 词汇知识融合可能是NLP任务的永恒话题
词汇知识融合可能是NLP任务的永恒话题
得益于BERT的加持,Encoder搭配CRF的结构在中文NER上通常都有不错的表现,而且BERT使用方便,可以迅速微调上线特定服务;在好的基准条件下,我们也能把精力放在更细节的问题中,本文并不以指标增长为目标,而是从先验知识融合与嵌套实体问题两方面讨论,希望可以从这两个方向的工作中获得解决其他问题的启发
融合词汇知识
Chinese NER Using Lattice LSTM
融合词汇知识的方法可能适用于NLP问题的每个子方向,也是近几年中文NER问题的大方向之一;因为中文分词的限制,加之有BERT的加成,如今基本默认基于字符比基于分词效果更好,这种情况下,引入词汇知识对模型学习实体边界和提升性能都有帮助,Lattice LSTM是这一方向的先行者
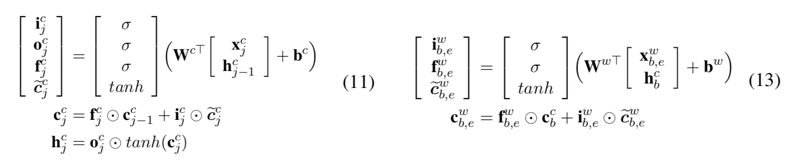
相比于char和word级的RNN,Lattice LSTM加入了针对词汇的cell,用以融合词汇信息;计算上比char-cell少一个output gate,此外完全一致,可以理解为在传统LSTM链路中插入了一组LSTMCell,具体可以对照原文公式10-15理解(下图公式11为LSTMCell,公式13为WordLSTMCell):
FLAT: Chinese NER Using Flat-Lattice Transformer
Lattice LSTM验证了融合词汇信息提升中文NER任务的可行性,就是有点慢,每句话要加入的词汇不一样,无法直接batch并行,此外Lattice LSTM没法套BERT,现成的BERT不能用太不甘心;于是就有了同时弥补这两点的FLAT,并且其融合词汇的实现方式也简单的多:如图,FLAT融合词汇的方式就是拼接,词汇直接拼在输入里,此外只需改造Postion Embedding,将原始的位置编码改为起止位置编码
