 图神经网络的解释性综述
图神经网络的解释性综述
图神经网络的可解释性是目前比较值得探索的方向,今天解读的2021最新综述,其针对近期提出的 GNN 解释技术进行了系统的总结和分析,归纳对比了该问题的解决思路。作者还为GNN解释性问题提供了标准的图数据集和评估指标,将是这一方向非常值得参考的一篇文章。
论文标题:Explainability in Graph Neural Networks: A Taxonomic Survey
论文地址:https://arxiv.org/pdf/2012.15445.pdf
参考文献
0.Abstract近年来,深度学习模型的可解释性研究在图像和文本领域取得了显著进展。然而,在图数据领域,既没有针对GNN可解释性的统一处理方法,也不存在标准的 benchmark 数据集和评估准则。在这篇论文中,作者对目前的GNN解释技术从统一和分类的角度进行了总结,阐明了现有方法的共性和差异,并为进一步的方法发展奠定了基础。此外,作者专门为GNN解释技术生成了 benchmark 图数据集,并总结了当前用于评估GNN解释技术的数据集和评估方法。
1. Introduction解释黑箱模型是十分必要的:如果没有对预测背后的底层机制进行推理,深层模型就无法得到完全信任,这就阻碍了深度模型在与公平性、隐私性和安全性有关的关键应用程序中使用。为了安全、可信地部署深度模型,需要同时提供准确的预测和人类能领会的解释,特别是对于跨学科领域的用户。
深层模型的解释技术通常从研究其预测背后的潜在关系着手,解释技术大致可分为两类:
1)input-dependent explanations(依赖输入的解释方法)
该类方法从特征的角度出发,提供与输入相关的解释,例如研究输入特征的重要性得分,或对深层模型的一般行为有高水平的理解。论文 [10],[11],[18]通过研究梯度或权重,分析预测结果相对于输入特征的敏感程度。论文 [12],[13],[19] 通过将隐藏特征映射到输入空间,从而突出重要的输入特征。[14] 通过遮蔽不同的输入特征,观察预测的变化,以识别重要的特征。
2)input-independent explanations(独立于输入的解释方法)
与依赖特征的解释方法不同,该类方法从模型角度出发,提供独立于输入的解释,例如研究输入 patterns,使某类的预测得分最大化。论文[17],[22]通过探究隐藏神经元的含义,进而理解的整个预测过程。论文[23],[24],[25],[26] 对近期的方法进行了较为系统的评价和分类。然而,这些研究只关注图像和文本领域的解释方法,忽略了深度图模型的可解释性。
GNN 的可解释性
与图像和文本领域相比,对图模型解释性的研究较少,然而这是理解深度图神经网络的关键。近年来,人们提出了几种解释 GNN 预测的方法,如XGNN[41]、gnexplainer[42]、PGExplainer[43]等。这些方法是从不同的角度提供了不同层次的解释。但至今仍然**缺乏标准的数据集和度量来评估解释结果。**因此,需要对GNN解释技术和其评估方法进行系统的研究。
本文
本研究提供了对不同GNN解释技术的系统研究,目的对不同方法进行直观和高水平的解释,论文贡献如下:
对现有的深度图模型的解释技术进行了系统和全面的回顾。
提出了现有GNN解释技术的新型分类框架,总结了每个类别的关键思想,并进行了深刻的分析。
详细介绍了每种GNN解释方法,包括其方法论、优势、缺点,与其他方法的区别。
总结了GNN解释任务中常用的数据集和评价指标,讨论了它们的局限性,并提出了几点建议。
通过将句子转换为图,针对文本领域构建了三个人类可理解的数据集。这些数据集即将公开,可以直接用于GNN解释任务。
名词解释:Explainability versus Interpretability
在一些研究中,“explainability” 和 “interpretability”被交替使用。本文作者认为这两个术语应该被区分开来,遵循论文[44]来区分这两个术语。如果一个模型本身能够对其预测提供人类可理解的解释,则认为这个模型是 “interpretable”。注意,这样的模型在某种程度上不再是一个黑盒子。例如,一个决策树模型就是一个 “interpretable“的模型。同时,”explainable “模型意味着该模型仍然是一个黑盒子,其预测有可能被一些事后解释技术所理解。
