 详解机器学习在铁路缺陷检测中的实际应用
详解机器学习在铁路缺陷检测中的实际应用

机器学习在铁路缺陷检测中的实际应用
本文介绍了在铁轨的超声波检测过程中有效使用机器学习技术自动检测缺陷的经验,并提出了一种使用数学建模为神经网络创建训练数据集的有效方法,为实际缺陷图的识别提供了更高精度的指标。文中训练神经网络运算的原型实例,其实际缺陷图的预测精度高达92%。
铁轨在列车行进过程中往往承受着巨大的压力,而这一过程可能会产生导致火车发生事故的缺陷。
铁轨缺陷与预防性检测是铁路安全领域的一个极其重要的领域。本文将对广泛应用于火车铁轨诊断的超声波检测技术进行阐述和分析。
分析缺陷检测结果面临的一个主要问题是,目前缺乏在数百公里的铁轨上捕获缺陷数据的自动检测能力。而在人工搜索缺陷时,遗漏缺陷的可能性很高,并且其结果主要取决于检测人员的经验和人为因素。
问题陈述
在这项工作中,主要的任务是创建一个神经网络的工作原型,以自动检测铁轨超声检测图上的缺陷,其准确性需要超过85%。
超声波检测中的铁轨缺陷的分类
为了训练神经网络,需要以数字形式对铁轨进行超声波检查的初始数据,这些数据可以使用相应的缺陷图的检测仪获得,这些检测仪以B扫描(BSCAN)的形式显示。
BSCAN形成的原理是将脉冲超声波信号以一定的角度和距离输入到铁轨中,并记录其反射信号(如图2所示)。在反射信号强度图中,不同的输入角度的信号生成不同亮度的点。使用不同输入角度的超声波信号探测是由于缺陷具有不同性质,而反映信号的深度取决于缺陷的深度和形状。
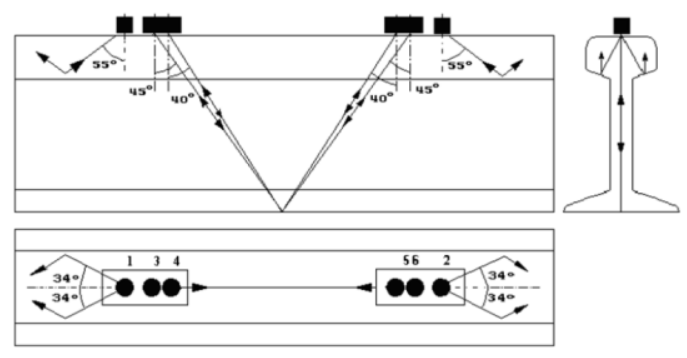
图2:使用六个传感器的铁轨测深方案示例
为了对缺陷进行分类,需要考虑铁轨缺陷分类的原则。而根据PJSC俄罗斯铁路公司2017年推出的文件“关于无损铁轨检测结果解密的声明”,其分类的所有铁轨缺陷都用三位数字进行编码。
为了创建数据集,以下选择了8个最常见的缺陷。表1和表2显示了所选铁轨缺陷的视图、缺陷代码以及BSCAN的外观。
