 了解信息抽取必须要知道关系抽取
了解信息抽取必须要知道关系抽取
本文主要详细解读关系抽取SOTA论文Two are Better than One:Joint Entity and Relation Extraction with Table-Sequence Encoders[1], 顺带简要介绍关系抽取的背景,方便完全不了解童鞋。
信息抽取
我们说的信息抽取一般是指从文本数据中抽取特定数据结构信息的一种手段。对于不同结构形式的数据如结构化文本,半结构化文本,自由文本,有各自对应的方案,其中从自由文本中抽取难度最大。总之,我们的目的是希望在海量文本中,快速抽出我们关注的事实。
了解信息抽取必须要知道关系抽取。
关系抽取
大部分情况下,我们喜欢用三元组的数据结构来描述抽取到的信息
三元组
三元组的表达能力非常丰富,几乎所有事情都可以自然或者强行的表达成三元组,比如随便一句”今天天气真冷“ 表达为天气-状态-冷。
三元组与后续的知识图谱工作非常适配,如Neo4j等图数据库就是以三元组为存储单位,图谱的查询推断等工具使用三元组比普通的关系型数据库来的方便的多。
三元组千千万,我应该怎么抽?
Schema
当我们拿到一个信息抽取的任务,需要明确我们抽取的是什么,”今天天气真冷“,我们要抽的天气的状态天气-状态-冷,而非今天-气候-冷(虽然也可以这样抽),因此一般会首先定义好我们要抽取的数据结构模式shcema, 会确定谓词以及主语并与的类型
一个三元组schema的例子,其中Subject_type代表主语类型,Predicate是谓词,Object_type指宾语类型:
Subject_type:人物 Predicate:出生地 Object_type:地点
确定了schema,我们一般如何抽取呢?
常规RE方案
目前主流关系抽取一般两种解决方法
pipline两步走:将关系抽取分解为NER任务和分类任务,NER任务标注主语或宾语,分类主要针对定义的schema中的有限个谓词进行分类。根据具体任务不同,有些可能是两步走或者三步走,pipline任务的顺序先分类还是先标注也会有差异
Pipline优势:每一步分别针对各个任务进行,表征是task-specific, 相对来说精度较高
