 基于Aspect、Target等医疗领域情感分析的应用场景
基于Aspect、Target等医疗领域情感分析的应用场景
前言
情感分析是文本分类的一个分支,是对带有情感色彩(褒义贬义/正向负向)的主观性文本进行分析,以确定该文本或者用户的观点、喜好、情感倾向。医疗领域同样存在情感分析的应用场景,但与一般的领域不同,医疗领域的难点在于:
医疗实体既能作为aspect,又能作为情感词。对于一般aspect,如药品,行为等,比较接近以往研究;但是对于疾病,症状这样的aspect,情况复杂。如:“感冒吃白加黑管用 ”,对于这里“感冒”来讲,只是普通上下文。但是对于“感冒一周了,谁说能自己好的?”,“感冒”是aspect且情感是负向,同时,句子里也出现了“好”这一常见的情感词。两者的混杂,使得情感分析相当依赖上下文和领域特点。
大部分疾病实体词在公开情感词典中都是负向的,如:感冒,发烧,疼痛等。并且丁香园场景下的很多评论的情感倾向不是单纯的正负中,会出现更多样的情感(如:质疑,吐槽,建议),这是一般的情感词典里是无法处理的。所以领域情感词典的构建也是情感分析中关键一步。
存在多种情感,标注或远监督过程会存在噪音。
本文将从可解释性,上下文(aspect与sentiment的潜在关系),如何处理噪声数据以及构建领域词典四个角度,引出相应研究。
一。 可解释性
《Contextual Sentiment Neural Network for Document Sentiment Analysis》
深度神经网络已成为众多nlp任务的首选模型。然而,在需要解释的情况下,通常避免使用dnn,因为这些网络通常是黑匣子。因此,建立一个高度可预测的神经网络(NN)模型,并用类似人的方式来解释其预测过程是一个关键问题。那么在情感分析任务上,应该考虑人类通常是如何判断每次评论的正负极性的。论文主要考虑了4个方面:
词级原始情感得分:表示评论中每个词最初的情感,如good是正,bad是负。
词级情绪转移分数:该分数表示评论中每个术语的情绪是否发生了变化,如存在否定词,讽刺,幽默。
词级语境情绪得分:该得分是指在考虑情绪转移和全局重要点后,每个词的积极或消极情绪得分。
概念级上下文情绪得分:该分数表示每个评论的概念级积极或消极情绪,其中一个概念意味着一组相似的术语。
结构简单来说就是four interpretable layers+IP Learning:其中WOSL采用词典特征,SSL采用否定词典,GIL采用revised self-attention,CCSL采用kmeans。
