 ICLR 2021杰出论文奖出炉 让我们看看前八位优秀论文有哪些
ICLR 2021杰出论文奖出炉 让我们看看前八位优秀论文有哪些
ICLR 2021杰出论文奖出炉今年共有2997篇投稿,接收860篇,最后共有8篇获得杰出论文奖。
这8篇论文中,谷歌成最大赢家,共有4篇论文获奖(包括DeepMind、谷歌大脑在内)。
除此之外,AWS、Facebook等机构,以及CMU、南洋理工等高校也纷纷上榜。
共有8篇论文上榜
1、Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with 1/n Parameters
来自AWS、Google、南洋理工大学。
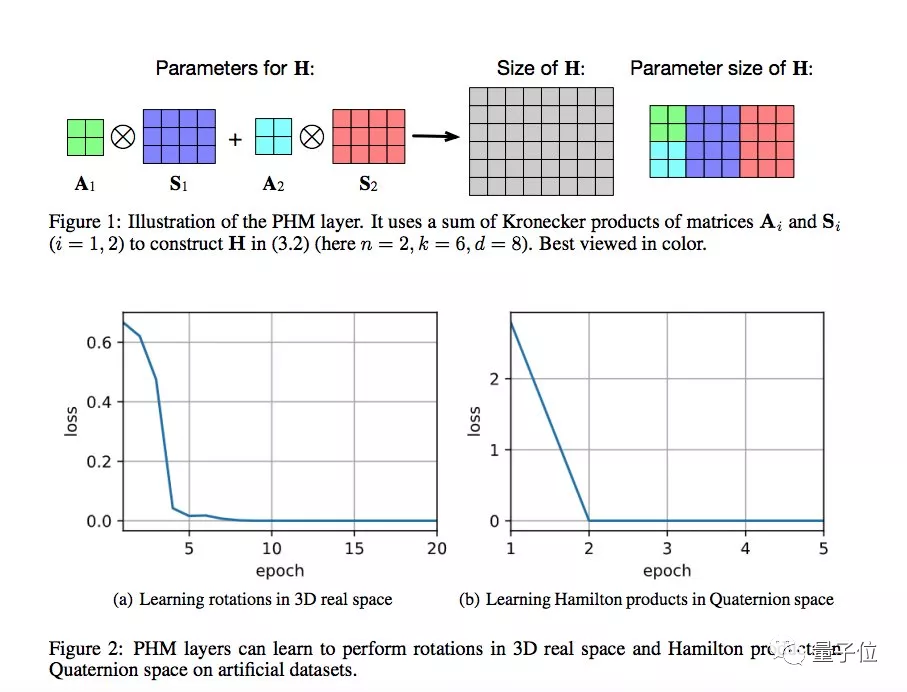
这篇论文提出了一种基于四元数的全连接层(Fully-Connected Layers with Quaternions),用四元数的哈密顿乘积(Hamilton products),替代了全连接层中的实值矩阵乘法,节省了1/4的可学习参数。
论文对超复数乘积进行了参数化,允许模型从数据中学习乘法规则,无需在意这些规则是否被预定义。与普通的全连接层方法相比,这种方法只需要使用1/n(n即维度)的可学习参数。
2、Complex Query Answering with Neural Link Predictors
来自UCL、阿姆斯特丹自由大学。
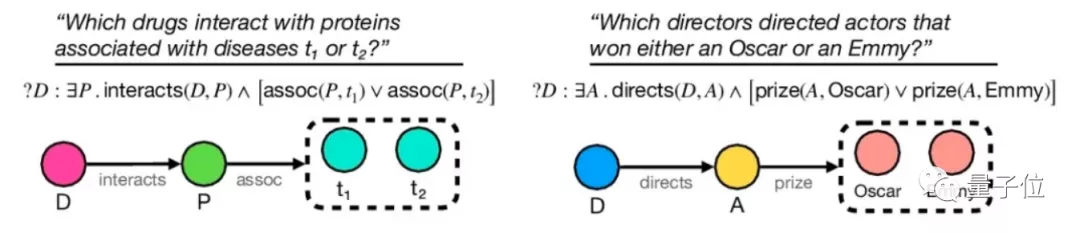
这篇论文提出了一种名为复杂查询分解 (CQD)的框架,通过在嵌入空间实体集上的推理,来回答相对复杂的逻辑查询——回答复杂查询,被简化为回答每个子查询,并通过t-norm聚合所得分数。
只需要训练原子查询的神经网络链接预测模型,就可利用这一框架,来回答给定的复杂查询,而不需要用大量生成的复杂查询进行训练。
同时,无论查询的复杂性如何,这一框架还能对查询回答过程的每一步进行解释。论文所提出的方法与查询类型无关,可以在不明确训练特定类型查询的情况下进行归纳。
3、EigenGame: PCA as a Nash Equilibrium
来自DeepMind、Google。

