 含有“Chiplet”的尖端封装技术能否牵引摩尔定律继续前进
含有“Chiplet”的尖端封装技术能否牵引摩尔定律继续前进
编者按过去几年,因为厂商的推动,Chiplet这个概念已经深入民心。在本文中,我们将首先讨论什么是“Chiplet”、为什么需要“Chiplet”?而且会参考上文提到的西尾先生的演讲内容(已经得到西尾先生的许可)。此外,本文还会介绍TSMC、三星电子、英特尔在此次的IEDM上发布了何种尖端封装技术。最后,展望未来,论述含有“Chiplet”的尖端封装技术能否牵引摩尔定律继续前进。
什么是“Chiplet”
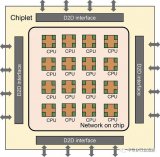
在此次的IEDM的短课程(Short Cause)上,三星电子的SE-Ho You先生做了题目为“From Package-Level to Wafer-Level Integration”的演讲,且展示了“Chiplet”的未来形象。(如下图1)
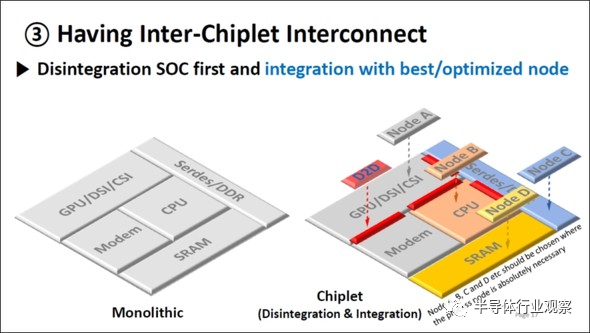
图1:“Chiplet”是什么?出自:SE-Ho You (Samsung), “From Package-Level to Wafer-Level Integration”, IEDM2020, SC1。
之前,用一个科技节点(Technology Node)可以制造出含CPU、GPU、调制解调器、SRAM、Serdes/DDR等功能的SoC(System on Chip)。
按照功能的不同,分别利用最合适的技术节点来制造。如图1的右侧所示,用Node A生产GPU、用Node B生产CPU、用Node C生产Serdes/DDR、用Node C生产SRAM,即分别在不同的晶圆上生产,集合(Integration)以上这些功能,并汇集在一颗芯片上。
即将以上这些功能集合在一颗芯片上。
如上所述,通过连接由单独的晶圆制造的芯片,形成具有某一功能的SoC技术就是“Chiplet”的概念。
那么,为什么“Chiplet”越来越重要呢?其原因在于尖端半导体需要处理的数据量成指数级增长。
下图2出自2020年8月13日在线举行的“Intel Architecture Day 2020”的资料,显示了人类创造的数据量的推移。从图2可以看出,2020年的数据量超过50ZB(Zettabyte,十万亿亿字节,1021),预计2025年将会扩大至175ZB。
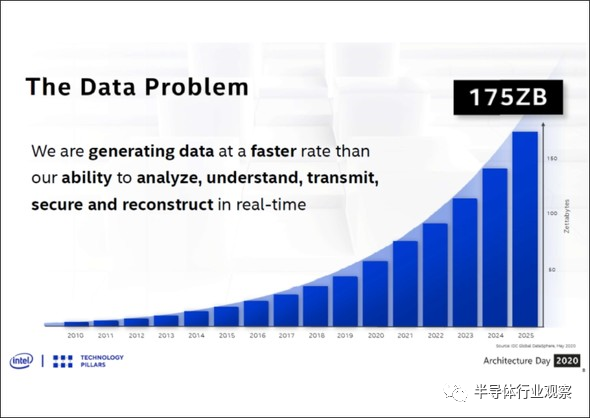
图2:人类创造的数据量。(图片出自:Intel Architecture Day 2020的资料)
为了处理这样庞大的数据量,所以人工智能(AI)半导体市场急剧扩大(如下图3)。据预测,2020年的市场规模将超过100亿美元(约人民币646.48亿元),2027年将会达到833亿美元(约人民币5,381.18亿元)。
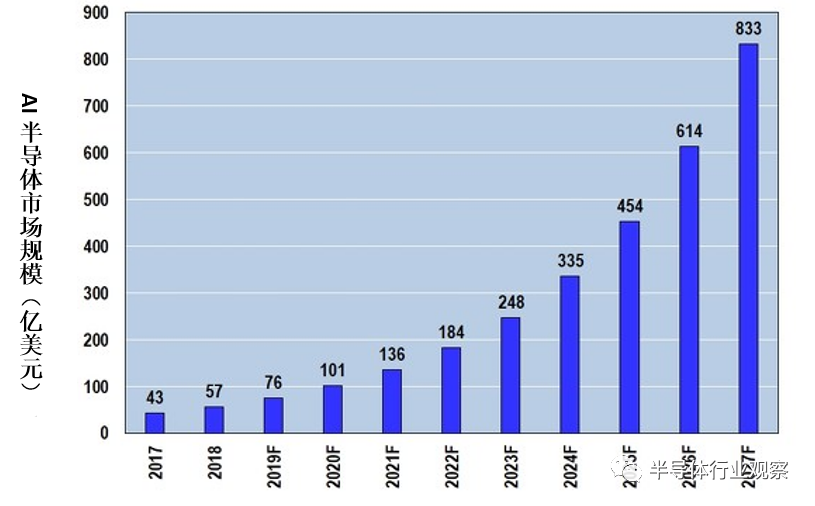
