 用生成模型来做图像恢复的介绍和回顾
用生成模型来做图像恢复的介绍和回顾
导读
本文给出了图像恢复的一般性框架,编解码器 + GAN,后面的图像复原基本都是这个框架。
本文会介绍图像修复的目的,它的应用,等等。然后,我们将深入研究文献中关于图像修复的第一个生成模型(即第一个基于GAN的修复算法,上下文编码器)。
目标
很简单的!我们想要填补图像中缺失的部分。
应用
移除图像中不需要的部分(即目标移除)
修复损坏的图像(可以扩展到修复电影)
很多其他应用!
术语
给出一个有一些缺失区域的图像,我们定义
缺失像素/生成像素/空洞像素:待填充区域的像素。
有效像素/ground truth像素:和缺失像素含义相反。需要保留这些像素,这些像素可以帮助我们填补缺失的区域。
传统方法
给出一个有一些缺失区域的图像,最典型的传统方法填充缺失区域是复制粘贴。
主要思想是从图像本身或一个包含数百万张图像的大数据集中寻找最相似的图像补丁,然后将它们粘贴到缺失的区域。
然而,搜索算法可能是耗时的,它涉及到手工设计距离的度量方法。在通用化和效率方面仍有改进的空间。
数据驱动的基于深度学习的方法
由于卷积神经网络(Convolutional Neural Networks, CNNs)在图像处理方面的成功,很多人开始将CNNs应用到自己的任务中。基于数据驱动的深度学习方法的强大之处在于,如果我们有足够的训练数据,我们就可以解决我们的问题。
如上所述,图像修复就是将图像中缺失的部分补上。这意味着我们想要生成一些不存在或没有答案的东西。因此,所有基于深度学习的修复算法都使用生成对抗网络(GANs)来产生视觉上吸引人的结果。为什么视觉上吸引人呢?由于没有模型来回答生成的问题,人们更喜欢有良好视觉质量的结果,这是相当主观的!
对于那些可能不知道GANs的读者,我推荐你先去了解一下。这里以图像修复为例,简单地说,典型的GAN由一个生成器和一个鉴别器组成。生成器负责填补图像中缺失的部分,鉴别器负责区分已填充图像和真实图像。请注意,真实的图像是处于良好状态的图像(即没有缺失的部分)。我们将随机地将填充的图像或真实的图像输入识别器来欺骗它。最终,如果鉴别器不能判断图像是被生成器填充的还是真实的图像,生成器就能以良好的视觉质量填充缺失的部分!
第一个基于GAN的修复方法:上下文编码器
在对image inpainting做了简单的介绍之后,我希望你至少知道什么是image inpainting, GANs(一种生成模型)是inpainting领域常用的一种。现在,我们将深入研究本系列的第一篇论文。
Intention
作者想训练一个CNN来预测图像中缺失的像素。众所周知,典型的CNNs(例如LeNet手写数字识别和AlexNet图像分类)包含许多的卷积层来提取特征,从简单的结构特征到高级的语义特征(即早期层简单的特征,比如边缘,角点,到后面的层的更复杂的特征模式)。对于更复杂的功能模式,作者想利用学到的高层语义特征(也称为隐藏特征)来帮助填充缺失的区域。
此外,为修复而学习的特征需要对图像进行更深层次的语义理解。因此,学习到的特征对于其他任务也很有用,比如分类、检测和语义分割。
背景
在此,我想为读者提供一些背景信息,
Autoencoders:这是一种通常用于重建任务的CNN结构。由于其形状,也有人称之为沙漏结构模型。对于这个结构,输出大小与输入大小相同,我们实际上有两个部分,一个是编码器,另一个是解码器。
编码器部分用于特征编码,针对输入得到紧凑潜在的特征表示,而解码器部分则对潜在特征表示进行解码。我们通常把中间层称为低维的“瓶颈”层,或者简单地称之为“瓶颈”,因此整个结构看起来就像一个沙漏。
让我们想象一下,我们将一幅完好无损的图像输入到这个自动编码器中。在这种情况下,我们期望输出应该与输入完全相同。这意味着一个完美的重建。如果可能的话,“瓶颈”是输入的一个完美的紧凑潜在特征表示。
更具体地说,我们可以使用更少的数字来表示输入(即更有效,它与降维技术有关)。因此,这个“瓶颈”包含了几乎所有的输入信息(可能包括高级语义特征),我们可以使用它来重构输入。
上下文编码器进行图像生成
首先,输入的是mask图像(即有中心缺失的图像)。输入编码器以获得编码后的特征。然后,本文的主要贡献是在编码特征和解码特征之间放置通道全连接层,以获得更好的语义特征(即“瓶颈”)。最后,解码器利用“瓶颈”特征重建缺失的部分。让我们来看看他们的网络内部。
编码器
编码器使用AlexNet结构,他们用随机初始化权值从头开始训练他们的网络。
与原始的AlexNet架构和图2所示的自动编码器相比,主要的区别是中间的通道全连接层。如果网络中只有卷积层,则无法利用特征图上距离很远的空间位置的特征。为了解决这个问题,我们可以使用全连接层,即当前层的每个神经元的值依赖于上一层的所有神经元的值。然而,全连接层会引入许多参数,8192x8192=67.1M,这甚至在GPU上也很难训练,作者提出了通道全连接层来解决这个问题。
通道全连接层
实际上,通道全连接层非常简单。我们只是完全独立地连接每个通道而不是所有的通道。例如,我们有m个大小为n x n的特征映射。如果使用标准的全连接层,我们会有m²n⁴个参数,对于通道级的全连接层,我们只有mn⁴个参数。因此,我们可以在距离很远的空间位置上捕获特征,而不需要添加那么多额外的参数。
