 关于超低延迟实时流媒体传输技术的图文详解
关于超低延迟实时流媒体传输技术的图文详解
现在云游戏,云应用越来越火,所以超低延迟实时流媒体传输技术的需求应用场景会越来越多。腾讯专家工程师刘泓昊老师在LiveVideoStackCon 2020北京站的演讲中,对超低延迟传输技术从传输协议的设计选择到流控算法和采集都分享了自己不同于行业的理解。
类似云游戏这一类场景是实时视频传输领域中最难的场景,今天主要分享一下我们这两年云游戏场景上做的一些工作和思考,也会提到一些我们不同于行业的观点。
这两年云VR,云游戏,云应用重新火起来。很多大公司都在加入这个行业,像云游戏,从全球来看所有巨头都在做,包括阿里,腾讯,Amazon,Facebook,Google都在做这个领域。其实这些应用早些年并不是没有,没有做起来的一个重要原因是网络能力跟不上。我非常感同身受,几年前要求几十兆码率延时只有几十毫秒是不可能的,但是随着整个中国互联网的发展,家庭都做到光纤入户百兆起步, WIFI5的大规模普及,已经有越来越多的用户网络能满足应用的要求,未来随着WIFI6的普及和5G的兴起,我相信新的时代快要来了。
从依赖buffer抗抖动到不抖动
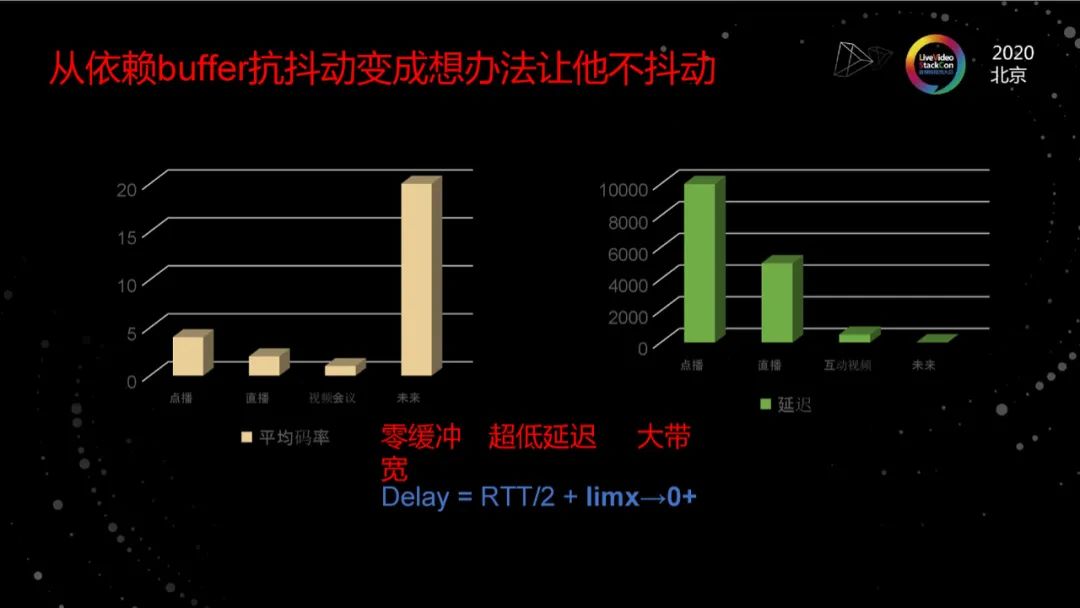
简单看一下类似场景对网络的要求,这种场景本质上是内容生产即消费,它们的间隔在十毫秒级。我们要让用户得到非常好的视听感受,需要足够大的速率来传输视频画面。以云游戏为例,云游戏想让用户的体验接近于本地游戏,只是就1080P而言,需要码率在20Mb以上,这还不算未来的4K、8K视频。云VR可能需要70兆。
简单用三个词描述对应用的要求,就是零缓冲,超低延迟,大带宽。随着边缘计算的大规模普及,网络的物理延迟倒还不是太大的挑战,关键是我们怎么让软件的传输延迟无限接近于物理延迟,怎么充分利用带宽、怎么从以前利用buffer来对抗网络抖动,变成让网络不抖动。 我们一直以来的观点是,网络传输协议设计和优化的本质是端到端的QoS,即结合应用的QoS来设计最合适的协议和算法,因此面向新的应用场景和技术挑战,我们需要围绕着零缓冲,超低延迟,大带宽来设计我们的系统、协议和算法。
我们所有的东西都是基于零缓冲,超低延迟,大带宽来设计的。
协议设计的关键点