通常情况下,情绪分析模型是使用反向传播,预测的文档级情绪与每个评论的正面或负面标签之间的损失值具有梯度值;但是,当使用这种通用反向传播方法时,每一层并不代表相应的情绪。因此文本提出了IP传播方法。
二。 上下文(aspect与sentiment的潜在关系)
《Weakly-Supervised Aspect-Based Sentiment Analysis via Joint Aspect-Sentiment Topic Embedding》
aspect级别情感分析的难点在于:第一,aspect真正的上下文;第二,同一句中每个aspect能够捕捉到自己的sentiment。
本文提出了一种基于topic model的弱监督方法,使用几个关键字来描述每个Aspect-Sentiment,无需使用任何带标签的样本。先在word embedding空间中学习Aspect-Sentiment联合主题嵌入,通过正则化来强化主题的显著性。学习了联合主题向量之后,利用文档embedding和主题embedding之间的余弦相似性对CNN进行预训练,
然后利用self-train CNN对未标记文档进行高置信度预测。
文中提出了几个关键的 joint representation learning,其中包括aspect---上下文, aspect---全文,aspect,sentiment单独representation learning,aspect—sentiment 联合学习。通过边缘分布和联合分布之间的关系,将联合主题嵌入的学习与单独的方面/情感主题联系起来。由于对于一般的sentiment,如good或bad,并不是aspect强相关的,使用均匀分布来调整它们在不相关维度上所有aspect的分布。
其次本文采用了self-train的思想,利用模型对未标记的高置信样本预测来完善模型。通过平方运算增强高置信度预测,根据当前模型的预测计算每个未标记文档的目标分数。当目标分数更新后没有更多的样本更改标签分配时(收敛),self-train过程终止。
从实验结果可以看出,模型对不同category词的聚类效果明显,可解释性强,因此用于下游分类任务时,表现较好。
《Context-aware Embedding for Targeted Aspect-based Sentiment Analysis》
现有的基于注意力机制的神经网络模型虽然取得了较好的效果,但是由于这些方法中表示target和aspect的向量都是随机初始化的,这样就会产生以下问题:
现有的方法在表示目标(target)和方面(aspect)时往往会脱离上下文。这种随机初始化或不依赖于上下文的表示方法有三个弊端:1)同一个目标或方面的向量表示在表达不同情感极性的句子中没有得到区分;2)目标不是确定实体时(例如“这个酒店”,“这个餐馆”,“那部电影”等),输入信息无法体现实体本身的价值;3)忽略了目标和方面之间的相互联系。
目标和方面在上下文中存在重叠的关联映射关系。在一句话中,一个目标可能会对应多个方面,而不同的方面可能会包含不同的情感极性。另一方面,在同一句话中往往会存在多个目标,所以目标和方面之间会存在错综复杂的对应关系。如图:
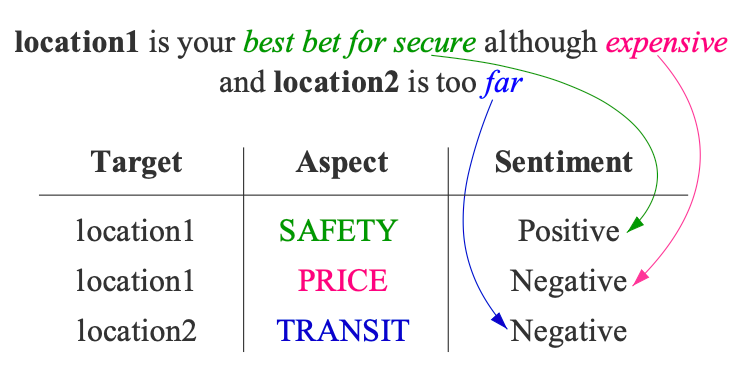
为解决上述问题,本文提出了一种结合上下文信息优化sentiment和aspect向量表示方法,该方法可以直接和现有基于神经网络的目标-方面级别情感分析模型相结合,如图所示:
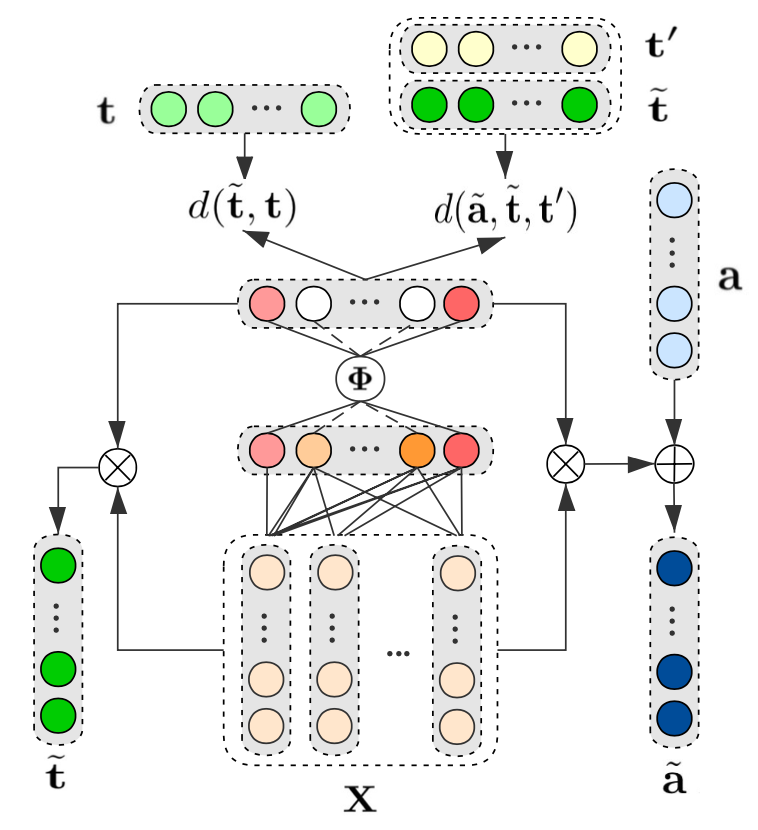
(1)稀疏系数向量:
本文使用一个稀疏系数向量来提取文本中与sentiment相关度较高的词语,并使用这些词语作为sentiment的上下文信息。通过对sentiment上下文词向量的聚合获得最终表示。通过这种方法,sentiment向量可以从上下文中自动学习,所以就算句子中的目标不是确定的实体,也能得到有价值的向量表示。得到每个词在句子中的权重表示,用阶跃函数将权重表示稀疏化,由此得到的就是稀疏系数矩阵,用输入X与稀疏系数矩阵相乘即可得到根据上下文构建的sentiment向量。
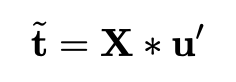
目标函数为最小化上下文相关sentiment向量与输入的sentiment向量距离:
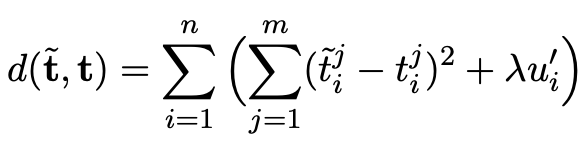
(2)微调aspect向量:
对于aspect向量,由于词本身就包含一定的语义信息,比如“价格”这个方面,而上下文信息与这个方面关联度比较高的词也会起很大作用,所以在对于方面信息的微调,是在初始的aspect向量上,利用上下文语义信息进行调整:
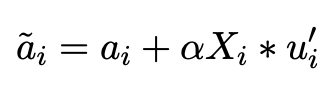
目标函数同理:
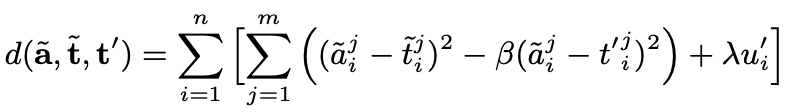