解码器
对于解码器来说,这只是编码过程的反向。我们可以使用一系列的转置卷积来获得期望大小的重建图像。
损失函数
本文使用的损失函数由两项组成。第一项是重建损失(L2损失),它侧重于像素级的重建精度(即PSNR方向的损失),但总是会导致图像模糊。第二个是对抗损失,它通常用于GANs。它鼓励真实图像和填充图像之间数据分布更接近。
对于那些对损失函数感兴趣的读者,我强烈推荐你们阅读这篇论文中的方程。在这里,我只是口头描述每个损失项。
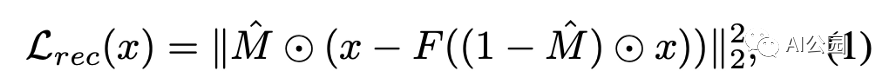
重建损失(L2损失),M表示缺失的区域(1表示缺失区域,0表示有效像素),F是生成器
L2损失:计算生成的像素与对应ground truth像素之间的L2距离(欧几里得距离)。只考虑缺失区域。
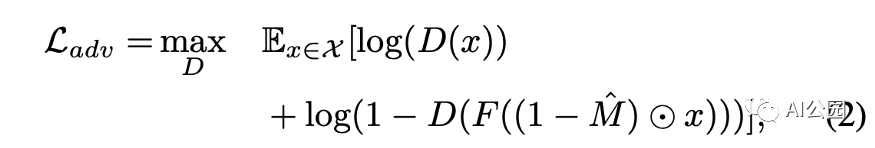
对抗损失,D是鉴别器。我们希望训练出一种能够区分填充图像和真实图像的鉴别器
对抗损失:对抗鉴别器的结构如图4所示。鉴别器的输出是一个二进制值0或1。如果输入是真实图像,则为1,如果输入是填充图像,则为0。
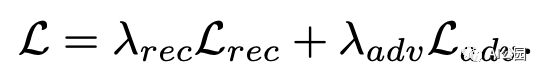
联合损失,Lambda_rec为0.999,Lambda_adv为0.001
使用随机梯度下降(SGD),Adam优化器交替训练生成器和鉴别器。
实验结果
评估使用了两个数据集,即Paris Street View和ImageNet。
作者首先展示了修复结果,然后他们还表明,作为预训练步骤,学习到的特征可以迁移到其他任务中。
语义修复
作者与传统的最近邻修复算法进行了比较。显然,该方法优于最近邻修复方法。
我们可以看到L2损失倾向于给出模糊的图像(第二列)。L2 +对抗性的损失给更清晰的填充图像。对于NN-Inpainting,他们只是复制和粘贴最相似的图像补丁到缺失的区域。
特征学习
为了显示他们学习到的特征的有用性,作者尝试编码不同的图像patch,并根据编码的特征得到最相似的patch。在图7中。作者将其与传统的HOG和典型的AlexNet进行了比较。它们实现了与AlexNet类似的表现,但AlexNet是在一百万张标有数据集的图像上预训练的。
如表2所示,在ImageNet上预训练过的模型具有最好的性能,但需要昂贵的标签。在该方法中,上下文是用于训练模型的监督。这就是他们所谓的通过修复图像来学习特征。很明显,它们学习到的特征表示与其他借助辅助监督训练的模型相当,甚至更好。
总结
所提出的上下文编码器训练可以在上下文的条件下生成图像。在语义修复方面达到了最先进的性能。
学习到的特征表示也有助于其他任务,如分类,检测和语义分割。
要点
我想在这里强调一些要点。
对于图像修复,我们必须使用来自有效像素的“提示”来帮助填充缺失的像素。“上下文”一词是指对整个图像本身的理解。
本文的主要贡献是通道全连接层。其实,理解这一层并不难。对我来说,它是Non-Local Neural Networks或Self-Attention的早期版本/简化版本。主要的一点是,前一层的所有特征位置对当前层的每个特征位置都有贡献。从这个角度来看,我们对整个图像的语义理解会更加深入。这个概念在后面的文章中被广泛采用!
所有后来的修复论文都遵循了GAN-based结构(即编码器-解码器结构)。人们的目标是具有良好视觉质量的充满图像。
英文原文:https://medium.com/analytics-vidhya/introduction-to-generative-models-for-image-inpainting-and-review-context-encoders-13e48df30244
编辑:jq
-
解码器
+关注
关注
9文章
1143浏览量
40742 -
编码器
+关注
关注
45文章
3643浏览量
134519 -
GaN
+关注
关注
19文章
1935浏览量
73426 -
cnn
+关注
关注
3文章
352浏览量
22215
原文标题:用生成模型来做图像恢复的介绍和回顾:上下文编码器
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenAI暂不推出Sora视频生成模型API
字节发布SeedEdit图像编辑模型
Meta发布Imagine Yourself AI模型,重塑个性化图像生成未来
经典卷积网络模型介绍
如何用C++创建简单的生成式AI模型
Runway发布Gen-3 Alpha视频生成模型
OpenAI发布图像检测分类器,可区分AI生成图像与实拍照片
KOALA人工智能图像生成模型问世
韩国科研团队发布新型AI图像生成模型KOALA,大幅优化硬件需求
谷歌模型合成工具怎么用
谷歌Gemini AI模型因人物图像生成问题暂停运行
openai发布首个视频生成模型sora
Stability AI试图通过新的图像生成人工智能模型保持领先地位






 工商网监
工商网监
评论