今天的内容我主要讲三点:
可靠性, 为什么我要强调可靠性,主要有两点原因:
1. 大码率场景下,单位吞吐大幅增加,单帧大小大幅增加,导致丢包数大幅增加,尤其是重传包丢包数大幅增加对我们的丢包处理提出了更高的要求;
2. 低延迟的要求导致我们对于重传的实时性提出了更好的要求;
流控算法,新的应用场景对单位吞吐和低延迟的要求,对流控算法提出了极高的收敛性和利用率要求,需要我们有颠覆性的算法设计;
最后我会说一下我们对于UDP和TCP的选择上,有不同于行业的观点和效果很不错的实践。
关于可靠传输机制

关于可靠传输机制的第一个观点,虽然视频流并不是完全不能丢包,但是应用层丢包是应该尽量避免的。所有的数据丢弃应该都是主动丢弃而不是能力不够导致的,举个例子,传一个O帧数据中有个包因为能力不够丢失了,就得生产一个I帧,平均一个I帧的大小是p帧的6-12倍,因为能力不够丢失一个数据包导致要生产一个数倍大的数据,这对传输延迟的体验是很糟糕的。所以要尽可能保证所有数据丢失,是我主动丢失的,而不是能力不够导致的。
类FEC和重传的关系

接下来我们来说一下FEC和重传的关系, FEC和重传的优缺点大家是有共识的,通过FEC可以降低丢包带来的影响,减小帧延迟,但是FEC会导致带宽的浪费;重传不会带来带宽的浪费, 但是重传就意味着延迟的增加。最合适的用法一定是把它们结合起来一起使用,延迟小、丢包率低的时候带宽优先,延迟大、持续丢包的时候FEC优先。 这个地方我想强调两点:第一,丢包是可以预测的,通过合理的预测是可以大幅降低FEC的使用的;第二,在使用FEC的情况下,尤其是网络不好的时候,是有机会去做先验冗余的。
NACK和SACK的选择
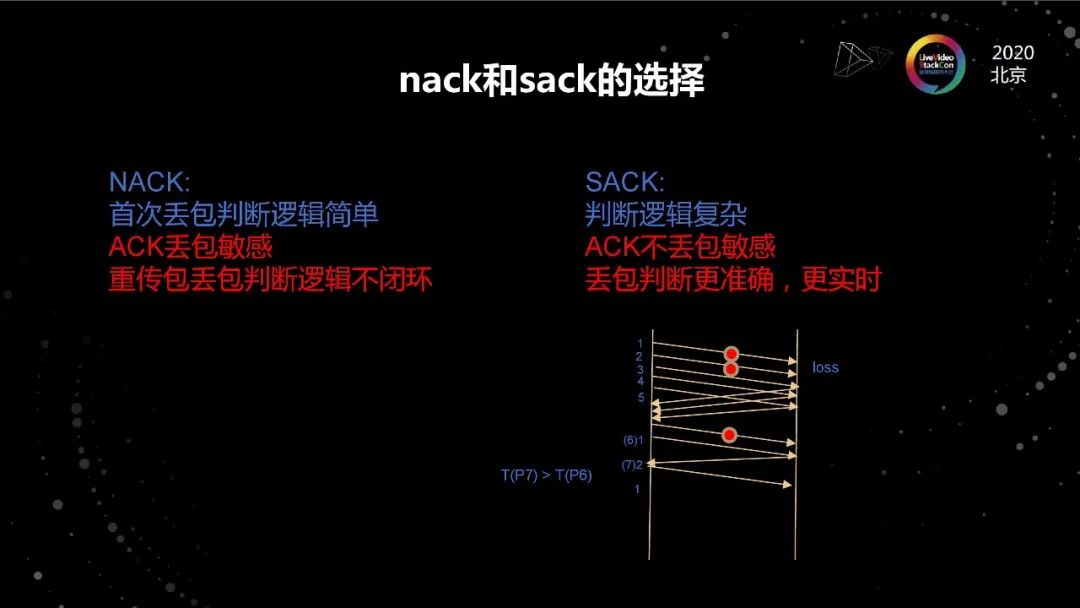
既然重传一定要有,就看怎么发现丢包,行业有两种通用做法。第一种做法是NACK 。NACK的优点是丢包判断逻辑非常简单,发现客户端有hole就知道它丢包了,但是如果NACK包丢了,客户端是不知道的,或者说收到NACK包,重传包丢了,客户端也是不知道的,没有一个逻辑能闭环保证我能知道这个包一定丢了。一旦出现上述情况,就只能靠超时,在超低延迟的场景下,超时是一个非常不好的手段。因为超时有两种可能性,第一种超时值太大了,超时太大意味着这一帧的延迟和抖动非常大,从用户感受来说就是卡顿或者手感不好。第二种如果说超时设置很小,会导致生产重复的包,让拥塞更加严重。这个点是很难平衡的,核心原因是NACK没有一个闭环逻辑能保证所有的丢包判断逻辑是准确的。
SACK其实是现在做可靠传输协议纯ALOHA协议的机制里面常用的方法。包括TCP,QUIC也是类似。SACK的缺点是判断逻辑非常复杂,SACK的优点是ACK丢包不敏感。第一因为SACK是有一串闭合逻辑的,丢掉任何一个包,后续的包能补上,所有丢一个SACK不会影响整体的判断逻辑。第二因为SACK是个有状态的,这个状态能做到丢包判断更准确,更实时,用一个rtt一定能判断出来。
展开一下,老的Linux内核里实现里面SACK的逻辑很复杂,是因为它是基于序号序的,整个判断逻辑是以序号来判断是否丢包,这会导致整个队列逻辑判断非常痛苦。我们在13年做了一个新的方法,我们称为基于时间序的丢包。如图所示,我们根据数据包的发送时间来判断做丢包的判断,基于这样一个逻辑,整体判断逻辑会比传统内核简单很多而且更精准,在这个逻辑下只要保证最后一个包不丢,那就能快速判断出前面的包有没有丢。如果最后一个包丢了,另一个办法叫prob包。类似的工作Google在16、17年已经patch到内核里了,QUIC上也有类似的实现方法。
所以,在大带宽、低延迟的场景下,丢包判断的逻辑会变得更重要,这个时候SACK是远比NACK更好的方法,虽然它的实现复杂度要大很多。
关于流控