表1:缺陷代码及其缺陷图列表的第1部分
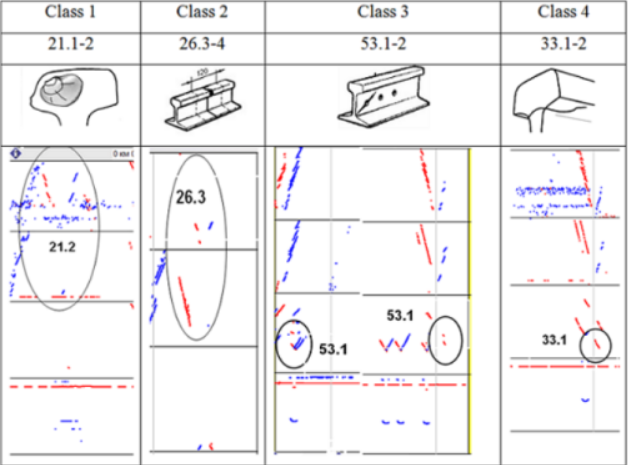
表2:缺陷代码及其缺陷图列表的第2部分
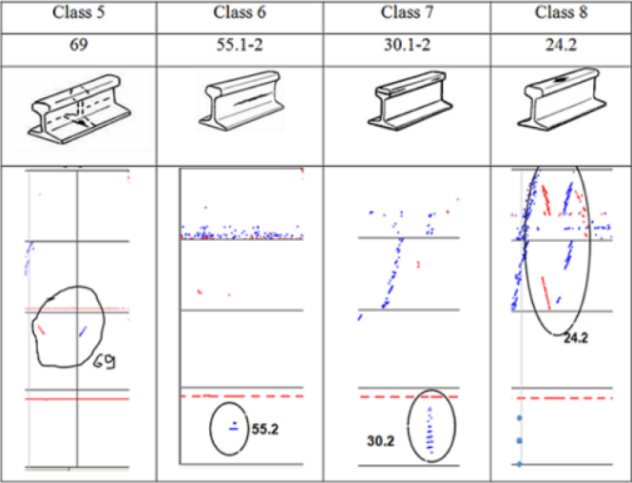
在实际缺陷图框架上训练的神经网络第一版
对现有缺陷图数据库的分析表明,由于各种制造商生产的设备具有各种信号处理算法、不同数量的发射器和接收器,因此无法同时使用它们。对于每个缺陷组都采用了Avikon-11检测仪,根据估计,在两个车站之间的铁轨获得的缺陷不会超过20个,而这对于创建有效的神经网络来说,这些缺陷的数量非常少。因此,在特定位置的参考缺陷铁轨的现有站点上也采用了一组缺陷图。这样的一段铁路被称为“控制死区”。图3显示了一条铁轨控制死区的缺陷图。
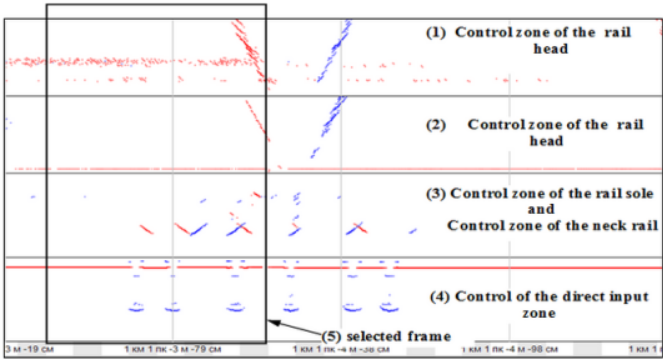
图3:采用Avikon-11检测仪显示的一根铁轨截面的缺陷图
可以将连续的缺陷图“切割”为单独的片段,然后将其分类并保存为单独的文件——帧。图3(第5点)所示的每个切割的帧同时包括沿其铁轨截面的所有检查区域。其测量通道的这种综合考虑允许使用所有可用的信息特征来对缺陷图帧进行分类。而[500,800]个条件点组成的帧数量很大,在训练神经网络时需要大量的时间和计算成本。此外,它还需要较大的数据集。为了扩大带有缺陷的数据集规模,可以使用一种偏移帧方法,如图4所示。因此可以在一个缺陷上获得50个以上的帧。这种方法允许将9个类的数据集从1,000个增加到60,000个,其中0类是无缺陷的铁轨。
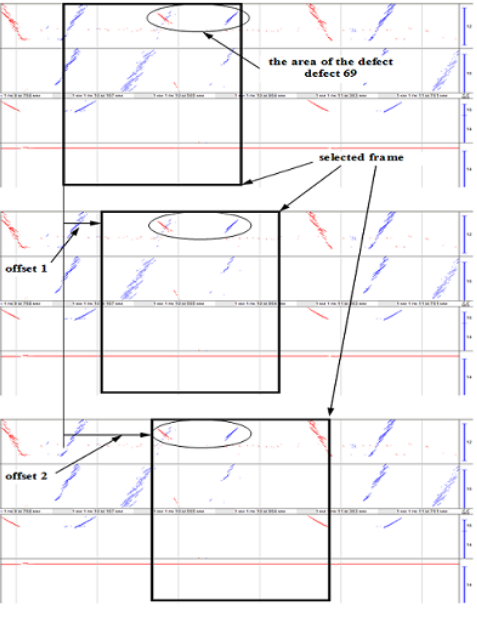
图4:用于创建带有缺陷的扩展数据集的帧
在这一过程中,合成了一个卷积神经网络用于无歧义的分类,其输出端有一个完全连接的分类器(CNN)。经过训练的神经网络在验证数据上显示35%的准确性。而每个可用的9类的准确率比纯粹的随机分类器要高出3倍。由于选择了神经网络的结构和超参数,因此无法提高识别精度。在这一阶段,缺少规模足够大的通用数据集是导致神经网络效率低下的关键因素。