通过两个目标函数,使优化后的aspect向量尽可能靠近与它相关联的目标,远离与它无关的目标,从而使输入句子针对不同方面的情感信息得到有效区分。从图中结果可以看出,本文提出的方法能使不同方面在训练过程中得到更好的区分,有效提升了aspect向量表示的质量。
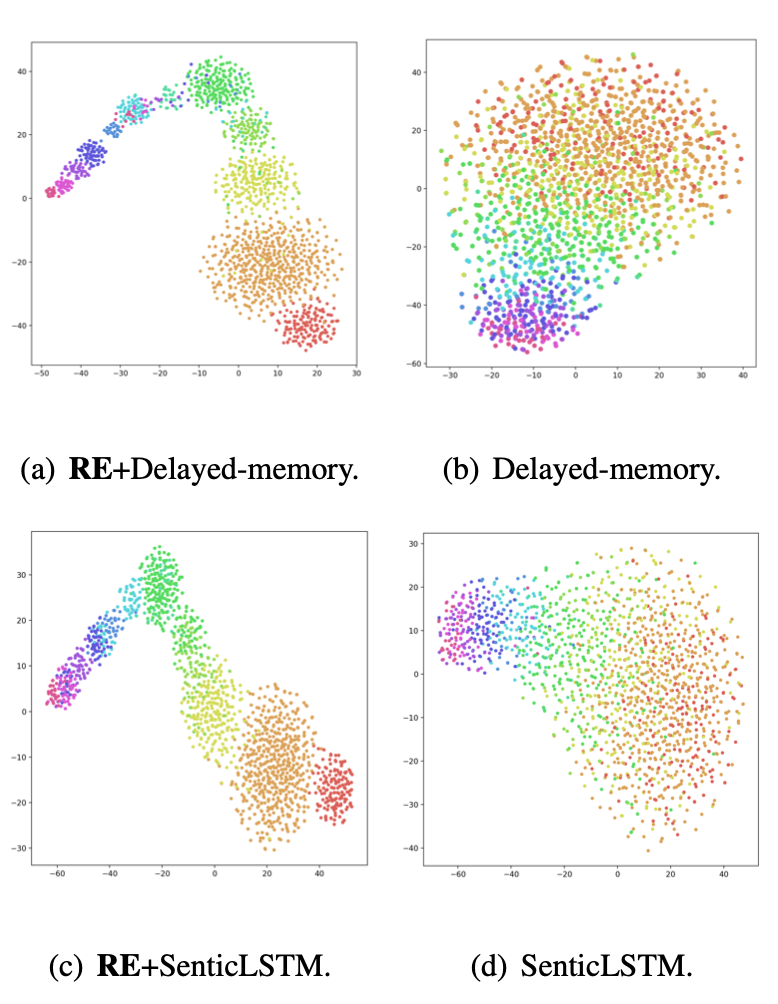
从实验结果可以看出,对于“恶心”“头疼”这种情感倾向极其依赖上下文,并且上下文语义结构复杂的情况,模型能很好地区分不同语境下同一aspect的情感,也能判断出此时的aspect是否是情感词。
《SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge》
相较于上述方法,本文用到了transformer,让模型获得更多上下文语义信息,除此之外,还有两处亮点:
(1)从SentiWordNet获取每个词及其词性标签的情感极性,作为“Linguistic Knowledge”。
(2)将预训练模型分2个阶段:Early Fusion早期融合和Late Supervision后期监督。
主要区别是早期融合阶段是把句子情感也作为输入,后期监督是把句子情感作为预测标签,监督训练句子情感。早期融合和后期监督的目的是让模型能够理解句子级情感和单词级情感和词性之间的内在联系。1)获取每个单词的词性tag和情感倾向;2)通过标签感知的mask语言模型进行预训练, 与现有的BERT-style预训练模型相比,模型通过其语言知识(包括词性tag和情感倾向)丰富了输入序列,并利用标签感知的masked语言模型来捕获sentence-level语言表示与word-level语言知识之间的关系。
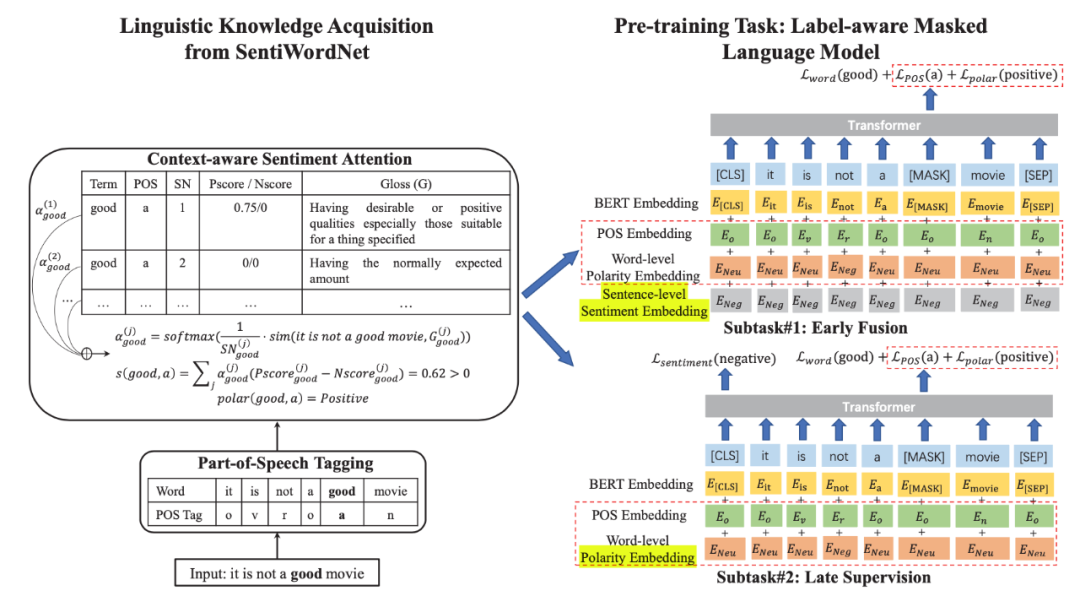
提出了一种上下文感知注意力机制,该机制同时考虑了词义等级, 以及上下文光连贯性来确定每种词义的注意力权重
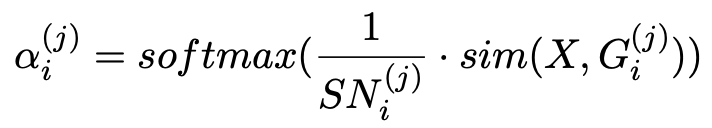
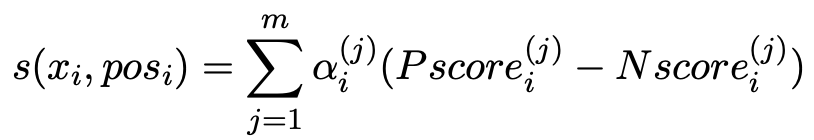
Early Fusion
早期融合的目的在于恢复以语句级label为条件的mask序列,模型分别预测masking位置处的单词,词性tag和word-level倾向。此子任务明确地对单词和单词的语言知识施加了全局情感label的影响,从而增强了复杂语义关系的能力。
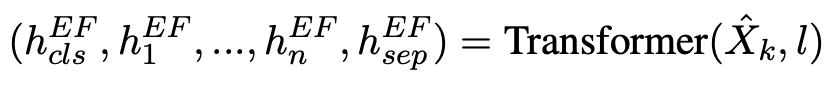
