 详细剖析有数BI的权限体系!
详细剖析有数BI的权限体系!

权限体系是所有BI产品都会涉及的一个重要组成部分,目的是对不同的人访问资源进行权限控制,避免因权限控制缺失或操作不当引发的风险,如隐私数据泄露等问题。有数BI权限体系设计的初衷,希望它既能满足实际业务中的复杂场景,又能简洁易用,今天我们将详细介绍有数BI的权限体系!
角色模型
对于权限管理,最简单的办法就是给每个用户配不同的权限,但这样的设计在用户较多时维护起来就显得非常力不从心。于是很多人想到在用户和权限之间增加一个角色,也就是迄今为止最为普及的权限设计模型,即RBAC(Role Based Access Control,基于角色的权限访问控制)权限模型。
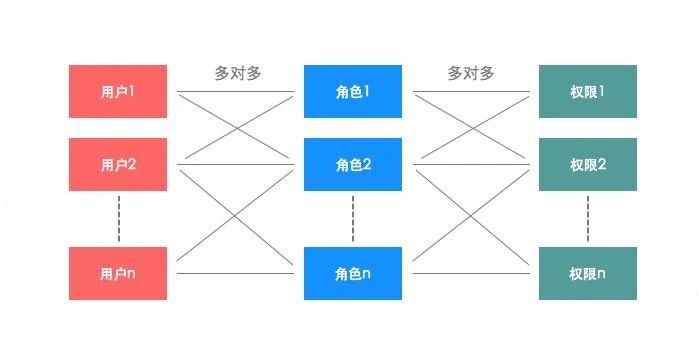
RBAC模型认为权限授权实际上是Who、What、How的问题。在RBAC模型中,Who、What、How构成了访问权限三元组,也就是“Who(权限的拥用者或主体)对What(权限针对的对象或资源)进行How(具体的权限)的操作”。换句话讲,在RBAC模型中,是通过控制“Who对What进行How的操作”来实现让不同的用户/用户组对不同的资源拥有不同的操作/数据权限的目的。
我们的权限体系即是依据RBAC模型思想所设计的,相关概念包括权限,角色和用户。角色与权限绑定,即项目中用户的权限与其被赋予的角色相关。一个用户可以拥有多个角色,一个角色也可以被添加给多个用户,每个角色可以被赋予多个权限。以下图所示的结构为例,用户1只拥有角色1的权限,即对资源1进行操作1;而由于用户3拥有3个角色全部的权限,因此该用户可以对资源1和资源2分别进行操作1和操作2。