2. 总体框架目前存在一系列针对深度图模型解释性问题的工作,这些方法关注图模型的不同方面,并提供不同的观点来理解这些模型。它们一般都会从几个问题出发实现对图模型的解释:哪些输入边更重要?哪些输入节点更重要? 哪些节点特征更重要?什么样的图模式会最大限度地预测某个类?为了更好地理解这些方法,本文为GNNs的不同解释技术提供了分类框架,结构如图1所示。根据提供什么类型的解释,解释性技术被分为两大类:实例级方法和模型级方法。本文接下来的部分将针对图1的各个分支展开讲解,并作出对比。
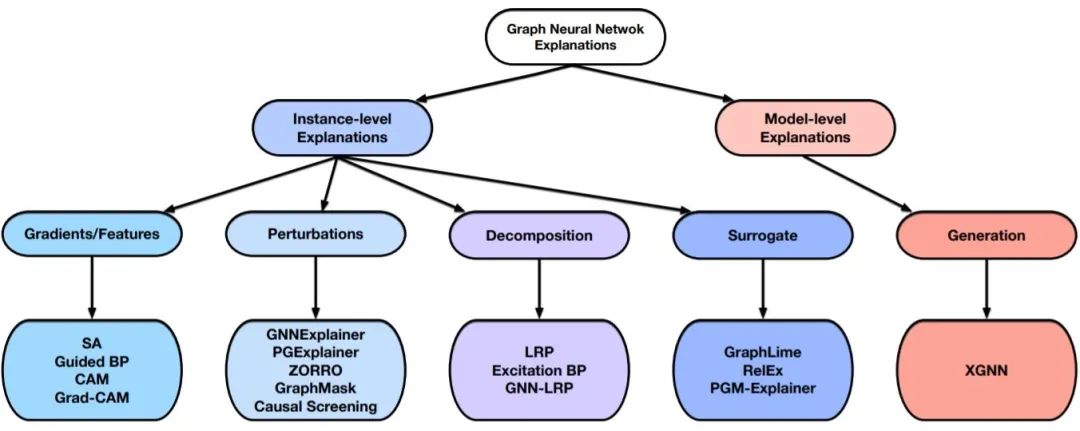
图1 GNN 解释性方法分类框架
1)实例级方法
实例级方法与特征工程的思想有些类似,旨在找到输入数据中最能够影响预测结果的部分特征,为每个输入图提供 input-dependent 的解释。给定一个输入图,实例级方法旨在探究影响模型预测的重要特征实现对深度模型的解释。根据特征重要性分数的获得方式,作者将实例级方法分为四个不同的分支:
基于梯度/特征的方法[49],[50],采用梯度或特征值来表示不同输入特征的重要程度。
基于扰动的方法[42],[43],[51],[52],[53],监测在不同输入扰动下预测值的变化,从而学习输入特征的重要性分数。
基于分解的方法[49],[50],[54],[55],首先将预测分数,如预测概率,分解到最后一个隐藏层的神经元。然后将这样的分数逐层反向传播,直到输入空间,并将分解分数作为重要性分数。
基于代理的方法[56],[57],[58],首先从给定例子的邻居中抽取一个数据集的样本。接下来对采样的数据集合拟合一个简单且可解释的模型,如决策树。通过解释代理模型实现对原始预测的解释。
2)模型级方法
模型级方法直接解释图神经网络的模型,不考虑任何具体的输入实例。这种 input-independent 的解释是高层次的,能够解释一般性行为。与实例级方法相比,这个方向的探索还比较少。现有的模型级方法只有XGNN[41],它是基于图生成的,通过生成 graph patterns使某一类的预测概率最大化,并利用 graph patterns 来解释这一类。
总的来说,这两类方法从不同的角度解释了深度图模型。实例级方法提供了针对具体实例的解释,而模型级方法则提供了高层次的见解和对深度图模型工作原理的一般理解。
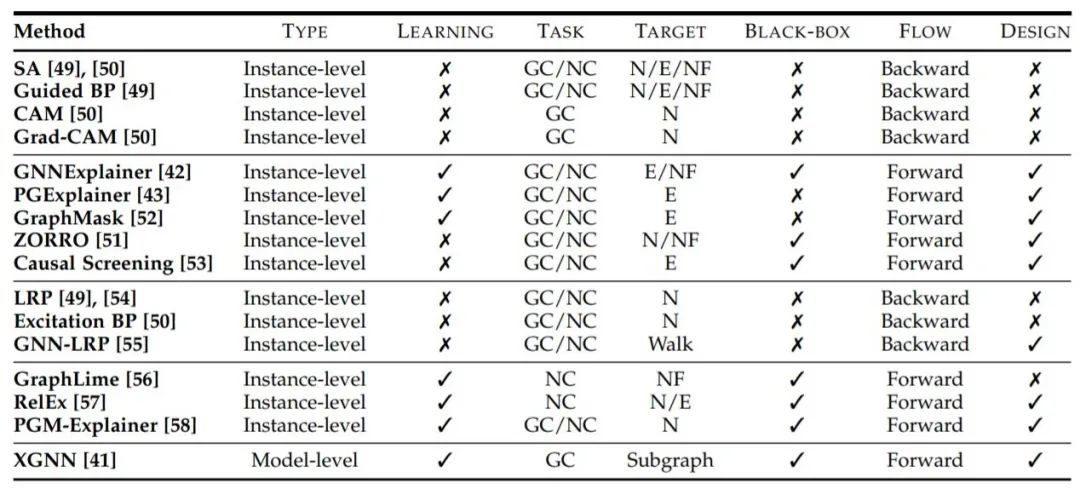
”Type “表示提供什么类型的解释,”Learning “表示是否涉及学习过程,”Task “表示每种方法可以应用于什么任务(GC表示图分类,NC表示节点分类),”Target “表示解释的对象(N表示节点,E表示边,NF表示节点特征,Walk表示图游走),”Black-box “表示在解释阶段是否将训练好的GNNs作为黑盒处理,”Flow “表示解释的计算流程,”Design “表示解释方法是否有针对图数据的具体设计。
3.方法介绍
3.1 基于梯度/特征的方法(Gradients/Features-Based Methods)
采用梯度或特征来解释深度模型是最直接的解决方案,在图像和文本任务中被广泛使用。其关键思想是将梯度或隐藏的特征图值作为输入重要性的近似值。一般来说,在这类方法中,梯度或特征值越大,表示重要性越高。需要注意的是,梯度和隐藏特征都与模型参数高度相关,那么这样的解释可以反映出模型所包含的信息。本文将介绍最近提出的几种方法,包括:SA[49]、Guided BP[49]、CAM[50]和Grad-CAM[50]。这些方法的关键区别在于梯度反向传播的过程以及如何将不同的隐藏特征图结合起来。
1)SA
SA[49]直接采用梯度的平方值作为不同输入特征的重要性得分。输入特征可以是图节点、边或节点特征。它假设绝对梯度值越高,说明相应的输入特征越重要。虽然它简单高效,但有几个局限性:1)SA方法只能反映输入和输出之间的敏感程度,不能很准确地表达重要性(敏感度不等于重要性)。2)还存在饱和问题[59]。即在模型性能达到饱和的区域,其输出相对于任何输入变化的变化都是十分微小的,梯度很难反映输入的贡献程度。
2)Guided BP
