 计算机视觉可以学习美式手语,进而帮助听力障碍群体吗?
计算机视觉可以学习美式手语,进而帮助听力障碍群体吗?

前言
计算机视觉可以学习美式手语,进而帮助听力障碍群体吗?数据科学家David Lee用一个项目给出了答案。
如果听不到了,你会怎么办?如果只能用手语交流呢?
当对方无法理解你时,即使像订餐、讨论财务事项,甚至和朋友家人对话这样简单的事情也可能令你气馁。对普通人而言轻轻松松的事情对于听障群体可能是很困难的,他们甚至还会因此遭到歧视。
在很多场景下,他们无法获取合格的翻译服务,从而导致失业、社会隔绝和公共卫生问题。为了让更多人听到听障群体的声音,数据科学家 David Lee 尝试利用数据科学项目来解决这一问题:计算机视觉可以学习美式手语,进而帮助听力障碍群体吗?
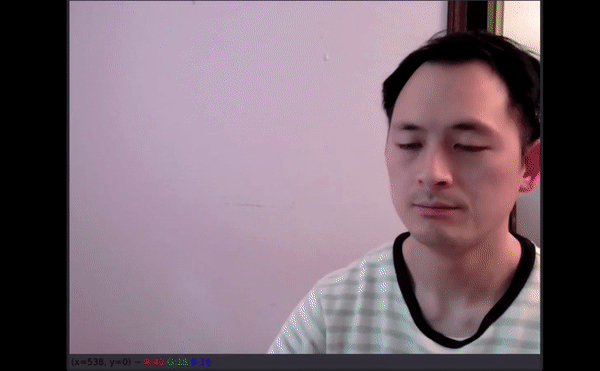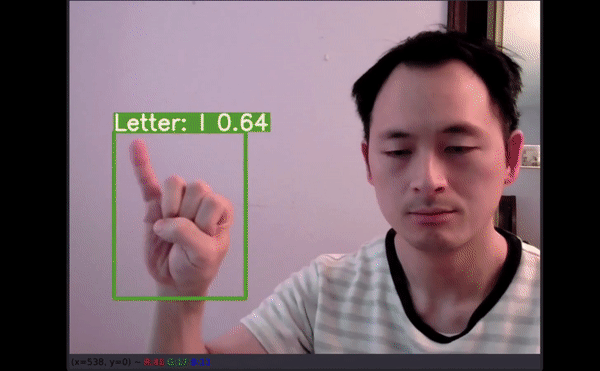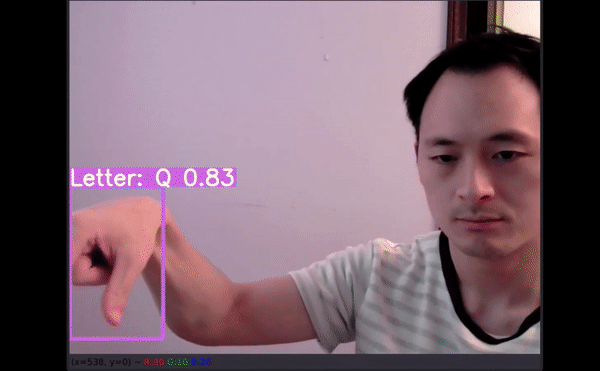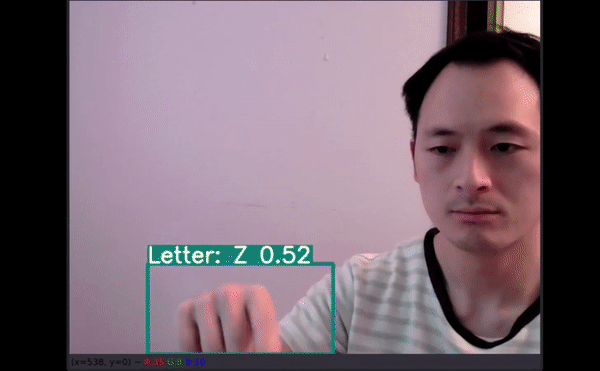
如果通过机器学习应用可以精确地翻译美式手语,即使从最基础的字母表开始,我们也能向着为听力障碍群体提供更多的便利和教育资源前进一步。
数据和项目介绍
出于多种原因,David Lee决定创建一个原始图像数据集。首先,基于移动设备或摄像头设置想要的环境,需要的分辨率一般是720p或1080p。现有的几个数据集分辨率较低,而且很多不包括字母「J」和「Z」,因为这两个字母需要一些动作才能完成。