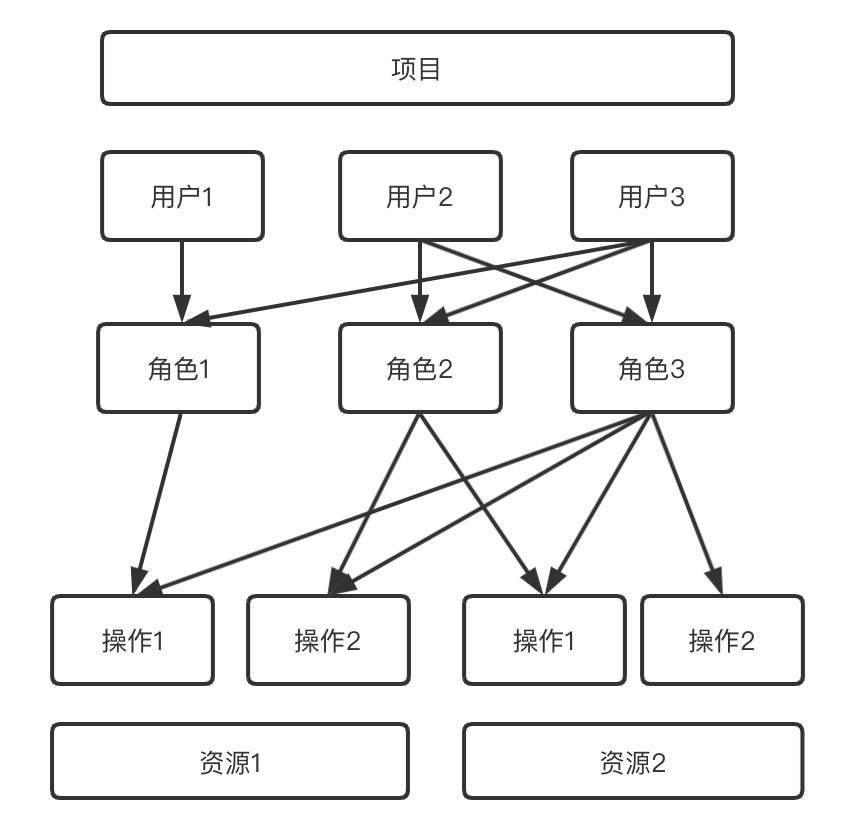
现在,有数BI的权限体系已经拥有了基础的RBAC模型思想,但还远远不够。通过市场分析,我们发现企业在使用权限体系的过程中,大多绕不开三大难题:
组织规模达到一定程度后,需要管理的资源数量庞大,同时对权限要求又很高时,需设置非常细粒度的权限,导致整个权限体系显得十分零散和无序,产生大量的维护成本;
而为了保证数据安全,这样的权限体系往往是由权限最高的少数管理员来配置组织内部全体成员的权限,给管理员带来巨大的工作量;
同时,在设置针对个人的不同数据权限时,其复杂程度更是呈几何增长,且当人员变更时,针对每个数据集需要重新配置行级权限,造成大量的权限重复配置操作。
那么为了解决这些难题,有数BI的权限体系是如何设计的呢?接下来,本文将围绕这些难题,给出我们的解决方案!
资源权限
1.基于角色,统一管理
不同于市面上其他的BI产品,有数BI中资源权限的设置和赋予完全通过角色来实现,这样的设计可以帮助用户基于角色来实现权限的统一管理,极大降低企业设置权限体系的复杂程度。例如,企业内各人员的资源权限往往是根据企业组织架构来对应设置的,当组织人员变动时,在权限体系中只需将该用户所拥有的角色变更为对应组织架构角色,就能一键实现资源权限的变更。
通过对资源权限和数据权限的组合设置,简单勾选即可创建角色,并将对应成员添加到该角色下面,轻松搭建灵活、简洁的权限体系!
2.分级授权,灵活应用