基于模型数据训练的神经网络第二版
基于模型数据训练的神经网络第一版的效率比较低下的原因并不是因为使用的算法不佳,而是由于缺乏针对其训练的代表性的数据集,这才是关键因素。在测试铁轨时,由于获得新数据而导致数据集的增加是一个漫长的过程,可能会持续数年的时间。在这里实施的任务是考虑使用模型数据训练神经网络的可能性。
建模是加快增加数据集过程的一种方法,因此有必要基于数学模型,来获得具有不同类别的缺陷图帧的样本。
建模类型选择
神经网络操作及其训练的主要原理是抽象化在输入端接收到的可见图像,将其转换为高级视觉概念,并同时过滤不重要的视觉细节。神经网络应该只记住图像,而细节只会妨碍它识别,这就是不必在铁轨中创建精确的超声波传播物理模型的原因。超声波在铁轨中传播的物理模型不能解决导致各种形式的缺陷及其位置的问题。此类缺陷需要人工创建,数量多达数万个。而在铁轨中引入超声波并测量反射信号的模型、随机性、对许多因素(生成器位置等)的依赖性等问题也没有得到解决。
在这项工作中提出了一种方法,该方法包括创建参数仿真模型,基于该模型可以生成一个数据集,用于训练处理数以千计的每类缺陷的神经网络。
为了构建这种神经网络的工作原型,选择了超声波输入角为α=0(严格向下)的通道。其帧长(沿铁轨长度)增加到1000个条件点,这对识别的准确性非常重要。
数学模型是在LabVIEW环境中开发的,用于原型设计和建模。所获得的数学模型不仅考虑从反射器获得的波形,而且考虑振幅的分布。在公共参数模型的输出处获得的每个帧都是唯一的,这是因为该模型的每个参数都有随机生成器。表3和表4显示了铁轨中各个异质结构的测量数据和模型数据的BSCAN示例。
表3:铁轨螺栓孔的实测数据和模型数据的BSCAN示例
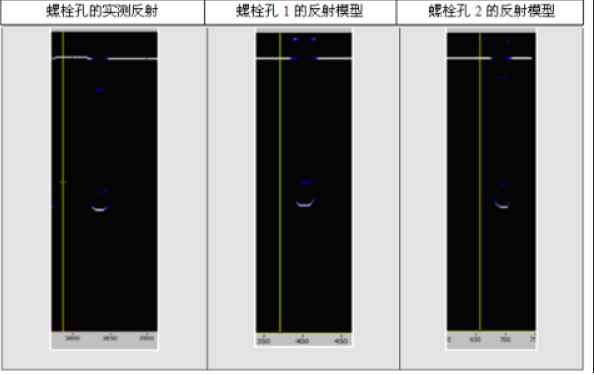