Pipline缺陷:- 任务有顺序会存在误差传递问题,即在预测时下一步任务会受上一步误差影响,而在训练阶段没有这种误差,因此存在训练和预测阶段的gap- 分开的任务在一句话中多个实体关系时,比较难解决实体和关系的对应问题,以及重叠关系
joint learning:joint learing可以理解为采用多任务的方式,同时进行NER和关系分类任务, 在众多joint learning中最出众的是采用tabel filled 方式,即任务的输出是filled一张有text-sequence构成的表,在表中的位置表达除了词与词的连接,该位置的标注则标出了谓语(如下图)
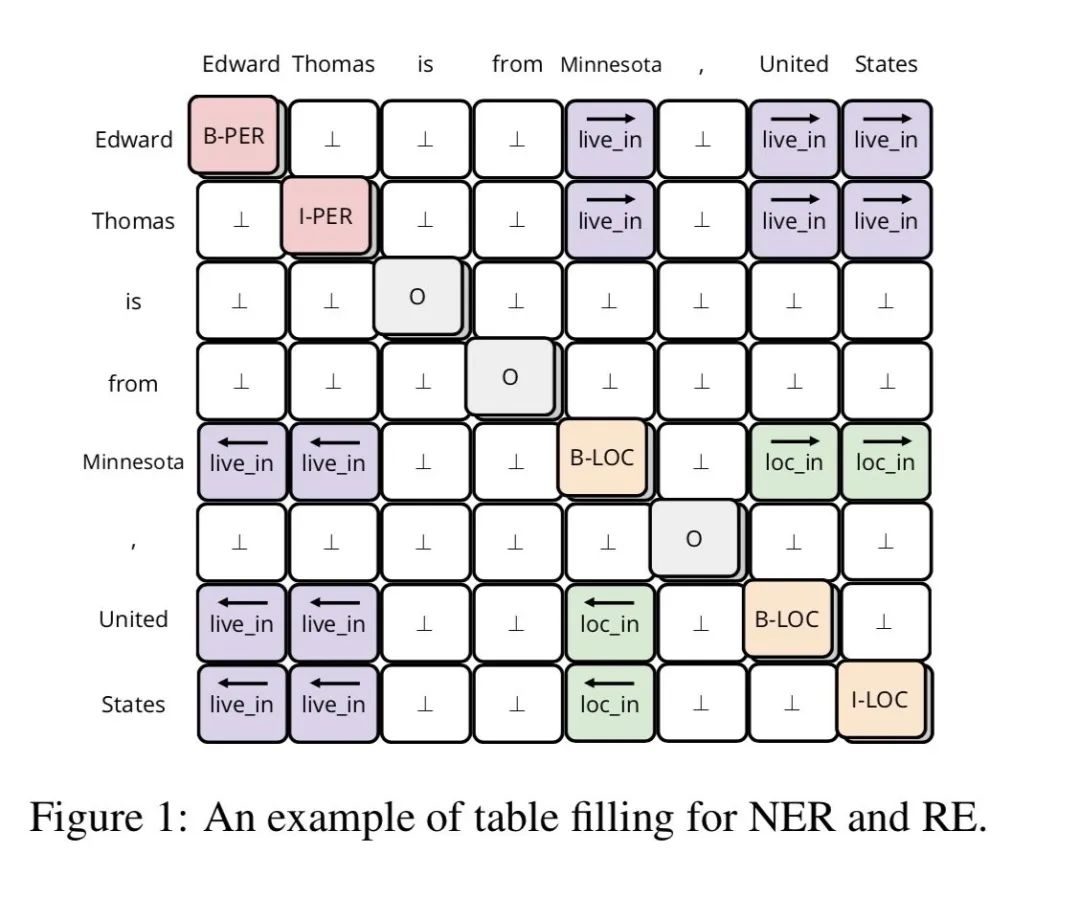
优势:1. 两个任务的表征有交互作用可能辅助任务的学习2. 不用训练多个模型,一个模型解决问题,不存在训练与预测时的gap
缺陷:1. 两个任务的表征可能冲突,影响任务效果2. 解决了主谓宾之间的对应关系,无法解决重叠问题3. Fill table本质仍然是转成sequence来fill,未能充分利用table结构信息(下文会解释)
下面重点解读table fill方式的一篇SOTA,解决了joint learning的多任务表征冲突以及为利用table结构信息
RE with Table Sequence
终于来到本篇的主题啦,为了解决一般filled table的问题, 作者提出table-sequence encoder的方法,分别对table和sequence做表征,本文的最大贡献在于
分别对table和sequence做表征(encoder),并设计了一个Table-Guided Attention来对table和sequence进行交互,这样即不会完全共享表征导致对不同的任务表征冲突,也不会丢失表征的相互指导作用
在table encoder中采用多维GRU来捕获更多的句子结构信息
在架构上table encoder和 sequence encoder多层交互
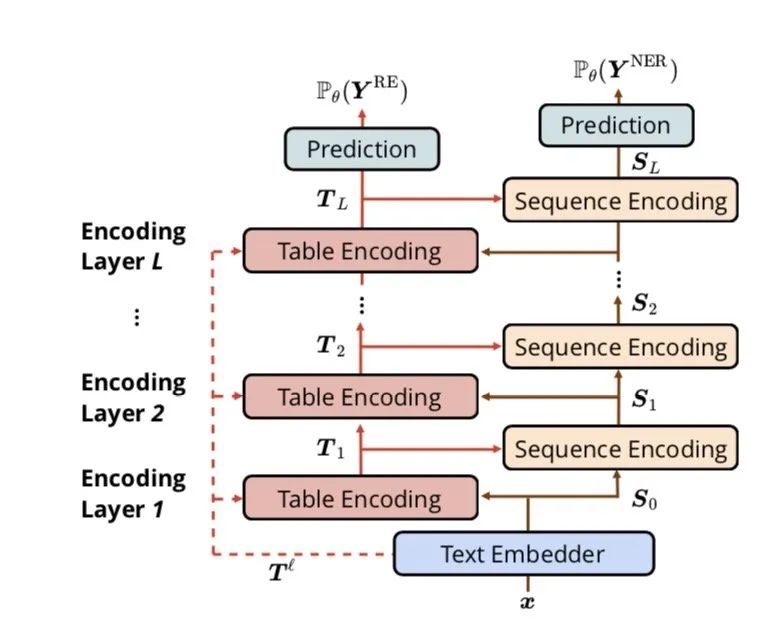
下面仔细介绍各个部分,看看它是如何神奇做到SOTA的