关于流控我们有三个观点,第一个观点是面向超低延迟和大吞吐场景我们需要新的流控目标模型,它跟传统的TCP的拥塞控制是不一样的。第二个观点是我们对延迟要求非常高,就意味着采集周期会变得很关键,百毫秒级的采集粒度已经完全满足不了新应用的要求了。第三个观点,流控算法的核心是吞吐,不是丢包,不是delay,也不是buffer,基于吞吐模型可以让我们有更好的收敛性。
流控的新目标
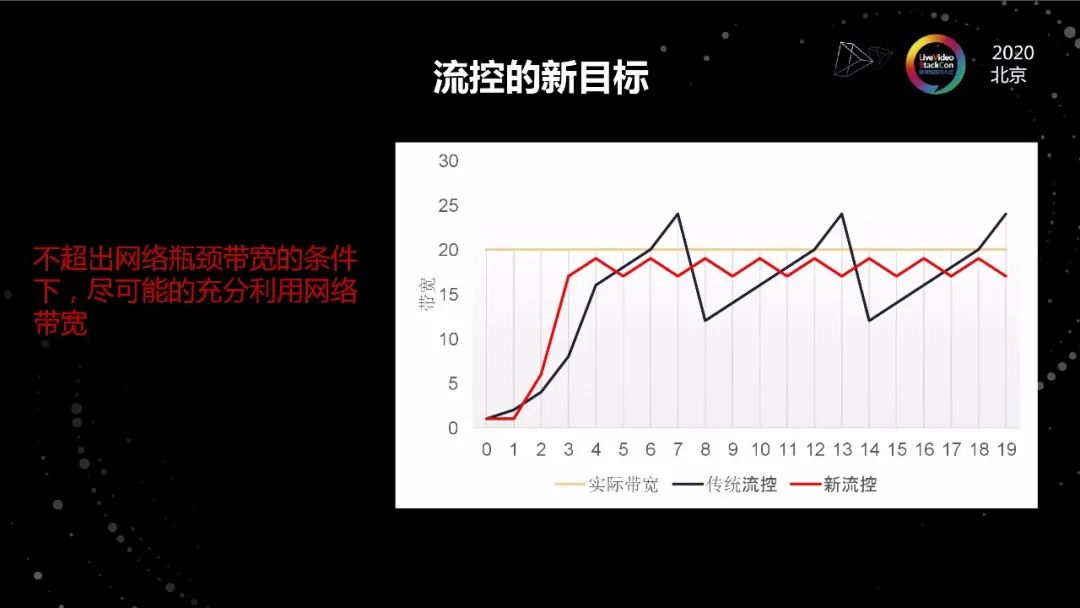
实时视频流是App Limit,它在宏观上的上限是受到码率限制的,在新的场景下,码率限制被彻底打开了,从实用的角度来说,流控的作用和价值就变得尤其巨大了。
实际上TCP的拥塞控制算法和流控,尤其是没有buffer的流控还真不是一回事。拥塞控制算法的设计目标是效率、公平、收敛。结合低延迟、零buffer的特性,流控的目标是在不超出网络瓶颈带宽的条件下,尽可能的充分利用网络带宽。
所以如图所示的红线才是我们期望的结果,即码率不断在接近目标带宽的下面徘徊, 如果说传统的TCP拥塞控制算法目标是带宽利用率100%的话,我们只要做到90%就可以了。
还有一条,TCP拥塞控制算法其实不太纠结微观的情况,它关心的是宏观的收敛性能,但是在流控上微观的收敛情况,尤其是收敛速度是很重要的。因为对于我们这种没有缓冲的场景来说,在降速的时候收敛慢就是卡顿。对于视频流来说,码率波动大,QoE肯定好不了。
关于采集