Guided BP[49]与SA有着相似的思想,但修改了反向传播梯度的过程。由于负梯度很难解释,Guided BP只反向传播正梯度,而将负梯度剪成零。因此Guided BP与SA有着相同的局限性。
3)CAM
CAM [50] 将最后一层的节点特征映射到输入空间,从而识别重要节点。它要求GNN模型采用全局平均池化层和全连接层作为最终分类器。CAM将最终的节点嵌入,通过加权求和的方式组合不同的特征图,从而获得输入节点的重要性分数。权重是从与目标预测连接的最终全连接层获得的。该方法非常简单高效,但仍有几大限制:1)CAM对GNN结构有特殊要求,限制了它的应用和推广。2)它假设最终的节点嵌入可以反映输入的重要性,这是启发式的,可能不是真的。3)它只能解释图分类模型,不能应用于节点分类任务中。
4)Grad-CAM
Grad-CAM [50] 通过去除全局平均池化层的约束,将CAM扩展到一般图分类模型。同样,它也将最终的节点嵌入映射到输入空间来衡量节点重要性。但是,它没有使用全局平均池化输出和全连接层输出之间的权重,而是采用梯度作为权重来组合不同的特征图。与CAM相比,Grad-CAM不需要GNN模型在最终的全连接层之前采用全局平均池化层。但它也是基于启发式假设,无法解释节点分类模型。
3.2 基于扰动的方法(Perturbation-Based Methods)
基于扰动的方法[14],[15],[60]被广泛用于解释深度图像模型。其根本动机是研究不同输入扰动下的输出变化。当重要的输入信息被保留(没有被扰动)时,预测结果应该与原始预测结果相似。论文 [14],[15],[60]学习一个生成器来生成掩码,以选择重要的输入像素来解释深度图像模型。然而,这种方法不能直接应用于图模型,图数据是以节点和边来表示的,它们不能调整大小以共享相同的节点和边数,结构信息对图来说至关重要,可以决定图的功能。
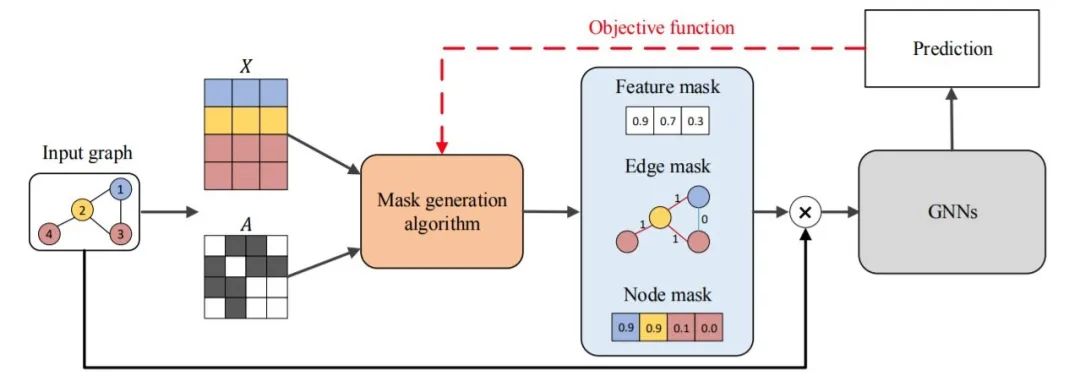
图2 基于扰动方法的一般流程
基于扰动的方法采用不同的掩码生成算法来获得不同类型的掩码。需要注意的是,掩码可以对应节点、边或节点特征。在这个例子中,我们展示了一个节点特征的软掩码,一个边的离散掩码和一个节点的近似离散掩码。然后,将掩码与输入图结合起来,得到一个包含重要输入信息的新图,遮蔽掉不需要的信息。
最终将新图输入到训练好的GNN中,评估掩码并更新掩码生成算法。本文将介绍几种基于扰动的方法,包括:GNNExplainer[42]、PGExplainer[43]、ZORRO[51]、GraphMask[52],Causal Screening[53]。直观地讲,掩码捕捉到的重要输入特征应该传达关键的语义意义,从而得到与原图相似的预测结果。这些方法的区别主要在于三个方面:掩码生成算法、掩码类型和目标函数。
软掩码包含[0,1]之间的连续值,掩码生成算法可以直接通过反向传播进行更新。但软掩码存在 ”introduced evidence “的问题[14],即掩码中任何非零或非一的值都可能给输入图引入新的语义或新的噪声,从而影响解释结果。同时,离散掩码只包含离散值0和1,由于没有引入新的数值,可以避免 ”introduced evidence “问题。
但是,离散掩码总是涉及到不可微的问题,如采样。主流的解决方法是策略梯度技术[61]。论文[45],[62],[63]提出采用重参数化技巧,如Gumbel-Softmax估计和稀疏松弛,来逼近离散掩码。需要注意的是,输出的掩码并不是严格意义上的离散掩码,而是提供了一个很好的近似值,这不仅可以实现反向传播,而且在很大程度上缓解了”introduced evidence“的问题。
接下来将详细的介绍目前存在的几种基于扰动的解释性方法,我们可以重点关注它们的作用对象(节点或边或节点特征),以及它们的掩码生成算法、掩码类型和目标函数。
1)GNNExplainer
GNNExplainer [42] 学习边和节点特征的软掩码,通过掩码优化来解释预测。软掩码被随机初始化,并被视为可训练变量。然后通过元素点乘将掩码与原始图结合。最大化原始图的预测和新获得的图的预测之间的互信息来优化掩码。但得到的掩码仍然是软掩码,因此无法避免 ”introduced evidence“问题。此外,掩码是针对每个输入图单独优化的,因此解释可能缺乏全局视角。
2)PGExplainer