Text Embedder
在上图的结构图中,Text Embedder采用类似FLAT分别做了基于lstm的char()和word(),以及基于bert的word ()作为预训练的embedding ,并拼接起来
图中
Table Encoder
整个Table Encoder部分由多个Table Encoding的单元组成,每个Encoding单元的输入分别是起始输入,对应senquence结构的输入,以及上一个Tabel Encoding单元的输出,Table Encoding 采用MDRNN结构提取输入的特征信息,作者在这选择MDGRU(多维度GRU),tabel结构本身有2维,加上前后层实际有4维,但是层的维度信息单向流动,实际上是只用到了3个方向()
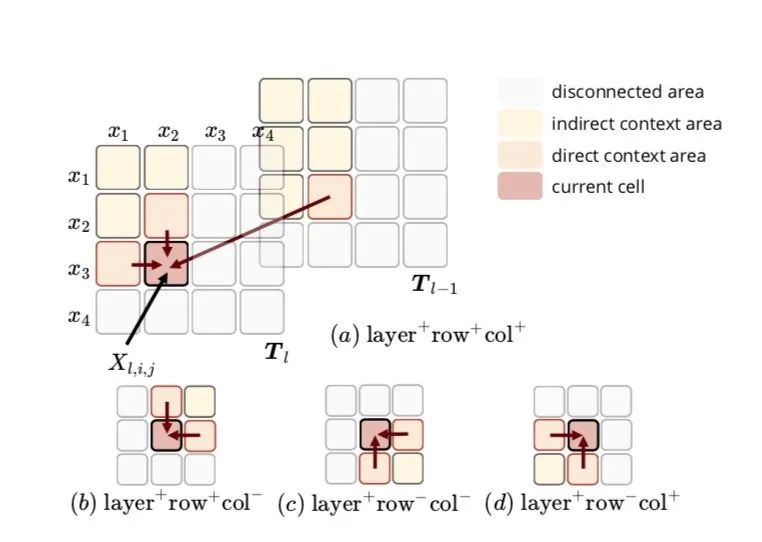
如图所示,是来自sequence的输入,作者分别测了使用所有方向和分别使用几个方向,发现上图中a,c效果类似,这种多维GRU全面的考虑了整个table的结构信息,即一个词的状态跟其他所有词的状态相关,并且受其他词的不同程度的影响,这种影响程度由GRU门控机制控制
Sequence Encoder
sequence Encoder 也由多个sequence encoding够成,sequence encoding结构直接采用transformer中的encoder
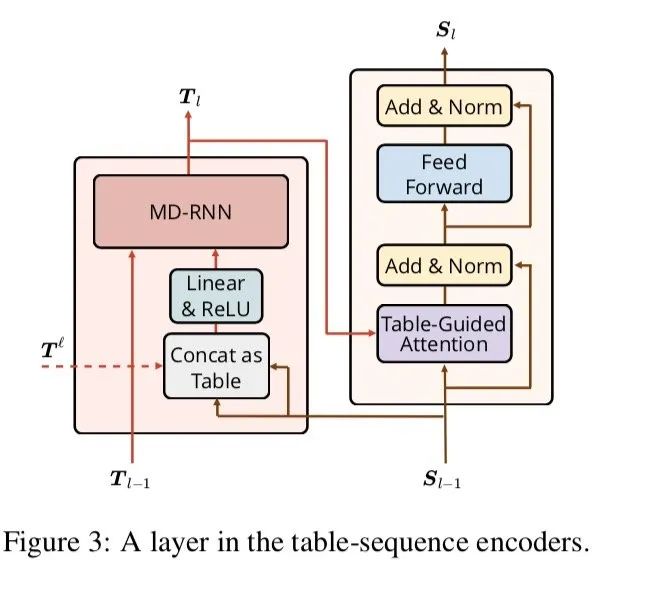
只不过将其中的self attention替换为table-guide attention,这种attention的改造非常巧妙,能更好捕捉word-word之间的关系
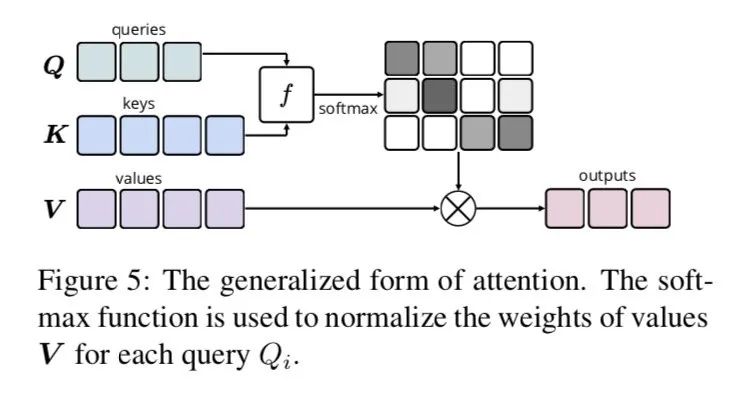
正常的dot attention如上图
Table-Guided attention具体来说:
为参数矩阵
采用加性
是table encoder中的table的隐藏节点,该节点由多个方向的经过GRU编码得到,不管是哪个方向它的来源始终是由构造而来,理论上是可以由拟合而来,因此这里直接由 来代替 ,也就是这个attention,其实是计算了table 结构中各个位置对该的权重,是一个四面八方attention