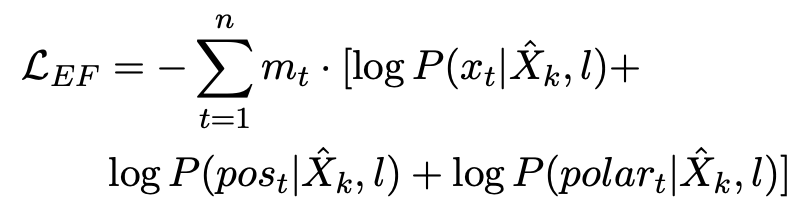
Late Supervision
基于[CLS]和masked位置的隐藏状态来预测sentence-level的label和单词信息。此子任务使我们的模型能够捕获[CLS]处的句子级表示形式与Masked位置处的单word-level语言知识之间的隐式关系。
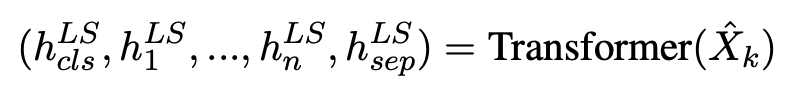
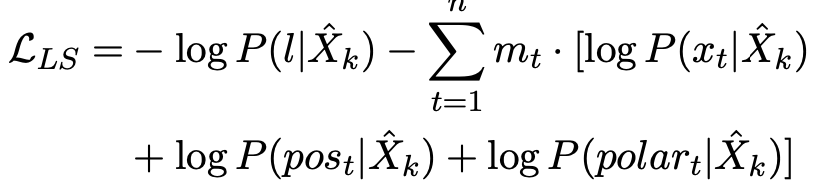
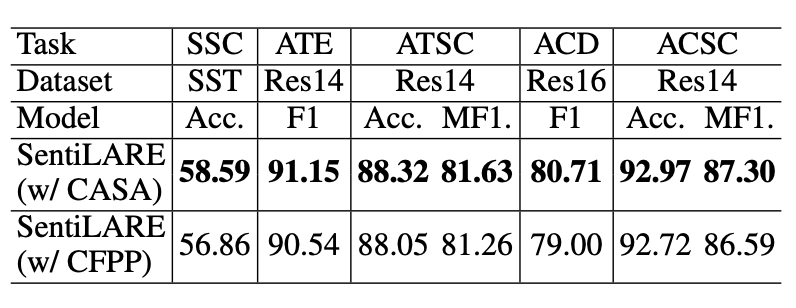
由于模型用到了pos embedding,因此在aspect的识别上效果明显,另外,可以通过相邻的情感词来检测aspect术语。另外上下文感知情感注意力机制。对不同上下文中单词的情感进行建模,从而带来更好的知识增强的语言表示。
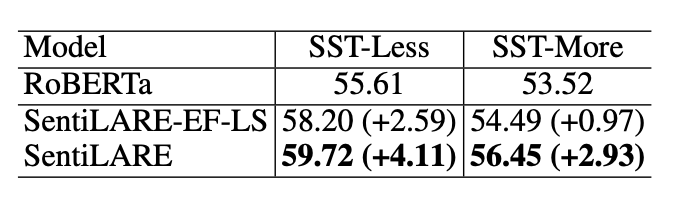
多情感词的句子可能包含更复杂的情感表达,为了进一步证明标签感知的masked语言模型的重要性,论文比较了三种模型:不使用语言知识的RoBERTa,通过语言知识简单地增加输入嵌入的SentiLARE-EF-LS和通过预训练任务深度集成语言知识的SentiLARE。结果表明预训练任务可以帮助将word-level语言知识所反映的局部情感信息集成到全局语言表示中,并有助于理解复杂的情感表达。
三。 标签中的噪音
《Learning with Noisy Labels for Sentence-level Sentiment Classification》
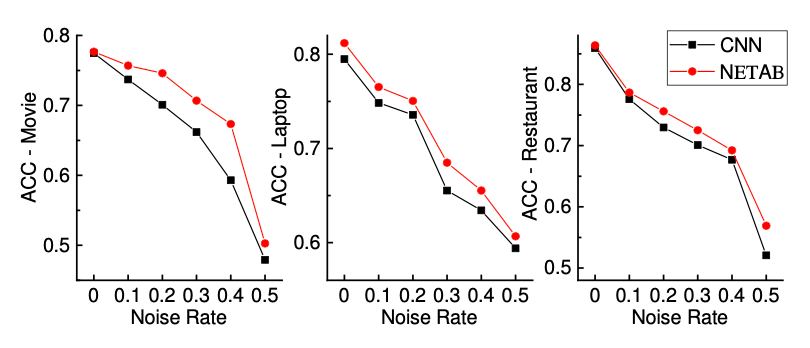
前言处我们提到句子级别的情感分析面临的一个问题,即存在多种情感时,标注过程会存在噪音。除了标注过程外,前面提到的Self-train 最大的问题也在于伪标签带来的噪音。针对标签中的大量噪音,本文提出了NETAB模型。
NETAB由两个卷积神经网络(cnn)组成,一个用于学习情绪得分以预测clean标签,另一个用于学习噪声转换矩阵以处理输入噪声标签。AB网络共享A网络的所有参数,除了门单元的参数和clean loss。
假设:训练数据中的噪音不超过50%
(1)DNN首先记忆简单的实例,并随着训练时间的增加逐渐适应硬实例;