第一点,如果希望延迟是几十毫秒,那网络波动的时候,采集周期是一百毫秒。等到一百毫秒才知道网络波动再去做处理,那意味着网络一波动就卡顿,所以采集的精度一定要足够细。但是采集精度足够细带来的另一个问题是怎么把数据做准,这是一个非常矛盾的点,又需要很小的采集间隔,又需要把数据做准,甚至能反应网络情况的,这是非常不容易的事。这也是为什么以前系统会把采集间隔放的稍微大一点的原因,这样采集数据是能真实体现网络情况的。解决这个问题的方式是帧粒度,因为帧是有逻辑,有状态的,这些逻辑和状态是可以梳理清楚并且建模的。帧粒度是目前为止我们能找到的最好的采集间隔和采集方法。
第二点,因为延迟性要求,所以要快速发现。这里面就两种采集方法一种是在发端采集,一种在收端采集,收端采集有一定时间间隔才能往上报,这样会导致判断的时间偏晚,这样和我们需要的尽可能实时判断和低延迟又是矛盾的。所以建议数据采集是发端为主,收端为辅。因为发端的采集和计算过程可以在任何一个中间态进行。发端采集数据不准的部分,用收端来补充。
第三点,没有数据也是数据。没有数据背后反映很多东西,是很有价值的,这一点在我们做的过程中,效果是非常好的。
流控算法
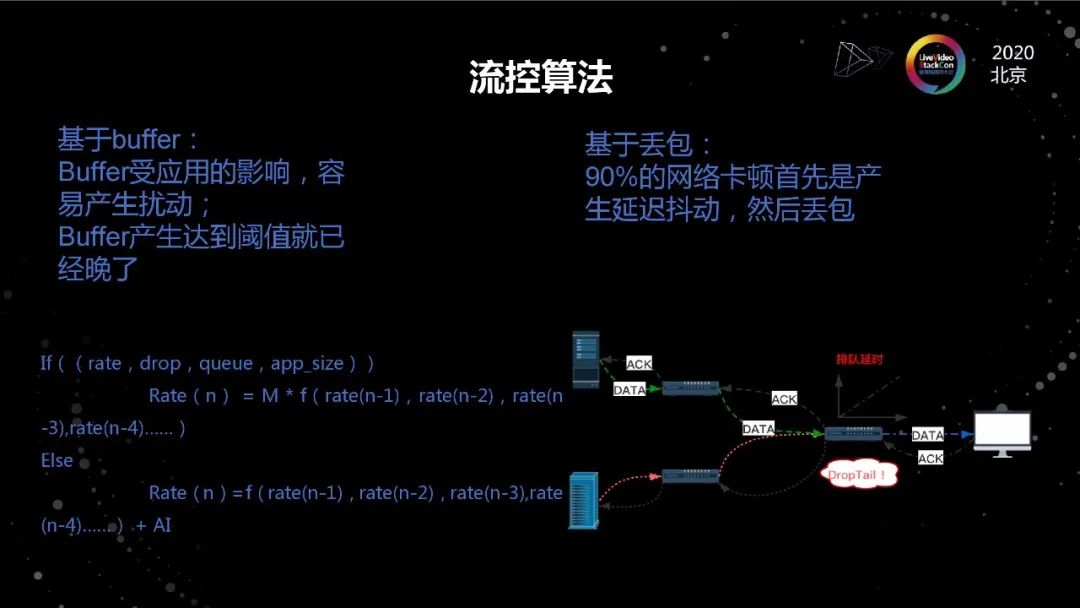
流控的本质是不断寻找可用带宽的过程。它在实际实现过程中无非是带宽没有用完的时候,通过不断上探的方法,找到合适的速率。当网络拥塞或者抖动的时候,快速降低速率以适配当前的网络情况。这里面就几个问题,第一个问题是当网络拥塞的时候依靠什么来发现。通常的方法就两种,第一种就是丢包,在中国有90%的场景是先rtt先升高再丢包,但是对于低延迟的场景来说,rtt的大幅升高是不可接受的。另外,早年关于TCP的不公平性,定义了两个场景,一个是rtt的不公平性,即rtt越大,速率越低;一个是多瓶颈链路的不公平性,它指的是在非瓶颈链路产生的丢包会导致连接的速率偏低,这就是因为我们通常把丢包做为拥塞的判断依据导致的。因此,丢包一定不是好的判断依据。
