 一种交通场景下的行人检测方法
一种交通场景下的行人检测方法
作者:何许梅,舒小华,谷志茹,韩 逸,肖习雨
0 引言
行人检测是目标检测领域中重要的研究课题,其在智能驾驶系统、视频监控、人流量密度监测等领域有广泛应用。但由于行人背景的复杂以及个体本身的差异,行人检测成为目标检测领域的研究难点之一。
目前行人检测方法主要分为两类:传统的行人识别主要通过人工设计特征结合分类器的方式进行。比较经典的方法有HOG+SVM、HOG+LBP 等。此类方法可以避免行人遮挡带来的影响,但是泛化能力和准确性较低,难以满足实际需求。另一类是基于深度学习的方法。通过多层卷积神经网络(CNN) 对行人进行分类和定位。与传统特征算子相比,CNN 能根据输入的图像自主学习特征,提取图像中更丰富和更抽象的特征。目前已有许多基于深度学习的目标检测框架,如R-CNN(Region Convolutional Neural Network) 系列、YOLO(You Look at Once) 系列。R-CNN 系列算法又被称为二阶段算法,该类算法通过网络找出待检测目标可能存在的位置,即疑似区域,然后利用特征图内的特征信息对目标进行分类,优点是检测准确率较高,但实时性较差。YOLO 系列算法又称为一阶段算法,此类算法所有工作过程在一个网络内实现,采用端到端的方式,将目标检测问题转换为回归问题,使其网络的实时性得到了较好的提高,但准确率却不及Faster R-CNN(Faster Region Convolutional Neural Network,更快速的区域卷积神经网络)。
本论文借鉴目标检测的R-CNN 系列算法,在Faster R-CNN 网络的第一层卷积层前加入一个预处理层,其次使用K-means 算法聚类分析anchor 框中行人的宽高比,选出适合行人的宽高比作为anchor 的尺寸,提出交通场景下基于Faster R-CNN 的行人检测算法。所提方法在自制的交通场景下的数据集上进行测试,实验表明网络的检测效果有明显提升。
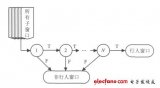
1 Faster R-CNN检测方法
Faster R-CNN 的检测框架如图1 所示。其检测流程主要分为4 部分:卷积网络、RPN(Region Proposal Network)、感兴趣区域池化(RoI Pooling) 以及目标检测分类。
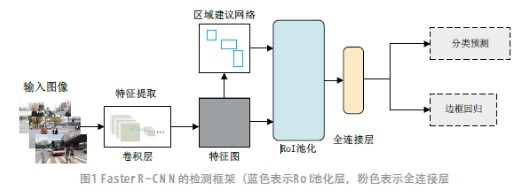
卷积网络由卷积层、池化层和输出层构成,各网络层之间权值共享,从训练的数据集中学习并自动提取目标特征。与传统手工设计特征相比,具有更好的泛化能力。
RPN 使用一个3×3 的块在最后一个卷积层输出的特征图上滑动来获得区域建议框即anchor 框,FasterR-CNN中的anchor 框有3 种比例尺寸,分别为0.5、1、2。
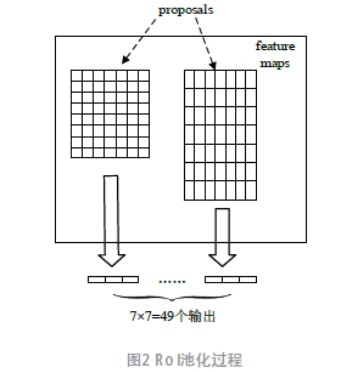
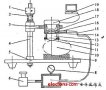
Faster R-CNN 的全连接层需要固定大小的输入,因此通过RoI 池化将不同大小的RoI 转成固定的大小。图2 为RoI 的池化过程。
在检测分类阶段,分类函数计算得分,得到目标的所属类别,同时通过边界框回归计算出检测框的位置偏移量,得到更精确的位置。
2 改进的行人检测方法
Faster R-CNN 是针对通用目标的检测网络,识别的类别数为20,但在行人检测中只需要识别“行人”及“背景”这两个类别。由于图片中的行人在图片中所占的比例较小,因此设计一个预处理层,提取一层底层特征(本文提取纹理特征),再与原始图像一起输入到卷积网络中,能够减少训练所需的时间。
2.1 预处理层
选择传统行人检测方法中的纹理特征(LBP 特征) 作为预处理部分要提取的特征。LBP 特征描述了图片的局部纹理,它以每个像素值为中心取一个局部邻域区域,比较该区域内的每个像素的灰度值与中心像素的灰度值,得到一个二进制码,即该中心像素的LBP 值。但会导致二进制模式种类过多,所以等价模式(Uniform Pattern) 应运而生。等价LBP(ULBP) 在LBP 算子的基础上,统计二进制数中“01”或“10”跳变的次数,若跳变次数在2 次以内,则称为一个等价模式类,定义式为:
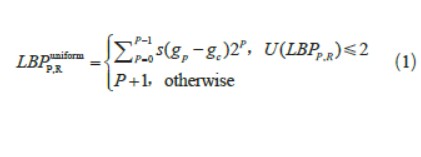