PGExplainer[43]学习边的近似离散掩码来解释预测。它训练一个参数化的掩码预测器来预测边掩码。给定一个输入图,首先通过拼接节点嵌入来获得每个边的嵌入,然后预测器使用边嵌入来预测边掩码。预测器使用边嵌入来预测每个边被选中的概率(被视为重要性分数)。通过重参数化技巧对近似的离散掩码进行采样。最后通过最大化原始预测和新预测之间的相互信息来训练掩码预测器。需要注意的是,即使采用了重参数化技巧,得到的掩码并不是严格意义上的离散掩码,但可以很大程度上缓解 ”introduced evidence“的问题。由于数据集中的所有边都共享相同的预测器,因此解释可以提供对训练好的GNN的全局理解。
3)GraphMask
GraphMask[52]是一种事后解释GNN各层中边重要性的方法。与PGExplainer类似,它训练一个分类器来预测是否可以丢弃一条边而不影响原来的预测。然而,GraphMask为每一层GNN获取边掩码,而PGExplainer只关注输入空间。此外,为了避免改变图结构,被丢弃的边被可学习的基线连接所取代,基线连接是与节点嵌入相同维度的向量。需要注意的是,采用二进制Concrete分布[63]和重参数化技巧来近似离散掩码。此外,分类器使用整个数据集通过最小化一个散度项来训练,用于衡量网络预测之间的差异。与PGExplainer类似,它可以很大程度上缓解 ”introduced evidence“问题,并对训练后的GNN进行全局理解。
3)ZORRO
ZORRO[51]采用离散掩码来识别重要的输入节点和节点特征。给定一个输入图,采用贪心算法逐步选择节点或节点特征。每一步都会选择一个fidelity score最高的节点或一个节点特征。通过固定所选节点/特征,并用随机噪声值替换其他节点/特征,来衡量新的预测与模型原始预测的匹配程度。由于不涉及训练过程,因此避免了离散掩码的不可微限制。此外,通过使用硬掩码,ZORRO不会受到 ”introduced evidence “问题的影响。然而,贪婪的掩码选择算法可能导致局部最优解释。此外,由于掩码是为每个图形单独生成的,因此解释可能缺乏全局的理解。
4)Causal Screening
Causal Screening[53]研究输入图中不同边的因果归因。它为 explanatory subgraph 确定一个边掩码。关键思想是:研究在当前 explanatory subgraph 中增加一条边时预测的变化,即所谓的因果效应。对于每一步,它都会研究不同边的因果效应,并选择一条边添加到子图中。具体来说,它采用个体因果效应(ICE)来选择边,即测量在子图中添加不同边后的互信息(原图与解释子图的预测之间)差异。与ZORRO类似,Causal Screening是一种贪心算法,不需要任何训练过程就能生成离散掩码。因此,它不会受到 ”introduced evidence “问题的困扰,但可能缺乏全局性的理解,而停留在局部最优解释上。
3.3 基于代理的方法(Surrogate Methods)
由于输入空间和输出预测之间的复杂和非线性关系,深度模型的解释具有挑战性。代理方法能够为图像模型提供实例级解释。其基本思想是化繁为简,既然无法解释原始深度图模型,那么采用一个简单且可解释的代理模型来近似复杂的深层模型,实现输入实例的邻近区域预测。
需要注意的是,这些方法都是假设输入实例的邻近区域的关系不那么复杂,可以被一个较简单的代理模型很好地捕获。然后通过可解释的代理模型的来解释原始预测。将代理方法应用到图域是一个挑战,因为图数据是离散的,包含拓扑信息。那么如何定义输入图的相邻区域,以及什么样的可解释代理模型是合适的,都是不清楚的。
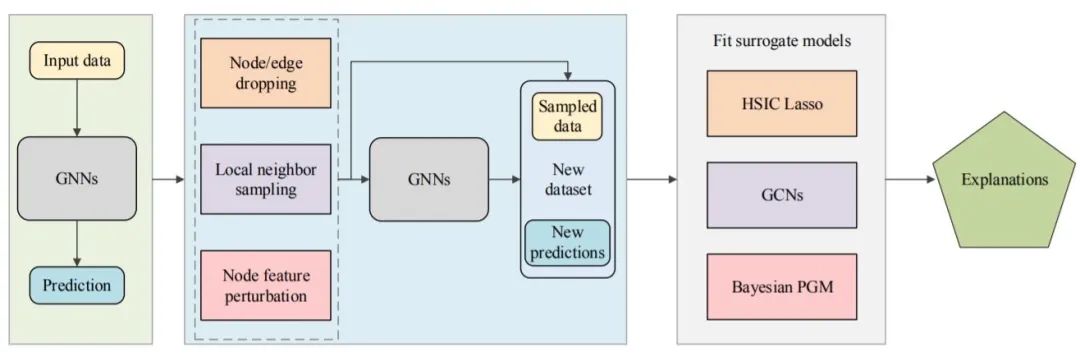
图3 代理模型的一般框架
给定一个输入图及其预测,它们首先对一个局部数据集进行采样,以表示目标数据周围的关系。然后应用不同的代理方法来拟合局部数据集。需要注意的是,代理模型一般都是简单且可解释的ML模型。最后,代理模型的解释可以看作是对原始预测的解释。本文将介绍最近提出的几种代理方法,包括:GraphLime[56]、RelEx[57]和PGM-Explainer[58]。
这些方法的一般流程如图3所示。为了解释给定输入图的预测,它们首先获得一个包含多个相邻数据对象及其预测的局部数据集。然后拟合一个可解释模型来学习局部数据集。来自可解释模型的解释被视为原始模型对输入图的解释。不同代理模型关键的区别在于两个方面:如何获得局部数据集和选择什么代理模型。