不过Postion Embedding的改造还不止于此,为了让模型学习到词汇span的交互信息,这里还引入了相对位置编码:如图,长度为N的输入会产生4个N * N的相对位置矩阵,分别由:head-head,head-tail,tail-head,tail-tail产生
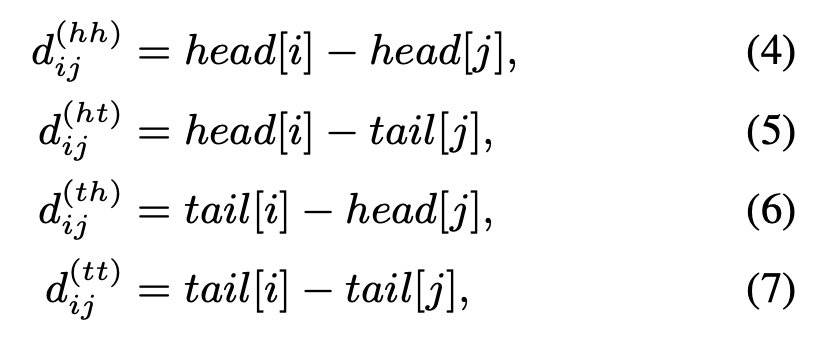
综上,基于Transformer的FLAT可batch并行,速度自然优于Lattice LSTM,同时又可以套用BERT,在常用中文NER数据集上都有非常出色的表现;FLAT的显存占用比较高,但用显存换来的推理时间减少肯定是值得的
Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network
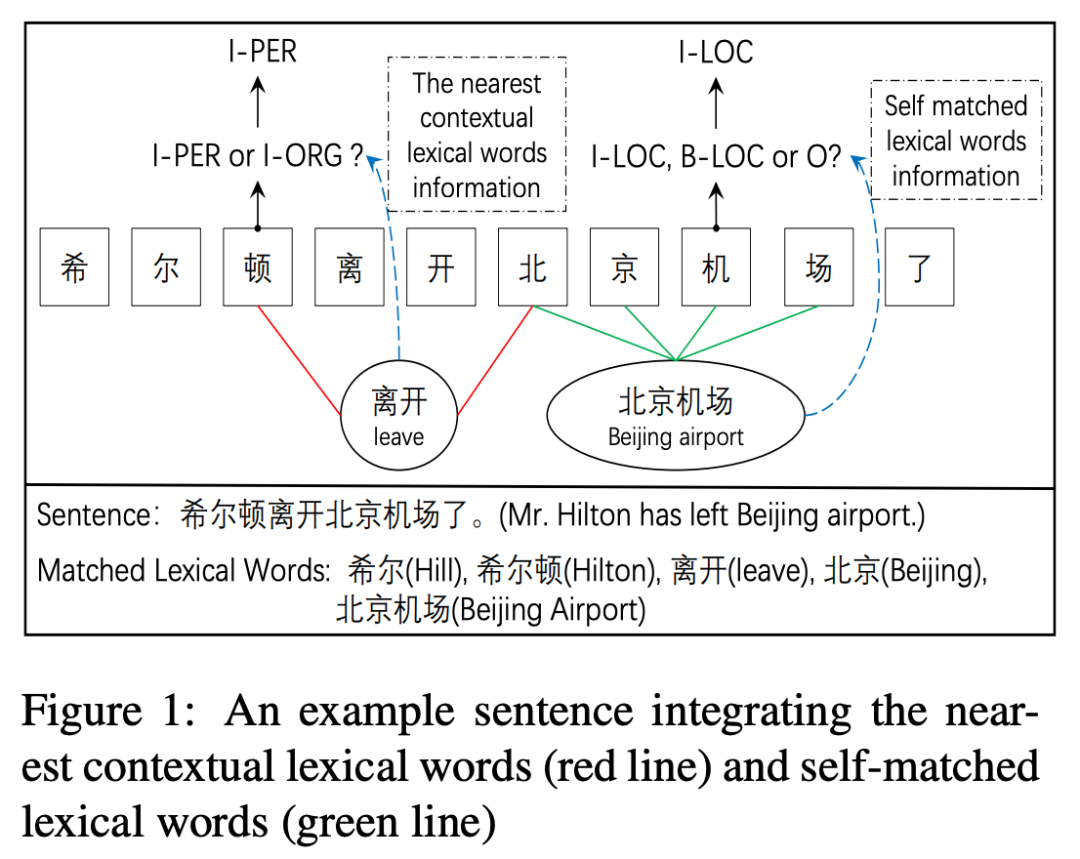
通过词汇增强模型识别边界的能力很重要,然而Lattice LSTM在这方面还存在信息损失,受限于构造方式,词汇表示只能加给最后一个字,这样有什么问题呢?以本文CGN中提到的“北京机场”为例,想要成功标出“北京机场”而非“北京”,需要模型将“机”识别为“I-LOC”,而非“O”或“B-LOC”,然而Lattice LSTM中的词汇并不影响“机”的encoding;此外,Lattice LSTM的融合方式说明词汇只对实体本身有帮助,然而正确识别实体可能也需要临近词汇的帮助,例如下图的“离开”表明“希尔顿”是人名而非酒店
复杂的字词关系无法通过RNN结构表示,选择Graph更为灵活,本文通过融合三种图结构学习复杂关系,利用GAN提取特征,获得倍数于Lattice LSTM的速度提升