(2)噪声标签理论上是通过噪声转移矩阵从干净/真实标签中transition。在训练中,先对A网络进行早期预训练,然后交替训练AB网络和A网络,使其具有各自的loss func。
在训练过程中,对A网络进行了early epoch的预训练,然后利用各自的交叉熵损失对两个网络进行AB网络和A网络交替训练。即给出一批句子,我们首先训练AB网络,然后利用A网络预测出的分数,从这一批中选出一些可能干净的句子,并对所选句子进行训练。具体地说,使用argmax计算标签,然后选择其结果等于输入标签的句子。在图中,选择过程由一个门单元标记。测试一个句子时,使用A网络来产生最终的分类结果。NETAB的表现非常出色,尤其在movie数据集上:
四。 领域情感词典构建
第二篇论文里提到,利用主题模型增强不同aspect的情感特征,当但主题模型的缺点也很明显:
(1)高频且没有任何情感含义的形容词非常容易被选中
(2)分词:由于一些情感词更像是短语,如“多用用脑子”,“涨姿势”,“不早点推(荐)”,所以主题模型的重要一环是发现新情感词。
那么下面我们会介绍一些领域情感词典构建的相关研究。
《Sentiment Lexicon Construction with Representation Learning Based on Hierarchical Sentiment Supervision》
为了充分利用文本中的sentiment label,业界提出了一系列有监督学习方法来学习情感词。其中在神经网络结构中加入Sentiment Supervision,训练sentiment-aware word embedding,成为主流。但文档级情感分析中存在的否定、过渡、比较度等复杂的语言现象以及word representation sum up,使得很多词语的真实情感会随着文档标签变化,导致模型表现不佳。因此,论文除了在文档层次训练sentiment-aware word embedding,同时也引入了词层次上的情感感知的词嵌入,以提高词嵌入和情感词典的质量。
(1) 词级情感学习与标注
论文提出了多种词级情感标注,如1)预定义的情感词典;2)带有硬情感标注的PMI-SO词典;3)带有软情感标注的PMI-SO词典。
(2) 情感感知词嵌入学习
对于文档d中的每个单词,将其映射为一个连续表示形式e,cost function 为平均交叉熵,度量预测的情感分布和在词水平上的情感注释之间的差异。
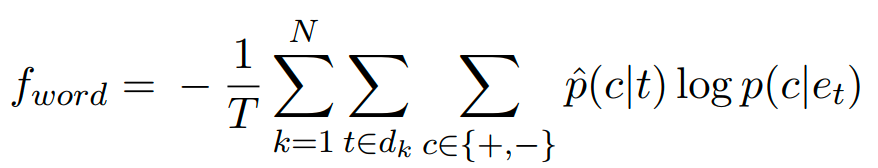