1)GraphLime
GraphLime[56]将LIME[64]算法扩展到深度图模型,并研究不同节点特征对节点分类任务的重要性。给定输入图中的一个目标节点,将其N-hop 邻居节点及其预测值视为局部数据集,其中N的合理设置是训练的GNN的层数。然后采用非线性代理模型HSIC Lasso[65]来拟合局部数据集。根据HSIC Lasso中不同特征的权重,可以选择重要的特征来解释HSIC Lasso的预测结果。这些被选取的特征被认为是对原始GNN预测的解释。但是,GraphLime只能提供节点特征的解释,却忽略了节点和边等图结构,而这些图结构对于图数据来说更为重要。另外,GraphLime是为了解释节点分类预测而提出的,但不能直接应用于图分类模型。
2)RelEx
RelEx[57]结合代理方法和基于扰动的方法的思想,研究节点分类模型的可解释性。给定一个目标节点及其计算图(N-hop邻居),它首先从计算图中随机采样连接的子图,获得一个局部数据集,并将这些子图喂入训练好的GNN,以获得其预测结果。从目标节点开始,它以BFS的方式随机选择相邻节点。采用GCN模型作为代理模型来拟合局部数据集。与GraphLime不同,RelEx中的代理模型是不可解释的。训练后,它进一步应用前述基于扰动的方法,如生成软掩码或Gumbel-Softmax掩码来解释预测结果。该过程包含了多个步骤的近似,比如使用代理模型来近似局部关系,使用掩码来近似边的重要性,从而使得解释的说服力和可信度降低。由于可以直接采用基于扰动的方法来解释原有的深度图模型,因此没有必要再建立一个不可解释的深度模型作为代理模型来解释。
3)PGM-Explainer
PGM-Explainer[58]建立了一个概率图形模型,为GNN提供实例级解释。局部数据集是通过随机节点特征扰动获得的。具体来说,给定一个输入图,每次PGM-Explainer都会随机扰动计算图中几个随机节点的节点特征。然后对于计算图中的任何一个节点,PGM-Explainer都会记录一个随机变量,表示其特征是否受到扰动,以及其对GNN预测的影响。通过多次重复这样的过程,就可以得到一个局部数据集。通过Grow-Shrink(GS)算法[66]选择依赖性最强的变量来减小局部数据集的大小。最后采用可解释的贝叶斯网络来拟合局部数据集,并解释原始GNN模型的预测。PGM-Explainer可以提供有关图节点的解释,但忽略了包含重要图拓扑信息的图边。此外,与GraphLime和RelEx不同的是,PGM-Explainer可以同时用于解释节点分类和图形分类任务。
3.4 分解方法(Decomposition Methods)
分解方法是另一种比较流行的解释深度图像分类器的方法,它通过将原始模型预测分解为若干项来衡量输入特征的重要性。然后将这些项视为相应输入特征的重要性分数。这些方法直接研究模型参数来揭示输入空间中的特征与输出预测之间的关系。需要注意的是,这些方法要求分解项之和等于原始预测得分。由于图包含节点、边和节点特征,因此将这类方法直接应用于图域是具有挑战性的。很难将分数分配给不同的边,图数据边包含着重要的结构信息,不容忽视。
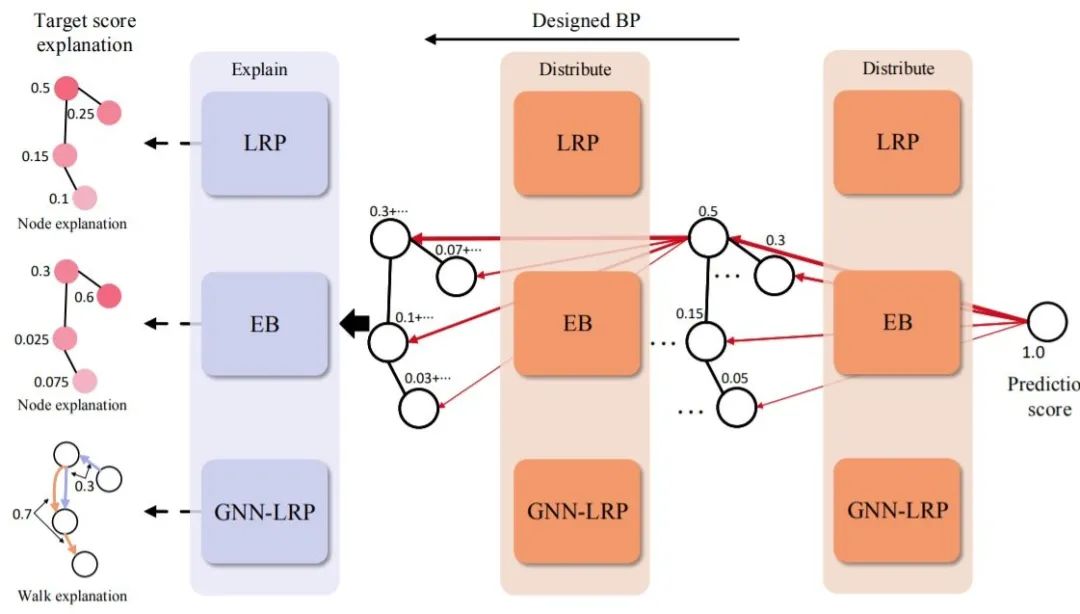
图5 分解方法的一般流程
本文将介绍最近提出的几种用于解释深层图神经网络泛读分解方法,包括:Layerwise Relevance Propagation(LRP)[49]、[54]、Excitation BP[50]和GNN-LRP[55]。这些算法的主要思想是建立分数分解规则,将预测分数分配到输入空间。这些方法的一般流程如图4所示。
以反向传播的方式逐层分发预测得分,直到输入层。从输出层开始,将模型的预测结果作为初始目标分数。然后将分数进行分解,并按照分解规则分配给上一层的神经元。通过重复这样的过程,直到输入空间,它们可以得到节点特征的重要性分数,这些分数可以组合起来表示边重要性、节点重要性和游走重要性。但是这些算法都忽略了深度图模型中的激活函数。不同分解方法的主要区别在于分数分解规则和解释的目标。
1)LRP