为此,David Lee 在社交平台上发送了手语图像数据收集请求,介绍了这个项目和如何提交手语图像的说明,希望借此提高大家的认识并收集数据。
数据变形和过采样
David Lee 为该项目收集了 720 张图片,其中还有几张是他自己的手部图像。由于这个数据集规模较小,于是 David 使用 labelImg 软件手动进行边界框标记,设置变换函数的概率以基于同一张图像创建多个实例,每个实例上的边界框有所不同。下图展示了数据增强示例:

经过数据增强后,该数据集的规模从 720 张图像扩展到 18,000 张图像。
建模
David 选择使用 YOLOv5 进行建模。将数据集中 90% 的图像用作训练数据,10% 的图像用作验证集。使用迁移学习和 YOLOv5m 预训练权重训练 300 个 epoch。

在验证集上成功创建具备标签和预测置信度的新边界框。
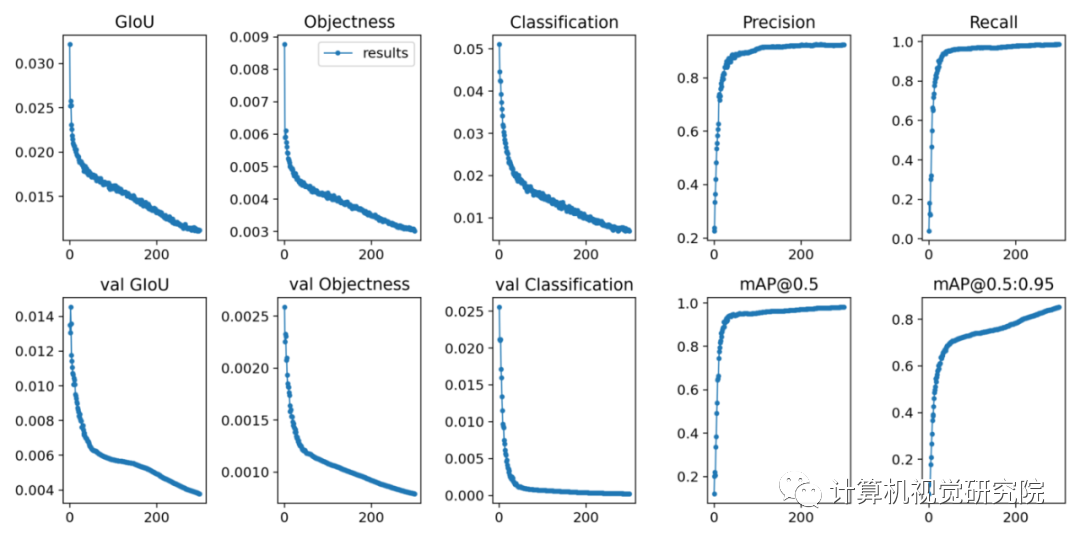
由于损失值并未出现增长,表明模型未过拟合,因此该模型或许可以训练更多轮次。模型最终获得了 85.27% 的 mAP@.5:.95 分数。
图像推断测试
David 额外收集了他儿子的手部图像数据作为测试集。事实上,还没有儿童手部图像用于训练该模型。理想情况下,再多几张图像有助于展示模型的性能,但这只是个开始。