为了在词和文档两个层次上学习情感感知的词表示,采用加权组合的方法来集成两个层次的代价函数。
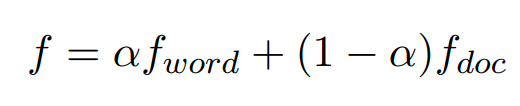
(3) 情感词典构建
利用人工标注的125个正种子词和109个负种子词的嵌入作为训练数据。最后,利用variant-KNN classifier对种子词进行扩展。
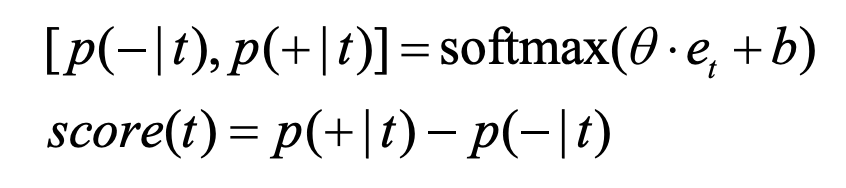
《Automatic construction of domain-specific sentiment lexicon based on constrained label propagation》
除了文档级情感分析中存在的否定、过渡、比较度等复杂语言现象外,特定领域的情感词极性也有很大区别,如:
电影,金融和食品所有的推文都在每条推文中使用“long”一词。然而,“long”有完全不同的含义。在电影里“long”代表电影长度,意味着这部电影很无聊;在金融领域,投资者总是用“long”字来形容代表买入仓位。在食品领域,“long”字只是用来形容某物的形状是长的。
本文提出了一种基于约束标签传播的领域情感词典自动构建策略。利用句法和先验泛型词典提取候选情感词,通过WordNet、句法规则和SOC-PMI三种不同的策略确定了整个未标注语料库中两个词的语义相似度。把词看作节点,相似性作为加权边来构造构词图。基于图的半监督标签传播方法,将提取到的情感词之间成对的上下文约束,作为先验知识用于标签传播过程中。应用约束传播将局部约束的效果传播到整个候选情感词集合中,最后传播的约束被合并到标签传播中,将极性分配给未标记词。
词图可以通过不同的方式从语料库、WordNet、web文档等多种资源中构建,构建词图的核心思想是确定每个词之间的相似性,作为词图的加权边。论文结合了WordNet、句法规则和SOC-PMI三种不同的策略,通过聚合多个资源的发现情感词之间的互补关系。
其中SOC-PMI(情感倾向点互信息算法)基于语料库计算两个目标词的情感倾向相似度。利用点互信息(PMI)对两个目标词的重要邻居词进行排序,并将其PMI值聚合。这样尽管两个目标词从未同时出现,SOC-PMI仍然可以通过它们共同的邻居来计算情感倾向相似度。
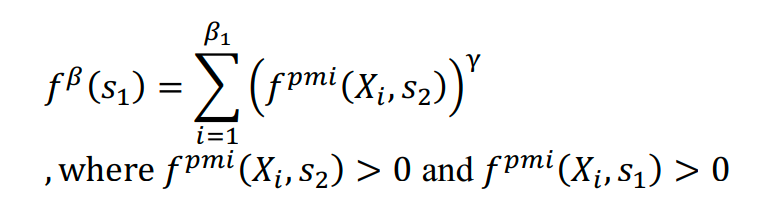
构建了词图之后,基于图的半监督传播方法在similarity matrix 上,将极性从种子词传播到未标记词。
