 使用Redis时可能遇到哪些「坑」?
使用Redis时可能遇到哪些「坑」?
这篇文章,我想和你聊一聊在使用 Redis 时,可能会踩到的「坑」。
如果你在使用 Redis 时,也遇到过以下这些「诡异」的场景,那很大概率是踩到「坑」了:
明明一个 key 设置了过期时间,怎么变成不过期了?
使用 O(1) 复杂度的 SETBIT 命令,Redis 竟然被 OOM 了?
执行 RANDOMKEY 随机拿出一个 key,竟然也会阻塞 Redis?
同样的命令,为什么主库查不到数据,从库却可以查到?
从库内存为什么比主库用得还多?
写入到 Redis 的数据,为什么莫名其妙丢了?
究竟是什么原因,导致的这些问题呢?
这篇文章,我就来和你盘点一下,使用 Redis 时可能会踩到「坑」,以及如何去规避。
我把这些问题划分成了三大部分:
常见命令有哪些坑?
数据持久化有哪些坑?
主从库同步有哪些坑?
导致这些问题的原因,很有可能会「颠覆」你的认知,如果你准备好了,那就跟着我的思路开始吧!
这篇文章干货很多,希望你可以耐心读完。
常见命令有哪些坑?
首先,我们来看一下,平时在使用 Redis 时,有哪些常见的命令会遇到「意料之外」的结果。
1) 过期时间意外丢失?
你在使用 Redis 时,肯定经常使用 SET 命令,它非常简单。
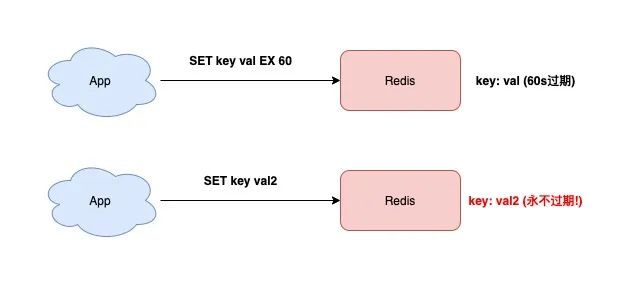
SET 除了可以设置 key-value 之外,还可以设置 key 的过期时间,就像下面这样:
127.0.0.1:6379》 SET testkey val1 EX 60 OK 127.0.0.1:6379》 TTL testkey (integer) 59
此时如果你想修改 key 的值,但只是单纯地使用 SET 命令,而没有加上「过期时间」的参数,那这个 key 的过期时间将会被「擦除」。
127.0.0.1:6379》 SET testkey val2 OK 127.0.0.1:6379》 TTL testkey // key永远不过期了! (integer) -1
看到了么?testkey 变成永远不过期了!
如果你刚刚开始使用 Redis,相信你肯定也踩过这个坑。
导致这个问题的原因在于:SET 命令如果不设置过期时间,那么 Redis 会自动「擦除」这个 key 的过期时间。
如果你发现 Redis 的内存持续增长,而且很多 key 原来设置了过期时间,后来发现过期时间丢失了,很有可能是因为这个原因导致的。
这时你的 Redis 中就会存在大量不过期的 key,消耗过多的内存资源。
所以,你在使用 SET 命令时,如果刚开始就设置了过期时间,那么之后修改这个 key,也务必要加上过期时间的参数,避免过期时间丢失问题。
2) DEL 竟然也会阻塞 Redis?
删除一个 key,你肯定会用 DEL 命令,不知道你没有思考过它的时间复杂度是多少?
O(1)?其实不一定。
如果你有认真阅读 Redis 的官方文档,就会发现:删除一个 key 的耗时,与这个 key 的类型有关。
Redis 官方文档在介绍 DEL 命令时,是这样描述的:
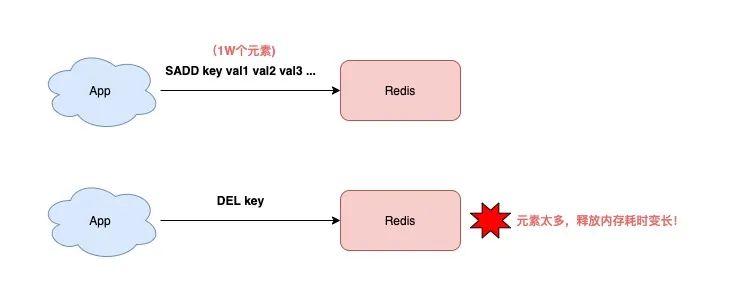
key 是 String 类型,DEL 时间复杂度是 O(1)
key 是 List/Hash/Set/ZSet 类型,DEL 时间复杂度是 O(M),M 为元素数量
也就是说,如果你要删除的是一个非 String 类型的 key,这个 key 的元素越多,那么在执行 DEL 时耗时就越久!
为什么会这样?
原因在于,删除这种 key 时,Redis 需要依次释放每个元素的内存,元素越多,这个过程就会越耗时。
而这么长的操作耗时,势必会阻塞整个 Redis 实例,影响 Redis 的性能。
所以,当你在删除 List/Hash/Set/ZSet 类型的 key 时,一定要格外注意,不能无脑执行 DEL,而是应该用以下方式删除:
查询元素数量:执行 LLEN/HLEN/SCARD/ZCARD 命令
判断元素数量:如果元素数量较少,可直接执行 DEL 删除,否则分批删除
分批删除:执行 LRANGE/HSCAN/SSCAN/ZSCAN + LPOP/RPOP/HDEL/SREM/ZREM 删除
了解了 DEL 对于 List/Hash/Set/ZSet 类型数据的影响,我们再来分析下,删除一个 String 类型的 key 会不会有这种问题?
啊?前面不是提到,Redis 官方文档的描述,删除 String 类型的 key,时间复杂度是 O(1) 么?这不会导致 Redis 阻塞吧?
其实这也不一定!
你思考一下,如果这个 key 占用的内存非常大呢?
例如,这个 key 存储了 500MB 的数据(很明显,它是一个 bigkey),那在执行 DEL 时,耗时依旧会变长!
这是因为,Redis 释放这么大的内存给操作系统,也是需要时间的,所以操作耗时也会变长。
所以,对于 String 类型来说,你最好也不要存储过大的数据,否则在删除它时,也会有性能问题。
此时,你可能会想:Redis 4.0 不是推出了 lazy-free 机制么?打开这个机制,释放内存的操作会放到后台线程中执行,那是不是就不会阻塞主线程了?