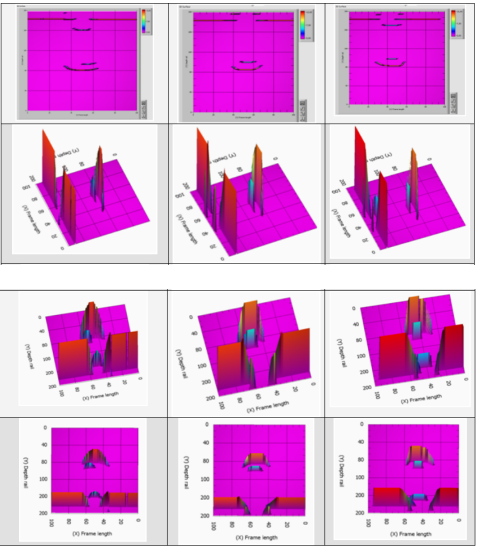
表4:30组实测缺陷和模型缺陷扫描(表面缺陷和轨头缺陷)

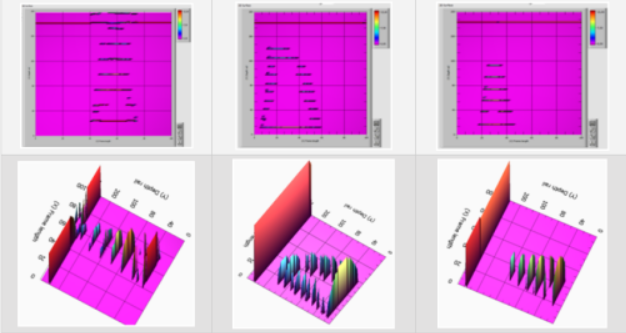
将单个铁轨故障的超声波检查的测量数据与获得的模型数据进行比较,可以了解它们的相似性。建议基于神经网络识别实际缺陷的准确性指标来检查所获得模型的适当性,该神经网络将从模型数据中学习。
从不同的铁轨故障模型中,可以获得对铁轨进行超声波检查的帧。与此同时,模型的参数将会发生变化,以获得在实际条件下可能发生的各种组合,也就是:
各种深度的缺陷;
各种坐标的缺陷;
以螺栓孔的形式存在的缺陷和过程反射器的各个相对位置;
根据螺栓孔数的不同,螺栓连接的组合方式不同;
铁轨中不同形式的缺陷和工艺异质结构;
铁轨中所有异类结构的振幅响应随机性。
模型数据样本的示例
图5显示了具有30组缺陷-表面缺陷和轨头缺陷模型帧的样本。
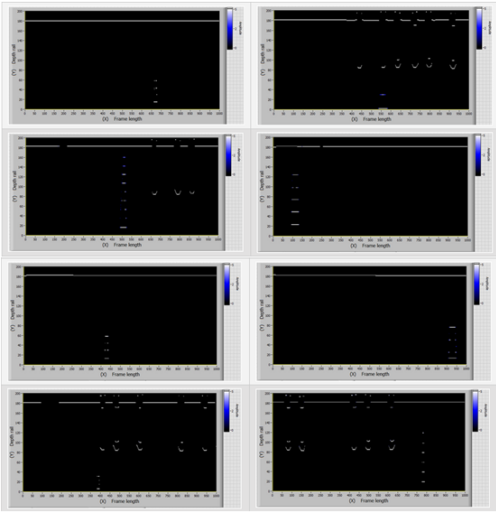
图5:具有30组缺陷的模型帧样本—表面缺陷和轨头缺陷
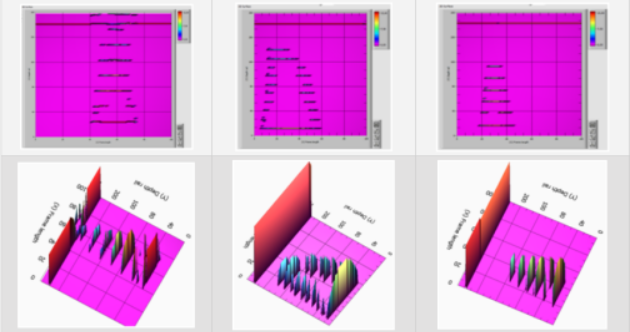
为了进行比较,图6显示了来自Avikon-11检测仪的实际数据。

图6:具有第30组缺陷的真实帧的样本—表面缺陷(轨头缺陷)
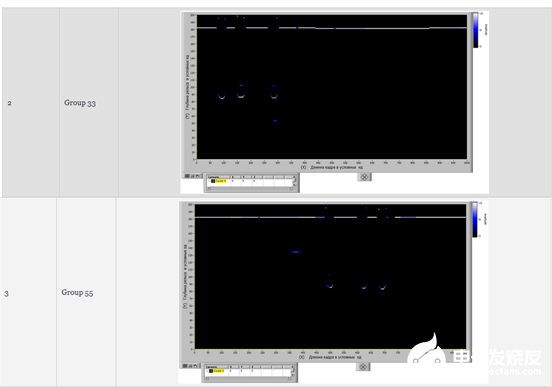
图7显示了具有33组缺陷—轨颈缺陷模型帧的样本。
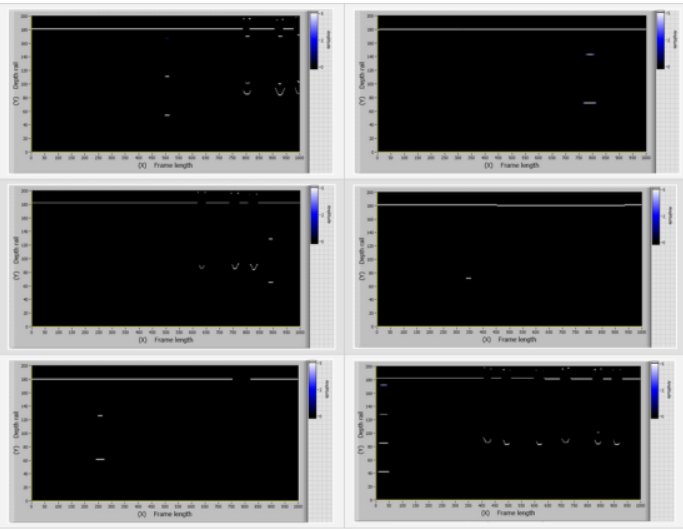
图7:具有33组缺陷—轨颈缺陷模型帧的样本
为了进行比较,图8显示了来自Avikon-11检测仪的实际数据。

图8:具有33组缺陷-轨颈缺陷实际帧的样本
图9显示了具有55组缺陷(轨颈中的缺陷)模型帧的样本。图10显示了具有55组缺陷的实际帧。

图9:具有55组缺陷-—轨颈缺陷模型帧的样本
