 目标物体识别算法:物体识别算法的一般路径
目标物体识别算法:物体识别算法的一般路径

导语:智能驾驶的决策执行依赖于对目标物体识别的精准判断,因而目标物体识别功能也是最早开始研发的部分。精度、响应度提升是现阶段技术关键。
物体识别分类对于速度和精度要求极高。一方面,物体的识别和分类是实时的,且结果的置信度要足够高。由于无人驾驶需要实时做出驾驶决策,而物体识别仅仅是其中一环,在做出判断前,需要给算法处理、决策效应到执行器留有足够时间,因此留给物体分类和识别器的时间很短,实时性要求非常高。
另一方面,汽车驾驶关系到乘客的生命安全,在此情况下,物体识别必须将误报、错判的概率和可能性降低到极低范围。一旦发生误判,系统执行错误的指令,则结果将是致命的。
目标物体识别难点
•目标物体差异化。
无人驾驶需要依赖算法来识别道路上的各种差异化目标。道路情况十分复杂,面对的物体多种多样。即使同一类物体,也存在外形、尺寸差异。同时,路面上的物体也可能以组合形式出现。以行人为例,行人有不同的静态和动态差异,静态包括行人的外形、服装、高矮胖瘦、体貌特征差异;动态差异指行人的运动状态,可能奔跑、行走或者静止。这就要求识别算法拥有极高的辨识度,能够区分路面上各个不同的物体,精准判断。
•环境和路况差异化。
实际道路行驶中,会碰到不同环境和路况,这就要求识别算法普适所有工况。例如:极端的天气情况(大雨、大雪、闪电、雾霾等)、不同的光照、不同的路况。
•在动态场景中进行识别。
在实际道路行驶中周围的场景都是运动的物体,从不同的视角看过去,不同的物体的坐标变化模式、姿态变化模式都会不同,识别难度进一步增加。
物体识别算法的一般路径
物体识别算法通常分为六个步骤:
前处理→前景分离→物体分类→结果改进→物体追踪→应用层面处理
前五个部分是算法的核心,第六部分则通常指后续的物体行为预测、路径规划、导航和防碰撞算法等。
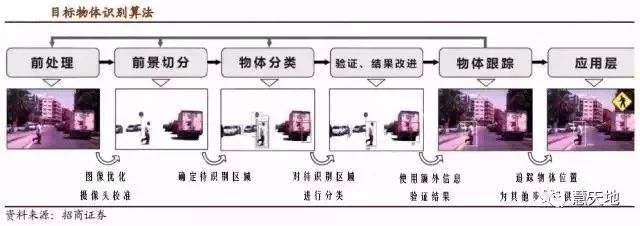
1
——前处理
此部分为最底层的机器视觉算法,通常包含摄像头曝光、增益控制、摄像头标定校准等步骤。由于路况复杂多变而实时性要求很高(例如当车辆快速驶入驶离隧道时,周围的光照变化剧烈,需要迅速做出调整),无人驾驶中对前处理算法的要求极高。
前处理算法需要保证输入到后续步骤的图像质量。图像质量会直接影响后续分类算法性能。尽管传统的机器视觉增强算法能够部分解决这一问题,但是使用高动态范围(HDR)的视觉传感器和配套算法将是未来的主要趋势。高动态范围传感器可以通过多次曝光运算增强图片对比度, “照亮” 场景。汽车上使用的 HDR 摄像头通常还会将近红外夜视波段也涵盖进去,实现夜视功能。
传感器自身的在线标定也在这一部分完成。由于传感器始终处于运动状态中,因此实时确认传感器自身的姿态尤为重要。单目摄像头往往通过跟踪不同图像帧之间的差别来确认自身姿态,而双目摄像头则使用额外的景深信息来实现这一功能。前者的可靠性较差,而后者则需要更多的计算资源。
2
——前景切分
前景切分的目的是尽可能过滤与待识别物体无关的背景信息(例如天空),并且将图像切分为适宜大小。一个好的前景切分算法可能将原先的 200k- 1000k 个待识别区域缩小到 20k-40k,大大减轻后续处理负担。主流算法有基于仿生原理的注意力算法等,但是这些算法往往需要依赖于预先收集的数据,这些数据规定了不同场景下的可能的背景区间信息。另外,额外的传感器输入(包括定位系统、双目摄像头或雷达提供的景深信息等)可以进一步加快前景切分。
一旦有了这些额外的信息,前景切分算法对图像区域是否处于前景(待识别)的判断确信度会大幅提升,大量背景区间将会被去除,大幅减少输入到物体识别器中的待识别区域,提高识别的速度和准确性。

3
——物体识别
将上一步骤生成的大量待识别区间归类为数百种已知的可能在道路上出现的物体,并且尽量减少误判。基本上所有的物体识别算法都是以二维图像作为输入的。这种输入分为两种,一种是将待识别区域图像中的边缘提取出来,将边缘信息输入分类器(可以辅以激光雷达以获得更高精度);另一种则是直接将图像的外观输入到分类器(通过摄像头实现)。前者在性能上基本已经到了极限,而后者则是目前研发的主要方向。
具体到算法,主流的特征提取方法包括梯度方向直方图法(HOG)和形状上下文描述符法(SCT),提取特征后进入分类程序。主流的 AI 分类学习算法包括支持向量机(SVM)、迭代分类算法(AdaBoost)和神经网络(NN)。
4
——验证与结果改进
这一步骤使用与分类方法不同的判据来验证分类的结果可靠性,并提取被归类为特定物体的待识别区间中更加详细的信息(例如交通标志)。由于雷达、激光雷达等非视觉传感器往往能够满足“冗余传感信息来源”这一要求,因此在实际算法中,这一部分也将应用大量的传感器融合。