图3:AI半导体市场规模推移(2019年以后为预测值)。(图片出自:Artificial Intelligence Chip Market)
AI半导体的用途主要有以下:智能手机、平板电脑、音响、可穿戴设备、企业边缘(Enterprise Edge)等(如下图4)。AI的最大用途方向在于智能手机,据预测,2020年的规模为5亿美元(约人民币32.3亿元),2024年翻至2020年的两倍,达到10亿美元(约人民币64.6亿元)。另一方面,企业边缘的市场规模虽然不及智能手机,但2024年的市场规模为2020年(市场规模为0.5亿美元,约人民币3.23亿元)的5倍,增至2.5亿美元(约人民币16.15亿元)。
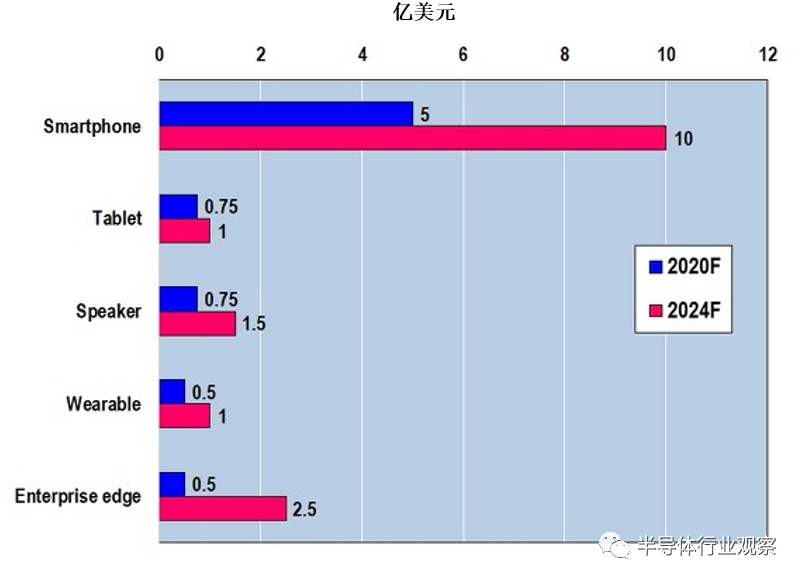
图4:各种方向的AI半导体市场(预测值)。(图片出自:MarketsandMarkets)
如今的4G智能手机已经搭载了NPU(Neural Processing Unit)这一AI应用处理器(AP,Application Processor),未来,随着5G手机的普及,占据NPU性能、AP的空间会越来越大。因此,智能手机方向的AI市场也会出现增长。
此外,随着5G的普及,云计算市场就像金字塔一样,AI市场定会迅速扩大。即,在各种5G通信设备附近都设有搭载了AI的边缘计算(Edge Computing,此处包含“企业边缘”)进行高速运算处理,其上面一层为“雾计算(Fog Computing)”、再上一层为“云计算(Cloud Computing)”。
AI:从GPU到ASIC
如上所述,由于大数据规模的扩大,带动处理大数据的AI半导体市场增长,到底什么样的AI半导体会成为主流呢---这是经常变化的(下图5)。在2017年,NVIDIA的GPU席卷全球,市场份额达到97%,据预测,到2025年GPU市占率会下滑至40%甚至更低,而ASIC的市占率会达到50%。
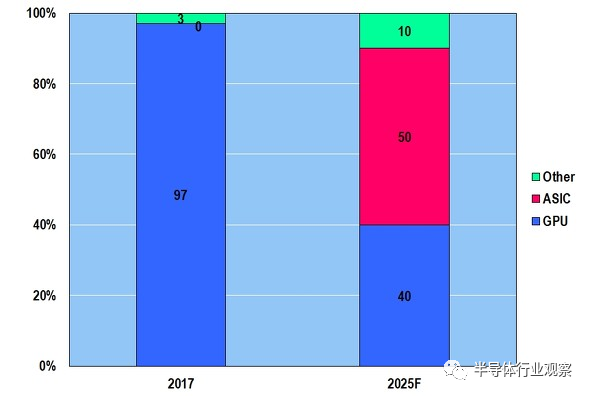
图5:AI半导体种类的变化(预测)。(图片出自:McKinsey)
换句话说,由于普通GPU(GPGPU:General-purpose computing on graphics processing units)的处理性能不足,因此出现了诸多专用AI半导体(如智能手机专用、无人驾驶汽车专用、边缘计算机专用),且占一半以上份额。
但是,即使是ASIC AI,要处理逐年不断增长的大数据也是十分困难的。据预测,仅靠提高芯片本身的性能已经无法同时满足AI半导体的高速处理、节能、成本优势等目标。
大数据和AI半导体的处理能力
在2020年9月17日-18日召开的The Second AI HW Summit上,英特尔指出,AI半导体处理的数据量每3.5个月扩大两倍、每年扩大约10倍、每两年扩大64-100倍。(如下图6)
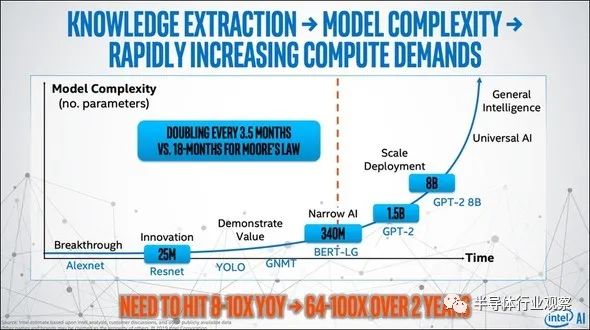