这篇论文提出了一种天然并行化的随机梯度上升方法EigenGame(本征博弈),结合了Oja规则、Krasulina矩阵和Riemannian优化方法的优点,来计算Top-K主成分。
其中,PCA即博弈纳什均衡、及序列化全局收敛主成分算法。
这种方法为大规模矩阵的PCA计算提供了一种可扩展方法,可计算出近200 TB的Imagenet的RESNET-200激活矩阵的前32个主成分。
4、Learning Mesh-Based Simulation with Graph Networks
来自DeepMind。
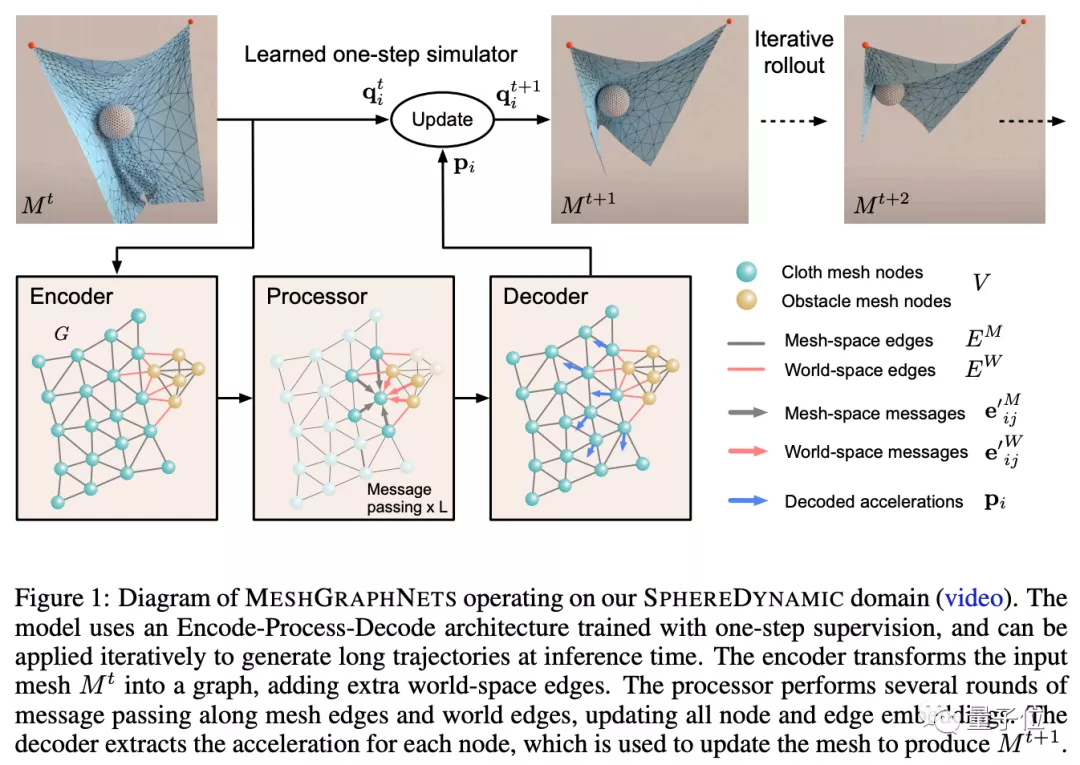
这篇论文介绍了MeshGraphNets,一个用图神经网络进行网格仿真学习的框架。这一框架可以精确地预测各种物理系统的动力学,包括空气动力学、结构力学和织物的形状等。
这种方法拓宽了神经网络模拟器可以运行的问题范围,并有望提高复杂的、科学的建模任务的效率。
5、Neural Synthesis of Binaural Speech From Mono Audio
来自Facebook Reality Lab、CMU。
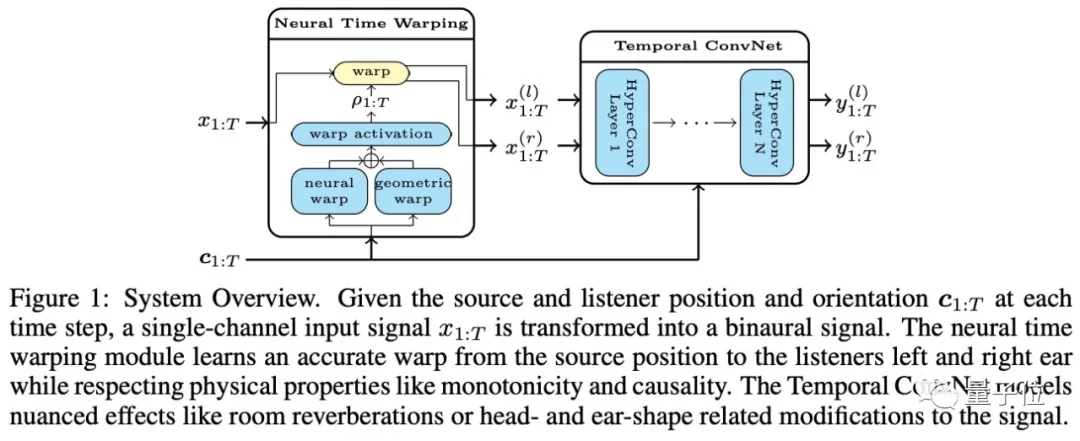
这篇论文提出了一种双声道合成的神经绘制方法,可以实时生成逼真、空间精确的双声道声音。所设计的网络以单声道音频源为输入,根据听者相对于声源的相对位置和方向,将双声道双耳声音合成为输出。