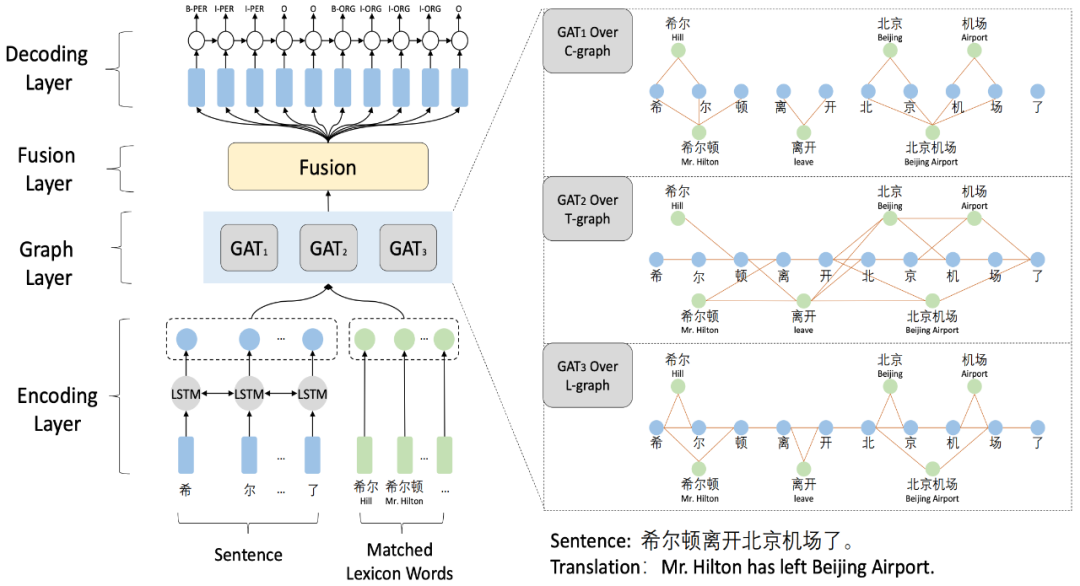
如图所示,在LSTM编码输入文本并传入词汇表示后,模型会经过三种策略的构图层:
Word-Character Containing graph(C-graph):负责学习自匹配特征和词汇边界信息
Word-Character Transition graph(T-graph):负责构造字词相互之间的上下文邻接关系
Word-Character Lattice graph(L-graph):负责捕捉自匹配特征和隐含的词汇邻接关系
图表示完成后,通过Fusion层的线性结构融合特征,再传给CRF做标签decoding即可;虽然流程上比FLAT复杂一些,但一方面其非batch并行版的速度更快(不知道算不算建图的时间),另外文中提供的各种词汇融合思路也值得学习借鉴,从词汇边界和覆盖本身考虑,上下文语义贡献的作用,已经图结构带来的额外特征或许可以作为特定任务的预训练过程拆解使用
嵌套实体问题
嵌套实体在标注应用场景下很少被顾及,一方面传统序列标注模型也只能选择一个,另外标注数据时我们就只根据语义选择其中一个;但嵌套实体本身是存在的,比如医疗场景下的疾病词常由身体部位和其他词构成,即便不作为NER任务本身看待,让模型能学习标识嵌套实体,对实际场景中的其他任务也大有益处
Pyramid: A Layered Model for Nested Named Entity Recognition
通过多层结构抽取嵌套实体是一种容易理解的模型,2007年就有工作通过堆叠传统NER层处理嵌套问题,不过之前的工作都无法处理嵌套实体重叠的情况,并且往往容易在错误的层级生成嵌套实体(即实体本身存在,但不该在当前层识别到,否则会影响后续层的识别,从而破坏整体模型效果);本文针对这两个问题提出的金字塔结构
