绍的先前最先进的技术。

图6,比较提出的基线模型和GLCIC,从左到右,输入图像,GLCIC结果,基线结果图6显示了使用建议的基线模型和以前最先进的GLCIC[2]进行修复的结果。提出的基线模型如图2所示,上下文注意力分支。很明显,基线模型在局部纹理细节方面优于GLCIC模型。请放大看清楚些。

图7,对比基线和完整模型的修复结果。从左到右,ground truth,输入图像,基线结果,全模型结果,全模型注意图图7显示了在Places2数据集上使用基线模型和完整模型(带有上下文注意)的定性结果。可见,完整模型具有较好的局部纹理细节,提供了较好的修复效果。这反映了上下文注意力层可以有效地从遥远的空间位置借用信息来帮助重建缺失的像素。请放大以便更好地观看,特别是注意力图。
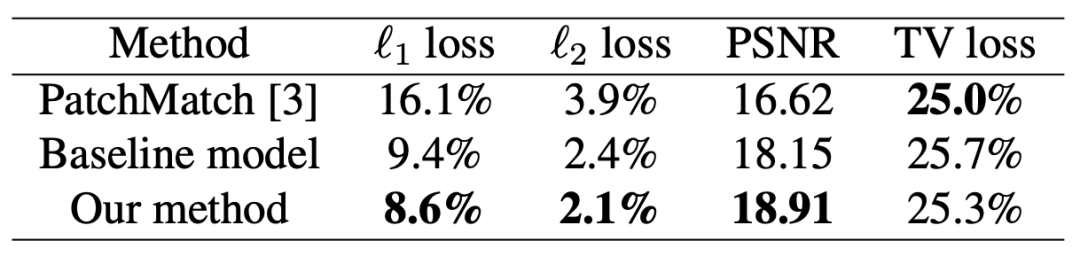
表1,不同方法在Places2数据集上的定量比较表1列出了一些客观的评价指标,供参考。如前所述,这些指标不能完全反映修复结果的质量,因为有许多可能的解决方案来填补缺失的区域。你可以看到,建议的完整模型提供最好的L1, L2损耗和PSNR。对于电视丢失,PatchMatch提供更低的电视丢失,因为它直接复制原始图像patch来填补漏洞。
供参考的全模型参数为2.9M。对于大小为512×512的图像,GPU上每张图像需要0.2秒,CPU上每张图像需要1.5秒。
消融研究
注意力机制并不是一个新概念,文献中有几个注意力模块。作者们用不同的注意力模块做了实验。

图8,通过使用不同的注意力模块进行修复。从左到右:输入,使用空间变换网络的结果,使用外观流的结果,以及使用提出的上下文注意力的结果比较了文献中两个著名的注意力模块,即空间变换网络和外观流。简单来说,对于外观流,使用卷积层代替上下文注意力层,直接预测二维像素偏移量作为注意力。这意味着我们添加一个卷积层来预测已知像素到缺失像素的移动。在图8中,你可以看到使用外观流(中间)为不同的测试图像提供类似的注意力图的结果。这就意味着注意力图对于给予我们想要的“注意力”是没有用的。你也可以观察到空间变换网络(左)不能为图像修复任务提供有意义的注意力图。一个可能的原因是空间变换网络预测全局仿射变换的参数,这并不足以帮助填补缺失的区域,也需要局部信息。这里我没有深入讲解不同的注意力模块。图像修复中GAN损失的选择。作者实验了不同的GAN损失,如WGAN损失,典型的对抗性损失,和最小平方GAN。他们通过经验发现WGAN损失提供了最好的修复效果。重要的重建损失。在不使用L1损失的情况下训练了细化网络。他们发现L1损失对于确保像素级重建精度是必要的,L1损失也会使修复结果变得模糊。因此,L1损失对于保证完整图像更好的内容结构至关重要。
感知损失,风格损失,TV损失。我们将很快说到感知损失和风格损失。一个简单的结论是,这三种损失并没有给修复效果带来明显的改善。因此,他们的模型只使用加权L1损失和WGAN损失进行训练。
总结
显然,本文的核心思想是上下文注意力机制。上下文注意力层嵌入到第二个细化网络中。注意,第一个粗重建网络的作用是对缺失区域进行粗略估计。这种估计用于上下文注意力层。通过匹配缺失区域内生成的特征和缺失区域外生成的特征,我们可以知道缺失区域外所有特征对缺失区域内每个位置的贡献。注意,上下文注意力层是可微的和完全卷积的。
要点
你可能会发现,我们正越来越深入到深度图像修复领域。我在上一篇文章中介绍了Shift连接层,它以硬分配的形式在CNN中嵌入了复制-粘贴的概念。本文以软分配的形式构造了一个上下文注意力层,该层是可微的,并且可以端到端学习,无需修改梯度的计算。希望大家能够掌握本文提出的上下文注意力层的核心思想,特别是图3和图4所示的上下文注意力层公式。
编辑:lyn
-
cnn
+关注
关注
3文章
352浏览量
22203 -
深度图像
+关注
关注
0文章
19浏览量
3506
原文标题:深入探讨深度图像修复的一个突破——上下文注意力
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于因果路径的层次图卷积注意力网络

Llama 3 在自然语言处理中的优势
SystemView上下文统计窗口识别阻塞原因
【《大语言模型应用指南》阅读体验】+ 基础知识学习
鸿蒙Ability Kit(程序框架服务)【应用上下文Context】
编写一个任务调度程序,在上下文切换后遇到了一些问题求解
微信大模型扩容并开源,推出首个中英双语文生图模型,参数规模达15亿
【大语言模型:原理与工程实践】揭开大语言模型的面纱
JPEG LS算法局部梯度值计算原理
基于门控线性网络(GLN)的高压缩比无损医学图像压缩算法






 工商网监
工商网监
评论