论文从理论上分析了原始波形上l2损耗的不足,并介绍了克服这些局限性的改进损耗。
6、Optimal Rates for Averaged Stochastic Gradient Descent under Neural Tangent Kernel Regime
来自东京大学。
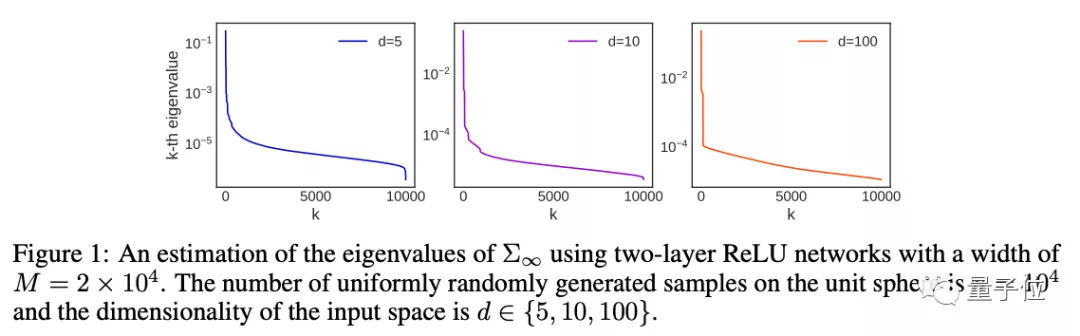
这篇论文分析了过参数化(overparameterized)的双层神经网络回归问题的平均随机梯度下降的收敛性。
论文证明,平均随机梯度下降可以通过利用目标函数的复杂性以及与神经切线核(NTK)相关的再生希尔伯特空间(RKHS),在保证全局收敛的前提下,达到极小极大最优收敛速度。
7、Rethinking Architecture Selection in Differentiable NAS
来自UCLA、理海大学、Amazon。
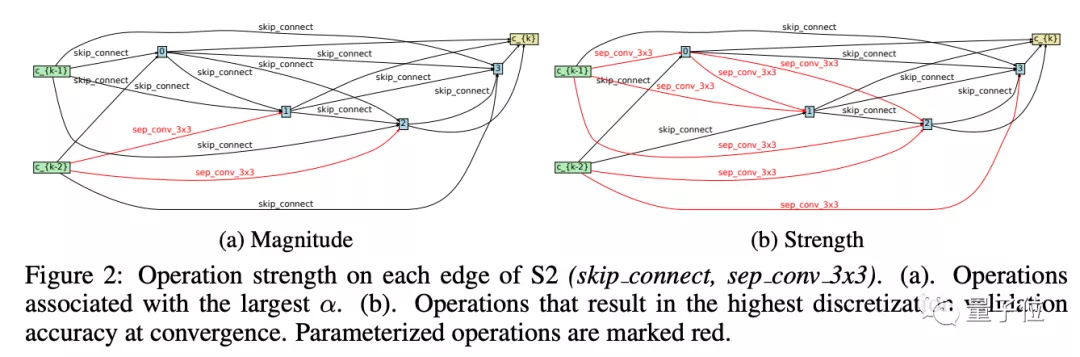
可微神经结构搜索(differential Neural Architecture Search,NAS)以搜索效率高、搜索过程简单等优点,成为当前最流行的神经结构搜索(Neural Architecture Search,NAS)方法之一。
这篇论文分析认为,架构参数的大小,并不一定证明操作对贪心超网络(supernet)性能的贡献效果,并提出了一种可供选择的、基于扰动的体系结构选择,直接测量每个操作对贪心超网络的影响。