这个问题非常好。
真的会是这样吗?
这里我先告诉你结论:即使 Redis 打开了 lazy-free,在删除一个 String 类型的 bigkey 时,它仍旧是在主线程中处理,而不是放到后台线程中执行。所以,依旧有阻塞 Redis 的风险!
这是为什么?
这里先卖一个关子,感兴趣的同学可以先自行查阅 lazy-free 相关资料寻找答案。:)
其实,关于 lazy-free 的知识点也很多,由于篇幅原因,所以我打算后面专门写一篇文章来讲,欢迎持续关注~
3) RANDOMKEY 竟然也会阻塞 Redis?
如果你想随机查看 Redis 中的一个 key,通常会使用 RANDOMKEY 这个命令。
这个命令会从 Redis 中「随机」取出一个 key。
既然是随机,那这个执行速度肯定非常快吧?
其实不然。
要解释清楚这个问题,就要结合 Redis 的过期策略来讲。
如果你对 Redis 的过期策略有所了解,应该知道 Redis 清理过期 key,是采用定时清理 + 懒惰清理 2 种方式结合来做的。
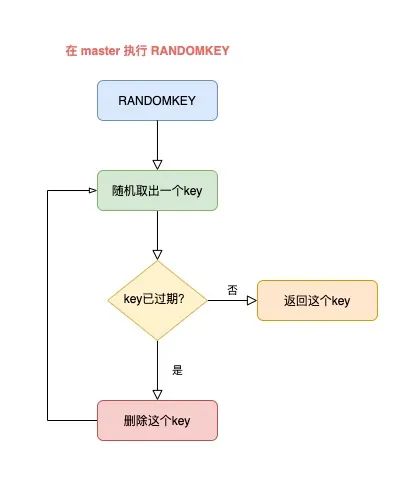
而 RANDOMKEY 在随机拿出一个 key 后,首先会先检查这个 key 是否已过期。
如果该 key 已经过期,那么 Redis 会删除它,这个过程就是懒惰清理。
但清理完了还不能结束,Redis 还要找出一个「不过期」的 key,返回给客户端。
此时,Redis 则会继续随机拿出一个 key,然后再判断是它否过期,直到找出一个未过期的 key 返回给客户端。
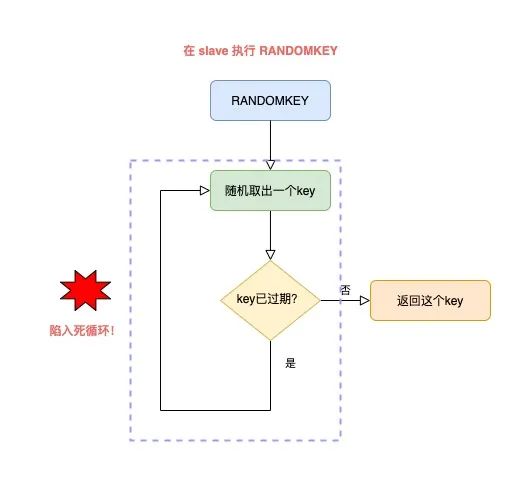
整个流程就是这样的:
master 随机取出一个 key,判断是否已过期
如果 key 已过期,删除它,继续随机取 key
以此循环往复,直到找到一个不过期的 key,返回
但这里就有一个问题了:如果此时 Redis 中,有大量 key 已经过期,但还未来得及被清理掉,那这个循环就会持续很久才能结束,而且,这个耗时都花费在了清理过期 key + 寻找不过期 key 上。
导致的结果就是,RANDOMKEY 执行耗时变长,影响 Redis 性能。
以上流程,其实是在 master 上执行的。
如果在 slave 上执行 RANDOMEKY,那么问题会更严重!
为什么?
主要原因就在于,slave 自己是不会清理过期 key。
那 slave 什么时候删除过期 key 呢?
其实,当一个 key 要过期时,master 会先清理删除它,之后 master 向 slave 发送一个 DEL 命令,告知 slave 也删除这个 key,以此达到主从库的数据一致性。
还是同样的场景:Redis 中存在大量已过期,但还未被清理的 key,那在 slave 上执行 RANDOMKEY 时,就会发生以下问题:
slave 随机取出一个 key,判断是否已过期
key 已过期,但 slave 不会删除它,而是继续随机寻找不过期的 key
由于大量 key 都已过期,那 slave 就会寻找不到符合条件的 key,此时就会陷入「死循环」!
也就是说,在 slave 上执行 RANDOMKEY,有可能会造成整个 Redis 实例卡死!
是不是没想到?在 slave 上随机拿一个 key,竟然有可能造成这么严重的后果?
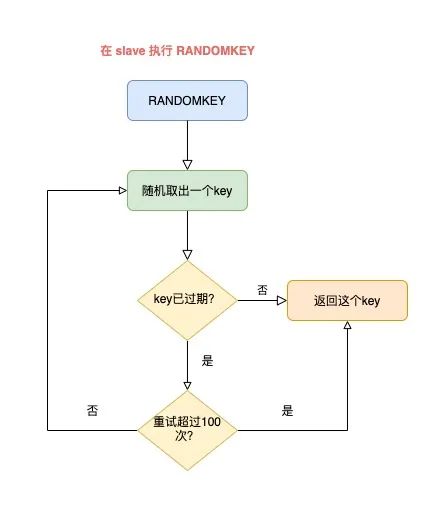
这其实是 Redis 的一个 Bug,这个 Bug 一直持续到 5.0 才被修复。
修复的解决方案是,在 slave 上执行 RANDOMKEY 时,会先判断整个实例所有 key 是否都设置了过期时间,如果是,为了避免长时间找不到符合条件的 key,slave 最多只会在哈希表中寻找 100 次,无论是否能找到,都会退出循环。
这个方案就是增加上了一个最大重试次数,这样一来,就避免了陷入死循环。
虽然这个方案可以避免了 slave 陷入死循环、卡死整个实例的问题,但是,在 master 上执行这个命令时,依旧有概率导致耗时变长。
所以,你在使用 RANDOMKEY 时,如果发现 Redis 发生了「抖动」,很有可能是因为这个原因导致的!