图6:AI处理的数据量每3.5个月扩大两倍,每两年扩大64-100倍。(图片出自:MOOR Insights and Strategy, AI Hardware: Harder Than It Looks)
作为ASIC(或者SoC)的AI半导体能否处理以上这些成指数级增长的数据量?下图7是2018年版的IRDS(International Roadmap for Devices and systems)登载的SoC的CPU、GPU核数、CPU吐出量(处理能力)。
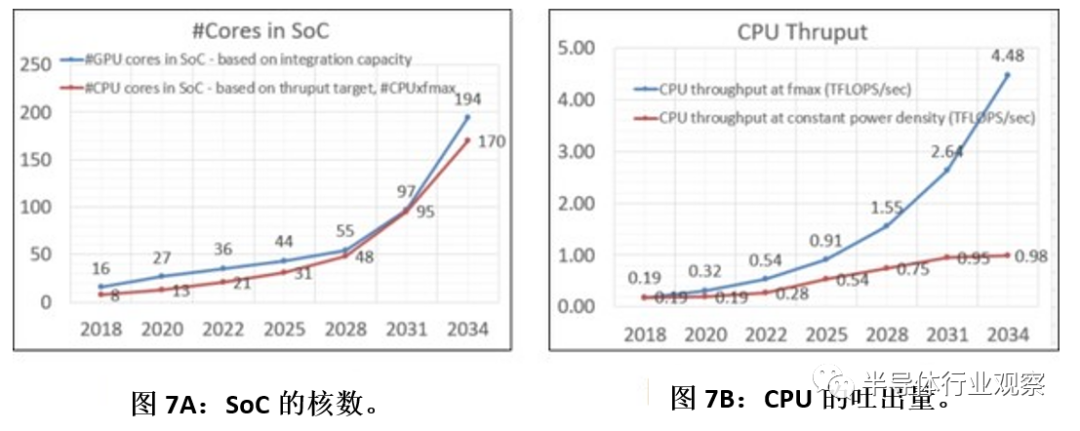
图7:SoC的核数、CPU的吐出量。(图片出自:IRDS2018)
2020年SoC中的CPU核数为13,GPU为27个,到2031年,CPU增至95个(7.3倍)、GPU增至97个(3.6倍)。其中,CPU的吐出量在2020年为0.32 TFLOPS/sec、2031年将会增为2.64 TFLOPS/sec,增长了8.25倍。但是,这是不考虑因发热问题而产生的速度下降问题,如果因发热而导致速度下降,2031年的吐出量仅为0.95 TFLOPS/sec,增长约3倍。
所谓的“TFLOPS/sec”指的是“tera floating-point operations per second”的缩略,是表示计算机处理能力的单位,tera为1万亿,FLOPS为每秒浮点计算次数。因此,1 TFLOPS为浮点每秒计算一万亿次。
那么,从2020年到2031年,SoC中的CPU核数将增长7.3倍,增至95个,如果不考虑因发热引起的速度低下问题,CPU的预测速度将提高8.25倍,提高至2.64 TFLOPS/sec。因此,预计在2031年登场的SoC AI半导体与2020年相比,其计算能力将会提高60倍=7.3*8.25。
但是,AI半导体处理的数据量如上图6英特尔所展示的一样,在两年内增长64-100倍,即使是最小值64倍,在2031年将会达到10亿倍(2020年的64的五次方),仅靠增加核数、提高各核的吐出量,处理能力还是不足。
随着核数的增加、SoC成本也增加
与持续增长的数据量形成对比,SoC AI半导体的处理能力完全不足。但是,为了提高处理能力,只能增加SoC的核数、持续扩大各核的吐出量。因此需要进一步提高微缩化(Scaling)。但是,随之而来的高昂的晶圆成本又是一大问题。
下图8是2020年VLSI座谈会上的演讲内容,AMD的Samuel Naffziger先生发表了名为“Chiplet Meets The Real World -- Benefits and Limits of Chiplet Designs”的演讲,同时展示了微缩化与芯片成本的关系。
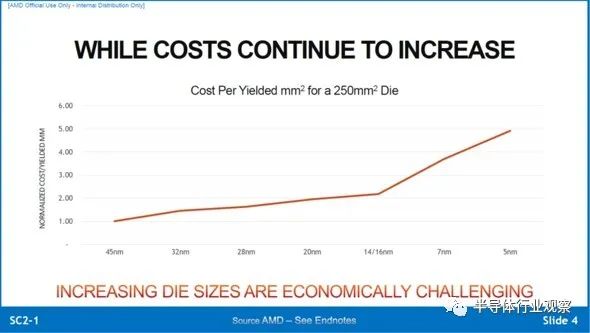
图8:微缩化与芯片成本的增长。(图片出自:Samuel Naffziger (AMD), “Chiplet Meets The Real World -- Benefits and Limits of Chiplet Designs ”, VLSI2020, Short Course 2-1.)