5
——物体跟踪
这一步骤的目的有二。除了为应用层提供物体轨迹外,还能为前景切分、物体分类提供输入(告诉前景切分之前这个地方出现过什么)。目前最为常用的算法是卡尔曼滤波算法(用来跟踪、预测物体轨迹,根据过去空间位置预测未来位置)。在物体跟踪环节同样涉及较多的传感器融合算法,通过视觉数据预测轨迹,同时同雷达的物体跟踪数据进行耦合。
精度和响应速度之间的最优选择
精度是视觉算法的核心,近年来视觉识别算法精度不断提高。视觉识别算法的精度由误检率和漏检率共同决定。物体识别本身的复杂性决定了这一功能必须以视觉为核心。
纵观过去十多年,视觉物体识别的精度有了长足的发展。以美国加州理工学院进行的一项行人识别的算法调查为例,当误判率为每张图 0.1 个行人时,纯视觉算法的漏检率已由 2004 年最早的 95%降低到了最近几年的 50%附近。
因此我们有理由相信在无人驾驶真正商用时,即使是纯视觉算法也能达到很高的物体识别精确度,而若加以传感器融合(在相同误判率下约能降低 10%的漏检率)和强大的车联网实时数据,无人驾驶阶段的精度要求将得以满足。
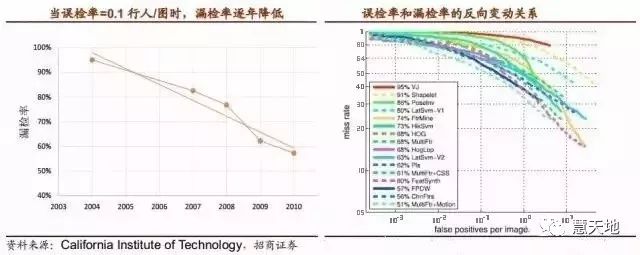
视觉识别算法精度提升途径
•视觉算法本身的优化。在前处理和前景分离阶段提取明确目标值,分类和学习系统的算法不断优化。这需要技术研发的不断投入,产生极高的进入壁垒,目前国内从事视觉算法研究的公司只有少数几家,因而也构成了标的稀缺性。
•通过传感融合算法冗余信息判断,提高精度。视觉识别以摄像头数据为主,同时辅以雷达、激光雷达的边界、距离信息。数据显示,在相同误判率下雷达的决策辅助能降低约 10%的漏检率。
•利用车联网、地图数据的辅助决策。无人驾驶的商用与车联网应用密不可分,通过 V2X 实时数据传输,协助车辆判断物体信息,同时通过 GPS 高精度定位和地图数据相结合,辅助物体的分类识别。
另外一个值得关注的问题是各种算法的处理速度。为了保证在高速行驶状态下的可靠性,物体识别的图像输入速率往往达到了 60~90fps (比一般摄像头帧数高 3-4 倍)。即使前景分离步骤每张图仅产生 20,000 个待识别区域,流入硬件的待识别区间也达到了每秒1200,000 个。目前算法在一台普通计算机下运行速度如下图所示。
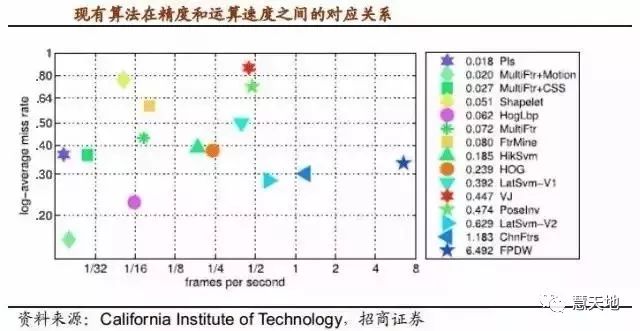
面对如此大的计算量,通常情况会有如下几种解决方法:
第一, 算法上做出妥协。不使用过于复杂的算法,这意味着精度上要做出妥协。
第二, 优化算法架构,在算法上取得突破,分类器的性能往往是主流算法瓶颈,通过加强在前处理和前景分离过程中的数据筛选能力减少传输给分类环节的数据量。
第三, 更加强大的运算芯片。
第四, 定制专门的计算单元来处理物体识别计算,这需要较高的研发投入。CPU 用来处理日常的运算、排序、组合,GPU用来处理图像、着色、点距等信息,DSP 应用于处理时间序列信号。三者结合的定制芯片更为实用。
责任编辑:lq
-
芯片
+关注
关注
463文章
54593浏览量
470594 -
识别算法
+关注
关注
0文章
45浏览量
10854 -
无人驾驶
+关注
关注
100文章
4315浏览量
127248
原文标题:目标物体识别算法:精度和响应度关乎生命
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
占据感知网络如何识别动态物体?

瑞芯微(EASY EAI)RV1126B 手势识别算法识别

自动驾驶汽车如何识别悬空物体?

瑞芯微(EASY EAI)RV1126B OCR文字识别

自动驾驶汽车如何准确识别小物体?
【上海晶珩睿莓1开发板试用体验】物体识别的板端推理
如何挑选人脸识别终端?人脸识别一体机品牌排行榜

瑞芯微RK3576语音识别算法


在树莓派5上使用YOLO进行物体和动物识别-入门指南

基于FPGA的SSD目标检测算法设计
【正点原子STM32MP257开发板试用】基于 YOLO 模型的物体识别
【正点原子STM32MP257开发板试用】基于 MobileNet 的物体识别
AI视觉识别收银称:水果生鲜店的“智能店员”




评论