 胶囊网络在小样本做文本分类中的应用(下)
胶囊网络在小样本做文本分类中的应用(下)
论文提出Dynamic Memory Induction Networks (DMIN) 网络处理小样本文本分类。
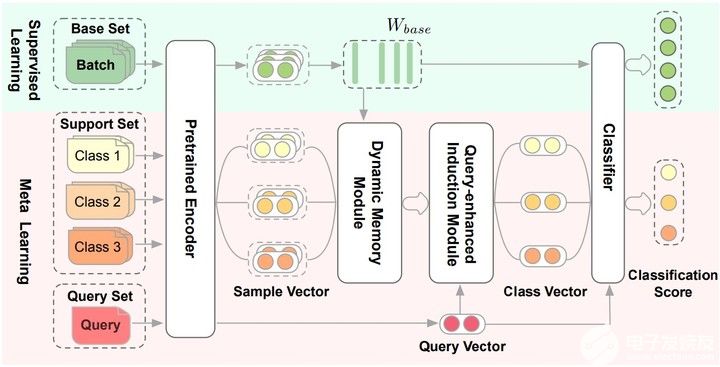
两阶段的(two-stage)few-shot模型:
在监督学习阶段(绿色的部分),训练数据中的部分类别被选为base set,用于finetune预训练Encoder和分类器也就是Pretrained Encoder和Classfiier图中的部分。
在元学习阶段(红色的部分),数据被构造成一个个episode的形式用于计算梯度和更新模型参数。对于C-way K-shot,一个训练episode中的Support Set是从训练数据中随机选择C个类别,每个类别选择K个实例构成的。每个类别剩下的样本就构成Query Set。也就是在Support Set上训练模型,在Query Set上计算损失更新参数。
Pretrained Encoder
用[CLS]预训练的句子的Bert-base Embedding来做fine-tune。$W_{base}$ 就作为元学习的base特征记忆矩阵,监督学习得到的。
Dynamic Memory Module
在元学习阶段,为了从给定的Support Set中归纳出类级别的向量表示,根据记忆矩阵 $W_{base}$ 学习Dynamic Memory Module(动态记忆模块)。

给定一个 $M$ ( $W_{base}$ )和样本向量 q , q 就是一个特征胶囊,所以动态记忆路由算法就是为了得到适应监督信息 $ W_{base} $ 的向量 $q^{'}$ ,
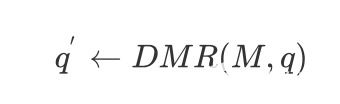
$$ q^{'} \leftarrow DMR(M, q) $$ 学习记忆矩阵 $M$ 中的每个类别向量 $M^{'} $ 进行更新,
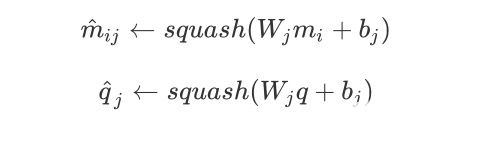
其中
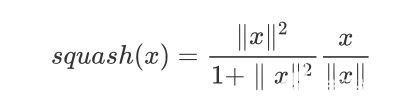
这里的 $W_j$ 就是一个权重。因此变换权重 $W_j$ 和偏差 $b_j$ 在输入时候是可以共享的, 因此计算 $\hat{m}{ij}$ 和 $\hat{q}_j$ 之间的皮尔逊相关系数
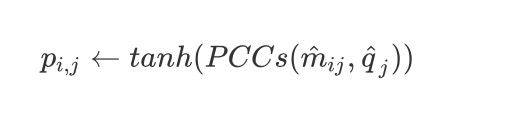
其中
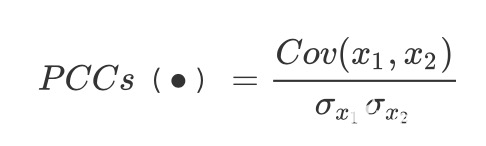
接下来就是进行动态路由算法学习最佳的特征映射(这里添加了$p_{ij}$到路由协议中),到第11行为止。从第12行开始也会根据监督学习的记忆矩阵和胶囊的皮尔逊相关系数来更新$p_{ij}$,最后把部分胶囊
编辑:jq
-
数据
+关注
关注
8文章
7193浏览量
89818 -
Query
+关注
关注
0文章
11浏览量
9396 -
小样本
+关注
关注
0文章
7浏览量
6835 -
动态路由
+关注
关注
0文章
16浏览量
23148 -
网络处理
+关注
关注
0文章
5浏览量
6380
发布评论请先 登录
相关推荐
AFE4960如何正确的从FIFO中读取样本呢?
图纸模板中的文本变量
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
利用TensorFlow实现基于深度神经网络的文本分类模型
BP神经网络样本的获取方法
BP神经网络最少要多少份样本
BP神经网络在语言特征信号分类中的应用
cnn卷积神经网络分类有哪些
卷积神经网络在文本分类领域的应用
交换机的基本分类
基于神经网络的呼吸音分类算法
了解如何使用PyTorch构建图神经网络





 工商网监
工商网监
评论