4) O(1) 复杂度的 SETBIT,竟然会导致 Redis OOM?
在使用 Redis 的 String 类型时,除了直接写入一个字符串之外,还可以把它当做 bitmap 来用。
具体来讲就是,我们可以把一个 String 类型的 key,拆分成一个个 bit 来操作,就像下面这样:
127.0.0.1:6379》 SETBIT testkey 10 1 (integer) 1 127.0.0.1:6379》 GETBIT testkey 10 (integer) 1
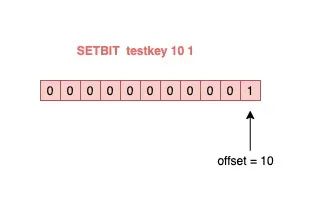
其中,操作的每一个 bit 位叫做 offset。
但是,这里有一个坑,你需要注意起来。
如果这个 key 不存在,或者 key 的内存使用很小,此时你要操作的 offset 非常大,那么 Redis 就需要分配「更大的内存空间」,这个操作耗时就会变长,影响性能。
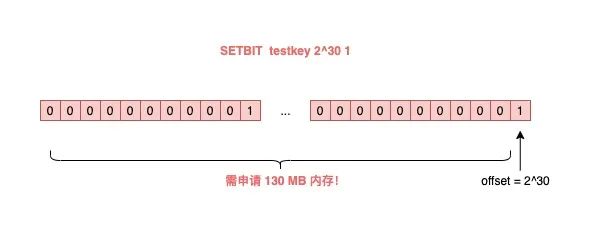
所以,当你在使用 SETBIT 时,也一定要注意 offset 的大小,操作过大的 offset 也会引发 Redis 卡顿。
这种类型的 key,也是典型的 bigkey,除了分配内存影响性能之外,在删除它时,耗时同样也会变长。
5) 执行 MONITOR 也会导致 Redis OOM?
这个坑你肯定听说过很多次了。
当你在执行 MONITOR 命令时,Redis 会把每一条命令写到客户端的「输出缓冲区」中,然后客户端从这个缓冲区读取服务端返回的结果。
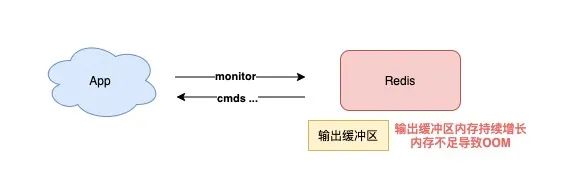
但是,如果你的 Redis QPS 很高,这将会导致这个输出缓冲区内存持续增长,占用 Redis 大量的内存资源,如果恰好你的机器的内存资源不足,那 Redis 实例就会面临被 OOM 的风险。
所以,你需要谨慎使用 MONITOR,尤其在 QPS 很高的情况下。
以上这些问题场景,都是我们在使用常见命令时发生的,而且,很可能都是「无意」就会触发的。
下面我们来看 Redis「数据持久化」都存在哪些坑?
数据持久化有哪些坑?
Redis 的数据持久化,分为 RDB 和 AOF 两种方式。
其中,RDB 是数据快照,而 AOF 会记录每一个写命令到日志文件中。
在数据持久化方面发生问题,主要也集中在这两大块,我们依次来看。
1) master 宕机,slave 数据也丢失了?
如果你的 Redis 采用如下模式部署,就会发生数据丢失的问题:
master-slave + 哨兵部署实例
master 没有开启数据持久化功能
Redis 进程使用 supervisor 管理,并配置为「进程宕机,自动重启」
如果此时 master 宕机,就会导致下面的问题:
master 宕机,哨兵还未发起切换,此时 master 进程立即被 supervisor 自动拉起
但 master 没有开启任何数据持久化,启动后是一个「空」实例
此时 slave 为了与 master 保持一致,它会自动「清空」实例中的所有数据,slave 也变成了一个「空」实例
看到了么?在这个场景下,master / slave 的数据就全部丢失了。
这时,业务应用在访问 Redis 时,发现缓存中没有任何数据,就会把请求全部打到后端数据库上,这还会进一步引发「缓存雪崩」,对业务影响非常大。
所以,你一定要避免这种情况发生,我给你的建议是:
Redis 实例不使用进程管理工具自动拉起
master 宕机后,让哨兵发起切换,把 slave 提升为 master
切换完成后,再重启 master,让其退化成 slave
你在配置数据持久化时,要避免这个问题的发生。
2) AOF everysec 真的不会阻塞主线程吗?
当 Redis 开启 AOF 时,需要配置 AOF 的刷盘策略。
基于性能和数据安全的平衡,你肯定会采用 appendfsync everysec 这种方案。
这种方案的工作模式为,Redis 的后台线程每间隔 1 秒,就把 AOF page cache 的数据,刷到磁盘(fsync)上。
这种方案的优势在于,把 AOF 刷盘的耗时操作,放到了后台线程中去执行,避免了对主线程的影响。
但真的不会影响主线程吗?
答案是否定的。
其实存在这样一种场景:Redis 后台线程在执行 AOF page cache 刷盘(fysnc)时,如果此时磁盘 IO 负载过高,那么调用 fsync 就会被阻塞住。
此时,主线程仍然接收写请求进来,那么此时的主线程会先判断,上一次后台线程是否已刷盘成功。
如何判断呢?
后台线程在刷盘成功后,都会记录刷盘的时间。
主线程会根据这个时间来判断,距离上一次刷盘已经过去多久了。整个流程是这样的:
主线程在写 AOF page cache(write系统调用)前,先检查后台 fsync 是否已完成?
fsync 已完成,主线程直接写 AOF page cache
fsync 未完成,则检查距离上次 fsync 过去多久?