基于buffer来判断网络拥塞,有两个问题,第一,实际虽然我们是App Limit型的,但每帧大小是不一致的,buffer的堆积并不完全是因为网络的带宽不匹配导致的;第二, buffer的堆积是以牺牲体验为代价的,并不是一个好的信号。
从目前我们的探索来看, 速率模型是一个更好的模型,理由有三:
1. 流控的本质是让发送的带宽和网络瓶颈链路的接收能力是一致的,接收能力是速率,发送带宽也是速率,所以基于速率来作为模型更实时的判断卡顿依据是更好的方法。
2. 接收速率来决定降速到多少,是可以实现降速的快速收敛的。
3. 带宽的探测过程本质还是预测速率,他背后还是速率模型。
TCP的拥塞控制早年最经典的算法是AIMD,即加性增,乘性减。我个人非常认可AIMD这个思路的,因为AIMD是我目前看到收敛到公平的最好的机制。虽然有很多启发式的算法,例如MIMD号称可以收敛的效率很快,但是收敛到公平的能力是很差的。然而今天互联网音视频最大的问题不是最快的那个跑的有多快,而是最慢的那个跑的太慢了,这是有人说应用体验不好的核心原因。这本质上就是收敛到公平的能力,所以收敛到公平都是其中非常重要的因素。
基于此,我们认为AIMD并不是一个过时的方法,问题是我们应用怎么使用。最后说一下基于人工智能的流控,我的观点是,流控的核心是模型,人工智能是模型之上的补充,不存在完全的人工智能,人工智能是加分项,不是地基,它或许能帮我们做到95分,前提是我们自己能做到80分。
流控流程
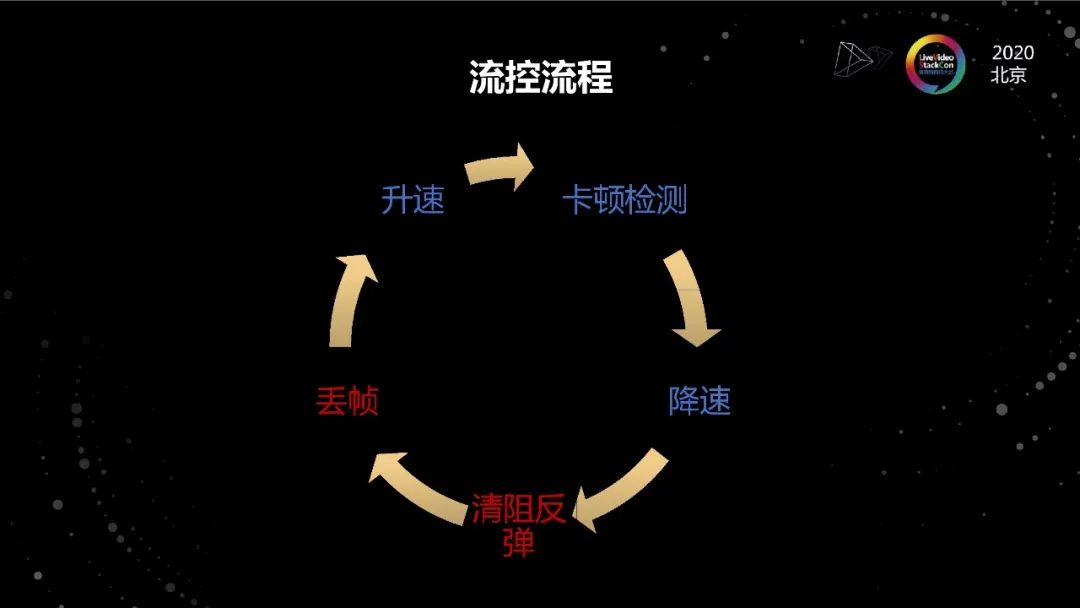
因为做超低延迟的应用,不同于其他场景,为了保证实时性,清阻过程(包括丢帧)是很重要的阶段,不能被忽略。
关于网络传输协议