如果把利用45纳米节点生产的芯片成本看做“1”,随着微缩化发展,芯片成本也增长,5纳米节点下的成本为45纳米节点的五倍。从图8可以看出,14纳米/16纳米节点以后,图表呈现急剧增长趋势,此处应该是采用了EUV(极紫外光刻)技术。
微缩化照此发展下去,芯片成本势必会增长,即便如此,为了提高AI半导体的处理能力,TSMC、三星电子都在发展微缩化。此外,虽然必须要增加核数,但其成本的增长会远远超过微缩化花费的成本。然而,能解决以上问题的方案就是“Chiplet”。
Chiplet可以控制因核数增加带来的高昂成本
下图9是用于AMD服务器的处理器“EPYC”。“EPYC”是拥有32核的CPU,如果用一颗芯片来做的话,就会像图9左边一样,芯片面积达到777mm2。按照Chiplet的方法来处理这颗大型芯片的话,就会像图9右侧一样生成四份,再连接。分成四份后各个芯片的面积为213mm2,213*4=852mm2,比分割之前更大,即使把多出的面积去掉也比分割前更有优势。(下图10进行说明)
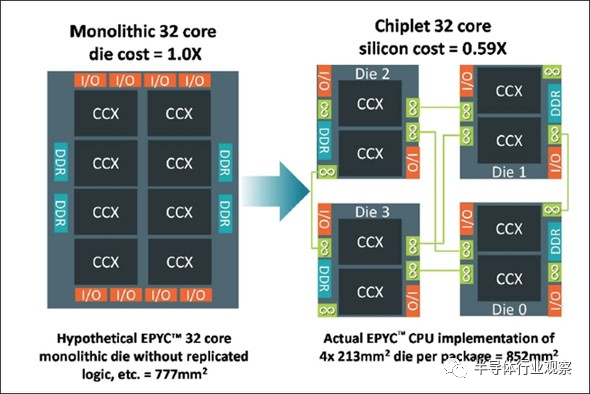
图9:将32核的处理器分为四份的AMD的EPYC。(图片出自:Greg Yeric, arm community, “Three Dimensions in 3DIC - Part I”, April 2, 2018)
下图10的横轴为芯片面积,纵轴为良率,蓝色线条可以看做是量产初期时的良率(缺陷密度为1个/cm2),另一方面,橙色线条可以看做是改善了量产工艺后稳定生产时的良率(缺陷密度为0.22个/cm2)。
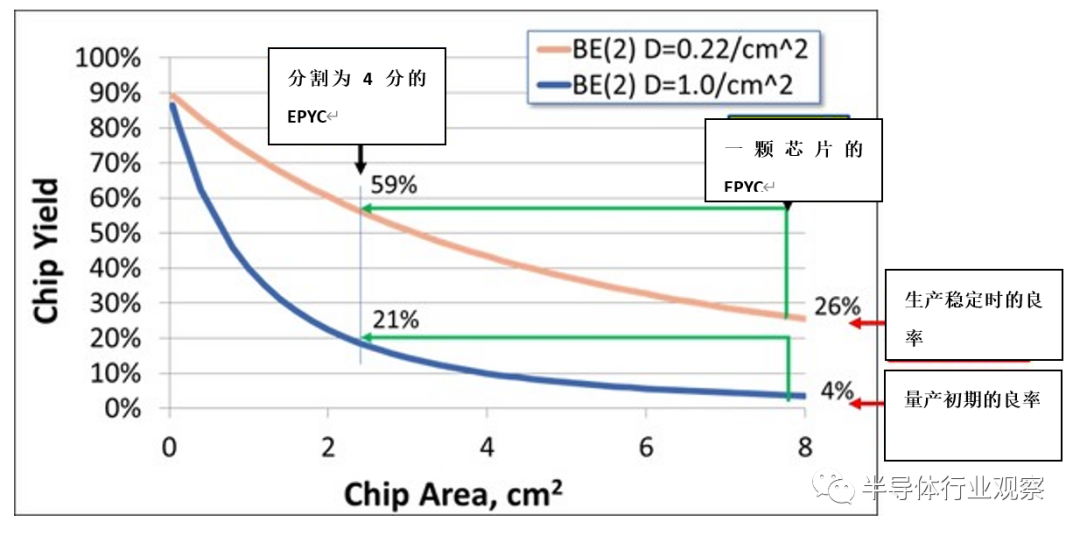
图10:芯片面积和良率的关系。(图片出自:Greg Yeric, arm community, “Three Dimensions in 3DIC - Part I”, April 2, 2018)
那么,用一颗芯片生产EPYC的情况下,量产初期的良率仅有4%,即使优化工艺流程,良率也仅为26%。
而被分为四份的EPYC(213mm2)在量产初期的良率为21%,优化工艺流程、生产稳定时的良率达到了59%,即,分割后的芯片的量产初期良率是分割前的5.3倍,稳定时的良率是分割前的2.3倍。
在这种条件下,1颗晶圆可以做出多少个EPYC呢,在下图11中进行说明。用一颗面积为777mm2的芯片来生产EPYC的话,一颗晶圆可生产出约69颗芯片,由于生产稳定时的良率为26%,因此实际可获得的芯片数量为69*26%=17颗。