LRP[49],[54]将原来的LRP算法[67]扩展到深度图模型。它将输出的预测分数分解为不同的节点重要性分数。分数分解规则是基于隐藏特征和权重制定的。对于一个目标神经元,其得分表示为上一层神经元得分的线性近似。目标神经元激活贡献度较高的神经元获得的目标神经元得分比例较大。为了满足保守属性,在事后解释阶段将邻接矩阵作为GNN模型的一部分,这样在分数分配时就可以忽略它,否则,邻接矩阵也会收到分解后的分数,从而使保守属性失效。由于LRP是直接根据模型参数开发的,所以其解释结果更具有可信度。但它只能研究不同节点的重要性,不能应用于图结构,如子图和游走。该算法需要对模型结构有全面的了解,这就限制了它对非专业用户的应用,如跨学科研究人员。
2)Excitation BP
Excitation BP[50]与LRP算法有着相似的思想,但它是基于全概率法则开发的。它定义了当前层中一个神经元的概率等于它输出给下一层所有连接神经元的总概率。那么分数分解规则可以看作是将目标概率分解为几个条件概率项。Excitation BP的计算与LRP中的z+规则高度相似。因此它与LRP算法有着相同的优点和局限性。
3)GNN-LRP
GNN-LRP[55]研究了不同图游走的重要性。由于在进行邻域信息聚合时,图游走对应于消息流,因此它对深层图神经网络更具有一致性。得分分解规则是模型预测的高阶泰勒分解。研究表明,泰勒分解(在根零处)只包含T阶项,其中T是训练的GNN的层数。那么每个项对应一个T阶图游走,可以视为其重要性得分。由于无法直接计算泰勒展开给出的高阶导数,GNN-LRP还遵循反向传播过程来逼近T阶项。GNN-LRP中的反向传播计算与LRP算法类似。然而,GNN-LRP不是将分数分配给节点或边,而是将分数分配给不同的图游走。它记录了层与层之间的消息分发过程的路径。这些路径被认为是不同的游走,并从它们对应的节点上获得分数。虽然GNN-LRP具有坚实的理论背景,但其计算中的近似值可能并不准确。由于每个游走都要单独考虑,计算复杂度很高。此外,对于非专业人员来说,它的使用也具有挑战性,尤其是对于跨学科领域。
4. 模型级方法与实例级方法不同,模型级方法旨在提供一般性的见解和高层次的理解来解释深层图模型。它们研究什么样的输入图模式可以导致GNN的某种行为,例如最大化目标预测。输入优化[16]是获得图像分类器模型级解释的一个热门方向。但是,由于图拓扑信息的离散性,它不能直接应用于图模型,从而使GNN在模型层面的解释更具挑战性。它仍然是一个重要但研究较少的课题。据我们所知,现有的解释图神经网络的模型级方法只有XGNN[41]。
1)XGNN
XGNN[41]提出通过图生成来解释GNN。它不是直接优化输入图,而是训练一个图生成器,使生成的图能够最大化目标图预测。然后,生成的图被视为目标预测的解释,并被期望包含判别性的图模式。在XGNN中,图形生成被表述为一个强化学习问题。对于每一步,生成器都会预测如何在当前图中增加一条边。然后将生成的图输入到训练好的GNN中,通过策略梯度获得反馈来训练生成器。此外,还加入了一些图规则,以鼓励解释既有效又能被人类理解。XGNN是一个生成模型级解释的通用框架,因此可以应用任何合适的图生成算法。该解释是通用的,并且提供了对训练的GNNs的全局理解。然而XGNN只证明了其在解释图分类模型方面的有效性,XGNN是否可以应用于节点分类任务还不得而知,这是未来研究中需要探索的重要方向。
5. 评估模型由于缺乏 ground truths,因此不容易对解释方法的结果进行评估,作者讨论并分析了几种常用的数据集和度量标准。
5.1. Datasets
需要选择合适的数据集来评估不同的解释技术,并且希望数据是直观的,易于可视化的。应该在数据实例和标签之间蕴含人类可以理解的理由,这样专家就可以验证这些理由是否被解释算法识别。为了评估不同的解释技术,通常采用几种类型的数据集,包括合成数据、情感图数据和分子数据。
5.1.1. Synthetic data
利用现有的合成数据集来评估解释技术[42],[43]。在这样的数据集中,包含了不同的 graph motifs,可以通过它们确定节点或图的标签。数据实例和数据标签之间的关系由人类定义。即使经过训练的GNNs可能无法完美地捕捉到这样的关系,但graph motifs 可以作为解释结果的ground truths 的合理近似值。这里我们介绍几种常见的合成数据集。