8、Score-Based Generative Modeling through Stochastic Differential Equations
来自斯坦福、谷歌、谷歌大脑。
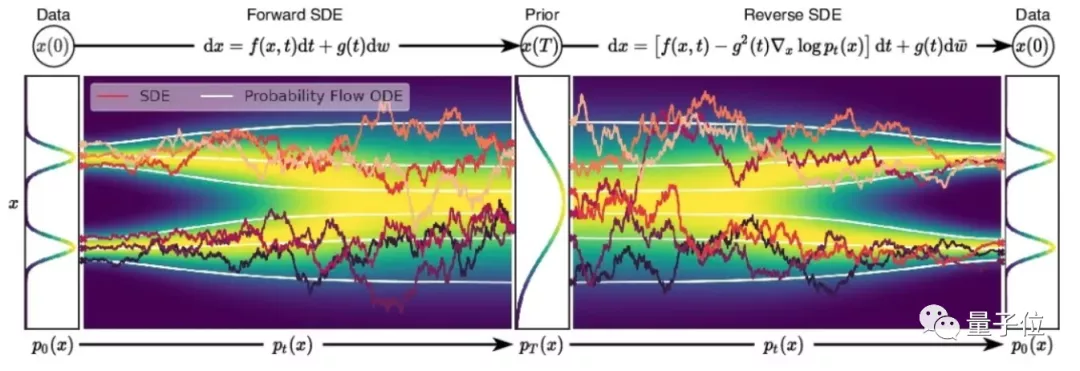
论文提出了一种基于随机微分方程(SDEs)的分数式生成模型框架。其中,SDE通过缓慢注入噪声,平稳地将一个复杂的数据分布转换为一个已知的先验分布,相应的逆时SDE通过缓慢去除噪声将先验分布转换回数据分布。
逆时SDE只依赖于扰动数据分布随时间变化的梯度场(分数),引入了预测-校正框架来纠正离散逆时SDE演化中的错误,推导了与SDE相同的分布采样的等效神经ODE,使精确的似然计算成为可能,并提高了采样效率。
关于杰出论文奖评选
ICLR 2021杰出论文奖,主要从四个方向来考察论文质量:技术质量、影响潜力、是否提出新方向、以及是否解决了重要问题。
今年负责评奖的委员会,成员分别来自Facebook、DeepMind、德州奥斯汀分校、斯坦福大学、微软等各高校和机构。
值得一提的是,虽然ICLR表示:
评分最高的论文也入选了此次奖项。
然而,在这8篇论文中,却并没有见到平均分最高的论文身影。
按平均分来看的话,得分最高的论文名为「How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks」,来自MIT、马里兰大学、华盛顿大学。