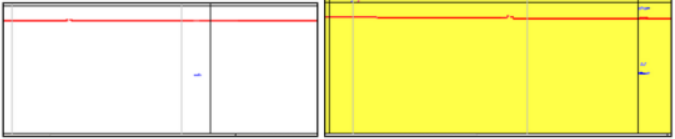
图10:具有55组缺陷—-轨颈缺陷实际帧的样本
图11显示了具有无缺陷条件(带有和不带有螺栓孔)模型帧的样本。
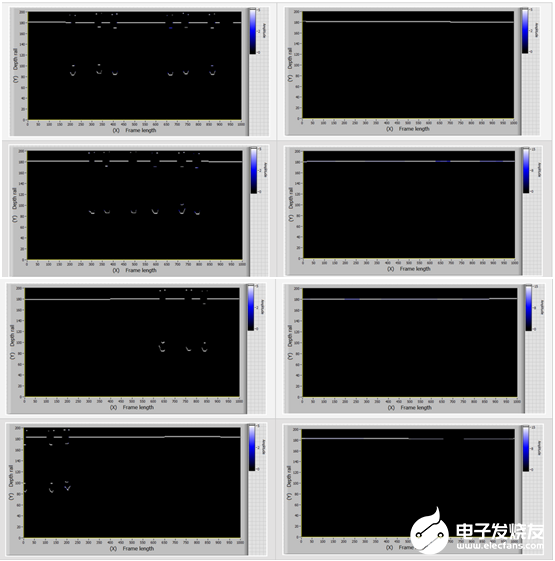
图11:处于无缺陷状态(有螺栓孔和不带有螺栓孔)模型帧的样本
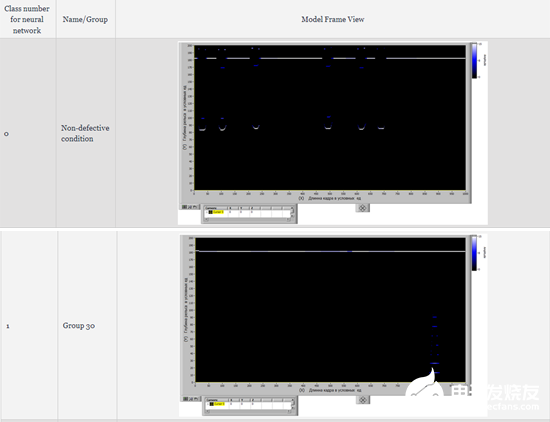
根据表5为每组模型帧分配一个类别编号(编码标记)
表5-分配类别
创建的数学模型使得有可能针对4个给定的类别(如上表中的0、1、2、3)生成10000个训练数据、1000个验证数据和1000个测试数据的平衡集。这样一个数据集的生成时间为10分钟。
想法的有效性
此外,这项工作还进行了卷积神经网络(CNN)模型的综合、训练以及对创建的数据集的综合(模型)数据的验证。实践表明,其训练数据的识别准确率为98%,测试数据的识别准确率为97%。
为了检查识别实际缺陷帧(由检测仪测量)的准确性,将来自控制死区的标记帧(通过Avikon-11检测仪检查数据集,这里有3000个样本)提供给所创建的神经网络的输入。对Avikon-11型检测仪实测数据的识别准确率为92%。
获得的精度是一个很好的结果。但是采用一些方法可以提高精度。失配矩阵(如图12所示)有助于了解神经网络在哪些帧上出错。
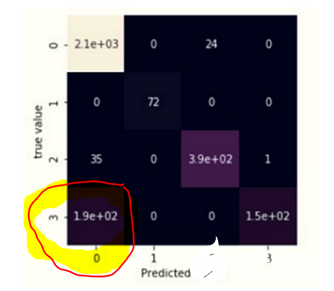
图12:失配矩阵
在分析矩阵之后,很明显,神经网络会在3类(缺陷组-55)的帧中做出主要预测误差,而在0类(无缺陷状态)的帧中进行预测,神经网络将其识别为一个螺栓孔的位置。由于其相似性,导致第55组出现缺陷(如图13所示)。在这种情况下,有必要添加其他通道的信息符号,从而提高预测的准确性(在这种情况下通常是轨颈控制通道,这是由于存在螺栓孔)。这对图13进行了解释。
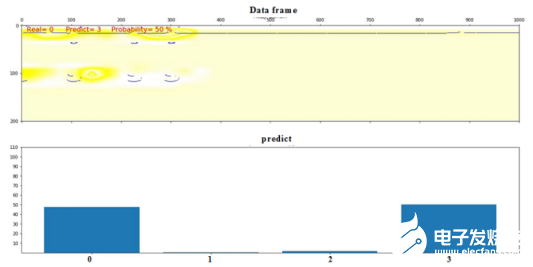