现实场景中,当企业发展到一定程度时,往往拥有多层组织架构,而在传统的RBAC模型中,往往都只能由一个权限最高的用户(一般为管理员)来创建所有角色,对所有用户进行权限的授予,进行权限体系的维护工作,这样导致管理员工作量过大。同时,企业里不同的业务线,或者不同的业务部门都有数据分析需求,如果无法将不同业务线或部门资源分隔开,将对资源的整理和权限配置带来巨大挑战。
基于上述情况,有数BI提供了“项目+二级管理员”的多项目结合分级授权体系。首先,企业可以为不同的业务部门建立不同的项目,通过“项目列表”在不同的项目前切换,项目管理员拥有该项目内所有资源的所有权限。其次,通过二级管理员的设置来实现二级授权,项目管理员可以将部分资源的授予权限赋予该二级管理员,由二级管理员来管理对应的资源。多租户结合分级授权体系可以帮助用户创建非常丰富立体的权限分配体系。
具体来看,有数BI将角色分成三类:系统角色、一级角色和二级角色。
系统角色包括:项目管理员、二级管理员、编辑者、阅览者,系统角色无法编辑、修改和删除。编辑者可以查看或编辑所有的资源;阅览者仅可以查看所有资源。
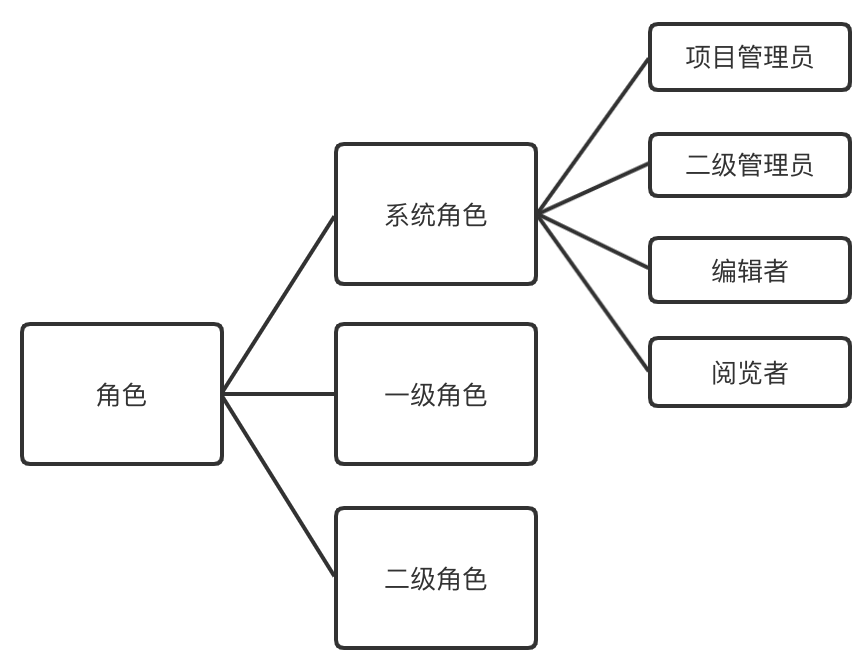
一级角色和二级角色由项目管理员和二级管理员创建,一级角色可以拥有编辑权限,二级角色只能拥有阅览权限。
数据权限
1.行列权限,精准定位
数据安全对于企业的重要性不言而喻。数据权限解决的便是用户能看到多少数据量和什么数据的问题。现实场景中,企业往往有大量业务数据和权限需求,在设置数据权限时,如何实现数据权限的精准定位,是有数BI在设计数据权限时所考虑的重要方面。因此,有数BI提供行和列级别的数据权限控制粒度,通过对同一张表进行行权限和列权限的配置,就可以精准实现数据权限的高效配置。
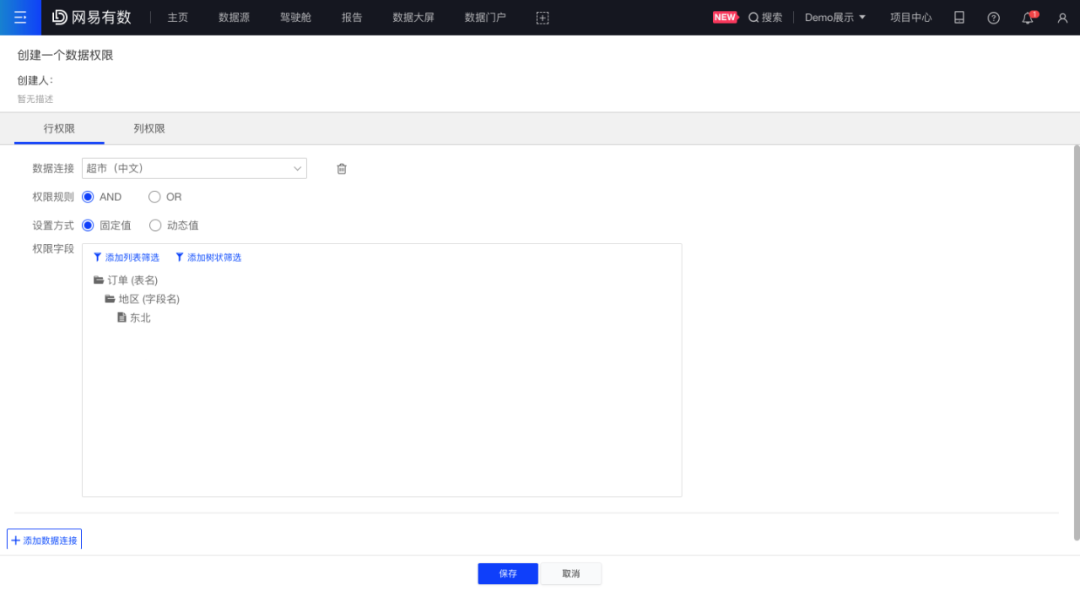
