 浅析智能音箱为什么听不懂人话?
浅析智能音箱为什么听不懂人话?
当你字正腔圆地对着智能音箱发问,得到的却是让人一脸懵逼的回答。使用过智能音箱或其它语音助手的朋友,对这一场景都不会陌生。
怀疑自己被割了智商税的你可能会问:智能音箱为什么听不懂人话?它能变聪明吗?
想解答这个问题,我们需要先了解智能音箱听懂语音的工作原理。
语音、文本、图片、视频,这些信息对于机器来说,属于“非结构化数据”,无法直接理解。机器能够理解并作出反馈的,是“结构化数据”。
简单理解二者之间的区别与关系,非结构化数据相当于写了一段文本的word文档,而结构化数据则是将这段文本进行总结归纳的excel文档。
当我们向智能音箱提问时,智能音箱会先将语音转化为文字,然后将文字形成结构化数据理解并反馈,最后再将文本转化成语音输出答案。
三大流程对应着3种技术,其中ASR(自动语音识别)和TTS(处理结果转化成语音输出)技术相对成熟,像ASR已广泛应用在语音转文字、语音输入法、智能翻译笔等应用上。据中科院2019年的测试,国内四家主流智能音箱品牌ASR识别率均在94%以上。
智能音箱听不懂我们的话,问题主要出在NLP(理解文字的意思并进行处理)环节上。
AI在拿到文本后,需要进行语料清洗、分词、词性标注、实体命名识别、去除停用词等一系列操作,才能将文本正确转化为结构化数据,并作出反应。
智能音箱今天已经可以比较“智能“地处理明确的指令问题,比如打开电视,今天天气怎么样,设定闹钟等。
但在开放性语境下,智能音箱错误频出。这是因为口语文本经常会出现歧义,机器难以理解,特别是在处理同音字繁多、语法复杂的中文时,歧义的现象尤其多见。
比如“帮我上一个半小时之后的闹钟”,音箱基本没法识别是半小时还是一个半小时。再比如“帮我预定一家餐厅不要日本菜“,AI大概率无法理解“不要”在句子中的含义。
面对复杂的自然语言,AI想要辨别、理解、消除歧义,必须要分析海量“语料”,也就是对人类语言的实例进行学习。
供AI学习的语料,主要有三种来源:
第一是AI算法企业根据需求自己构造的“语料库”,比如针对特定功能,需要构造人名库、地名库、歌手名库、歌曲名库等。
第二是从互联网上大量抽取的文本,最常见的是从社交网络中抽取,以便机器理解最新的口语表达方式。
最后则是用户在与产品交互过程中产生的数据,像我们与智能音箱对话的部分内容,会被上传进厂商的语料库,供AI进行学习。
那如果长时间和智能音箱对话,是不是能让智能音箱更懂我呢?
答案是很难。一般来说,所有的训练学习过程,都是在AI算法商一端完成的。算法商会根据所有用户的数据,对AI进行训练、更新,而非针对某个特定用户。
所以,要想让智能音箱听懂你个人习惯性的语病、倒装、口头禅等等,目前的最好办法,是自己手动录入,指定它该作出什么反应。
虽然智能音箱技术还没完全成熟,但在互联网巨头眼中,它却是必须攻下来的阵地。 2019年的中国智能音箱市场经历了爆发式增长,总出货量4589万台,同比增长109.7%。其中阿里的天猫精灵,百度的小度音箱,小米的小爱音箱,三家占据了9成以上市场份额。
智能音箱在出货量上涨的同时却没给巨头们带来利润。2019年,百度副总裁景鲲向媒体表示,百度是通过补贴维持了小度音箱的低价。而另据业内人士估算,每卖一台小爱音箱,小米只赚1块钱。
巨头们的底层逻辑是,智能音箱很有可能成为未来家庭的控制中心,所以要用现在的低价策略换取未来物联网时代的入场券。这样的策略确实能带来销量的增加,但切实解决用户的痛点才能保证产品使用率。
编辑:jq
为了提高智能音箱在用户生活中的不可替代性,厂商都在费尽心思给智能音箱增加新的功能,因为谁也不想看到当物联网时代真正到来的时候,用户家中的智能音箱上已经落满了厚厚的灰尘。
编辑:jq
-
AI
+关注
关注
87文章
31044浏览量
269392 -
ASR
+关注
关注
2文章
43浏览量
18753 -
TTS
+关注
关注
0文章
42浏览量
10800 -
智能音箱
+关注
关注
31文章
1783浏览量
78654
原文标题:智能音箱为什么听不懂人话?
文章出处:【微信号:电子工程世界,微信公众号:电子工程世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
蓝牙音箱的EMC问题与解决方法
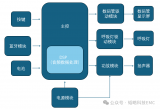
NTP8910A功放芯片,助力智能音箱音质再升级!


用TAS5630芯片做了一个2.1功放板,通电的音箱没声音,须要开机后再插音箱才会有声音,为什么?
时钟蓝牙音箱怎么打开蓝牙
小米跃居中国智能音箱市场领头羊
AI智能音箱用2×15W立体声功放芯片NTP8918
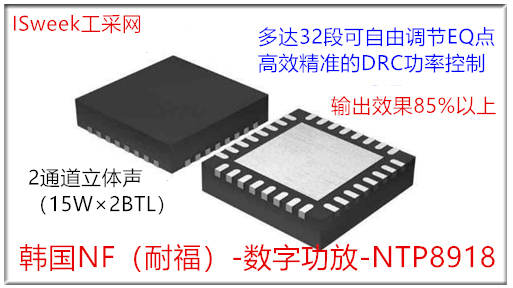
便携式智能音箱音频解决方案

天龙智能音箱支持苹果Siri调用功能
浅析基于泛在电力物联网的智能电表设计与应用
浅析城市综合管廊智能照明设计应用
浅析配电室智能监控系统的设计与实践探索





 工商网监
工商网监
评论