 简述OpenVINO™ + ResNet实现图像分类
简述OpenVINO™ + ResNet实现图像分类
推理引擎(IE)应用开发流程
与相关函数介绍
通过OpenVINO的推理引擎跟相关应用集成相关深度学习模型的应用基本流程如下:
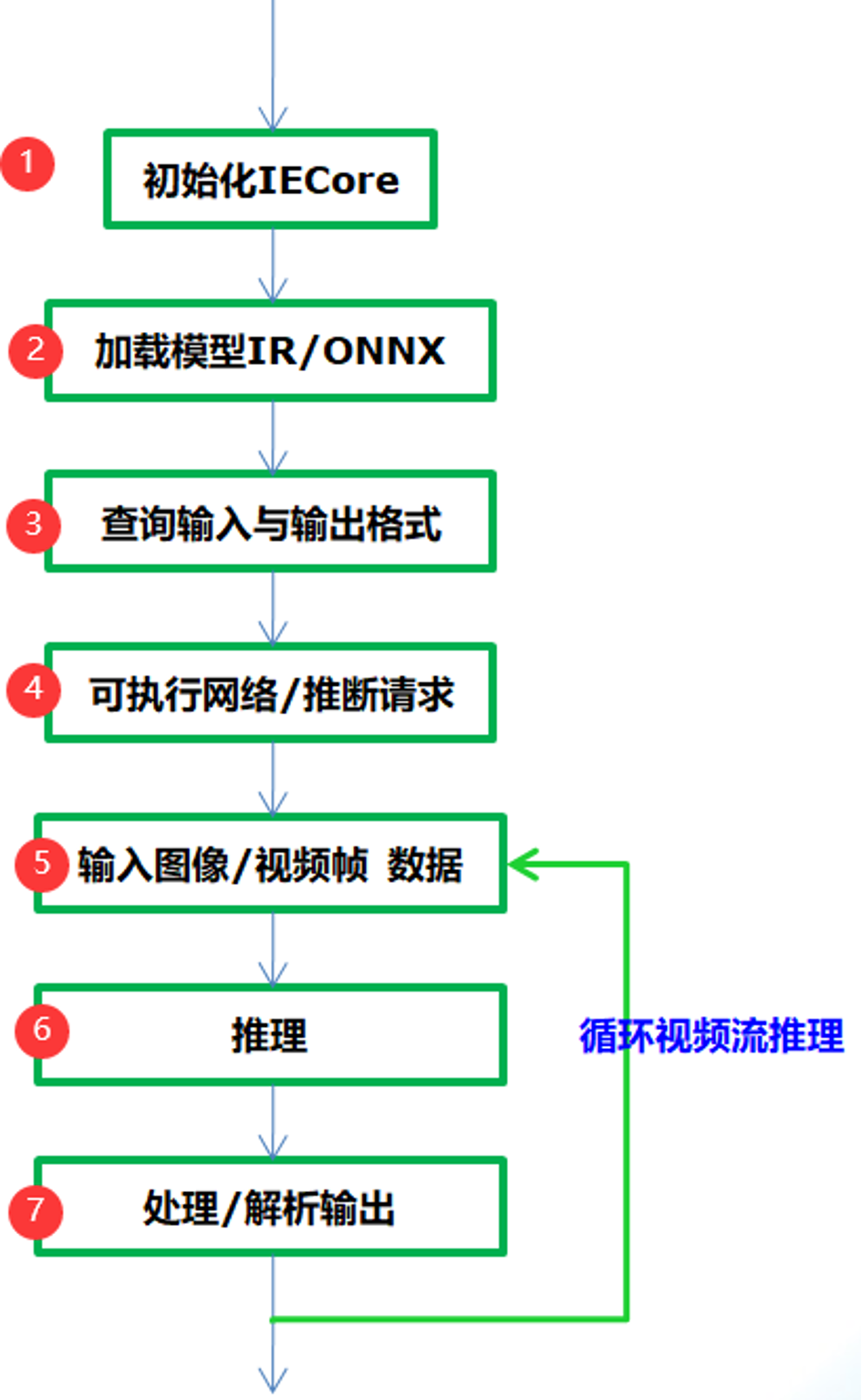
图-1
从图-1可以看到只需要七步就可以完成应用集成,实现深度学习模型的推理预测,各步骤中相关的API函数支持与作用解释如下:
Step 1:
InferenceEngine::Core // IE对象
Step 2:
Core.ReadNetwork(xml/onnx)输入的IR或者onnx格式文件,返回CNNNetwork对象
Step 3:
InferenceEngine::InputsDataMap, InferenceEngine::InputInfo, // 模型输入信息
InferenceEngine::OutputsDataMap // 模型输出信息
使用上述两个相关输入与输出对象就可以设置输入的数据类型与精度,获取输入与输出层的名称。
Step 4:
ExecutableNetwork LoadNetwork (
const CNNNetwork &network,
const std::string &deviceName,
const std::map< std::string, std::string > &config={}
)
通过Core的LoadNetwork方法生成可执行的网络,如果你有多个设备,就可以创建多个可执行的网络。其参数解释如下:
network 参数表示step2加载得到CNNNetwork对象实例
deviceName表示模型计算所依赖的硬件资源,可以为CPU、GPU、 FPGA、 FPGA、MYRIAD
config默认为空
InferRequest InferenceEngine::CreateInferRequest()
表示从可执行网络创建推理请求。
Step 5:
根据输入层的名称获取输入buffer数据缓冲区,然后把输入图像数据填到缓冲区,实现输入设置。其中根据输入层名称获取输入缓冲区的函数为如下:
Blob::Ptr GetBlob (
const std::string &name // 输入层名称
)
注意:返回包含输入层维度信息,支持多个输入层数据设置!
Step 6:
推理预测,直接调用推理请求的InferRequest.infer()方法即可,该方法无参数。
Step 7:
调用InferRequest的GetBlob()方法,使用参数为输出层名称,就会得到网络的输出预测结果,根据输出层维度信息进行解析即可获取输出预测信息与显示。