如果距离上次 fysnc 成功在 2 秒内,那么主线程会直接返回,不写 AOF page cache
如果距离上次 fysnc 成功超过了 2 秒,那主线程会强制写 AOF page cache(write系统调用)
由于磁盘 IO 负载过高,此时,后台线程 fynsc 会发生阻塞,那主线程在写 AOF page cache 时,也会发生阻塞等待(操作同一个 fd,fsync 和 write 是互斥的,一方必须等另一方成功才可以继续执行,否则阻塞等待)
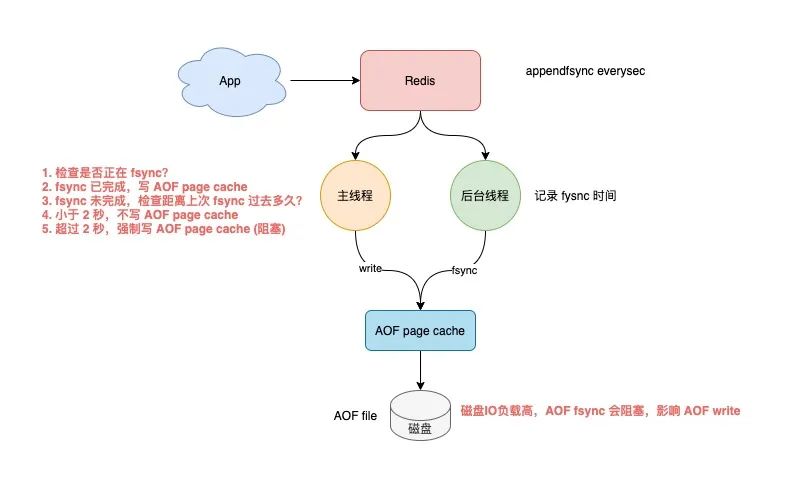
通过分析我们可以发现,即使你配置的 AOF 刷盘策略是 appendfsync everysec,也依旧会有阻塞主线程的风险。
其实,产生这个问题的重点在于,磁盘 IO 负载过高导致 fynsc 阻塞,进而导致主线程写 AOF page cache 也发生阻塞。
所以,你一定要保证磁盘有充足的 IO 资源,避免这个问题。
3) AOF everysec 真的只会丢失 1 秒数据?
接着上面的问题继续分析。
如上所述,这里我们需要重点关注上面的步骤 4。
也就是:主线程在写 AOF page cache 时,会先判断上一次 fsync 成功的时间,如果距离上次 fysnc 成功在 2 秒内,那么主线程会直接返回,不再写 AOF page cache。
这就意味着,后台线程在执行 fsync 刷盘时,主线程最多等待 2 秒不会写 AOF page cache。
如果此时 Redis 发生了宕机,那么,AOF 文件中丢失是 2 秒的数据,而不是 1 秒!
我们继续分析,Redis 主线程为什么要等待 2 秒不写 AOF page cache 呢?
其实,Redis AOF 配置为 appendfsync everysec 时,正常来讲,后台线程每隔 1 秒执行一次 fsync 刷盘,如果磁盘资源充足,是不会被阻塞住的。
也就是说,Redis 主线程其实根本不用关心后台线程是否刷盘成功,只要无脑写 AOF page cache 即可。
但是,Redis 作者考虑到,如果此时的磁盘 IO 资源比较紧张,那么后台线程 fsync 就有概率发生阻塞风险。
所以,Redis 作者在主线程写 AOF page cache 之前,先检查一下距离上一次 fsync 成功的时间,如果大于 1 秒没有成功,那么主线程此时就能知道,fsync 可能阻塞了。
所以,主线程会等待 2 秒不写 AOF page cache,其目的在于:
降低主线程阻塞的风险(如果无脑写 AOF page cache,主线程则会立即阻塞住)
如果 fsync 阻塞,主线程就会给后台线程留出 1 秒的时间,等待 fsync 成功
但代价就是,如果此时发生宕机,AOF 丢失的就是 2 秒的数据,而不是 1 秒。
这个方案应该是 Redis 作者对性能和数据安全性的进一步权衡。
无论如何,这里你只需要知道的是,即使 AOF 配置为每秒刷盘,在发生上述极端情况时,AOF 丢失的数据其实是 2 秒。
4) RDB 和 AOF rewrite 时,Redis 发生 OOM?
最后,我们来看一下,当 Redis 在执行 RDB 快照和 AOF rewrite 时,会发生的问题。
Redis 在做 RDB 快照和 AOF rewrite 时,会采用创建子进程的方式,把实例中的数据持久化到磁盘上。
创建子进程,会调用操作系统的 fork 函数。
fork 执行完成后,父进程和子进程会同时共享同一份内存数据。
但此时的主进程依旧是可以接收写请求的,而进来的写请求,会采用 Copy On Write(写时复制)的方式操作内存数据。
也就是说,主进程一旦有数据需要修改,Redis 并不会直接修改现有内存中的数据,而是先将这块内存数据拷贝出来,再修改这块新内存的数据,这就是所谓的「写时复制」。
写时复制你也可以理解成,谁需要发生写操作,谁就先拷贝,再修改。
你应该发现了,如果父进程要修改一个 key,就需要拷贝原有的内存数据,到新内存中,这个过程涉及到了「新内存」的申请。
如果你的业务特点是「写多读少」,而且 OPS 非常高,那在 RDB 和 AOF rewrite 期间,就会产生大量的内存拷贝工作。
这会有什么问题呢?
因为写请求很多,这会导致 Redis 父进程会申请非常多的内存。在这期间,修改 key 的范围越广,新内存的申请就越多。
如果你的机器内存资源不足,这就会导致 Redis 面临被 OOM 的风险!
