 英伟达最新推出的自动驾驶芯片Atlan详解
英伟达最新推出的自动驾驶芯片Atlan详解
英伟达在2019年12月推出Orin后沉寂一年半推出新一代自动驾驶SoC,即Atlan,从命名来看,Nvidia 还在使用《海王》(Aquaman)系列中的名字。在2019年开始,Nvidia宣布的Orin SoC,就是以亚特兰蒂斯的第一统治者命名的。而最近 Nvidia 宣布了以 Orin 之父命名的 Atlan SoC。相对Orin,Atlan可谓颠覆性的,与Orin远非一个系列的产品,与其说它是一个车载芯片,不如说它是一个大型数据中心服务器芯片,不太考虑成本,不太考虑功耗。
英伟达从未公开Orin芯片的内部布局图,但Atlan一开始就公布了,或许是对Atlan信心更足。
英伟达在2019年11月发布的Orin芯片官方图片。不过在网上可以找到Orin的大致布局图。
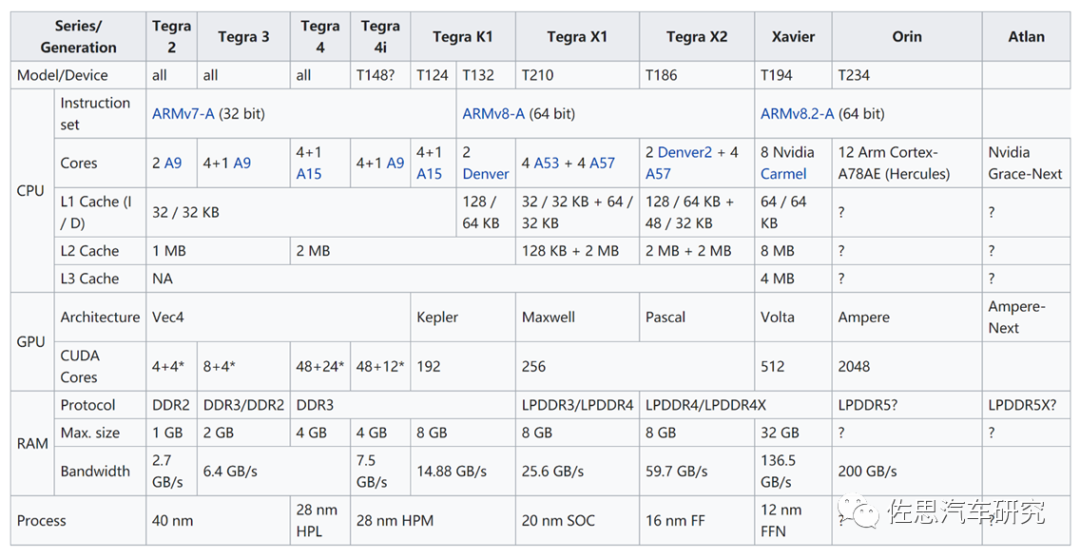
Atlan不再沿用使用了近10年ARMv8的指令集,改为ARM Neoverse V1指令集。开发人员可能需要花大量精力来熟悉这种从未出现过的指令集。最大的改动是CPU使用了ARM针对服务器领域的Zeus架构,增加了Bluefield即DPU部分,增加了针对功能安全的安全岛设计。 先来看CPU部分。
ARM在2019年3月针对服务器市场推出Neoverse平台,按照计划最初是Ares,即希腊神话里的战神;2020年是Zeus,即希腊神话里二代天神中的最高神的宙斯;2021年是Poseidon,即希腊神话里的海神波塞冬。或许不会有Hades,冥王哈迪斯。至少这个系列代号可以用11代。
Neoverse平台再分3个系列,分别是V、N、E三个系列,分别对应高性能、高效率、低功耗三大应用场景。V系列中第一个产品,顺便说一下,N2平台代号是Perseus,即希腊神话里的宙斯之子,砍下美杜莎脑袋的希腊英雄珀尔修斯。英伟达破天荒推出的CPU即是以宙斯为平台的CPU。
V1可以看作ARM刚刚发布的ARM v9指令集的SVE强化版,ARM v9指令集中最大变化就是增加了SVE,SVE(Scalable Vector Extension)是ARM AArch64架构下的下一代SIMD指令集,旨在加速高性能计算。 ARM v7的高级SIMD (即ARMNEON 或“MPE” 多媒体处理引擎) 指令集自2005年发布,已经面世十几年了。ARM v7 NEON的主要特性如下:
支持8/16/32位整数操作,支持非IEEE兼容单精度浮点操作,支持指令条件执行
32个64位矢量寄存器,也可视为16个128位矢量寄存器
旨在CPU端加速多媒体处理任务
在升级到ARMv8架构时,AArch64 NEON指令集做出了许多改进,比如:
支持IEEE兼容单精度和双精度浮点操作和64位整数矢量操作
2个128位矢量寄存器
这些改进使NEON指令集更适用于通用计算,而不仅仅是多媒体计算
但是到了现在,ARMv8的新市场需要更彻底的SIMD指令改进。需要能够并行处理非常规数据和复杂数据结构,也需要更长的矢量,SVE因此而生,SVE旨在加速高性能计算。
128位的整数倍。 最高可支持2048位
不同的实现可以适应不同的应用场景,不用更改指令集
每通道预测
支持复杂嵌套循环和if/then/else条件跳转, 没有循环尾数。
聚集加载和分散存储支持复杂数据结构,如步长数据存取、数组索引,链表等。