图13:将帧错误分配给3类的示例
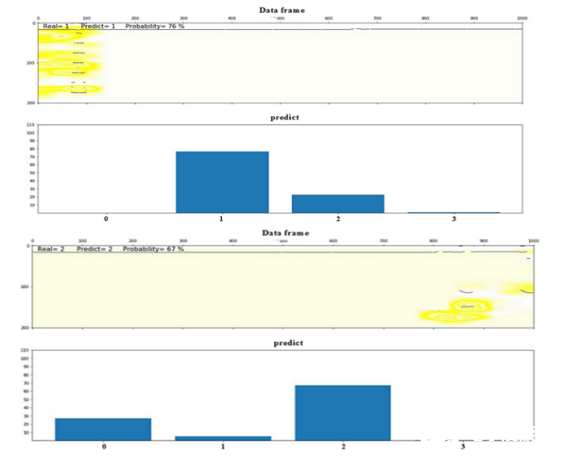
目前,在识别系统中已添加了在神经网络已“决定”分类的帧上突出显示信息符号的算法(图14中的黄色背景)。
结论和进一步的发展策略
获得的92%的准确度表明了将模型数据用于训练网络的可能性,并将其应用于自动识别铁轨超声检测的实际缺陷图,从而解决了训练数据量少的问题,这将显著加快采用自动缺陷识别系统生成软件的进程。这一想法的进一步发展包括以下步骤:
(1)轨头控制通道、轨颈控制通道、轨底控制通道的模型综合。
(2)调整模型以消除噪音。
(3)将生成的缺陷“植入”(放置和引入)到实际缺陷图(具有引入缺陷的真实噪声图)。
(4)改进模型以提高神经网络的精度。
工作原型所提出的发展阶段将允许增加:
缺陷识别的准确性
已识别的缺陷类别的数量
创建一个完整的系统,以通过所选检测仪的所有测量通道来自动检测缺陷。
所获得的模型可以适合所需的检测仪。
编辑:lyn
-
神经网络
+关注
关注
42文章
4842浏览量
108178 -
超声波检测
+关注
关注
0文章
28浏览量
8857 -
机器学习
+关注
关注
67文章
8565浏览量
137226
发布评论请先 登录
功率放大器在空气耦合超声波斜入射的钢板缺陷检测中的应用

AOI光学检测设备原理:自动光学检测如何识别外观缺陷?
高压功率放大器在铝板内部缺陷脉冲涡流检测中的应用
如何深度学习机器视觉的应用场景

机器视觉缺陷检测中传感器集成的五大关键

机器视觉检测PIN针
射频功率放大器在单缺陷导波高精度检测中的关键作用
海伯森产品在屏幕缺陷检测中的应用
汽车后视镜加热片细微缺陷检测难题,PMS光度立体轻松拿捏

FLIR Si1-LD声学成像仪在铁路行业中的应用优势
大模型在半导体行业的应用可行性分析
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统




评论