另一方面,分成四份后的芯片面积为213mm2,那么一颗晶圆可产出273个芯片,假如生产稳定时的良率为59%,可获得的芯片数量为273*59%=161个。由于四个组成一个芯片,因此实际可做出161/4=40个EPYC。
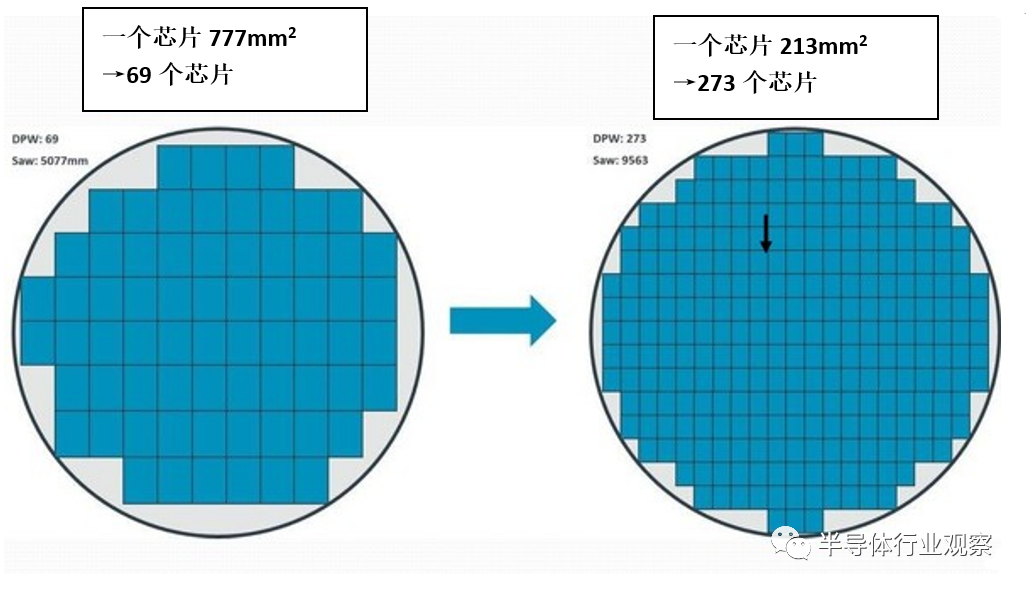
图11:芯片面积与从晶圆上获得的数量。(图片出自:Greg Yeric, arm community, “Three Dimensions in 3DIC - Part I”, April 2, 2018)
综上所述,用一个芯片(777mm2)来做的话,实际获得的EPYC数量为17个,而分割为四份的话,可以多做出2.4倍的EPYC。反过来说,通过四分芯片,EPYC的成本也会降低1/2.4。
通过分割芯片来提高良率,结果降低了单颗芯片的成本。这是Chiplet的优势之一,不过Chiplet的优势不限于以上。
像乐高积木一样的形成SoC
下图12是AMD的第一代、第二代EPYC(用于服务器的处理器)的比较图。第一代EPYC采用的是由4个14纳米的芯片组成;在第二代中,橙色为用7纳米制作的“处理器8芯”,蓝色为用14纳米制作的Input/Output(IO)芯片,将以上这些安装在Interposer上,就制成了用于EPYC的处理器。
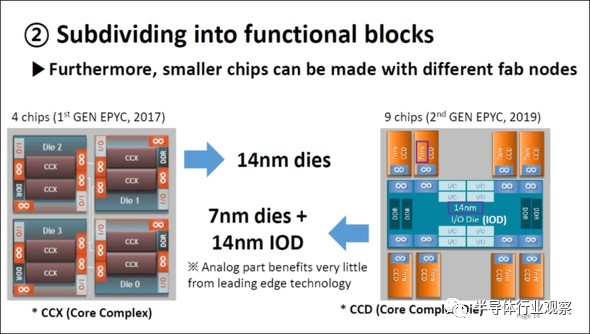
图12:第一代EPYC和第二代EPYC的区别。(图片出自:SE-Ho You (Samsung), “From Package-Level to Wafer-Level Integration”, IEDM2020, SC1)
要求最高的处理器采用了2019年当时最先进的7纳米工艺,而I/O使用的不是那么尖端的14纳米,即不同的芯片选择使用不同的合适工艺节点。
而三星的厉害“绝技”在下图1,不使用Chiplet的情况下,如图1左侧所示,整个芯片必须由同一个技术节点制造。就利害而言,芯片面积越大,良率越低,那么单颗芯片的成本也就越高(如上文所述)。除此之外,为了在同一个Mask上配置CPU、GPU、调制解调器、SRAM、Serdes/DDR,需要将精密的图案与粗略的图案混合,使制造工艺更复杂。
另一方面,在图1的右侧,各个产品都是按照其自身的功能来选择合适的节点生产的,如GPU采用A节点、CPU采用B节点、SRAM采用C节点、I/O采用D节点,然后将它们安装在一个Interposer 上。各种半导体模组就像乐高积木一样堆叠在一起。
Chiplet拥有以上优势。通过有序地配置CPU、GPU、DRAM等产品,从而进一步提高SoC AI的处理能力。
用HBM(High Bandwidth Memory)实现高速化