横向操作
支持基本的reduction操作,降低循环依赖性
SVE2于2019年4月和V1一起发布,SVE和SVE2的优势还在于其可变的向量大小,范围从128b到2048b,从而允许向量的可变粒度为128b,无论实际运行的硬件是什么。纯粹从向量处理和编程的角度来看,这意味着软件开发人员将只需要编译一次其代码,并且如果将来某个CPU带有本机512b SIMD执行管道,该代码将能够已经充分利用了单元的整个宽度。
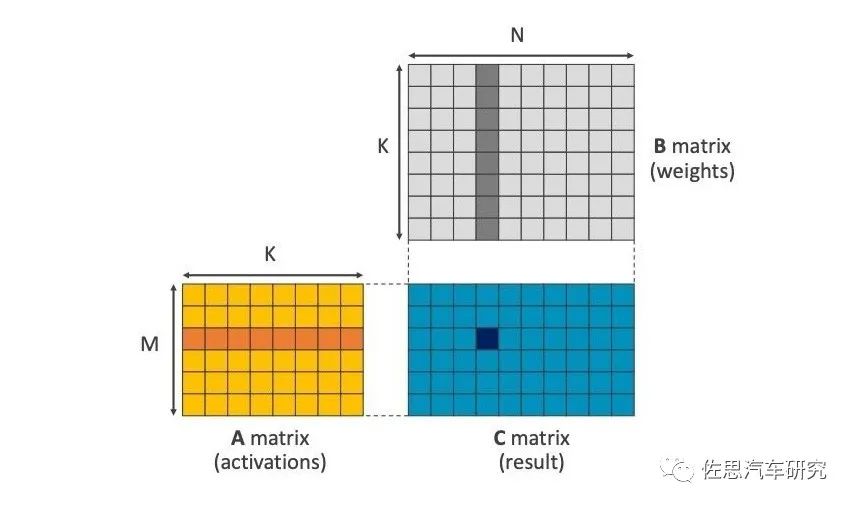
SVE2是针对机器学习设计的,通用矩阵乘法GEMM指令是其最突出特色。我们都知道AI加速器就是乘和累加MAC的堆砌,其特色就是一次可以执行乘和加两个指令。实际是一种矩阵乘法累加器,在ARM v8.6中也加入了GEMM指令,乘法累加器中,乘法要遍历每一个矩阵中的数值(通常是像素),这是最费时间的地方,加法器则要快的多,ARM的CPU不能像AI那样堆砌MAC,但是可以加速矩阵乘法,让后端的多核处理器部分工作量大大减轻。这近似于一个超高速DSP,频率不高,但带宽很高。
V1的突出特色还有CCIX和CXL,也就是大名鼎鼎的小芯片chiplet,chiplet的概念其实很简单,就是die级别的重用。设计一个系统级芯片,以前的方法是从不同的IP供应商购买一些IP,软核(代码)或硬核(版图),结合自研的模块,集成为一个SoC,然后在某个芯片工艺节点上完成芯片设计和生产的完整流程。 未来,对于某些IP,你可能不需要自己做设计和生产了,而只需要买别人实现好的die片,然后在一个封装里集成起来,很像SiP( System in Package),但两者有很大不同,chiplet是晶圆级的,晶圆制造的中段mid-end封装,只有晶圆厂Foundry才能做,封装之间是超高速的bump连线,SiP是芯片级的封装,是专业封装厂的业务范畴,是锡球级别的。 小芯片的另一个名字叫MCM,Multi-Chip-Module。 2017年英伟达、德州大学、亚利桑那州立大学、巴塞罗那超算中心、加泰罗尼亚理工大学联合出品一篇研究论文:MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability,对此有详细的研究,在2017年加拿大多伦多ISCA上发表。
简单地说就是用4个小芯片合成一个大芯片,英伟达称为MCM技术。
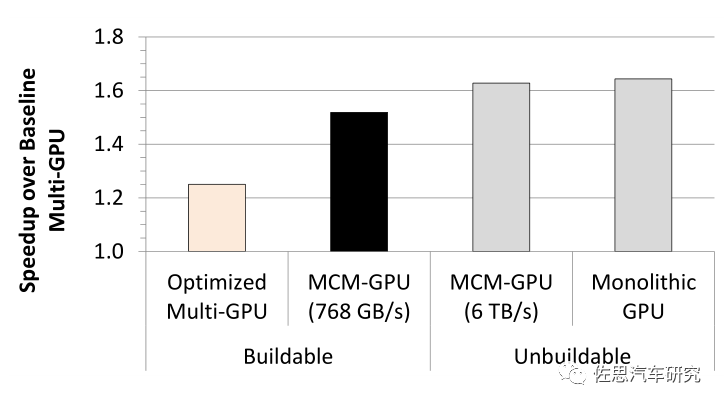
上图为英伟达采用MCM-GPU和多GPU性能对比。英伟达在2019年VLSI大会上提出RC-18概念,采用36个小芯片。
不仅GPU或者说AI芯片可以这样做,CPU也可以,这就是AMD在服务器领域崛起的关键,最典型的是AMD的32核(应该是32小芯片)EPYC,这种方式最大优点是成本低,如果将32核封装到一块芯片中成本是1,那它们的MCM方式只有0.59,换言之,节省了41%的成本。
把小芯片合成一个大芯片,貌似就是一个“胶水”大法,但实际门槛是很高的,能支持的只有台积电CoWos和英特尔的EMIB工艺,英伟达一向不喜欢台积电,更喜欢三星。和高通一样,英伟达知道不能过分依赖台积电,否则容易出现供应链问题,也就是后来英伟达基本放弃MCM路线。
回到Atlan,Atlan可能用了ARM V1提供的CXL小芯片,即内存扩展,减少内存于处理器间的物理距离是解决AI处理器内存瓶颈的最有效方式。CCIX比较复杂,可能下一代会用。
