 什么是图像实例分割?常见的图像实例分割有哪几种?
什么是图像实例分割?常见的图像实例分割有哪几种?
实例分割概念
图像实例分割是在对象检测的基础上进一步细化,分离对象的前景与背景,实现像素级别的对象分离。所以图像实例分割是基于对象检测的基础上进一步提升。图像实例分割在目标检测、人脸检测、表情识别、医学图像处理与疾病辅助诊断、视频监控与对象跟踪、零售场景的货架空缺识别等场景下均有应用。很多人会把图像语义分割跟实例分割搞混淆,其实图像的语义分割(Semantic Segmentation)与图像的实例分割(Instance Segmentation)是两个不同的概念,看下图:

图-1(来自COCO数据集论文)
左侧是图像语义分割的结果,几个不同的类别人、羊、狗、背景分别用不同的颜色表示;右侧是图像实例分割的结果,对每只羊都用不同的颜色表示,而且把每个对象从背景中分离出来。这个就是语义分割跟实例分割的区别,直白点可以说就是语义分割是对每个类别、实例分割是针对每个对象(多个对象可能属于同一个类别)。
常见的实例分割网络
Mask-RCNN实例分割网络
图像实例分割是在对象检测的基础上再多出个基于ROI的分割分支,基于这样思想的实例分割Mask-RCNN就是其经典代表,它的网络结构如下:
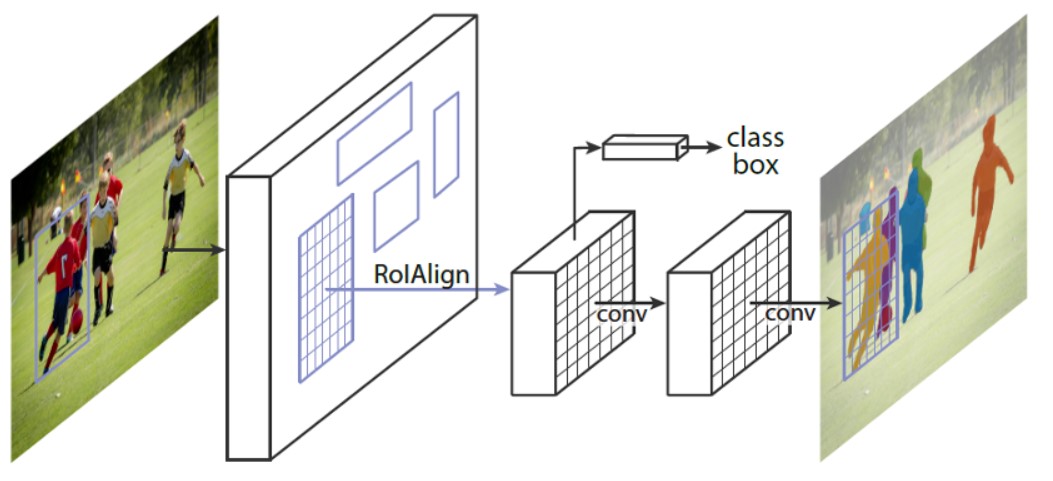
图-2(来自Mask-RCNN的论文)
Mask-RCNN可以简单地认为是Faster-RCNN的基础上加上一个实例分割分支。
