 Grace设计是为了填补英伟达人工智能服务器中CPU的空缺
Grace设计是为了填补英伟达人工智能服务器中CPU的空缺
4月12日上午,英伟达召开了春季GPU技术大会,图形和加速器设计师宣布他们将再次设计自己的基于Arm的CPU。这款CPU以计算机编程先驱、美国海军少将格蕾丝•霍珀(Grace Hopper)的名字命名,它是英伟达在全面垂直整合硬件堆栈方面的最新尝试,能够在提供常规GPU产品的同时提供高性能CPU。据英伟达介绍,该芯片是专为大规模神经网络工作负载设计的,预计将于2023年在英伟达的产品中使用。
距离芯片准备就绪还有两年的时间,英伟达这次表现得相对低调,只提供了芯片的部分细节。例如,它将基于Arm的Neoverse内核的未来迭代产品,因为目前更多关注的是英伟达未来的工作流模式,而不是速度和输出。至少目前,英伟达已经明确表示,Grace是英伟达的内部产品,将作为其大型服务器产品的一部分。该公司并没有直接瞄准英特尔Xeon或AMD EPYC服务器市场,相反,他们正在建造自己的芯片来补充他们的GPU产品,创造一种可以直接连接他们的GPU的专用芯片,帮助处理参数规模达到万亿级的人工智能模型。
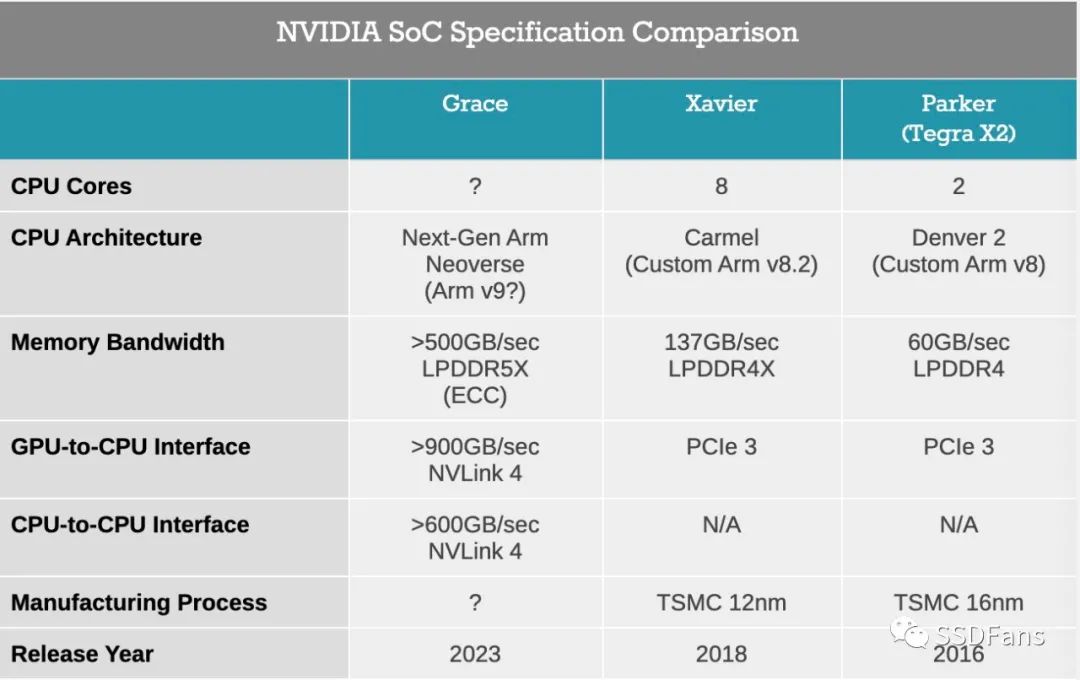
总的来说,Grace的设计是为了填补英伟达人工智能服务器中CPU的空缺。公司的GPU非常适合于特定的深度学习模型,但不是所有模型都必须依赖于GPU。英伟达当前的服务器产品通常依赖于AMD的EPYC处理器,该处理器对于一般的计算目的来说速度非常快,但缺少英伟达寻找的那种高速I/O和深度学习优化。更重要的是,英伟达目前因使用PCI Express进行CPU-GPU连接而遇到瓶颈。它们的GPU可以通过NVLink在彼此之间快速对话,但不能返回主机CPU或系统RAM。
这个问题的解决方案是使用NVLink进行CPU-GPU通信,就像Grace之前的情况一样。正是出于这个原因,英伟达曾与OpenPOWER基金会合作,将NVLink引入到POWER9中。然而,随着POWER的流行度下降,以及POWER10跳过了NVLink,这种关系似乎正在逐渐消失。而英伟达正在以自己的方式构建带有NVLink功能的Arm服务器CPU。
根据英伟达的说法,最终的结果将是一种高性能、高带宽的CPU与未来一代的英伟达服务器GPU协同工作。在英伟达谈论将每个英伟达 GPU与一个Grace CPU集成在一块板上的情况下(类似于今天的夹层卡),不仅CPU性能和系统内存随GPU的数量而增加,而且通过回旋方式,Grace可以用作英伟达 GPU的各种协处理器。这是一个非常英伟达解决方案,不仅可以提高性能,而且在AMD或Intel的CPU与GPU尝试类似的集成与融合的情况下,可以给他们一个反击。
到2023年,英伟达将达到NVLink 4, SoC和GPU之间的累积带宽将至少达到900GB/秒,Grace SoC之间的累积带宽将超过600GB/秒。关键是,这大于SoC的内存带宽,意味着英伟达的GPU将有一个到CPU的高速缓存链接,可以在全带宽下访问系统内存,同时也允许整个系统拥有一个单一的共享内存地址空间。英伟达将此描述为平衡系统中可用的带宽数量。拥有内置CPU是增加内存有效量的主要手段,因为英伟达的GPU仍然是大型神经网络的主要限制因素,由于内存容量的限制,只能有效地运行与本地内存池一样大的网络。
而且,这种以内存为中心的策略也反映在Grace的内存池设计中。由于英伟达将CPU与GPU放在一个共享的软件包中,因此他们打算将RAM放在它旁边。配备Grace的GPU模块将包括一定数量的LPDDR5x内存,而英伟达的目标是至少500GB /秒的内存带宽。在2023年,LPDDR5x可能会成为带宽最高的非显卡存储器选项,此外,由于LPDDR5x技术的根源是移动设备,而且追踪长度非常短,英伟达还在大力宣传使用LPDDR5x可以提高能源效率。而且,由于这是服务器部分,Grace的内存也将启用ECC。