式中, gp 表示邻域像素值, gc 表示中心像素值,U(LBP ) P,R 代表“01”或“10”的跳变次数。
从图3 中可以看出,图像中行人与背景的区别转换成了纹理上的差异。
(a)原图
(b)ULBP图
图3 原图与ULBP图
2.2 anchor框聚类分析
使用k-means 聚类对训练集中所有行人目标的真实框进行聚类分析。anchor 框聚类分析算法的主要流程:
Step1:将训练集中所有目标框的宽高构成数据集D,再从D 中随机选择一个聚类中心ci false;
Step2:求D 中每个样本s 到ci 的距离,记为di ,将使di 最小的那个样本归到ci 中;
Step4:循环执行Step2 和Step3,直到聚类中心不变。
取出所有行人标注框的坐标信息,计算出每一个标注框的宽和高,并对其进行聚类统计,这里取聚类数k = 3 。随后,计算宽与高的比值,使用统计直方图的方法求出其均值,得到宽高比的均值μ = 0.39 ,也就是说训练集中目标的anchor 框的合适的宽高比是0.39,即w ≈ 0.39h。图 4 为行人 anchor 框的宽高统计结果。
因此,本文将原Faster R-CNN 算法中anchor 框的宽高比修改为(0.39:1)。
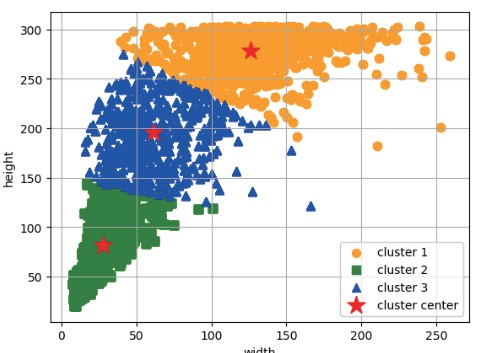
a)宽高统计图
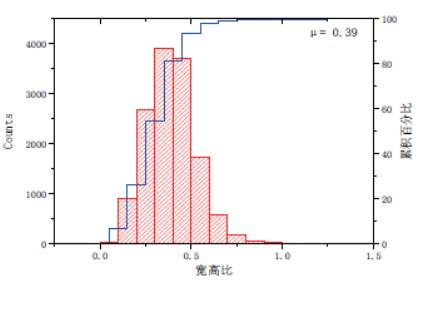
(b)宽高比统计图
图4 宽高聚类分析
3 实验结果与分析
3.1 实验数据集
实验数据集来源有:车载摄像头拍摄的图片、手机拍摄的图片,选取光照条件比较好的图片作为数据集,采用LabelImg 图像标注工具对采集到的图片进行标注,标注的区域包含行人的轮廓,得到带标签的行人数据集,共计1 304 张。标签名统一采用person 表示。在模型的训练阶段,选取数据集的80% 来训练模型,20% 作为测试集。部分实验数据集如图5 所示。
图5 数据集样本
3.2 实验平台及训练
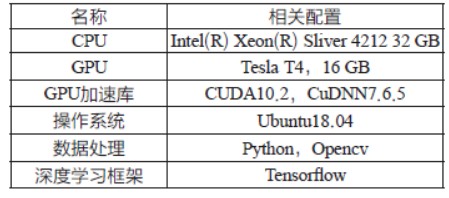
实验所使用的软硬件环境如表1 所示。
表1 软硬件配置
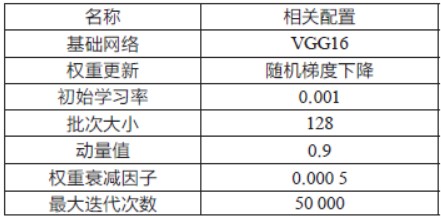
训练参数如表2 所示。
表2 训练参数设置
3.3 实验结果分析
实验采用平均准确度(mAP)作为判断算法性能的标准。在自制的数据集上进行实验,检测精度达到了90.1%。所提方法检测结果与直接使用Faster R-CNN的检测效果对比如图6 所示,图6(a) 表示直接使用Faster R-CNN 的检测效果,图6(b) 表示所提算法的检测效果,通过左右图片对比可以看出,使用所提算法检测出来的目标个数要优于调整前的检测个数。
(a) Faster R-CNN检测结果
(b)本文方法结果
图6 测试结果对比
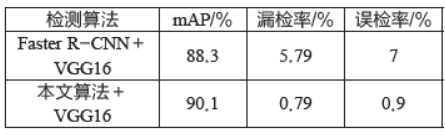
为了比较调整宽高比对模型准确率的影响,在自制数据集上对原算法和所提算法分别训练40 000 次。得到的检测准确率如表3 所示,所提算法的准确率较原算法提高了1.8%。
表3 调整宽高比前后测试结果
4 结语
以Faster R-CNN 为基础,通过在卷积层之前加入一个预处理层成功实现行人检测的目标。以自制数据集为训练和测试网络所需的数据,针对漏检和误检,提出将纹理特征作为底层特征对原图进行预处理,同时使用K-means 算法对行人宽高比进行统计分析,得出适合数据集中行人的宽高比尺寸,达到降低漏检的目的。实验测试结果表明,本文算法可以有效提高交通场景下行人检测的准确率,在漏检率和误检率上,分别提高了5%、6.1%。但存在训练样本还不够丰富,因此下一步研究工作的重点将放在提高检测模型的实时性和鲁棒性上。
责任编辑:tzh
-
视频监控
+关注
关注
17文章
1710浏览量
64945 -
网络
+关注
关注
14文章
7553浏览量
88726 -
检测
+关注
关注
5文章
4480浏览量
91440 -
深度学习
+关注
关注
73文章
5500浏览量
121109
发布评论请先 登录
相关推荐
基于稀疏编码的迁移学习及其在行人检测中的应用
如何设计一种基于DSP的车辆碰撞声检测装置?
一种基于图像平移的目标检测框架
基于车载视觉的行人检测与跟踪方法
一种基于交通视频的摄像机标定方法


基于改进型LBP特征的监控视频行人检测
一种改进的基于卷积神经网络的行人检测方法






 工商网监
工商网监
评论