 开放域信息抽取和文本知识结构化的3篇论文详细解析
开放域信息抽取和文本知识结构化的3篇论文详细解析
引言
2020年,自然语言处理领域顶级的国际学术会议EMNLP(Conference on Empirical Methods in Natural Language Processing)共录取论文751篇
开放域信息抽取是信息抽取任务的另一个分支任务,其中抽取的谓语和实体并不是特定的领域,也并没有提前定义好实体类别。更一般的,开放域信息抽取的目的是抽取出所有输入的文本中的形如 《主语,谓语,宾语》 的三元组。开放域信息抽取对于知识的构建至关重要,可以减少人工标注的成本和时间。
本次Fudan DISC实验室将分享EMNLP2020中关于开放域信息抽取和文本知识结构化的3篇论文,介绍最新的开放域信息抽取的研究。
文章概览
关于开放域信息抽取神经网络结构和训练方式的系统比较 (Systematic Comparison of Neural Architectures and Training Approaches for Open Information Extraction)
该文将神经网络基础的OpenIE框架系统分解为三个基本模块:嵌入块、编码块和预测模块。在探究各种组合时,他们发现:pre-training的语言模型+Transformer编码器+LSTM预测层在OpenIE2016基准上有了巨大的改进(提升200%)。此外,他们还提到,NLL损失函数可能更偏向浅层预测。
OpenIE6:开放域信息的迭代网格标记抽取以及并列短语分析 (OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction)
该文将OpenIE任务的三元组抽取构建为2-D(#extraction #words)网格标记任务,使得通过迭代抽取可以将一个句子中的所有三元组都有概率被模型识别出来。该文将他们的抽取方式称为IGL(Iterative Grid Labeling),并在计算损失函数的时候加4种入关于词性的软约束,并在最终的loss计算时加起来作为约束惩罚项。实验结果表明了他们模型的有效。
DualTKB: 在文本和知识库之间进行双重学习 (DualTKB: A Dual Learning Bridge between Text and Knowledge Base)论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.694.pdf