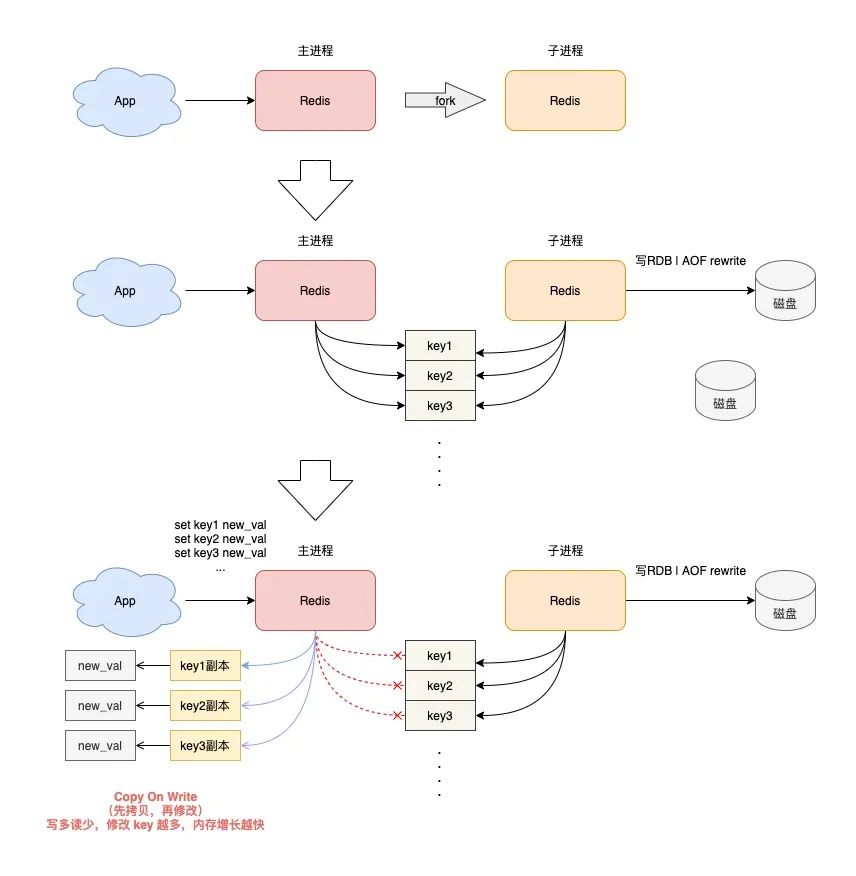
这就是你会从 DBA 同学那里听到的,要给 Redis 机器预留内存的原因。
其目的就是避免在 RDB 和 AOF rewrite 期间,防止 Redis OOM。
以上这些,就是「数据持久化」会遇到的坑,你踩到过几个?
下面我们再来看「主从复制」会存在哪些问题。
主从复制有哪些坑?
Redis 为了保证高可用,提供了主从复制的方式,这样就可以保证 Redis 有多个「副本」,当主库宕机后,我们依旧有从库可以使用。
在主从同步期间,依旧存在很多坑,我们依次来看。
1) 主从复制会丢数据吗?
首先,你需要知道,Redis 的主从复制是采用「异步」的方式进行的。
这就意味着,如果 master 突然宕机,可能存在有部分数据还未同步到 slave 的情况发生。
这会导致什么问题呢?
如果你把 Redis 当做纯缓存来使用,那对业务来说没有什么影响。
master 未同步到 slave 的数据,业务应用可以从后端数据库中重新查询到。
但是,对于把 Redis 当做数据库,或是当做分布式锁来使用的业务,有可能因为异步复制的问题,导致数据丢失 / 锁丢失。
关于 Redis 分布式锁可靠性的更多细节,这里先不展开,后面会单独写一篇文章详细剖析这个知识点。这里你只需要先知道,Redis 主从复制是有概率发生数据丢失的。
2) 同样命令查询一个 key,主从库却返回不同的结果?
不知道你是否思考过这样一个问题:如果一个 key 已过期,但这个 key 还未被 master 清理,此时在 slave 上查询这个 key,会返回什么结果呢?
slave 正常返回 key 的值
slave 返回 NULL
你认为是哪一种?可以思考一下。
答案是:不一定。
嗯?为什么会不一定?
这个问题非常有意思,请跟紧我的思路,我会带你一步步分析其中的原因。
其实,返回什么结果,这要取决于以下 3 个因素:
Redis 的版本
具体执行的命令
机器时钟
先来看 Redis 版本。
如果你使用的是 Redis 3.2 以下版本,只要这个 key 还未被 master 清理,那么,在 slave 上查询这个 key,它会永远返回 value 给你。
也就是说,即使这个 key 已过期,在 slave 上依旧可以查询到这个 key。
// Redis 2.8 版本 在 slave 上执行 127.0.0.1:6479》 TTL testkey (integer) -2 // 已过期 127.0.0.1:6479》 GET testkey “testval” // 还能查询到!
但如果此时在 master 上查询这个 key,发现已经过期,就会把它清理掉,然后返回 NULL。
// Redis 2.8 版本 在 master 上执行 127.0.0.1:6379》 TTL testkey (integer) -2 127.0.0.1:6379》 GET testkey (nil)
发现了吗?在 master 和 slave 上查询同一个 key,结果竟然不一样?
其实,slave 应该要与 master 保持一致,key 已过期,就应该给客户端返回 NULL,而不是还正常返回 key 的值。
为什么会发生这种情况?
其实这是 Redis 的一个 Bug:3.2 以下版本的 Redis,在 slave 上查询一个 key 时,并不会判断这个 key 是否已过期,而是直接无脑返回给客户端结果。
这个 Bug 在 3.2 版本进行了修复,但是,它修复得「不够彻底」。
什么叫修复得「不够彻底」?
这就要结合前面提到的,第 2 个影响因素「具体执行的命令」来解释了。
Redis 3.2 虽然修复了这个 Bug,但却遗漏了一个命令:EXISTS。
也就是说,一个 key 已过期,在 slave 直接查询它的数据,例如执行 GET/LRANGE/HGETALL/SMEMBERS/ZRANGE 这类命令时,slave 会返回 NULL。
但如果执行的是 EXISTS,slave 依旧会返回:key 还存在。
// Redis 3.2 版本 在 slave 上执行 127.0.0.1:6479》 GET testkey (nil) // key 已逻辑过期 127.0.0.1:6479》 EXISTS testkey (integer) 1 // 还存在!
原因在于,EXISTS 与查询数据的命令,使用的不是同一个方法。
Redis 作者只在查询数据时增加了过期时间的校验,但 EXISTS 命令依旧没有这么做。
直到 Redis 4.0.11 这个版本,Redis 才真正把这个遗漏的 Bug 完全修复。
如果你使用的是这个之上的版本,那在 slave 上执行数据查询或 EXISTS,对于已过期的 key,就都会返回「不存在」了。
这里我们先小结一下,slave 查询过期 key,经历了 3 个阶段:
3.2 以下版本,key 过期未被清理,无论哪个命令,查询 slave,均正常返回 value
3.2 - 4.0.11 版本,查询数据返回 NULL,但 EXISTS 依旧返回 true
4.0.11 以上版本,所有命令均已修复,过期 key 在 slave 上查询,均返回「不存在」
这里要特别鸣谢《Redis开发与运维》的作者,付磊。
这个问题我是在他的文章中看到的,感觉非常有趣,原来 Redis 之前还存在这样的 Bug 。随后我又查阅了相关源码,并对逻辑进行了梳理,在这里才写成文章分享给大家。
虽然已在微信中亲自答谢,但在这里再次表达对他的谢意~
最后,我们来看影响查询结果的第 3 个因素:「机器时钟」。
假设我们已规避了上面提到的版本 Bug,例如,我们使用 Redis 5.0 版本,在 slave 查询一个 key,还会和 master 结果不同吗?