图像分类与ResNet网络
图像分类是计算机视觉的关键任务之一,关于图像分类最知名的数据集是ImageNet,包含了自然场景下大量各种的图像数据,支持1000个类别的图像分类。OpenVINO在模型库的public中有ResNet模型1000个分类的预训练模型支持,它们主要是:
- resnest-18-pytorch
- resnest-34-pytorch
- resnest-50-pytorch
- resnet-50-tf
其中18、34、50表示权重层,pytorch表示模型来自pytorch框架训练生成、tf表示tensorflow训练生成。ResNet系列网络的详细说明如下:
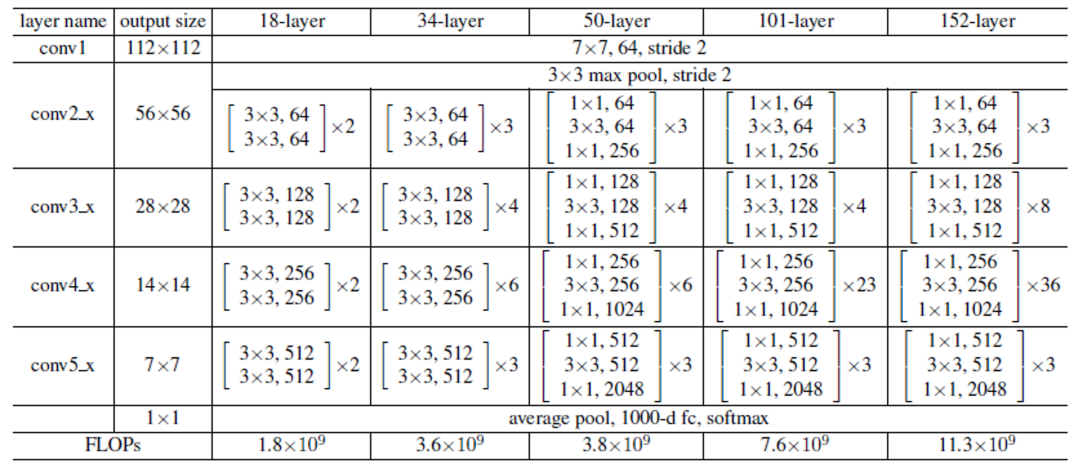
图-2(来自《Deep Residual Learning for Image Recognition》论文)
我们以ResNet18-pytorch的模型为例,基于Pytorch框架我们可以很轻松的把它转换为ONNX格式文件。然后使用Netron工具打开,可以看到网络的输入图示如下:

图-3
查看网络的输出:
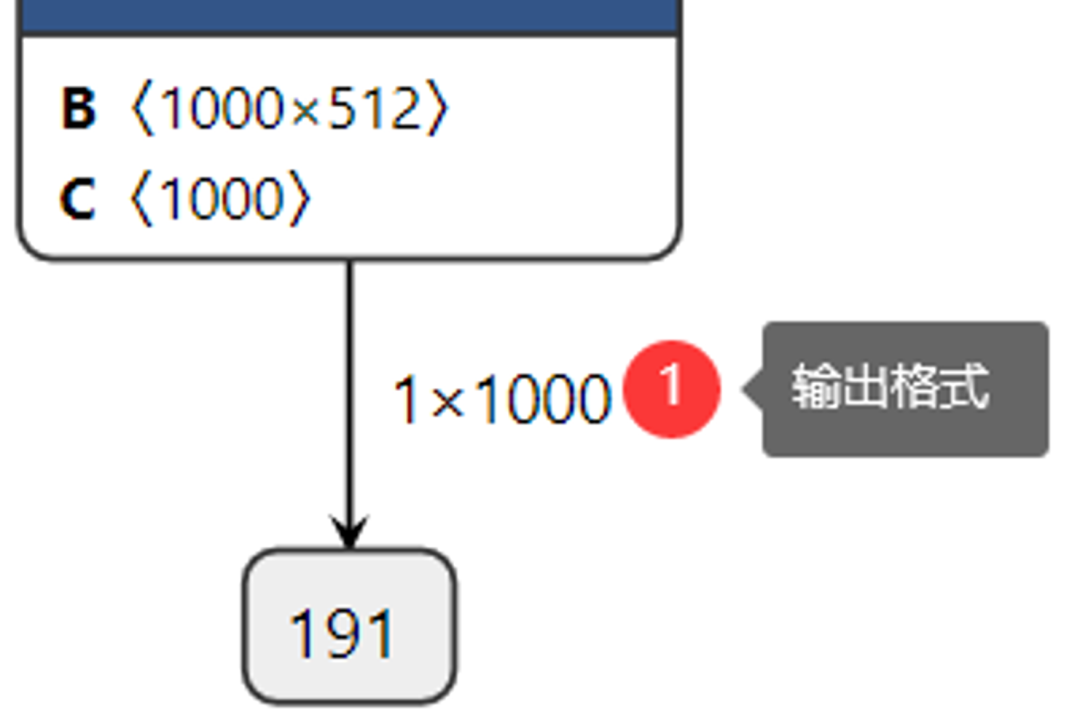
图-4
这样我们很清楚的知道网络的输入与输出层名称,输入数据格式与输出数据格式,其中输入数据格式NCHW中的N表示图像数目,这里是1、C表示图像通道数,这里输入的是彩色图像,通道数为3、H与W分别表示图像的高与宽,均为224。在输出格式中1x1000中1表示图像数目、1000表示预测的1000个分类的置信度数据。
程序实现的基本流程与步骤
前面已经介绍了IE SDK相关函数,图像分类模型ResNet18的输入与输出格式信息。现在我们就可以借助IE SDK来完成一个完整的图像分类模型的应用部署了,根据前面提到的步骤各步的代码实现与解释如下:
1. 初始化IE
InferenceEngine::Core ie;
2. 加载ResNet18网络
InferenceEngine::CNNNetwork network = ie.ReadNetwork(onnx);
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
3. 获取输入与输出名称、设置输入与输出数据格式
std::string input_name = "";
for (auto item : inputs) {
input_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);
std::cout << "input name: " << input_name << std::endl;