至于CPU性能,实际上这是英伟达所说得最少的部分。该公司将使用下一代Arm的Neoverse CPU内核,,在这方面,最初的N1设计已经吸引了大量眼球。除此之外,该公司还表示,在SPECrate2017_int_base的吞吐量基准测试中,这款处理器的内核将突破300点,与AMD的一些第二代64核EPYC处理器相当。该公司也没有透露太多关于CPU是如何配置的,或者针对神经网络处理的优化是如何添加的。但由于Grace的目的是支持英伟达的GPU,预计它会在GPU普遍较弱的情况下变得更强。
另外,如前所述,英伟达为Grace设计的远大目标是大大减少了大型神经网络模型训练所需的时间。英伟达的目标是在1万亿参数模型上提高10倍的性能,
而他们对64个模块的Grace+A100系统(具有理论上的NVLink 4支持)的性能预测将把这种模型的训练时间从一个月缩短至三天。或者,能够在8个模块的系统上对5000亿个参数模型进行实时推断。
总体而言,这是英伟达在数据中心CPU市场的第二次真正尝试,也是第一次有可能成功。英伟达的Project Denver计划最初是在十年前宣布的,但从未像英伟达预期的那样取得真正的成果。定制的Arm内核家族从来都不够好,也从未使用英伟达的移动SoC制成。相比之下,Grace对于英伟达来说是一个更安全的项目。它们只是授予Arm内核许可,而不是构建自己的内核,这些内核也将被其他许多方使用。因此,英伟达的风险降低了,主要是在I/O和内存方面做得很好,并保持最终设计的节能效果。
如果一切都按计划进行,那么有望在2023年见到Grace。英伟达已经确认Grace模块将可用于HGX载板,以及扩展为DGX和所有其他使用这些板的系统。因此,尽管我们还没有看到英伟达Grace计划的全部内容,但很明显,他们正在计划使其成为未来服务器产品的核心部分。
两个超级计算机客户:CSCS和LANL
尽管Grace要到2023年才能发货,但英伟达已经找到了首批客户,而且他们都是超级计算机的客户。瑞士国家超级计算中心(CSCS)和洛斯阿拉莫斯国家实验室今天宣布,他们将订购基于Grace的超级计算机。这两套系统都将由惠普的克雷集团(Cray group)建造,预计将于2023年上线。
CSCS的系统称为Alps,将替换其当前的Piz Daint系统,即Xeon和英伟达 P100集群。根据两家公司的说法,Alps将提供20 ExaFLOPS的AI性能,大概是CPU,CUDA内核和张量内核吞吐量的组合。推出时,Alps应该是世界上最快的以人工智能为中心的超级计算机。
有趣的是,CSCS对系统的雄心壮志不仅限于机器学习工作负载。该研究所表示,他们将把Alps作为通用系统,从事更传统的HPC类型任务以及以AI为重点的任务。这包括CSCS对天气和气候的传统研究,而AI之前的Piz Daint也已用于该研究。
如前所述,Alps将由HPE建造,后者将基于其先前宣布的Cray EX架构。这将使英伟达的Grace与AMD的EPYC处理器一起成为Cray EX的第二个CPU选项。
与此同时,Los Alamos的系统正在开发,作为实验室与英伟达之间持续合作的一部分,而LANL将成为美国第一个使用Grace系统的客户。尽管实验室计划利用Grace提供的最大数据集规模来计划将其用于3D仿真,但LANL并未讨论系统的预期性能是否超出“领导级别”的事实。LANL系统定于2023年初交付。
原文标题:Grace:英伟达数据中心CPU市场的第一次成功尝试!
文章出处:【微信公众号:ssdfans】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
cpu
+关注
关注
68文章
10850浏览量
211524 -
英伟达
+关注
关注
22文章
3767浏览量
90969
原文标题:Grace:英伟达数据中心CPU市场的第一次成功尝试!
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论