26 个字母中,有 4 个没有预测结果(分别是 G、H、J 和 Z)。四个没有得到准确预测:
D 被预测为 F;
E 被预测为 T;
P 被预测为 Q;
R 被预测为 U。
视频推断测试
即使只有几个手部图像用于训练,模型仍能在如此小的数据集上展现不错的性能,而且还能以一定的速度提供优秀的预测结果,这一结果表现出了很大的潜力。更多数据有助于创建可在多种新环境中使用的模型。如以上视频所示,即使字母有一部分出框了,模型仍能给出不错的预测结果。最令人惊讶的是,字母 J 和 Z 也得到了准确识别。
其他测试
执行其他一些测试,例如:左手手语测试
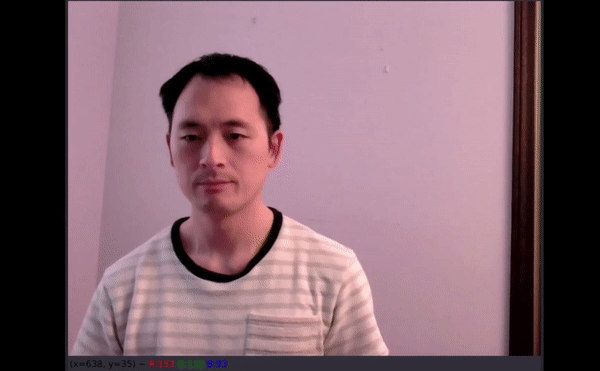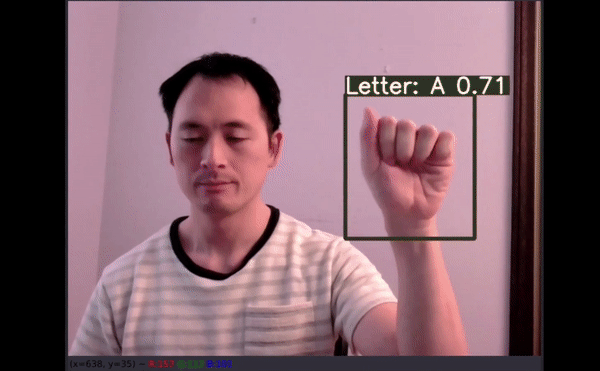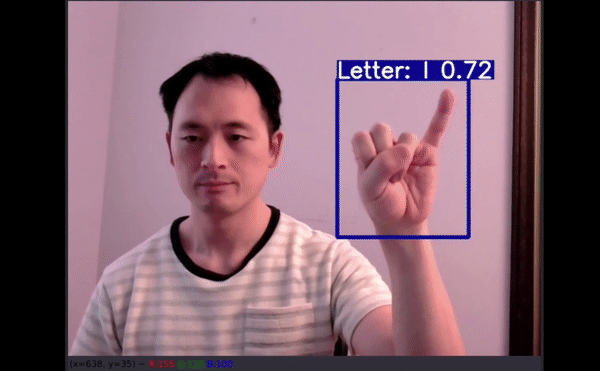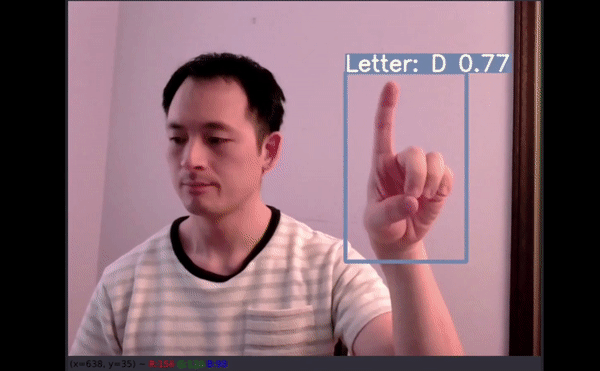
几乎所有原始图像都显示的是右手,但惊喜地发现数据增强在这里起到了作用,因为有 50% 的可能性是针对左手用户进行水平翻转。
儿童手语测试

儿童的手语数据未被用于训练集,但模型对此仍有不错的预测。
多实例

尽管手语的使用和视频中有所不同,但这个示例表明当多个人出现在屏幕上时,模型可以分辨出不止一个手语实例。
模型局限性
发现该模型还有一些地方有待改进。
距离

许多原始图像是用手机拍摄的,手到摄像头的距离比较近,这对远距离推断有一定负面影响。
新环境

这支视频来自于志愿者,未用于模型训练。尽管模型看到过很多字母,但对此的预测置信度较低,还有一些错误分类。
背景推断

该测试旨在验证不同的背景会影响模型的性能。
结论
这个项目表明:计算机视觉可用于帮助听力障碍群体获取更多便利和教育资源!该模型在仅使用小型数据集的情况下仍能取得不错的性能。即使对于不同环境中的不同手部,模型也能实现良好的检测结果。
而且一些局限性是可以通过更多训练数据得到解决的。经过调整和数据集的扩大,该模型或许可以扩展到美式手语字母表以外的场景。

责任编辑:lq
-
手势识别
+关注
关注
8文章
233浏览量
49305 -
计算机视觉
+关注
关注
9文章
1716浏览量
47730 -
数据集
+关注
关注
4文章
1240浏览量
26262
原文标题:YOLOv5的项目实践 | 手势识别项目落地全过程(附源码)
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
计算机专业408考研科目
传音相关研究成果入选计算机视觉顶会CVPR 2026

十进制计算机硬件体系结构及“独值”量化逻辑运算革命(一)

上海计算机视觉企业行学术沙龙走进西井科技
使用代理式AI激活传统计算机视觉系统的三种方法
工控机与普通计算机的核心差异解析

STM32计算机视觉开发套件:B-CAMS-IMX摄像头模块技术解析


【作品合集】赛昉科技VisionFive 2单板计算机开发板测评
易控智驾荣获计算机视觉顶会CVPR 2025认可
工业计算机的重要性

自动化计算机经过加固后有什么好处?
自动化计算机的功能与用途

工业计算机与商用计算机的区别有哪些

利用边缘计算和工业计算机实现智能视频分析



评论