假设这样一个场景:小王的公司在“东北、华北、华东、华南”四个大区都有销售人员,他希望不同大区的销售访问同一张报告时候,都只能看到自己所属大区的数据,在有数BI中,用“数据行级权限”可以实现这样的需求:我们可以创建4个“数据行级权限”,每个“数据行级权限”只能访问一个大区的数据,然后给不同大区的销售人员分配对应的“数据行级权限”。如东北大区的销售人员只能看到“东北”地区的数据,我们可以建立一个“数据行级权限”,然后设置数据访问权限,只允许该角色成员访问“东北”地区的数据,然后将该“数据行级权限”赋予东北大区的销售人员即可。
2.属性对应,动态匹配
使用上述方法时,当我们存在多少个大区,我们就需要创建对应数量的“数据行级权限”。当组织人员规模达到一定程度后,管理复杂度往往呈几何增长,这样的设置方式必然需要大量的时间成本和人力成本来维护。同时,考虑到组织内不同人员所能拥有的数据权限往往与TA所在的部门、岗位或地区有一定的映射关系,那么,能否提供一种简便的设置路径,能够直接对不同部门的用户匹配不同的行级权限呢?
基于此,我们在数据权限的创建页提供了固定值和属性值的配置选项,当选择属性值时,就可以通过设置属性值与对应字段的匹配,例如将“属性值-地区”与字段“地区匹配”,就能让不同地区的成员只能看到对应地区的数据,从而极大提高行级授权的管理效率。
1. 首先,企业域管理-人员信息-属性列表-设置一个属性值“地区”,在对应用户后输入东北或其他地区。
2. 创建一个“数据行级权限”,选择要设置权限的数据连接,设置方式选择“动态值”,选择要设置权限的表跟字段,选择要匹配的用户属性,在本例中,即将“地区”字段匹配“地区”属性。