}
std::string output_name = "";
for (auto item : outputs) {
output_name = item.first;
auto output_data = item.second;
output_data->setPrecision(Precision::FP32);
std::cout << "output name: " << output_name << std::endl;
}
4. 获取推理请求对象实例
auto executable_network = ie.LoadNetwork(network, "CPU");
auto infer_request = executable_network.CreateInferRequest();
5. 输入图像数据设置
auto input = infer_request.GetBlob(input_name);
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h*w;
cv::Mat blob_image;
cv::resize(src, blob_image, cv::Size(w, h));
cv::cvtColor(blob_image, blob_image, cv::COLOR_BGR2RGB);
blob_image.convertTo(blob_image, CV_32F);
blob_image = blob_image / 255.0;
cv::subtract(blob_image, cv::Scalar(0.485, 0.456, 0.406), blob_image);
cv::divide(blob_image, cv::Scalar(0.229, 0.224, 0.225), blob_image);
// HWC =》NCHW
float* data = static_cast
}
}
}
在输入数据部分OpenCV导入的图像三通道顺序是BGR,所以要转换为RGB,resize到224x224大小、像素值归一化为0~1之间、然后要减去均值(0.485, 0.456, 0.406),除以方差(0.229, 0.224, 0.225)完成预处理之后再填充到Blob缓冲区中区。
6. 推理
infer_request.Infer();
7. 解析输出与显示结果
auto output = infer_request.GetBlob(output_name);
const float* probs = static_cast
