 如何去解决文本到图像生成的跨模态对比损失问题?
如何去解决文本到图像生成的跨模态对比损失问题?
Google提出了一个跨模态对比学习框架来训练用于文本到图像合成的 GAN 模型,用于研究解决生成的跨模态对比损失问题。
从文本到图像的自动生成,如何训练模型仅通过一段文本描述输入就能生成具体的图像,是一项非常具有挑战性的任务。
与其它指导图像创建的输入类型相比,描述性句子是一种更直观、更灵活的视觉概念表达方式。强大的自动文本到图像的生成系统可以成为快速、有效的内容生产、制作工具,用于更多具有创造性的应用当中。
在CVPR 2021中,Google提出了一个跨模态对比生成对抗网络(XMC-GAN),训练用于文本到图像合成的 GAN 模型,通过模态间与模态内的对比学习使图像和文本之间的互信息最大化,解决文本到图像生成的跨模态对比损失问题。
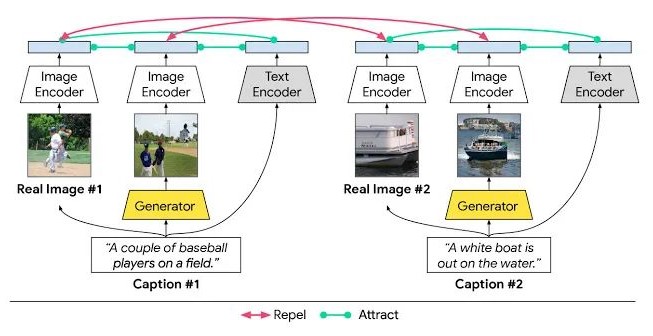
XMC-GAN 文本到图像合成模型中的模态间和模态内对比学习
XMC-GAN 被成功应用于三个具有挑战性的数据集:一个是MS-COCO 图像描述集合,另外两个是用Localized Narratives注释的数据集,一个是包括MS-COCO 图像(称为LN-COCO) ,另一个描述开放图像数据 (LN-OpenImages)。结果显示 XMC-GAN生成图像所描绘的场景相比于使用其它技术生成的图像质量更高,在每个方面都达到了最先进的水平。
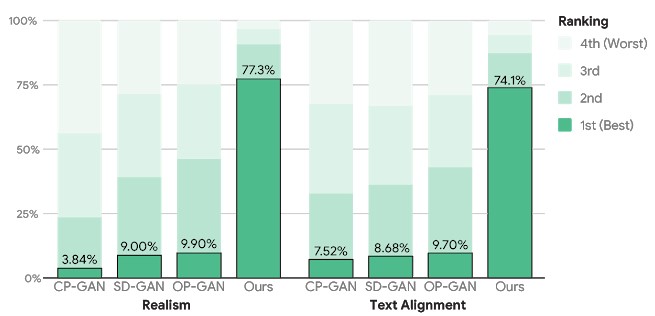
MS-COCO对图像质量和文本对齐的人工评估
此外,XMC-GAN还在 LN-OpenImages 上进行了一系列训练和评估,这相比于 MS-COCO 更具有挑战性,由于数据集更大,图像涵盖主题范围更加广泛且复杂。
对于人类评估和定量指标,XMC-GAN 在多个数据集模型中相较之前有显著的改进。可以生成与输入描述非常匹配的高质量图像,包括更长,更详细的叙述,同时端到端模型的复杂度也相对较为简单,这代表了从自然语言描述生成图像的创造性应用的重大进步。
责任编辑:lq6
-
图像
+关注
关注
2文章
1089浏览量
40601 -
GaN
+关注
关注
19文章
1974浏览量
74469
原文标题:XMC-GAN:从文本到图像的跨模态对比学习
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

#新年新气象,大家新年快乐!#AIGC入门及鸿蒙入门
AIGC入门及鸿蒙入门
浅析OpenVINO 2024.5的新功能
生成式AI工具作用
如何使用 Llama 3 进行文本生成
AIGC与传统内容生成的区别
利用OpenVINO部署Qwen2多模态模型
Meta发布多模态LLAMA 3.2人工智能模型
鸿蒙ArkTS声明式开发:跨平台支持列表【半模态转场】模态转场设置

阿里云通义大模型助力“小爱同学”强化多模态AI生成能力
李未可科技正式推出WAKE-AI多模态AI大模型

深度学习生成对抗网络(GAN)全解析
NVIDIA Edify多模态架构升级,引领视觉生成式AI新纪元
Stability AI试图通过新的图像生成人工智能模型保持领先地位






 工商网监
工商网监
评论