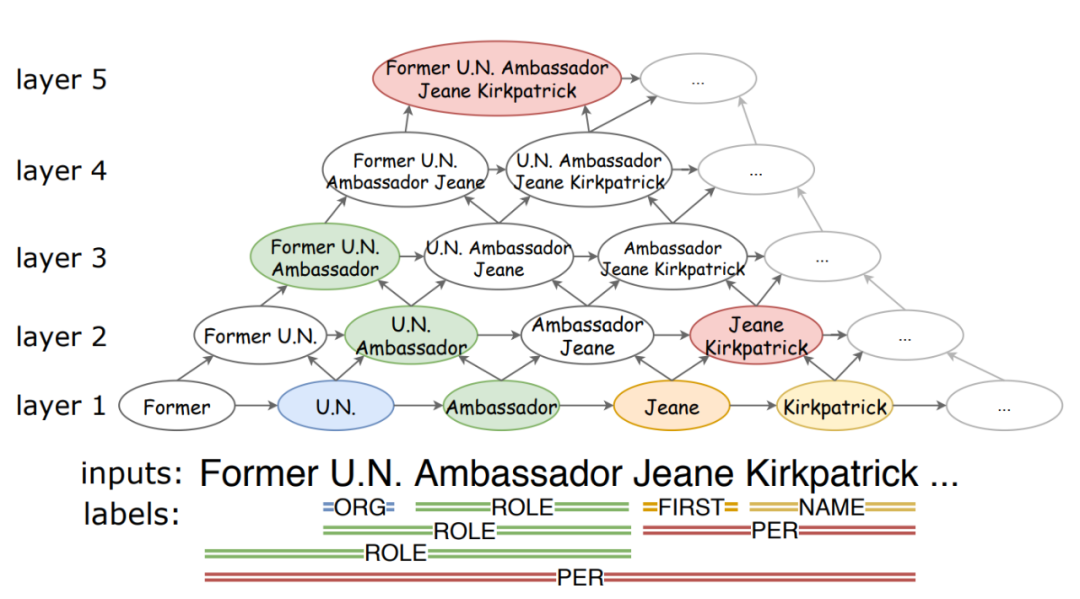
金字塔结构的思想如图所示,最底层为最小的文本单元,每一层负责长度为L的实体的识别,通过CNN向上聚合,模型不会遗漏重叠实体span,同时由于L的限制,该结构不会在错误的层生成不对应的实体;作者还认为高层span的信息对底层也有帮助,所以还设计了逆向金字塔结构,具体实现如下
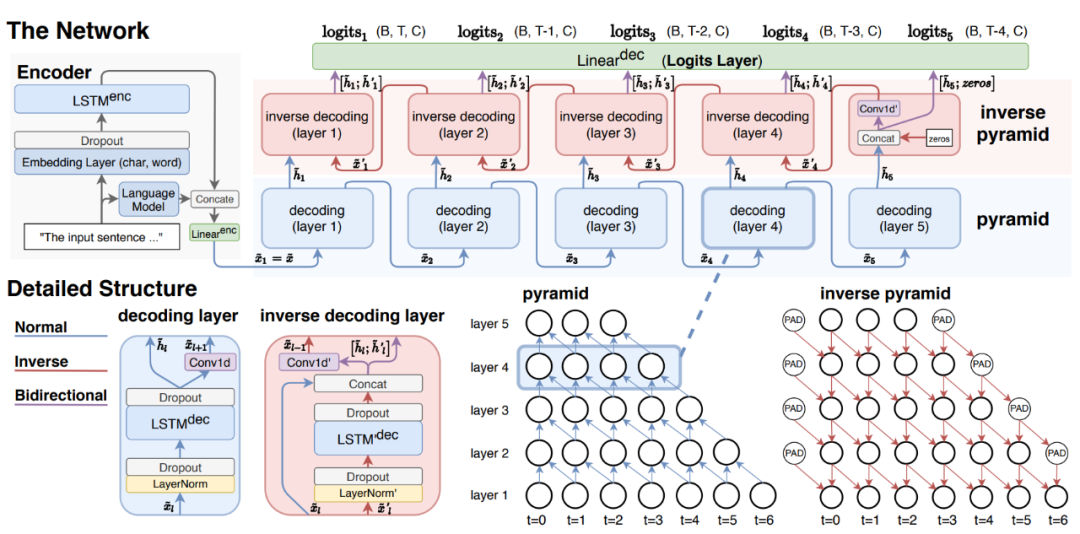
在经过LSTM编码后,自底向上的Decoding层为每一层预测对应标签,因为按长度区分,所以理论上只需要预测“B-”,但这样模型就必须堆叠N层才能覆盖全部span,不然就无法预测长度超过l的实体,所以作者设计了补救措施,在最高层同时预测“B-”和“I-”

Pyramid表现了处理嵌套问题的重要方向,即构造和编码潜在实体span,下面的工作也都遵循这一点设计实现各种模型结构
A Unified MRC Framework for Named Entity Recognition
本文彻底放弃了序列标注模型,用阅读理解的方法处理嵌套实体,即预测起止位置和实体分类;由起止位置标识的实体当然允许覆盖,自然就解决了嵌套问题;熟悉MRC的同学很快就会发现,通常的MRC只有一个答案span,然而一句话中可能存在多个实体span,怎么表示多个实体?因此本文修改了MRC的结构,首先起止位置预测:
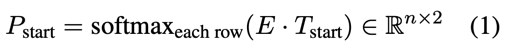
预测P_end也是同样的结构,这里类似序列标注,表示每个char为起止位置的概率分布,这样就产生了a个起始位置和b个终止位置,理论上存在 a * b 个实体span;而后还需要一个模块计算a * b个匹配中有多少个真的是实体,即:
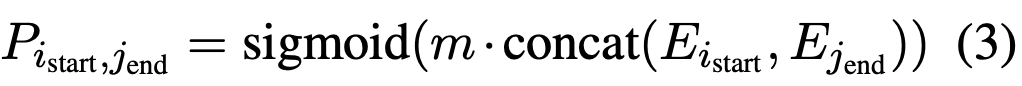
到此便解决了预测起止位置识别实体的问题,下面需要对每个实体span分类;通常的做法都是设计分类器,区别仅在于传入分类器的表示,本文的分类则十分新颖,也十分MRC,即:给输入文本拼接一个指向特定实体的问题,在这个问题下找出的span都属于这一类
本文思路新颖,实现简单且可套用BERT等不同Encoder,在传统NER和Nested-NER数据集上都有sota或接近的水准;唯一的遗憾是不适合多实体类别的应用服务,因为针对K个类别都要单独设计问题,所以相当于在预测时把每个问题都问一遍,时间开销或显存开销扩大K倍是无法避免的
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
本文是实体关系联合抽取的工作,虽然思路上基本遵循实体识别-》关系分类的流程,但实现上于寻常工作有巨大差别;虽然并不是中文数据集上的工作,但在嵌套实体的处理思路上,本文与寻常工作也有巨大差别,很有借鉴意义;这里首先介绍对普通实体,头实体,尾实体的标识方法:
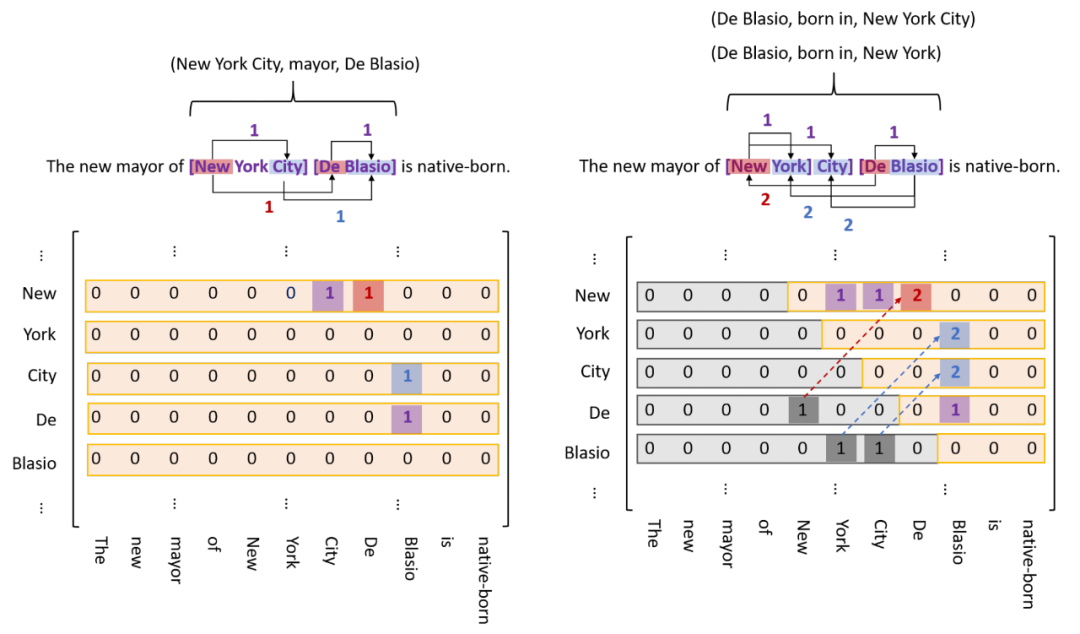
如图所示,既然存在嵌套实体,那么不妨假设任意两个char都可能构成实体,这样就形成左图的N * N矩阵,模型通过二分类即可标识出存在的实体;不过文本是单向的,所以实体的start一定在end前面,这样就有了右图,即矩阵包括主对角线的下三角矩阵可以忽略,这样矩阵flat后的长度就从N * N减少到 (N + 1) * N / 2;因为是实体关系联合抽取,所以分别用三种颜色标识,紫色标记普通实体,红色标记同一关系下的头实体,蓝色标记尾实体,代码实现上对应三种分类器;另外由于一对实体可能存在多种关系,所以需要为每种关系准备一个分类器,如下图