BA-shapes:它是一个节点分类数据集,有4个不同的节点标签。对于每个图形,它包含一个基础图(300个节点)和一个类似房子的5节点 motif。需要注意的是,基础图是由Barab´asi-Albert(BA)模型获得的,它可以生成具有优先附加机制的随机无标度网络[68]。motif 被附加到基图上,同时添加随机边。每个节点根据其是否属于基础图或motif 的不同空间位置进行标注。
BA-Community:这是一个有8个不同标签的节点分类数据集。对于每个图,它是通过组合两个随机添加边的BA-shapes图获得的。节点标签由BA-shapes图的成员资格及其结构位置决定。
Tree-Cycle:它是一个有两个不同标签的节点分类数据集。对于每个图,它由深度等于8的基平衡树图和6节点周期 motif 组成。这两部分是随机连接的。基图中节点的标签为0,否则为1。
Tree-Grids:它是一个有两个不同标签的节点分类数据集。它与 Tree-Cycle 数据集相同,只是Tree-Grids数据集采用了9节点网格 motifs 而不是周期 motifs 。
BA-2Motifs:它是一个具有2种不同图标签的图形分类数据集。有800个图,每个图都是通过在基础BA图上附加不同的motif来获得的,如house-like motif 和 five-node cycle motif。不同的图是根据motif 的类型来标注的。
在这些数据集中,所有节点特征都被初始化为全1向量。训练好的GNNs模型要捕捉图结构来进行预测。然后根据每个数据集的构建规则,我们可以分析解释结果。例如,在BA-2Motifs数据集中,我们可以研究解释是否能够捕获motif结构。然而,合成数据集只包含图和标签之间的简单关系,可能不足以进行综合评估。
5.1.2 Sentiment graph data
由于人类只有有限的领域知识,传统的图数据集在理解上具有挑战性,因此需要构建人类可理解的图数据集。文本数据具有人类可理解的语义的单词和短语组成,因此可以成为图解释任务的合适选择,解释结果可以很容易地被人类评估。因此我们基于文本情感分析数据构建了三个情感图数据集,包括SST2[69]、SST5[69]和Twitter[70]数据集。

图5 文本情感图
对于每个文本序列,将其转换为一个图,每个节点代表一个单词,而边则反映不同单词之间的关系。作者采用Biaffine解析器[71]来提取词的依赖关系。图5中展示了生成的情感图的一个例子。生成的图是有向的,但边标签被忽略了,因为大多数GNNs不能捕获边标签信息。用BERT[72]来学习单词嵌入,并将这种嵌入作为图节点的初始嵌入。建立一个模型,采用预训练好的BERT作为特征提取器,采用一层平均池化的GCN作为分类器。最后预训练的BERT为每个词提取768维的特征向量,作为情感图数据中的节点特征。
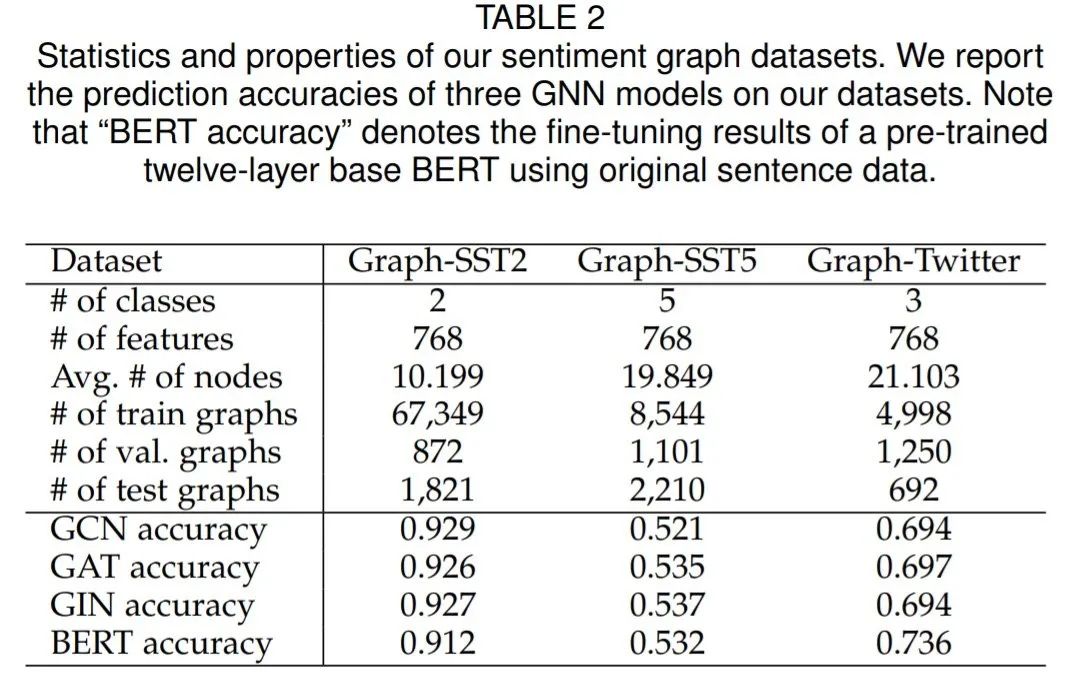
作者建立了三个情感图数据集,分别为Graph-SST2、Graph-SST5和Graph-Twitter ,并即将公开,可以直接用于研究不同的可解释技术。这些数据集的统计和属性如表2所示。为了验证本文生成的情感数据集具有可解释信息,作者分别再新生成的情感数据集和原始数据集进行实验。
作者展示了两层GNNs在这些数据集上的预测精度,包括GCNs、GATs和GINs。还展示了使用原始句子数据集的预训练的BERT[72]的微调精度。结果表明,与原始句子数据集相比,作者构建的情感图数据集可以达到具有竞争力的性能这些数据集是实现图模型解释的合理选择。根据不同词的语义和情感标签,我们可以研究可解释方法是否能识别出具有关键意义的词以及不同词之间的关系
5.1.3 Molecule data
分子数据集也被广泛用于解释任务,如MUTAG[73]、BBBP和Tox21[74]。这类数据集中的每个图对应一个分子,其中节点代表原子,边是化学键。分子图的标签一般由分子的化学功能或性质决定。采用这样的数据集进行解释任务需要领域知识,例如什么化学基团对其官能性更具有鉴别性。例如,在数据集MUTAG中,不同的图形是根据它们对细菌的诱变作用来标注的。例如,已知碳环和NO2化学基团可能导致诱变效应[73],那么可以研究可解释方法是否能识别出对应类别的 patterns
(在不同的领域中,不同的局部结构是具有区分力的,可解释方法是否能够识别这些模式?)