下图13是搭载了GDDR5规格DRAM的传统SoC和搭载了纵向压层的HBM(High Bandwidth Memory,用TSV连接GDDR5)的SoC的比较图。通过利用HBM,纵向缩短了1.6倍、横向缩短了2倍、面积缩短了3倍。即,DRAM和SoC的合计占用面积为1/3。可以说这也是是灵活运用Chiplet的一个事例。
图13:搭载了HBM(High Bandwidth Memory)的SoC。(图片出自:Greg Yeric, arm community, “Three Dimensions in 3DIC - Part I”, April 2, 2018)
下图14是搭载了HBM(High Bandwidth Memory)的SoC的断面图,用TSV连接的DRAM经由逻辑芯片和Interposer,与SoC相连接。在需要高速处理的SoC的旁边配有HBM,因此诞生了可以迅速传输数据的存储半导体。
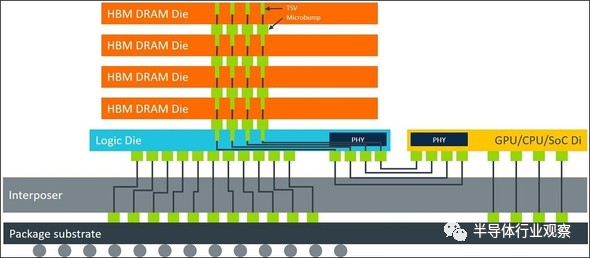
图14:配置有HBM(High Bandwidth Memory)的SoC的断面图。(图片出自:Greg Yeric, arm community, “Three Dimensions in 3DIC - Part I”, April 2, 2018)
下图15是GDDR5和HBM 的Bus Width、Clock Speed、Bandwidth、动作Voltage的比较图。GDDR5的Bus Width为32比特,HBM是其32倍,为1,024比特。结果,GDDR5的时钟频率(Clock Rate)为1,750MHz,HBM为500MHz,GDDR5的一颗芯片的Bandwidth为25GB/s,HBM的一个Block为100GB/s,是前者的4倍。
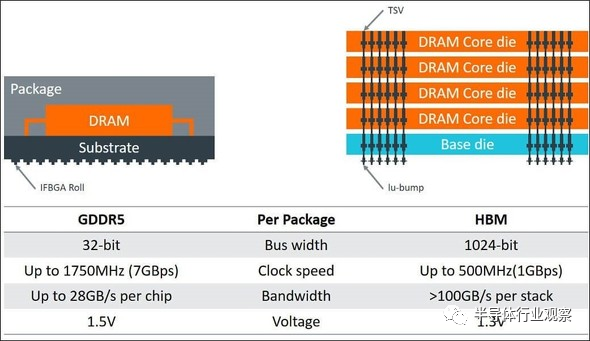
图15:HBM(High Bandwidth Memory)的带宽大小。(图片出自:Greg Yeric, arm community, “Three Dimensions in 3DIC - Part I”, April 2, 2018)
总之,一个GDDR5就相当于在单行道上高速行驶的卡车,因此可传输的数据量是有限的,HBM的情况下,相当于四辆行驶在四车道上的卡车,一次传输的数据量也是前者的四倍。
如果运用HBM可以较好地使用Chiplet的话,那么SoC AI也可以高速运行。终于解释清楚了什么是Chiplet以及其存储半导体。那么,在IEDM上,英特尔、三星、TSMC分别发布了什么呢?