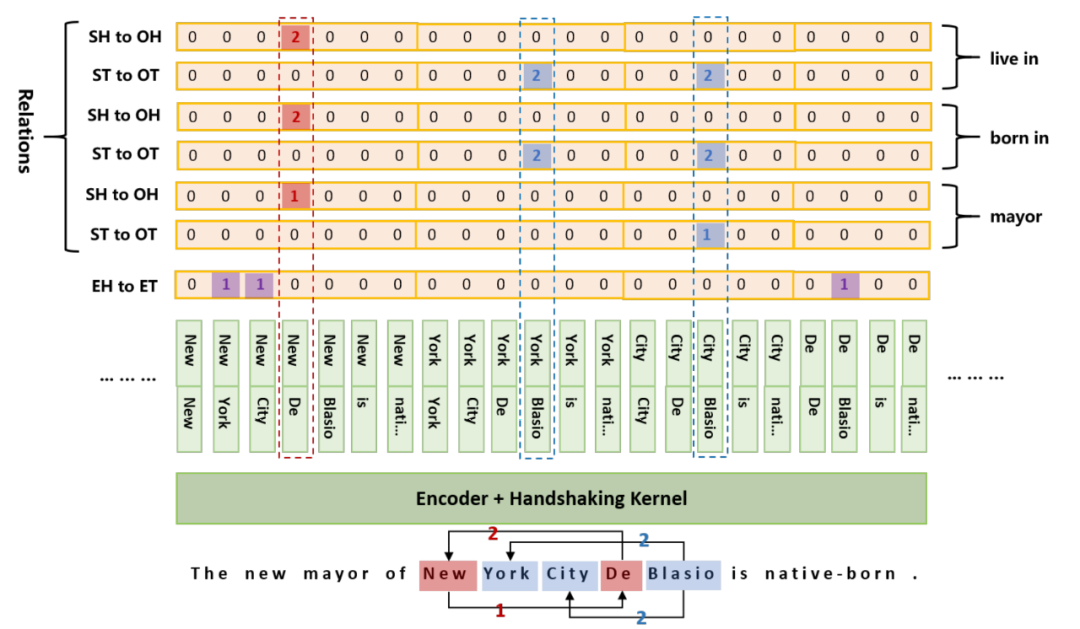
笔者认为TPlinker处理嵌套问题的思路与MRC颇有几分相似,矩阵中每个元素都是一个span,既然存在嵌套,我们就不得不假设任意两个char都可能构成实体;此外,虽然最终要在 (N + 1) * N / 2长的序列上预测实体,但显存占用之类的问题并没有那么明显,因为这个平方级的序列是在Encoder输出后拼成的,我们还可以通过设置一些约束进一步减少长度;不过要注意,这个长序列的预测可能非常稀疏(一句话里的实体很少,按长度平方后0占比更大)
Span-based Joint Entity and Relation Extraction with Transformer Pre-training
本文同样是实体关系联合抽取,处理嵌套问题的思路与TPlinker类似,穷举出全部的潜在实体,然后用分类器识别;如下图所示
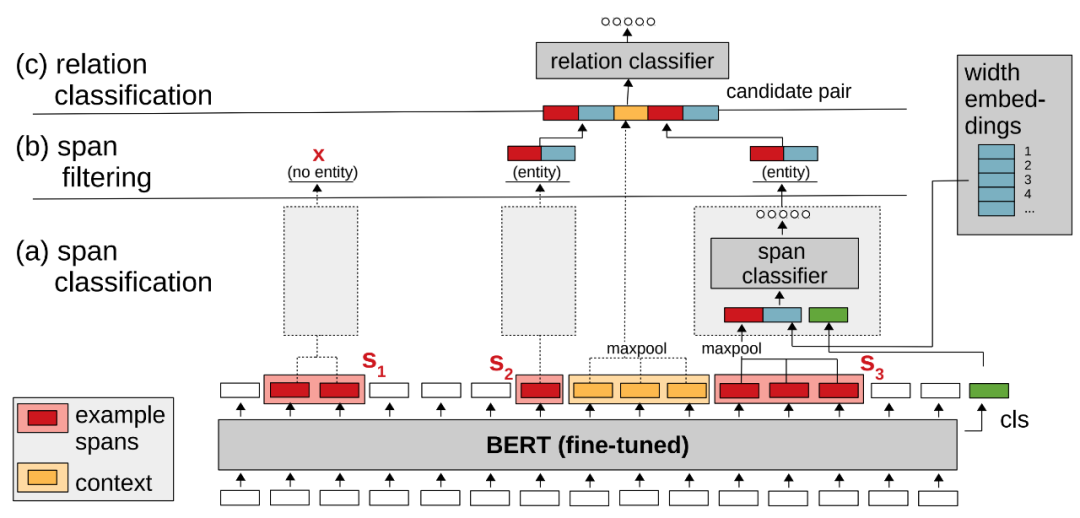
与TPlinker类似,在输入文本经过BERT后,sequence_output被用来构造潜在实体,理论上所有的ngram都是潜在实体,所以这里需要拼出全部ngram再通过span分类器识别实体,过滤非实体;文中提到一个小trick,给span classifier传入的向量表示除了sequence_output[span]和[CLS]外,还包含一个width embeddings向量,因为某些长度的span不大可能的实体,希望模型可以学到这一点;那么对于TPlinker和spERT,我们也都可以通过长度约束减少span的个数,手工降低模型的计算开销;最后关系分类的做法很直观,融合各路语义向量表示,通过sigmoid生成对应K个关系的1维向量,每个维度通过阈值判定是否存在该类关系