该文建立了多个任务将某些文本(选项A)或KB中的路径三元组(选项B)作为输入,然后两个解码器分别生成文本(A)或另一个三元组(B)。也就是说,你可以有多种路线,例如A-B(从文本中提取三元组)或B-B(知识图谱补全)等。重复这个过程,你可以从文本中迭代提取更多三元组,或者对知识图谱反向解码为文本。
论文细节
1

任务定义
现有的OpenIE的任务定义主要分为两种:1)序列标注、2)子序列提取
其中序列标注框架最为常见,下图为用序列标注任务设定的开放域信息抽取。例子中一共有7类标签

子序列通过模型生成大量的可能的子序列三元组组合,模型负责给这些候选组合进行打分,并选出概率最高的几个三元组作为抽取结果。
作者通过比较这两种任务设定,总结出统一的OpenIE的任务设定:OpenIE任务将每一个问题定义为一个元组《X,Y》,其中将一个句子表示成有很多个词语的序列,定义了一个合法的抽取结果集合。如果是建模为序列标注问题,则是BIO标签;如果看作子序列提取问题,则是子序列集合。
方法
模型结构:文中对神经网络OpenIE的方法进行全方位的总结,作者将目前的框架分为了三个模块:1)Embedding Module;2)Encoding Module;3)Prediction Module;各模块的种类如下图。
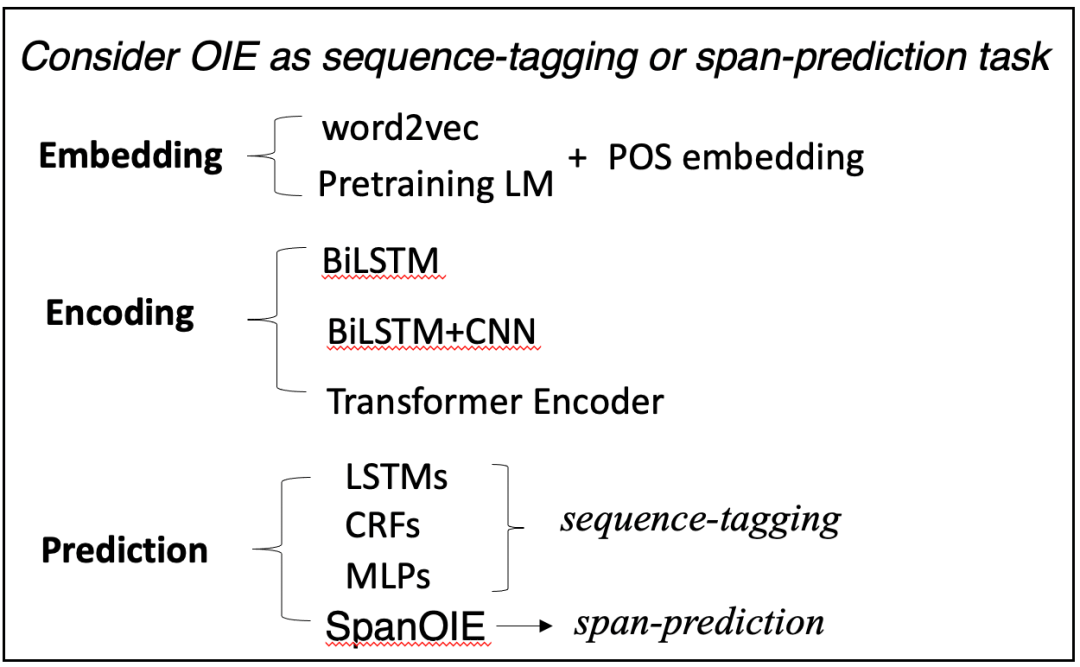
作者针对以上三个模块进行了不同组合,做了很多实验进行比较哪种组合方式是最好的。
训练方法:在进行训练的时候会遇到标签分类负样本标签的数量远远大于其他标签数量的情况,作者对这个问题提出了三种解决方案。如下图所示,第一种解决方案是在计算损失函数时不计算预测出标签的数据;第二种是计算预测出标签和非标签的边缘部分的损失函数;第三种是只计算边缘部分的非部分的损失函数值。
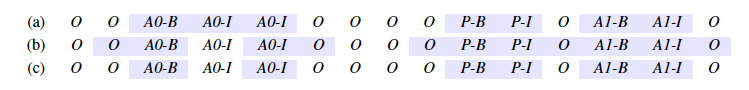
数据集和评价指标数据集来自于OIE16的benchmark 数据集,评价指标采用F1值和AUC-PR。
实验结果
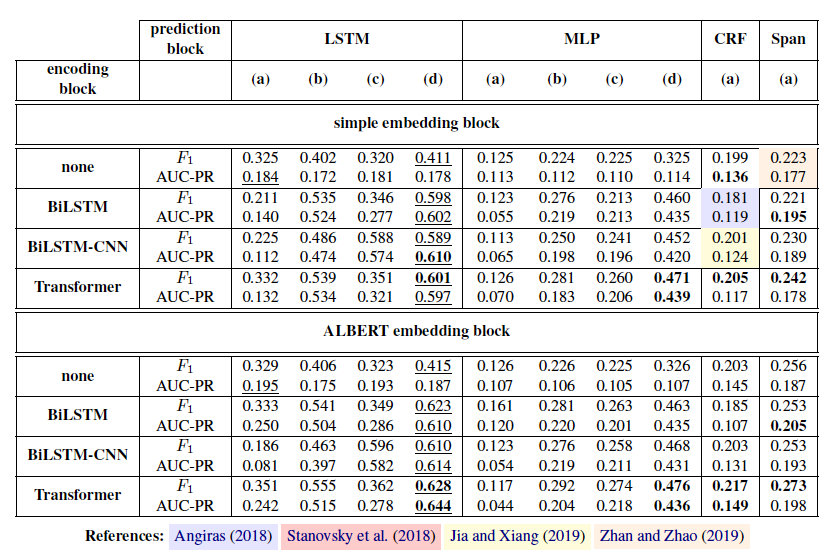
从主实验可以看出最优的组合是 ALBERT+Transformer+LSTM,并且用最后一种训练方式训练的模型。
作者对每个模块和训练方式还进行了消融实验如下。

该实验说明,embedding层使用Transformer效果最好。
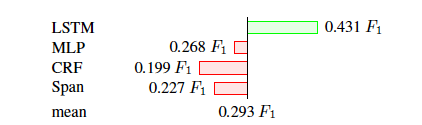