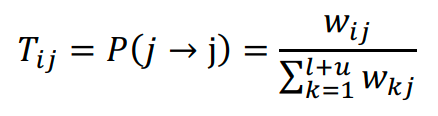
第一次迭代,只有与种子词连接的节点才能获得标签值。与种子词越相似,得到的标签值就越多。第二步,将标记数据的类矩阵固定到初始状态。从标记数据到未标记数据的迭代收敛,未标记数据在迭代过程中逐渐获得标记值。
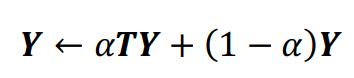
除了基于单纯词共现或者hownet,利用Topic Model发现相似情感词之间的语义关系也是一种途径。尤其在aspect sentiment这类语料中,同一类aspect的情感词分布相似,能够抓住aspect或者category的情感词分布,会使得情感词领域性更强,且能得到不同主题下的情感词的极性。
STCS的做法与上述方法有相似之处,在相似度特征方面,将基于共现的SOC-PMI换为情感关系图增加路径相似度,使得情感词的上下文特征更全面。而最终情感词的极性通过在情感关系图上对情感词进行谱聚类,得到主题特定的情感词汇。
TaSL则是直接利用LDA模型,获取主题信息,亮点在于,文档由多对主题和情感表示,每对主题和情感的是单词多项式分布。由于LDA模型一定会考虑到“主题和情感对” 与 词的分布,“主题和情感对” 与 文档的分布,因此也算继承了HSSWE的思想,使得TaSL可以充分捕捉不同主题中每个单词的情感极性,并能处理复杂的语言现象。
通过实验结果可以看出,基于主题和情感关系图构建情感词典用于下游情感分类任务,比Representation Learning(HSSWE)的表现更好。
总结
不难看出,不论是文档句子级别的情感分析,还是aspect级别情感分析,上述研究的重点都在于,如何发现真正的情感上下文以及aspect与情感词之间的语义关系,这一点在领域数据的情感分析任务上更加明显。
基于LDA的方法虽然能够发现aspect-sentiment之间的复杂关系,但这建立在一个好的分词或者实体识别模型基础上。
后续笔者还会继续关注一些其他策略的情感分析模型,如迁移学习,mixup train,半监督等。
原文标题:从基于Aspect、Target等方向全面解读医疗领域上的情感分析
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4771浏览量
100708
原文标题:从基于Aspect、Target等方向全面解读医疗领域上的情感分析
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论