在IEDM上,英特尔和三星发布了尖端封装技术
英特尔的Ravi Mahajan先生在“Advanced Packaging Technologies for Heterogeneous Integration(HI)”上,对尖端封装进行了说明(如下图16)。就Embedded Multi-Die Interconnect Bridge(EMIB)而言,分割处理器核(Processor Core)并生产以后,经由Interposer,再集成(Integration)、制成芯片。此外,就Foveros而言,经由TSV压层不同的芯片,制成一颗芯片。最后获得由EMIB和Foveros组合的Co-EMIB。
图16:英特尔的3D封装(EMIB、Foveros、Co-EMIB)。(图片出自:Ravi Mahajan (Intel), “Advanced Packaging Technologies for Heterogeneous Integration (HI)”, IEDM2020, Tutorial2.)
下图17是三星电子的SE-Ho You先生在From Package-Level to Wafer-Level Integration上发布的资料。X-Cube指的是用TSV压层不同的芯片,可以说相当于英特尔的Foveros。此外,经由Interposer连接了不同的芯片的I-Cube与英特尔的EMIB类似。此外,组合了X-Cube和I-Cube的X/I-Cube与英特尔的Co-EMIB非常类似。
笔者虽然不知道是三星电子还是英特尔率先研发了以上成果,但可以断言二者是非常类似的。
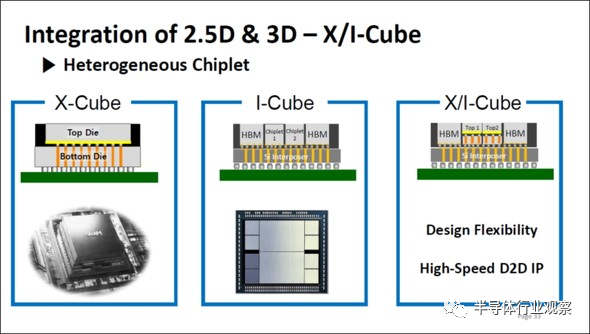
图17:三星的3D封装(X-Cube、I-Cube、X/I-Cube)。(图片出自:SE-Ho You (Samsung), “From Package-Level to Wafer-Level Integration”, IEDM2020, SC1)
TSMC在IEDM上的发布内容
TSMC比三星、英特尔更早地采用了Chiplet的封装方法。TSMC的KC Yee先生在IEDM的“Advanced 3D System Integration Technologies”上回顾了过去十年间Chiplet的历史。(下图18)
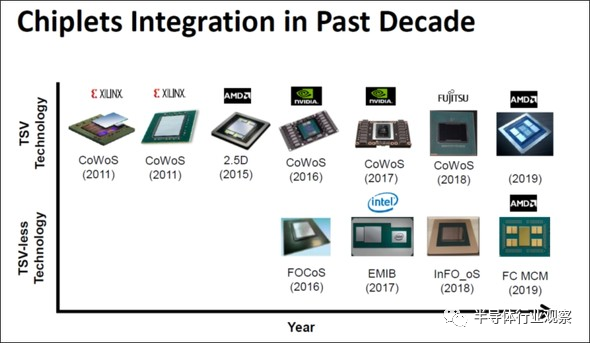
图18:TSMC在IEDM上公布的Chiplet。(图片出自:KC Yee (TSMC), “Advanced 3D System Integration Technologies”, IEDM2020, SC1)
图18的上半部分是被称为CoWoS(Chip-on-Wafer-on-Substrate)的Chiplet技术,2011年被应用于Xilinx的FPGA。后来,又被应用于NVIDIA的GPU、AMD的CPU。
此外,图18的下半部分是一种不使用TSV、经由Interposer连接芯片的Chiplet技术,被称为InFO(Integrated Fan-Out)。图18上虽然没有注明,苹果手机的处理器中采用了InFO技术。(下图19)

图19:TSMC的用于智能手机的3DSI(3D System Integration)。(图片出自:KC Yee (TSMC), “Advanced 3D System Integration Technologies”, IEDM2020, SC1)
TSMC将此项技术命名为“3DSI(3D System Integration)”,也适用于高性能计算(High Performance Computing)方向的CoWoS(下图20)。即,图19 和图20中出现的SoIC是“System on Integrated Chips using frontend 3D stacking process”的略称,是以3D方式来堆叠芯片的技术。
从以上可得知,TSMC在Chiplet尖端封装技术领域有十年的经验,领先于英特尔和三星。
采用Chiplet的尖端封装方式的未来展望