该实验说明,预测层使用LSTM效果最好。
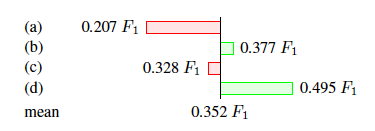
该实验说明,使用最后一种训练方式的效果是最好的。
2
论文动机
文中介绍了目前OpenIE最主流的两种框架:1)生成类的系统(通过迭代多次编码输入的文本,以进行多次抽取);2)序列标注系统。这两种框架都存在弊端:1)生成系统多次重复encoding输入的文本,会造成抽取速度慢,并不能很好的适应大数据时代的大量网页抽取场景;2)而序列标注系统,对于每个抽取都是独立的,并不能获取其他抽取内容的信息。
任务定义
给定一句话作为输入,然后抽取出一个集合作为抽取的结果,其中每个是一个的三元组。由于一句话中可能含有多个可抽取的三元组,如下图。
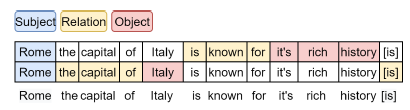
作者将这个任务建模为一个在2-D网格上进行迭代抽取的任务,网格的大小为,横坐标为句子分词,纵坐标为抽取出的结果。例如,坐标为的网格代表第n个词的第m次的预测标签,如下图。
方法
模型(Iterative Grid Labeling)
作者提出了一个迭代网格抽取方法,去完成这个网格抽取任务,其实就是利用迭代抽取,然后将上一节定义的的网格填满预测标签,模型图如下:
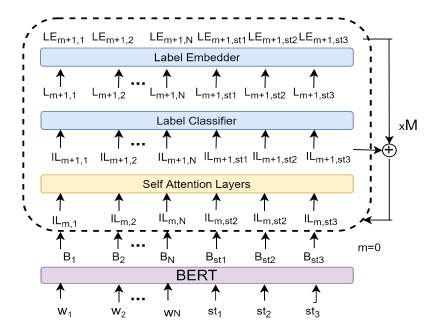
该结构一共迭代M次,每一次词向量都需要经过一个相同结构的模块如上图,模块中包含一个transformer 编码器的self-att层、一个又多层感知机组成的标签分类器和一个标签嵌入层。每次迭代后词向量编码器的输出会加入下一次的输入中去,以达到迭代信息传递的作用。文中作者将该方法称做IGL-OIE,训练得到的损失函数为。
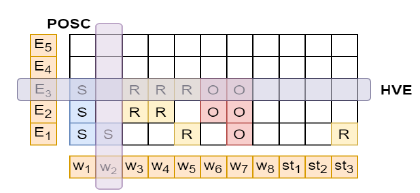
网格约束
在进行抽取的时候,作者提出了四种软约束来限制抽取的结果,一共有四种:1)POS Coverage(POSC);2)Head Verb Coverage(HVC);3)Head Verb Exclusivitu(HVE);4)Extraction Count(EC)。POSC约束了句子中的每个名词、动词、形容词和副词至少有一个要出现在抽取结果中;HVC约束了句中每一个头动词(有意义的动词)至少出现在其中一个抽取结果的关系中;HVE约束了每个抽取结果的关系只能有一个动词;EC约束了所有抽取结果的数量要少于句中所有头动词的数量。作者根据以上定义的约束,制定了以下四种损失函数惩罚项:
,
,
,
,
,
。
将以上约束和抽取训练的loss加起来得到总的损失:
并列连词检测
作者利用网格抽取和前人的并列连词抽取工具,设计了并列连词检测的方法称做IGL-CA,如下图
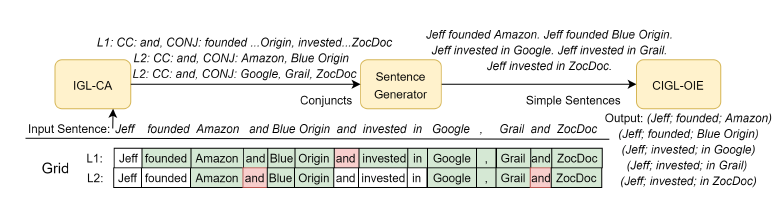
真正训练的时候先用IGL-CA将长句根据并列连词位置拆成简单句,再进行IGL-OIE进行抽取。
数据集和实验准备
训练数据集来自于Open-IE4,同时也是用来训练IMoJIE的数据集。用于比较的模型有IMoJIE、RnnOIE、SenceOIE、SpanOIE、MinIE、ClasusIE、OpenIE4和OpenIE5。实验评价在CaRB、CaRB(1-1)、OIE6-C和Wire57-C上,并以F1和AUC作为评价指标。
实验结果
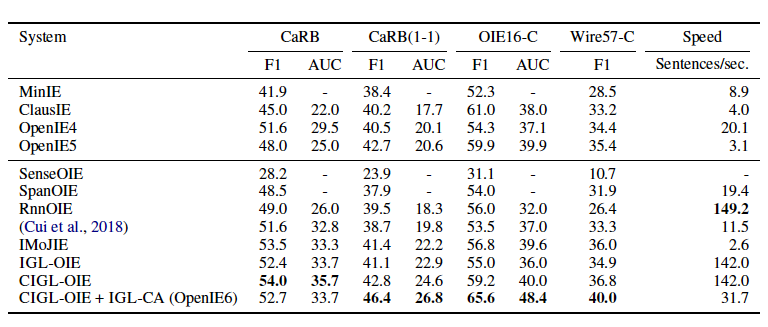
从实验结果看出本文提出的OpenIE6在三个评价数据集上都取得了最好的成绩,而且当加入了软约束后速度加快了5倍,该模型在准确率不降的基础上,加快了推理速度。
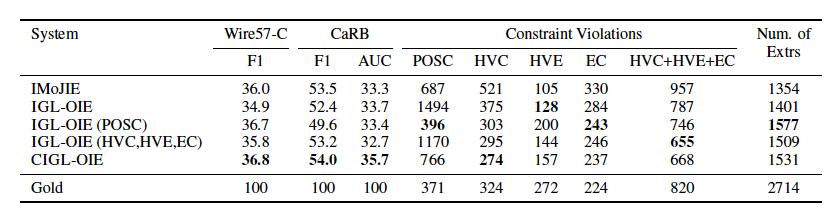
作者还分析了各约束间的关系,发现最有用的是POSC约束。
3

动机和贡献
构建知识图谱是一项很费人力的事情,这项工作提出了一种知识的转换器,用于转换纯文本和知识图。换句话说,如果给模型很多句子,模型就可以把这些句子变成一个图存储成知识图谱。反过来,给模型一个图,可以利用图中节点和边的关系,将图还原成带有知识的句子。
任务定义
任务1(文本路径):
给定一句话,然后生成一个具有格式正确的实体和关系的路径,该路径和实体可以属于已经构造的KB,也可以以一种实际有意义的方式对其进行扩展。此条件生成被构造为称为的翻译任务,其中。
任务2(路径文本):
给定KB路径,则生成描述性句子,将路径中的实体和关系连贯地合并。此条件生成是称为的翻译任务,其中。
下图给定了一些标记符号:

方法
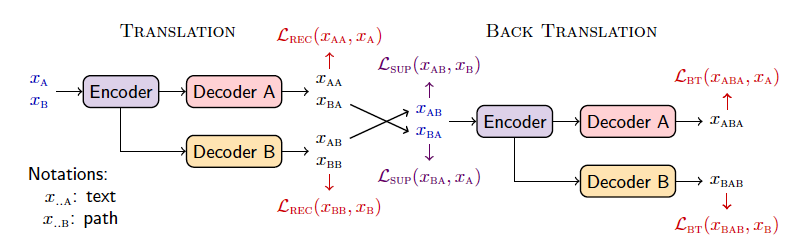
由于缺少KB和文本对应的数据集,所以作者首先想到了采用自编吗器的方式设计了四个无监督的任务:(1)文本到文本(AA)(2)图到图(BB)(3)文本到图到文本(ABA)(4)图到文本到图(BAB)。这四个任务分别对应上图的、、和。计算公式如下:
由于作者采用的数据集是ConceptNet,然后作者找到了构建ConceptNet的语料集合,然后作者采用实体和关系在文本中进行模糊匹配的方式对齐了一些图路径和文本的训练对,由于这个转换是不准确的所以只能是弱监督学习,在模型图中对应的任务是(1)图到文本(BA)和(2)文本到图(AB),损失函数如下:
实验设计
本文的实验选取了常识领域的文本数据OMCS,和常识知识图谱ConceptNet(CN600K)。因为CN600K中的部分三元组是从OMCS中抽取得来,所以部分文本和路径所表达的知识是相同的。对于弱监督数据,文中使用Fuzzy Matching的方式对齐文本和路径。需要注意的是,因为对齐的数据是基于路径和文本之间的相似度进行选择的,所以对齐的数据是有噪声的。
文中涉及文本生成任务和知识图谱补全任务,所以评价指标根据任务的不同有着变化。总体来说,生成任务包括BLEU2、BLEU3、Rougel和F1;知识图谱补全任务采用了常用的MRR和HITS@N指标。由于作者还设计了一个通过一堆句子生成新图的任务,所以需要一个指标来评价新图和原来的图有多少不同,因此引入了图编辑距离(GED)来评价这个任务。
实验结果
文本路径互转的性能

从文本到文本的效果很好,但是如果通过中间图转化的话效果就会差很多,说明跨模态的知识迁移能力需要提高。
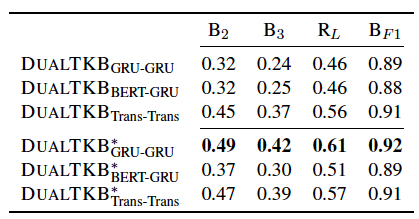
如果直接用路径生成文本,效果就更差了,但是本文提出了一种新颖的思想。
知识图谱补全任务
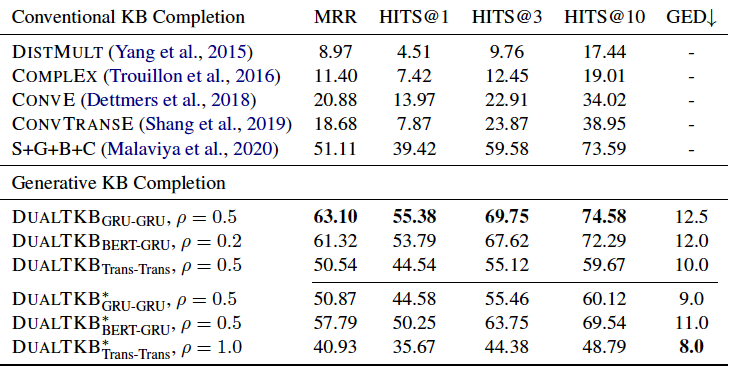
在知识图谱补全任务上,本文提出的模型优于前人的baseline,值得注意的是,代表了弱监督的比例,从实验结果来看,并不是弱监督越多越好,因为带有很多噪音。因此作者还对应该加入多少弱监督进行了探索,实验结果如下:
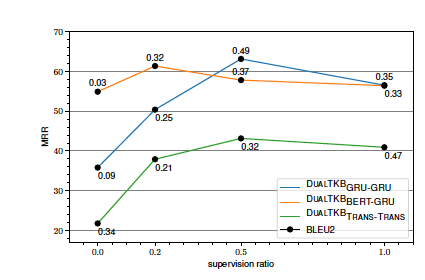
发现大致是加入0.5比例的监督效果是在最好的模型上表现提升较多。
编辑:lyn
-
神经网络
+关注
关注
42文章
4789浏览量
101613 -
LSTM
+关注
关注
0文章
60浏览量
3846
发布评论请先 登录
相关推荐
非结构化数据中台:企业AI应用安全落地的核心引擎
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
迅为RK3568开发板篇OpenHarmony实操HDF驱动控制LED-接口函数
结构化布线在AI数据中心的关键作用
TSMI252012PMX-3R3MT功率电感详细解析






 工商网监
工商网监
评论