答案是,还是有可能会的。
这就与 master / slave 的机器时钟有关了。
无论是 master 还是 slave,在判断一个 key 是否过期时,都是基于「本机时钟」来判断的。
如果 slave 的机器时钟比 master 走得「快」,那就会导致,即使这个 key 还未过期,但以 slave 上视角来看,这个 key 其实已经过期了,那客户端在 slave 上查询时,就会返回 NULL。
是不是很有意思?一个小小的过期 key,竟然藏匿这么多猫腻。
如果你也遇到了类似的情况,就可以通过上述步骤进行排查,确认是否踩到了这个坑。
3) 主从切换会导致缓存雪崩?
这个问题是上一个问题的延伸。
我们假设,slave 的机器时钟比 master 走得「快」,而且是「快很多」。
此时,从 slave 角度来看,Redis 中的数据存在「大量过期」。
如果此时操作「主从切换」,把 slave 提升为新的 master。
它成为 master 后,就会开始大量清理过期 key,此时就会导致以下结果:
master 大量清理过期 key,主线程发生阻塞,无法及时处理客户端请求
Redis 中数据大量过期,引发缓存雪崩
你看,当 master / slave 机器时钟严重不一致时,对业务的影响非常大!
所以,如果你是 DBA 运维,一定要保证主从库的机器时钟一致性,避免发生这些问题。
4) master / slave 大量数据不一致?
还有一种场景,会导致 master / slave 的数据存在大量不一致。
这就涉及到 Redis 的 maxmemory 配置了。
Redis 的 maxmemory 可以控制整个实例的内存使用上限,超过这个上限,并且配置了淘汰策略,那么实例就开始淘汰数据。
但这里有个问题:假设 master / slave 配置的 maxmemory 不一样,那此时就会发生数据不一致。
例如,master 配置的 maxmemory 为 5G,而 slave 的 maxmemory 为 3G,当 Redis 中的数据超过 3G 时,slave 就会「提前」开始淘汰数据,此时主从库数据发生不一致。
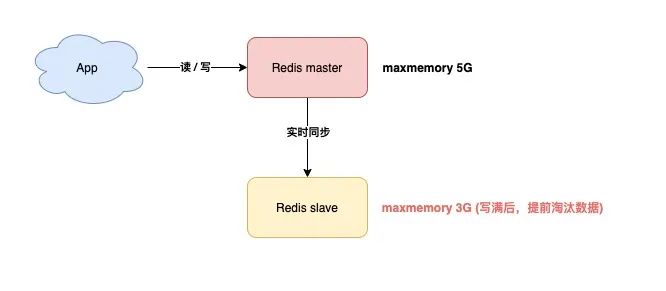
另外,尽管 master / slave 设置的 maxmemory 相同,如果你要调整它们的上限,也要格外注意,否则也会导致 slave 淘汰数据:
调大 maxmemory 时,先调整 slave,再调整 master
调小 maxmemory 时,先调整 master,再调整 slave
以此方式操作,就避免了 slave 提前超过 maxmemory 的问题。
其实,你可以思考一下,发生这些问题的关键在哪?
其根本原因在于,slave 超过 maxmemory 后,会「自行」淘汰数据。
如果不让 slave 自己淘汰数据,那这些问题是不是都可以规避了?
没错。
针对这个问题,Redis 官方应该也收到了很多用户的反馈。在 Redis 5.0 版本,官方终于把这个问题彻底解决了!
Redis 5.0 增加了一个配置项:replica-ignore-maxmemory,默认 yes。
这个参数表示,尽管 slave 内存超过了 maxmemory,也不会自行淘汰数据了!
这样一来,slave 永远会向 master 看齐,只会老老实实地复制 master 发送过来的数据,不会自己再搞「小动作」。
至此,master / slave 的数据就可以保证完全一致了!
如果你使用的恰好是 5.0 版本,就不用担心这个问题了。
5) slave 竟然会有内存泄露问题?
是的,你没看错。
这是怎么发生的?我们具体来看一下。
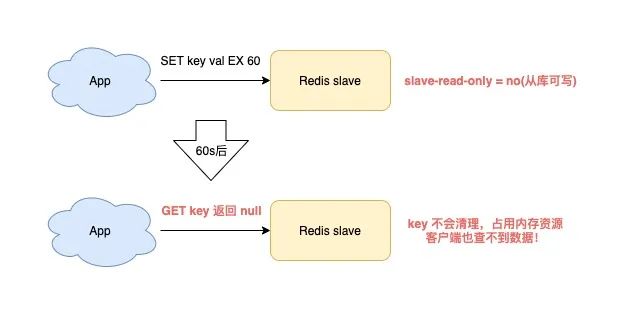
当你在使用 Redis 时,符合以下场景,就会触发 slave 内存泄露:
Redis 使用的是 4.0 以下版本
slave 配置项为 read-only=no(从库可写)
向 slave 写入了有过期时间的 key
这时的 slave 就会发生内存泄露:slave 中的 key,即使到了过期时间,也不会自动清理。
如果你不主动删除它,那这些 key 就会一直残留在 slave 内存中,消耗 slave 的内存。
最麻烦的是,你使用命令查询这些 key,却还查不到任何结果!
这就 slave 「内存泄露」问题。
这其实也是 Redis 的一个 Bug,Redis 4.0 才修复了这个问题。
解决方案是,在可写的 slave 上,写入带有过期时间 key 时,slave 会「记录」下来这些 key。
然后 slave 会定时扫描这些 key,如果到达过期时间,则清理之。
如果你的业务需要在 slave 上临时存储数据,而且这些 key 也都设置了过期时间,那么就要注意这个问题了。
你需要确认你的 Redis 版本,如果是 4.0 以下版本,一定要避免踩这个坑。
其实,最好的方案是,制定一个 Redis 使用规范,slave 必须强制设置为 read-only,不允许写,这样不仅可以保证 master / slave 的数据一致性,还避免了 slave 内存泄露问题。
6) 为什么主从全量同步一直失败?