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[0] << "x" << outputDims[1] << std::endl;
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++) {
if (max < probs[i]) {
max = probs[i];
max_index = i;
}
}<:fp32>
cv::putText(src, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("输入图像", src);
cv::waitKey(0);
解析部分代码首先通过输出层名称获取输出数据对象BLOB,然后根据输出格式1x1000,寻找最大值对应的index,根据索引index得到对应的分类标签,然后通过OpenCV图像输出分类结果。
运行结果
图-5(来自ImageNet测试集)
这样我们就使用OpenVINO 的推理引擎相关的SDK函数支持成功部署ResNet18模型,并预测了一张输入图像。你可以能还想知道除了图像分类模型,OpenVINO 推理引擎在对象检测方面都有哪些应用,我们下次继续…….
编辑:jq
-
函数
+关注
关注
3文章
4335浏览量
62728 -
代码
+关注
关注
30文章
4798浏览量
68715 -
OpenCV
+关注
关注
31文章
635浏览量
41383 -
SDK
+关注
关注
3文章
1038浏览量
46008
原文标题:OpenVINO™ + ResNet实现图像分类
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于FPGA实现图像直方图设计
高通AI Hub:轻松实现Android图像分类

使用卷积神经网络进行图像分类的步骤
基于改进ResNet50网络的自动驾驶场景天气识别算法

手把手教你使用LabVIEW TensorRT实现图像分类实战(含源码)
使用OpenVINO Model Server在哪吒开发板上部署模型
使用OpenVINO C# API部署YOLO-World实现实时开放词汇对象检测

简述计算机总线的分类
OpenVINO2024 C++推理使用技巧
计算机视觉怎么给图像分类
一种利用光电容积描记(PPG)信号和深度学习模型对高血压分类的新方法
OpenAI发布图像检测分类器,可区分AI生成图像与实拍照片
为OpenVINO添加对Paddle 2.5的支持
基于OpenVINO™和AIxBoard的智能安检盒子设计

如何在MacOS上编译OpenVINO C++项目呢?






 工商网监
工商网监
评论