总的来说,Pyramid、MRC、TPLinker、spERT处理嵌套问题的出发点基本一致,从传统的token级标注转变为对潜在实体span的标注;实现上各有特点,Pyramid设计了分层结构,TPlinker的矩阵构造非常灵性,不过平方级长度的序列太过稀疏;spERT虽然理论上也有平方级数量的span,但真实训练可以通过负采样降低训练压力;MRC做分类的想法很是独特,不过对于多类别场景可能计算压力过大,或许可以分离entity识别和分类,避免多次BERT计算的开销
总结
词汇知识融合可能是NLP任务的永恒话题,利用词汇知识增强NER模型的想法也非常自然,Lattice LSTM及其后续工作展开了一个很好的方向,引入词汇关联结构提升模型也许在其他任务上也有很大收益;嵌套实体问题在当前的实际应用场景也许重视度还不够,但问题本身切实存在,这方面的工作往往在潜在实体span的识别上有独特的创新点,通过拆解和重组传统的序列分类和标注模块,引入MRC机制等思路,为我们解决复杂NLP问题带来新的思路
原文标题:中文NER碎碎念—聊聊词汇增强与实体嵌套
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
深度学习
+关注
关注
73文章
5504浏览量
121221 -
nlp
+关注
关注
1文章
489浏览量
22049
原文标题:中文NER碎碎念—聊聊词汇增强与实体嵌套
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论