5.2 Evaluation Metrics
即使可视化的结果可以让人理解解释性方法是否合理,但由于缺乏 ground truths,这种评估并不完全可信。为了比较不同的解释性方法,我们需要研究每个输入样例的结果,这很耗时。因此评估度量对于研究可解释方法至关重要。好的度量方法应该从模型的角度来评估预测结果,比如解释是否忠实于模型[75],[76]。作者将介绍最近提出的几种针对解释性问题的评估度量方法。
5.2.1 Fidelity/Infidelity
首先,从模型的预测结果上分析解释性方法的性能,解释应该忠于模型,解释方法应该识别对模型重要的输入特征。为了评估这一点,最近提出了Fidelity[50]度量方法。关键思想在于如果解释技术所识别的重要输入特征(节点/边/节点特征)对模型具有判别力,那么当这些特征被移除时,模型的预测结果应该会发生显著变化。因此,Fidelity被定义为原始预测与遮蔽掉重要输入特征后的新预测之间的精度之差[50],[77],即衡量两种预测结果的差异性。
可解释方法可以看作是一个硬重要性映射 ,其中元素为 0(表示特征不重要)或1(表示特征重要)。对于现有方法,例如ZORRO[51] 和 Causal Screening[53] 等方法,生成的解释是离散掩码,可以直接作为重要性映射 。对于 GNNExplainer[42] 和 GraphLime[56] 等方法,重要性分数是连续值,那么可以通过归一化和阈值化得到重要性地映射。最后,预测精度的Fidelity得分可以计算为:
其中是图的原始预测,是图的数量。表示去掉重要输入特征的补全掩码,是将新图输入训练好的GNN 时的预测值。指示函数如果和相等则返回1,否则返回0。注意,指标研究的是预测精度的变化。通过对预测概率的关注,概率的Fidelity可以定义为:
其中,代表基于互补掩码,保留的特征得到的新图。需要注意的是,监测的是预测概率的变化,比更敏感。对于这两个指标来说,数值越高,说明解释结果越好,识别出的判别特征越多。
Fidelity度量通过去除重要节点/边/节点特征来研究预测变化。相反,Infidelity度量通过保留重要的输入特征和去除不重要的特征来研究预测变化。直观地讲,重要特征应该包含判别信息,因此即使去掉不重要的特征,它们也应该导致与原始预测相似的预测。从形式上看,度量Infidelity可以计算为:
其中是根据映射保留的重要特征时的新图,是新的预测值。需要注意的是,对于和来说,数值越低,说明去掉的特征重要信息越少,这样解释结果越好
5.2.2 Sparsity
从输入图数据的角度来分析解释性方法的性能,解释性方法应该是稀疏的,这意味着它们应该捕捉最重要的输入特征,而忽略不相关的特征,可以用稀疏度(Sparsity)指标衡量这样个特性。具体来说,它衡量的是被解释方法选择为重要特征的分数[50]。形式上,给定图和它的硬重要性映射 ,稀疏度度量可以计算为:
其中表示中识别的重要输入特征(节点/边/节点特征)的数量,表示原始图 中特征的总数。请注意,数值越高表示解释方法越稀疏,即往往只捕捉最重要的输入信息。
5.2.3 Stability
好的解释应该是稳定的。当对输入施加小的变化而不影响预测时,解释应该保持相似。最近提出的稳定性度量标准来衡量一个解释方法是否稳定[78]。给定一个输入图,它的解释被认为是真实标签。然后对输入图进行小的改变,比如附加新的节点/边,得到一个新的图。需要注意的是,和需要有相同的预测。然后得到的解释,表示为 。通过比较和之间的差异,我们可以计算出稳定性得分。请注意,数值越低表示解释技术越稳定,对噪声信息的鲁棒性越强。
5.2.4 Accuracy
针对合成数据集提出了精度度量方法[42]、[78]。在合成数据集中,即使不知道GNN是否按照我们预期的方式进行预测,但构建这些数据集的规则,如 graph motifs,可以作为 ground truths 的合理近似。然后对于任何输入图,我们都可以将其解释与这样的 ground truths进行比较。例如,在研究重要边的时候,可以研究解释中的重要边与 ground truths 的边的匹配率。这种比较的常用指标包括一般精度、F1得分、ROC-AUC得分。匹配率数值越高,说明解释结果越接近于 ground truths,认为是较好的解释方法。
6. Conclusion图神经网络近来被广泛研究,但对图模型的可解释性的探讨还比较少。
为了研究这些黑箱的潜在机制,人们提出了几种解释图模型的方法,包括XGNN、GNNExplainer等。这些方法从不同的角度和动机来解释图模型,但是缺乏对这些方法的全面研究和分析。在这项工作中,作者对这些方法进行了系统全面的调研。首先对现有的GNN解释方法进行了系统的分类,并介绍了每一类解释方法背后的关键思想。
然后详细讨论了每一种解释方法,包括方法、内涵、优势和缺点,还对不同的解释方法进行了综合分析。并且介绍和分析了常用的数据集和GNN解释方法的评价指标。最后从文本数据出发,建立了三个图形数据集,这些数据集是人类可以理解的,可以直接用于GNN解释任务bj
编辑:jq
-
神经网络
+关注
关注
42文章
4776浏览量
100931 -
SA
+关注
关注
3文章
128浏览量
37970 -
GNN
+关注
关注
1文章
31浏览量
6358
原文标题:【GNN综述】图神经网络的解释性综述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工神经网络的原理和多种神经网络架构方法

数据智能系列讲座第3期—交流式学习:神经网络的精细与或逻辑与人类认知的对齐






 工商网监
工商网监
评论