3. 保存后,将该“数据行级权限”分配给所有用户,则每个用户访问报告时会根据该用户所在大区来筛选数据,只能看到自己大区的数据。
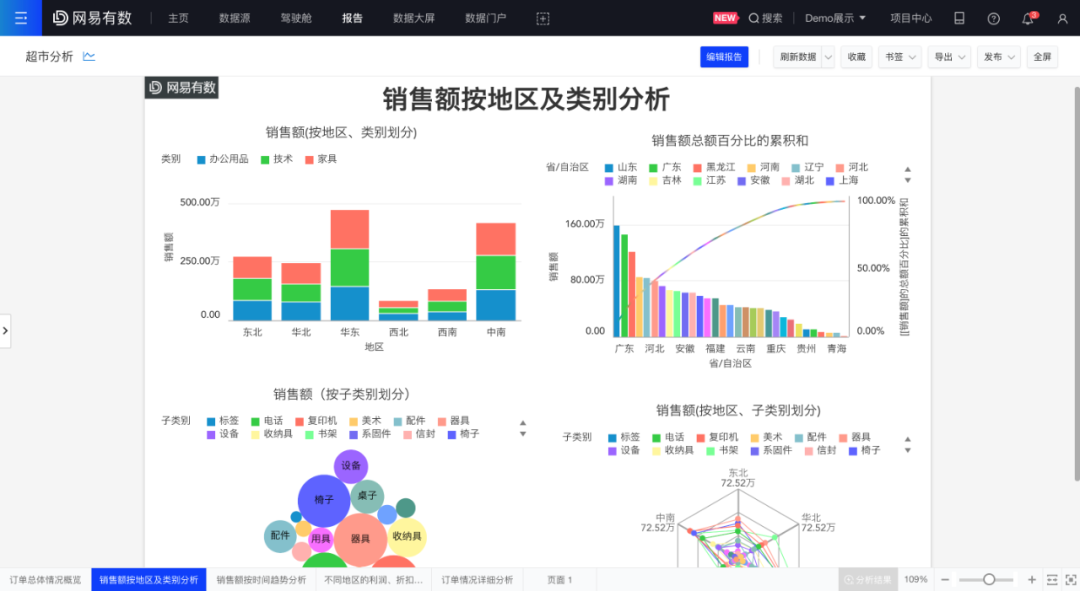
(未设置数据权限)
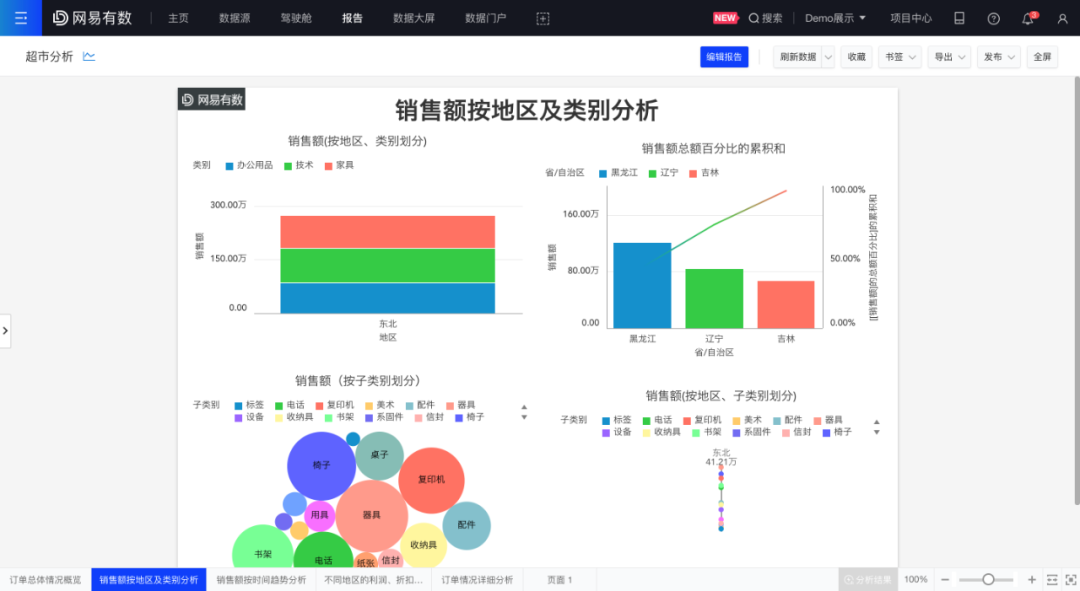
(设置了数据权限)
结语
为了应对更多复杂各异的组织架构和管理体系,我们仍然在不停地探索之中。具体来说,目前的分级授权体系仅支持对资源的分级授权,还无法做到对数据权限的分级授权,我们正在积极寻找更完美的解决办法,在保持用户低使用成本和高数据安全的同时,实现更高的灵活性。
编辑:jq
-
数据
+关注
关注
8文章
7349浏览量
95025 -
RBAC
+关注
关注
0文章
44浏览量
10441
原文标题:权限体系设计 : 网易有数 BI 功能品鉴
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文搞懂Linux权限体系
SGM48751:8:1 CMOS 模拟信号多路复用器的详细剖析
电能质量在线监测装置支持哪些运维权限分级管理?
Linux文件权限管理详解
深入解析TUSB4020BI双端口USB 2.0集线器:特性、应用与设计要点
电能质量在线监测装置的权限管理如何保障数据安全?

电能质量在线监测装置支持多账号权限管理吗?

移动BI可视化分析助力决策分析应用
企业实施BI的时机和选择考虑
电能质量在线监测装置的数据在云端的访问权限是如何管控的?
技术文章 | Ubuntu权限管理攻略

浅谈Sn-Bi-Ag低温锡膏的晶界强化机制
Linux权限体系解析
Linux权限管理基础入门



评论