 解读一下DeBERTa在BERT上有哪些改造
解读一下DeBERTa在BERT上有哪些改造
DeBERTa刷新了GLUE的榜首,本文解读一下DeBERTa在BERT上有哪些改造
DeBERTa对BERT的改造主要在三点
分散注意力机制
为了更充分利用相对位置信息,输入的input embedding不再加入pos embedding, 而是input在经过transformer编码后,在encoder段与“decoder”端 通过相对位置计算分散注意力
增强解码器(有点迷)
为了解决预训练和微调时,因为任务的不同而预训练和微调阶段的gap,加入了一个增强decoder端,这个decoder并非transformer的decoder端(需要decoder端有输入那种),只是直观上起到了一个decoder作用
解码器前接入了绝对位置embedding,避免只有相对位置而丢失了绝对位置embedding
其实本质就是在原始BERT的倒数第二层transformer中间层插入了一个分散注意力计算
训练trick
训练时加入了一些数据扰动
mask策略中不替换词,变为替换成词的pos embedding
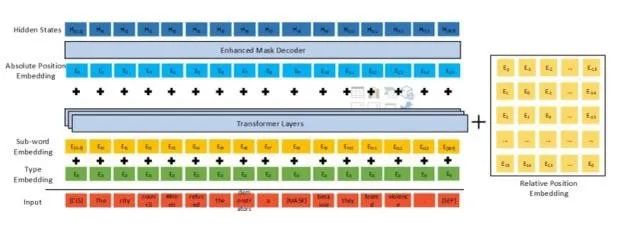
分散注意力机制
motivation
BERT加入位置信息的方法是在输入embedding中加入postion embedding, pos embedding与char embedding和segment embedding混在一起,这种早期就合并了位置信息在计算self-attention时,表达能力受限,维护信息非常被弱化了
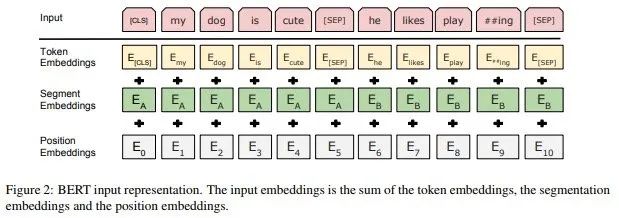
BERT embedding
本文的motivation就是将pos信息拆分出来,单独编码后去content 和自己求attention,增加计算 “位置-内容” 和 “内容-位置” 注意力的分散Disentangled Attention
Disentangled Attention计算方法
分散注意力机制首先在input中分离相对位置embedding,在原始char embedding+segment embedding经过编码成后,与相对位置计算attention,
即是内容编码,是相对的位置编码, attention的计算中,融合了位置-位置,内容-内容,位置-内容,内容-位置
相对位置的计算
限制了相对距离,相距大于一个阈值时距离就无效了,此时距离设定为一个常数,距离在有效范围内时,用参数用控制
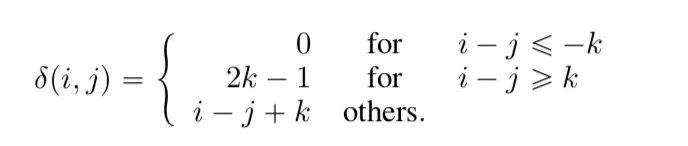
增强型解码器
强行叫做解码器
用 EMD( enhanced mask decoder) 来代替原 BERT 的 SoftMax 层预测遮盖的 Token。因为我们在精调时一般会在 BERT 的输出后接一个特定任务的 Decoder,但是在预训练时却并没有这个 Decoder;所以本文在预训练时用一个两层的 Transformer decoder 和一个 SoftMax 作为 Decoder。其实就是给后层的Transformer encoder换了个名字,千万别以为是用到了Transformer 的 Decoder端
绝对位置embedding
在decoder前有一个骚操作是在这里加入了一层绝对位置embedding来弥补一下只有相对位置的损失,比如“超市旁新开了一个商场”,当mask的词是“超市”,“商场”,时,只有相对位置时没法区分这两个词的信息,因此decoder中加入一层
一些训练tricks
将BERT的训练策略中,mask有10%的情况是不做任何替换,这种情况attention偏向自己会非常明显,DeBeta将不做替换改成了换位该位置词绝对位置的pos embedding, 实验中明显能看到这种情况下的attention对自身依赖减弱
在训练下游任务时,给训练集做了一点扰动来增强模型的鲁棒性
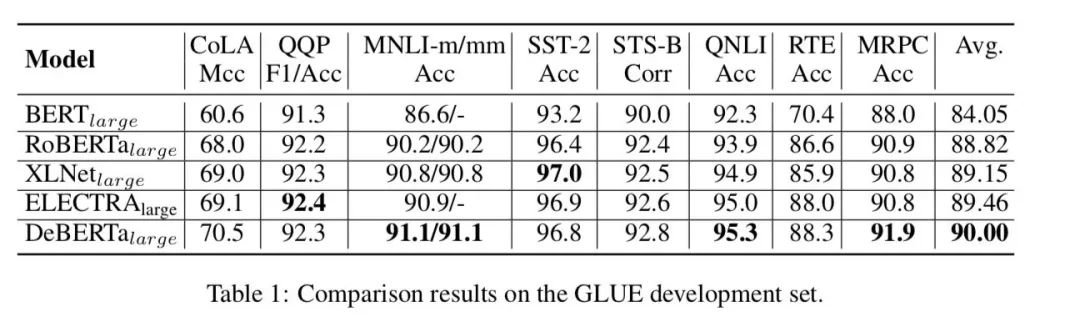
效果
DeBERTa large目前是GLUE的榜首,在大部分任务上整体效果相比还是有一丢丢提升
责任编辑:lq
-
数据
+关注
关注
8文章
7067浏览量
89107 -
编码
+关注
关注
6文章
945浏览量
54850 -
Decoder
+关注
关注
0文章
25浏览量
10709
原文标题:SOTA来啦!BERT又又又又又又魔改了!DeBERTa登顶GLUE~
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
“碰一下”支付背后的4G技术
支付宝发布新一代AI视觉搜索“探一下”
建议DFM工具里的拼版在完善一下
内置误码率测试仪(BERT)和采样示波器一体化测试仪器安立MP2110A

自感线圈断电时灯泡为啥会闪亮一下
AWG和BERT常见问题解答
请问一下ESP8266有没有位操作或者位带的功能?
欢创播报 支付宝“碰一下”正式发布

求助,求大神帮忙解答下AN65974同步Slave FIFO的读时序
总结一下LM317的几种经典应用电路
简单介绍一下电源纹波与电容啸叫
体验一下这款免费的云手机,大家觉得效果怎么样?
盘点一下高通CES 2024汽车创新技术






 工商网监
工商网监
评论