在主从全量同步时,你可能会遇到同步失败的问题,具体场景如下:
slave 向 master 发起全量同步请求,master 生成 RDB 后发给 slave,slave 加载 RDB。
由于 RDB 数据太大,slave 加载耗时也会变得很长。
此时你会发现,slave 加载 RDB 还未完成,master 和 slave 的连接却断开了,数据同步也失败了。
之后你又会发现,slave 又发起了全量同步,master 又生成 RDB 发送给 slave。
同样地,slave 在加载 RDB 时,master / slave 同步又失败了,以此往复。
这是怎么回事?
其实,这就是 Redis 的「复制风暴」问题。
什么是复制风暴?
就像刚才描述的:主从全量同步失败,又重新开始同步,之后又同步失败,以此往复,恶性循环,持续浪费机器资源。
为什么会导致这种问题呢?
如果你的 Redis 有以下特点,就有可能发生这种问题:
master 的实例数据过大,slave 在加载 RDB 时耗时太长
复制缓冲区(slave client-output-buffer-limit)配置过小
master 写请求量很大
主从在全量同步数据时,master 接收到的写请求,会先写到主从「复制缓冲区」中,这个缓冲区的「上限」是配置决定的。
当 slave 加载 RDB 太慢时,就会导致 slave 无法及时读取「复制缓冲区」的数据,这就引发了复制缓冲区「溢出」。
为了避免内存持续增长,此时的 master 会「强制」断开 slave 的连接,这时全量同步就会失败。
之后,同步失败的 slave 又会「重新」发起全量同步,进而又陷入上面描述的问题中,以此往复,恶性循环,这就是所谓的「复制风暴」。
如何解决这个问题呢?我给你以下几点建议:
Redis 实例不要太大,避免过大的 RDB
复制缓冲区配置的尽量大一些,给 slave 加载 RDB 留足时间,降低全量同步失败的概率
如果你也踩到了这个坑,可以通过这个方案来解决。
总结
好了,总结一下,这篇文章我们主要讲了 Redis 在「命令使用」、「数据持久化」、「主从同步」3 个方面可能存在的「坑」。
怎么样?有没有颠覆你的认知呢?
这篇文章信息量还是比较大的,如果你现在的思维已经有些「凌乱」了,别急,我也给你准备好了思维导图,方便你更好地理解和记忆。
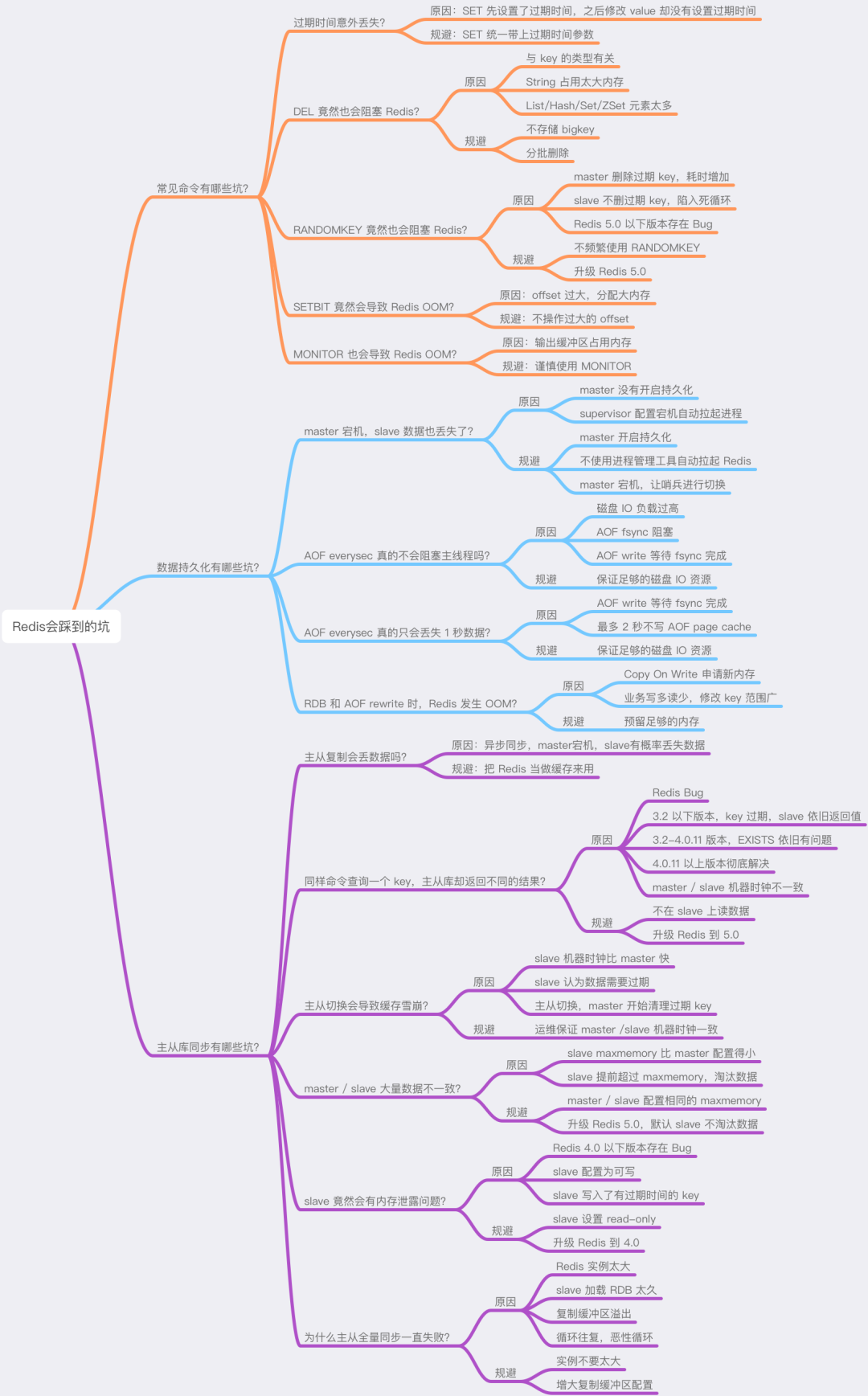
希望你在使用 Redis 时,可以提前规避这些坑,让 Redis 更好地提供服务。
后记
最后,我想和你聊一聊在开发过程中,关于踩坑的经验和心得。
其实,接触任何一个新领域,都会经历陌生、熟悉、踩坑、吸收经验、游刃有余这几个阶段。
那在踩坑这个阶段,如何少踩坑?或者踩坑后如何高效率地排查问题呢?