从视频流来讲,很显然UDP是比TCP更合适的。第一,UDP比TCP更灵活,丢数据更好丢,用TCP的话在底层丢数据是非常不容易的;第二,UDP可以用FEC,但是TCP用不了;第三,如果我们是推流,那手机端内核我们是改不了的,内核改不了用传统TCP效果肯定是不好的;第四,是内核代码不好改,相比应用层代码,Linux内核的学习成本确实不低。但是,从我们的数据来看,在高码率情况下UDP的丢包率是要高于TCP,而且码率越高丢包率越高。
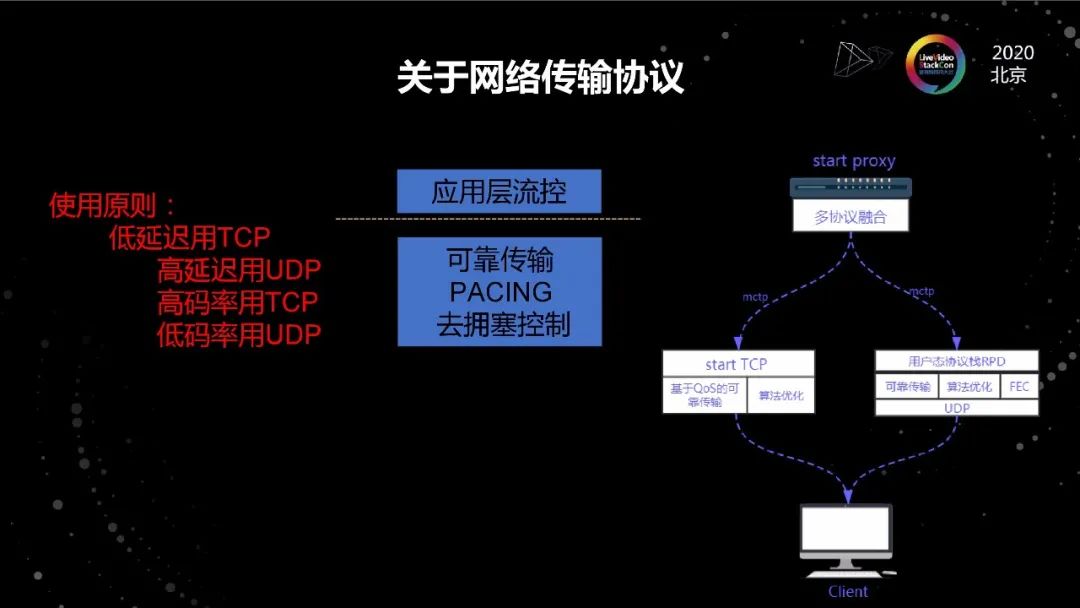
在实践过程中我们做了一套基于TCP的传输体系,在我们体系里面,TCP协议栈主要功能是可靠传输和围观尺度的PACING,但是不做拥塞控制。实际上,为什么TCP做视频传输做不好,很重要的一个原因是上面有应用层流控,下面又有拥塞控制,他们是互相冲突的。我们改造之后,整体的效果我们还是非常满意的。我们平均端到端的延迟,即从发送数据到被确认时间已经非常接近物理延迟了,到ACK回来不到二十毫秒,我们在有线网络上的卡顿情况并不比硬件产生的卡顿更多,我们空口的卡顿率比线上直播要低。
比较理想的方案是既把UDP用上又把TCP低丢包特性用上,所以我们最终的系统是我们会在一个会话里跑两个连接,一个TCP一个UDP,当我延迟小丢包率低码率高的时候我会用TCP,当我网络不好延迟高丢包率高码率上不去的时候用UDP。低延迟用TCP高延迟用UDP,高码率用TCP低码率用UDP 。
我们这里说的UDP指的是基于UDP实现的具备重传和FEC能力的应用层可靠传输协议,我们目前使用的是我们自研的可靠传输协议RPD 在可靠传输协议之上我们还需要实现一个协议实现多个连接跑在同一个会话上,让两个连接能做到无缝实时切换。