它的论文评分是9、9、8、9,平均分8.75,却并未入选此次的杰出论文奖。
相比于这篇论文,确实有几篇入选杰出论文奖的论文,获得过评委打出的10分。
但这两篇论文,却都收到过其他评审6、7分的打分,例如(9、6、6、10)和(7、10、7、7)等。
从打10分的评委评价来看,都是觉得这几篇论文“提出了开创性的观点”。

相比之下,评审在给MIT这篇论文打分时用得更多的评价是“有见解、有意思”。
关于ICLR
ICLR(International Conference on Learning Representations)又名“国际学习表征会议”,2013年举办第一届,由Yoshua Bengio和Yann LeCun牵头创办。
虽然创立时间较晚,但相比于其他顶会,ICLR推行Open Review公开评审制度,所有论文都会公开学校、姓名等信息,并接受所有同行的评价及提问。
在公开评审结束后,作者也能够对论文进行调整及修改。
值得一提的是,ICLR历年会议都只评选过最佳论文奖(Best Papers),今年应该是ICLR首次增加杰出论文奖。
这次ICLR 2021评选的杰出论文奖,国内并没有高校和研究机构入选,但有3篇论文的1作为华人作者。
对论文内容感兴趣的话,可以戳下方链接查看~
ICLR 2021杰出论文奖:
https://iclr-conf.medium.com/announcing-iclr-2021-outstanding-paper-awards-9ae0514734ab
参考链接:
[1]https://docs.google.com/spreadsheets/d/1n58O0lgGI5kI0QQY9f4BDDpNB4oFjb5D51yMr9fHAK4/edit#gid=1546418007
[2]https://openreview.net/group?id=ICLR.cc/2021/Conference
编辑:jq
-
神经网络
+关注
关注
42文章
4765浏览量
100561 -
NAS
+关注
关注
11文章
281浏览量
112371 -
PCA
+关注
关注
0文章
89浏览量
29558
原文标题:ICLR 2021杰出论文奖公布,DeepMind是最大赢家
文章出处:【微信号:cas-ciomp,微信公众号:中科院长春光机所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
四方光电参加2024年中国燃气具行业年会,发表主题演讲并荣获“优秀论文一等奖”

Marvell荣获通用汽车2023年Overdrive奖
对INA226的配置寄存器0x00回读,低八位始终为0xFF,为什么?
中科驭数联合处理器芯片全国重点实验室获得“CCF芯片大会最佳论文奖”
谷歌DeepMind被曝抄袭开源成果,论文还中了顶流会议

南芯科技荣获OPPO 2024 年度“最佳交付奖”和“优秀质量奖”
adxl359的offset寄存器是16位,再进行设置时只有高八位生效,低八位不生效,为什么?
川土微荣获“2024中国IC设计成就奖之年度杰出市场表现奖-汽车电子”

论文遭首届ICLR拒稿、代码被过度优化,word2vec作者Tomas Mikolov分享背后的故事

ICLR 2024高分投稿:用于一般时间序列分析的现代纯卷积结构

声扬科技荣获深圳人工智能“技术发明奖”






 工商网监
工商网监
评论