采用ASML制造的最尖端的EUV曝光设备,TSMC和三星才得以按照5纳米、4纳米、3纳米、1纳米的进程发展微缩化,但是,要提高AI半导体(用以解决成指数级增长的大数据)的处理能力,进靠增加核数、微缩化来提高核的吐出量还远远不够。此外,提高微缩化、增加核数都会产生高昂成本。
为解决以上问题,必须要研发采用了Chiplet的尖端封装技术,因此,TSMC、英特尔、三星都已经开始研发尖端封装技术。如今,TSMC的尖端封装技术领先于其他公司,半导体行业没有固定的标准,可谓是百花齐放、百家争鸣。
基于以上情况,采用的Chiplet的尖端封装技术也许没有像IRDS那样的技术蓝图。因此,我们很难预测未来会出现什么技术。
比方说,在此次的IEDM上,在TSMC的发布结束后,CEA Leti的C.Fenouillet-Beranger先生在“3D sequential integration: Opportunities, Breakthrough and Challenge”上提出了一项非常有意思的尖端封装技术的概念。(如下图21)
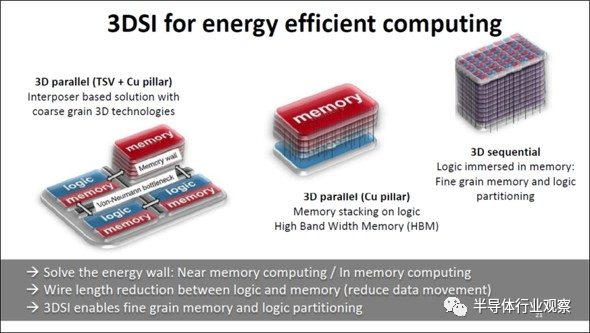
图21:3D 3D System Integration的未来。(图片出自:C.Fenouillet-Beranger (CEA Leti), “3D sequential integration: Opportunities, Breakthrough and Challenges”, IEDM2020, SC1)
当下,如图21的左边所示,融合存储半导体(HBM)、各种逻辑半导体并安装在一颗Interposer上,构筑SoC。下一个阶段是利用TSV将存储半导体和多个逻辑半导体纵向堆叠,合成一颗芯片。而且,在最后阶段,会在存储半导体内部连续嵌入多个逻辑半导体,即所谓的堆叠式“3D sequential”。
因此,牵引未来摩尔定律的不是微缩化(虽然微缩化已经做出了很大的贡献),而是采用了Chiplet的尖端封装技术。
此外,2月9日TSMC公布说要在日本筑波市建设半导体后段工序的研发据点,期待能够采用日本的材料、创造出先进的3D封装技术。
即使先进封装方式继续发展,如果当下的数字存储半导体、数字逻辑半导体无法适用的话,如下图22所示,就需要转为Neuromorphic Computing、Analog Computing、Quantum Computing等。
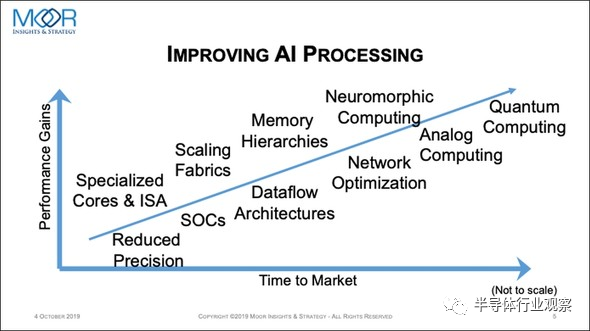
图22:AI处理技术进步的趋势。(图片出自::MOOR Insights and Strategy, AI Hardware: Harder Than It Looks)
也许在五年后的2025年前后最新的智能手机会搭载Neuromorphic(作为大脑型计算机而被研发的),此外,在2030年前后,也许量子计算机会被搭载到最新型的PC上。
假设以上皆为可能,人类第一步要走的是消灭新冠肺炎,继续勤洗手、勤漱口、佩戴口罩,期待疫苗发挥良效。
责任编辑:lq
-
三星电子
+关注
关注
34文章
15859浏览量
180973 -
晶圆制造
+关注
关注
7文章
276浏览量
24062 -
chiplet
+关注
关注
6文章
430浏览量
12582
原文标题:巨头竞逐Chiplet
文章出处:【微信号:半导体科技评论,微信公众号:半导体科技评论】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
击碎摩尔定律!英伟达和AMD将一年一款新品,均提及HBM和先进封装

Chiplet在先进封装中的重要性
高算力AI芯片主张“超越摩尔”,Chiplet与先进封装技术迎百家争鸣时代

创新型Chiplet异构集成模式,为不同场景提供低成本、高灵活解决方案
“自我实现的预言”摩尔定律,如何继续引领创新
封装技术会成为摩尔定律的未来吗?

易卜半导体创新推出Chiplet封装技术,弥补国内技术空白,助力高算力芯片发展

功能密度定律是否能替代摩尔定律?摩尔定律和功能密度定律比较
摩尔定律的终结:芯片产业的下一个胜者法则是什么?

Chiplet技术对英特尔和台积电有哪些影响呢?

中国团队公开“Big Chip”架构能终结摩尔定律?





 工商网监
工商网监
评论