这里我总结出了 4 个方面,应该可以帮助到你:
1) 多看官方文档 + 配置文件的注释
一定要多看官方文档,以及配置文件的注释说明。其实很多可能存在风险的地方,优秀的软件都会在文档和注释里提示你的,认真读一读,可以提前规避很多基础问题。
2) 不放过疑问细节,多思考为什么?
永远要保持好奇心。遇到问题,掌握剥丝抽茧,逐步定位问题的能力,时刻保持探寻事物问题本质的心态。
3) 敢于提出质疑,源码不会骗人
如果你觉得一个问题很蹊跷,可能是一个 Bug,要敢于提出质疑。
通过源码寻找问题的真相,这种方式要好过你看一百篇网上互相抄袭的文章(抄来抄去很有可能都是错的)。
4) 没有完美的软件,优秀软件都是一步步迭代出来的
任何优秀的软件,都是一步步迭代出来的。在迭代过程中,存在 Bug 很正常,我们需要抱着正确的心态去看待它。
这些经验和心得,适用于学习任何领域,希望对你有所帮助。
原文标题:Redis 会遇到的15个「坑」,你踩过几个?
文章出处:【微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
命令
+关注
关注
5文章
705浏览量
22218 -
Redis
+关注
关注
0文章
380浏览量
11034
原文标题:Redis 会遇到的15个「坑」,你踩过几个?
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Redis实战笔记

华为云 Flexus X 加速 Redis 案例实践与详解
Redis Cluster之故障转移
华为云Flexus X实例,Redis性能加速评测及对比
Redis缓存与Memcached的比较
Redis 开源协议调整,我们怎么办?
Redis 开源社区持续壮大,华为云为 Valkey 项目注入新的活力
Redis为什么这么快?
Redis开源版与Redis企业版,怎么选用?

数据安全没保障?GaussDB(for Redis) 为你保驾护航
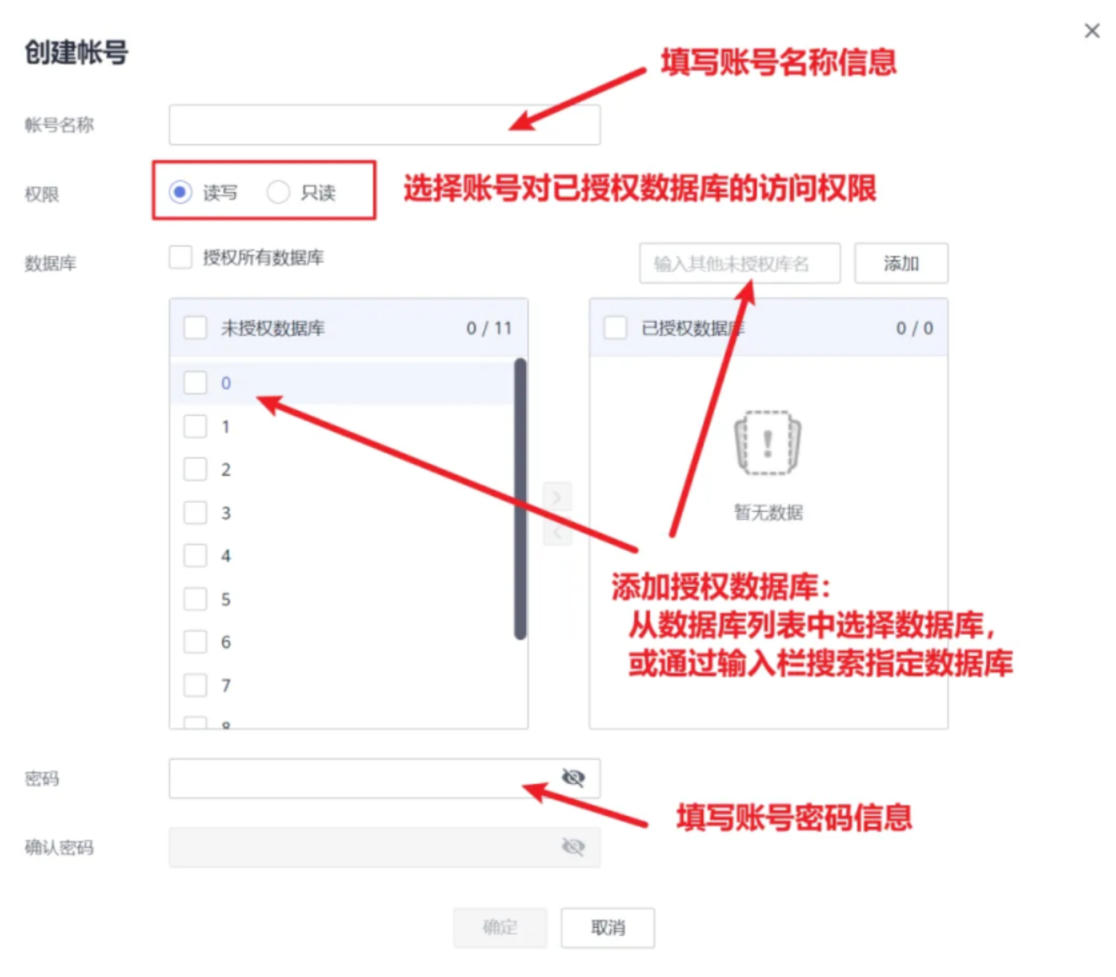
GaussDB(for Redis) 特性揭秘:多租户管理

GaussDB(for Redis) 特性揭秘:大 key 治理

GaussDB(for Redis) 游戏实践:玩家下线行为上报
新版 Redis 不再“开源”,对使用者都有哪些影响?





 工商网监
工商网监
评论