再来看Bluefield即DPU部分,2020年4月英伟达花70亿美元收购了以色列芯片公司Mellanox Technologies, Ltd.(迈络思科技有限公司),通过融合Mellanox的技术,新的NVIDIA将拥有从人工智能计算到网络的端到端技术,以及从处理器到软件的全堆栈产品,拥有足够的规模去推进下一代的数据中心技术。
Mellanox的主要产品就是名为Bluefield的芯片,英伟达将其改名为DPU。其实际上是一个高级的网卡。DPU专门执行原本需要CPU处理的网络、存储和安全等任务。这就意味着如果在数据中心中采用了DPU,那么CPU的不少运算能力可以被释放出来,按照英伟达的说法,一个DPU顶125个CPU的网络处理能力。
英伟达计划在2022年推出3代Bluefield。复杂一点的说法是DPU是一个可编程的电子部件,其处理数据流,数据可作为信息的复用包与组件传输。DPU具有中央处理单元(CPU)的通用性和可编程性,但专用于处理网络数据包、存储请求或分析请求上高效运行。DPU通过更大程度的并行性(可同时处理更多的数据),因而对比起CPU更胜一筹。
同时,DPU的MIMD架构相比图形处理单元(GPU)的SIMD架构更为优秀,其每个请求都需要做出不同的决定并遵循不同的路径通过芯片,从而使其区别于GPU 。也就是英伟达说的软件定义网络,Mellanox NVMe SNAP (软件定义的网络加速处理)技术可以为远程存储提供2.5M + IOPS读/写访问,这是4KB块大小时100Gb / s的线速性能。相比之下,入门级NVMe SSD可以提供带有4 KB块的300K IOPS。此外,BlueField-2 DPU毫不费力地以100 Gb / s的速度添加了IPSec加密和解密功能。
上图为二代Bluefield,内含8个ARMA72,Atlan里的要处理数据带宽远小于传统服务器,两个A72足够。Atlan里的DPU主要针对车载骨干以太网和外接的PCIe网络,内置网络控制器和PCIe交换,以太网可轻易支持到100G,PCIe则支持到第四代,也可以做数据采集车的网络接口芯片,与超高速固态硬盘连接。不过物理层芯片还是绕不开Marvell、德州仪器和博通。
最后是功能安全隔离岛,应该就是ARM发布的Cortex-R52。英伟达所说的功能安全岛与ARM所说的安全岛的宣传词都基本一致。R系列是ARM专门为实时性要求高的场合开发的内核,R52是R系列旗舰产品,之前英伟达芯片从未采用过R内核。
R52是ARM在2016年发布的专为自动驾驶安全市场供应的内核,Cortex-R52最高支持4核心锁步技术,相比Cortex-R5,有35%的性能提升,上下文切换(乱序)提高14倍,入口抢占提高2倍,支持硬件虚拟化技术。 按照ARM的说法,简单的中控系统可直接用Cortex-R52,但是像工业机器人和ADAS(先进辅助驾驶)系统则建议配合Cortex-A、MaliGPU等提升整体运算。另外,ARM Cortex-R52通过多项安全标准认证,包括有IEC 61508(工业)、ISO 26262(车用)、IEC60601(医疗)、EN 50129(车用)以及RTCA DO-254(工业)等。2021年3月还推出了R52+架构。可以最高支持8个核心锁步。 R52包括三大功能,软件隔离:通过硬件实现的软件隔离,意味着软件功能互不干扰。对于安全相关的任务,这也意味着需要认证的代码更少,从而节省了时间、成本和工作量。