我们现在面临的最大的问题并不是匹配不了用户带宽,而是所使用链路根本不具备传输超低延迟的这个能力。我们发现很多用户的wifi上连两兆速率的稳定传输都做不到。这个问题在wifi 2.4GHZ频段上非常明显,在wifi 5GHZ频段上就好很多。我相信随着wifi6的出现,未来会更好 。但是无论如何空口传输的稳定性,它们都是比不过有线网络的。我们的观点是,我们要做两件事:第一我们要深耕产业链,我们要把整个产业链打通,让空口的能力适配低延迟的要求。第二是空口很大一部分的问题是概率,如果能把两个独立的信道叠加起来,如果有两个信道的话就等于把两个独立的概率事件叠加起来,2个9有机会变成4个9。所以未来在不可靠的无线链路上,用多链路实现高可靠是有很大机会的。用现在大部分手机都能支持wifi/4g双通道了,我们判断wifi/5G 、wifi/wifi、5G/5G双通道一定是未来保证超低延迟的基础手段。而且这种手段不止在超低延迟的场景下使用,当前主流的直播、点播应用上都有很大的应用价值。
我们相信,多通道技术一定是未来网络传输系统发展的趋势。

首先Sack是更好的重传发现机制;第二点是帧粒度的采集是合适的采集方法;第三点是速率模型做流控;第四是TCP和UDP混用在超低延迟场景效果很好,最后未来是多链路的。
编辑:lyn
-
传输技术
+关注
关注
2文章
57浏览量
13845 -
vr
+关注
关注
34文章
9638浏览量
150224 -
wifi6
+关注
关注
4文章
502浏览量
38222
原文标题:超低延迟实时流媒体传输技术
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
流媒体后视镜市场份额连续6年称霸全国,新产品即将上市

北京君正X2000新品案例:流媒体音乐接收器
远峰科技:流媒体后视镜市场份额连续6年称霸全国,新产品即将上市

传感器技术在构建实时监控系统中有什么作用
ElfBoard技术贴|如何在ELF 1开发板上搭建流媒体服务器

谷歌宣布对Android设备流媒体服务进行重大扩展
贸泽开售AMD / Xilinx Alveo MA35D媒体加速器 为流媒体、游戏、远程医疗和在线学习应用提供支持
亚马逊拟收购印度流媒体MX Player部分资产
【RTC程序设计:实时音视频权威指南】信令与媒体协商
Deltacast借助AMD器件推出实时低时延视频采集与流媒体卡
车载智能后视镜_流媒体云镜_行车记录仪主板方案定制

高清视频编码器与流媒体平台的完美结合





 工商网监
工商网监
评论