剩下就是transform中正常的LayerNorm 和残差结构了
输出和loss
输出比较常规,loss采用常规
输出:
loss:
实验 and 效果
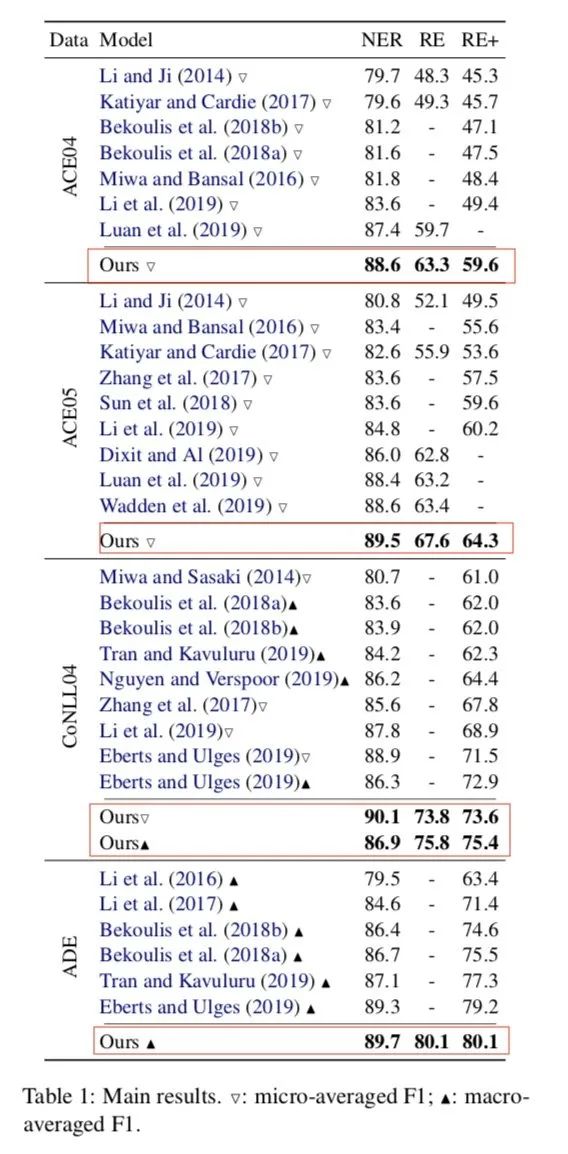
作者在各个数据集上进行实验,对比各个目前SOTA分别有一定的提高,且时效果最佳,模型参数量不到5M,要什么自行车,附上开源地址[2],作者的代码与论文在attention计算有一丢丢不一致,但是并不影响效果
责任编辑:lq
-
数据库
+关注
关注
7文章
3855浏览量
64797 -
Gru
+关注
关注
0文章
12浏览量
7512 -
数据结构
+关注
关注
3文章
573浏览量
40251
原文标题:关系抽取一步到位!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMC1210对AMC1305进行数字抽取滤波,输出后的数据是否需要用处理器进行一次平均和移位处理?
使用AMC1210为AMC1305L25做3阶的256抽1的sinc抽取滤波器,请问是否可以呢?
请问AMC1203文档中的OSC过采样率和sinc3滤波器中的抽取率是不是同一个概念?
轨道交通行业 ICY DOCK硬盘抽取盒解决方案

ADS1299用ADS采集数据,ADS可以不抽取看原始得数据吗?
求助,关于AMC1306M25抽取率OSR的疑问求解
TLV320AIC3254内部中的ADC处理模块和minidsp到底是什么关系?
有奖问卷:随机抽取 30 名用户送出快充数据线
求助,AD7190关于Σ-Δ ADC其中的抽取滤波器的数据转换问题求解
防水和防振动功能2.5 英寸SAS/SATA硬盘抽取盒 非常适合车载数据存储

学习鸿蒙必须要知道的几个名词

ICY DOCK Expresscage MB038SP-B硬盘抽取盒评测

用STM8做一个用于抽取频谱的东西, 如何采样128个点用于FFT数据计算?
企业级装机必备推荐 不用拆机的4盘位U.2 硬盘抽取盒






 工商网监
工商网监
评论