支持多个操作系统:借助虚拟化功能,开发人员能够在单个CPU内,使用多个操作系统来整合应用。这样可以简化功能的添加,而无需增加电子控制单元的数量。
实时性能:Cortex-R52+的高性能多核集群可为确定性系统提供实时响应能力,且在所有Cortex-R产品中产生的延迟最低。
Atlan拥有多达1000TOPS的算力,是Orin的4倍,看其内部布局,仍然是12个安培GPU模块,与Orin差不多,面积似乎也差不多,似乎还略微小了点,只不过Atlan的CPU die 面积远比Orin的要大,Atlan能取得1000TOPS的成绩,主要功劳应该是CPU、DPU和存储的功劳,单Ampere架构的改进不大可能取得如此高的提升。 Atlan是针对服务器超大规模模型而设计的,而自动驾驶车载模型的趋势是越来越小,精度越来越低,已经有人喊出1比特精度。Atlan反其道行之,特别支持服务器领域常见而自动驾驶领域少见的BFloat16精度。 显然英特尔对车载领域的兴趣度在逐渐下降,无论是CPU还是DPU,都是借服务器领域的,而非专为车载领域开发。
而在ARM服务器这个领域,依靠与ARM的深度合作与深厚的技术积累,英伟达能像英特尔笔记本电脑那样每两年就产品换代一次,不过一款车的生命周期至少是7-8年,车厂可不会认同这样的更新频率。但英伟达不在意,英伟达核心业务还是显卡和数据中心处理器,车载只是顺手做的,发挥CPUGPUDPU的余热。 而Orin的ARM A78内核是专为自动驾驶引进的新内核,在英伟达其他产品见不到A78的身影,足见对A78的重视,而Atlan只能见到对数据中心的重视。英伟达的另一个用意是拉上对手做算力军备竞赛,在宣传上大造声势,压迫对手必须跟进算力游戏,直到拖垮对手。其他厂家恐怕不会跟进这种算力数字游戏,这脱离了实际需求。Orin恐怕将是英伟达未来数年的主力产品。
原文标题:详解英伟达最新自动驾驶芯片-Atlan
文章出处:【微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
芯片
+关注
关注
455文章
50714浏览量
423158 -
英伟达
+关注
关注
22文章
3770浏览量
90990 -
自动驾驶
+关注
关注
784文章
13784浏览量
166397
原文标题:详解英伟达最新自动驾驶芯片-Atlan
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英伟达在华加大招聘,聚焦自动驾驶技术
Orin芯片的技术特点
科技看点:摩根大通详解“英伟达芯片问题”马斯克560亿薪酬方案引争议
FPGA在自动驾驶领域有哪些优势?
FPGA在自动驾驶领域有哪些应用?
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
自动驾驶公司Wayve获10.5亿美元C轮融资,软银、英伟达加持
沃尔沃利用英伟达的SoC和AI来提升自动驾驶的安全性
英伟达参投英国自动驾驶初创公司10亿美元融资
英伟达参投英国自动驾驶公司融资
比亚迪将搭载英伟达DRIVE Thor车机芯片,推进自动驾驶和智能工厂技术
高通自动驾驶靠软件开发革新力压英伟达自动驾驶芯片
挑战英伟达,索尼AFEELA里的高通数字底盘

英伟达:四家中国车企选其自动驾驶芯片平台
英伟达智能驾驶的核心芯片——Thor






 工商网监
工商网监
评论