RetinaMask实例分割网络
RetinaMask可以看成RetinaNet对象检测网络跟Mask-RCNN实例分割网络的两个优势组合,基于特征金字塔实现了更好的Mask预测,网络结构图示如下:
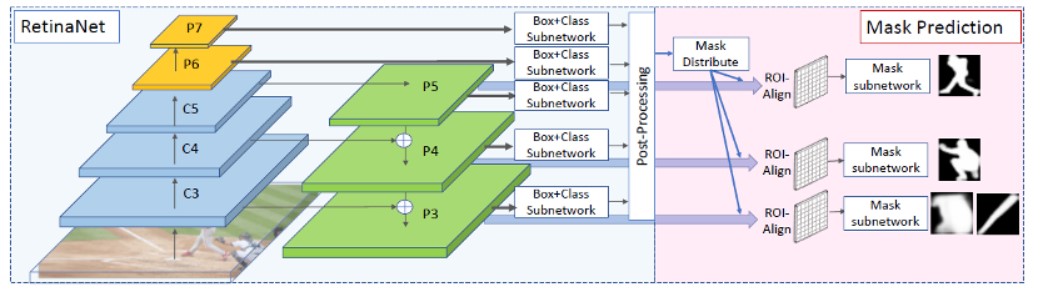
图-3(来自RetinaMask论文)
PANet实例分割网络
PANet主要工作是基于Mask-RCNN网络上改进所得,作者通过改进Backbone部分提升了特征提取能力,通过自适应的池化操作得到更多融合特征,基于全链接融合产生mask,最终取得了比Mask-RCNN更好的实例分割效果,该模型的结构如下:
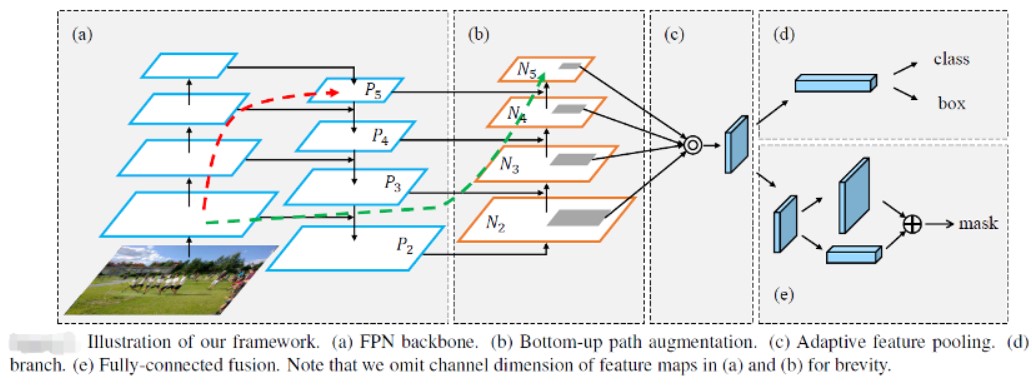
图-4(来自PANet论文)
其中全链接特征融合mask分支如下图:
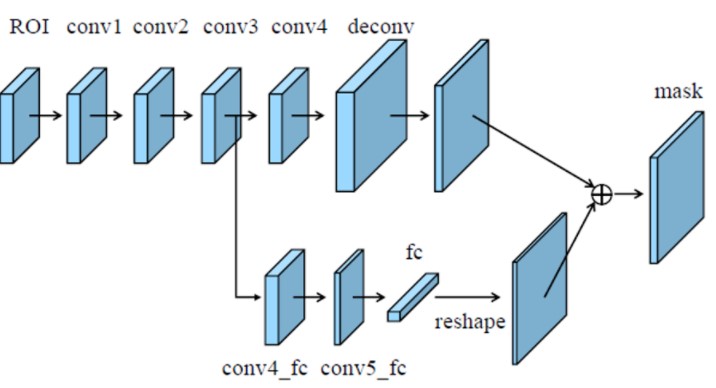
图-5(来自PANet论文)
YOLACT实例分割网络
该实例分割网络也是基于RetinaNet对象检测网络的基础上,添加一个Mask分支,不过在添加Mask分支的时候它的Mask分支设计跟RetinaMask有所不同,该网络的结构图示如下:
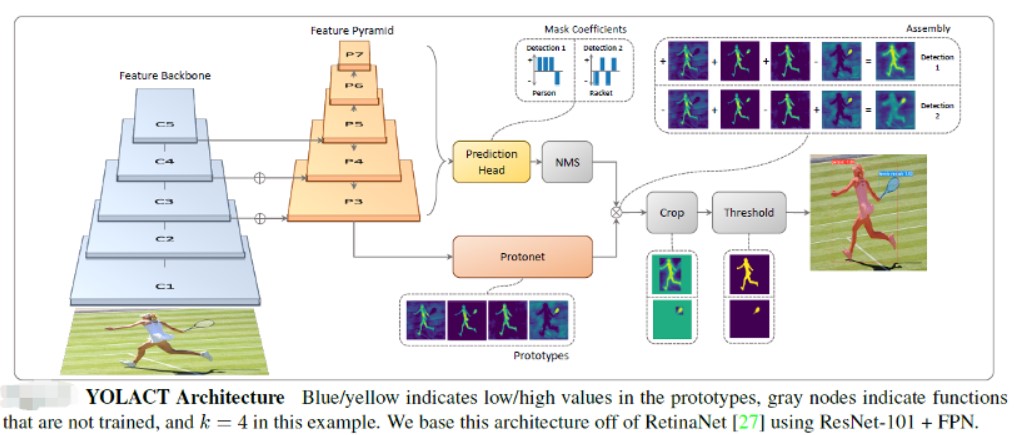
图-6(来自YOLACT作者论文)
CenterMask实例分割网络
该实例网络是基于FCOS对象检测框架的基础上,设计一个Mask分支输出,该Mask分支被称为空间注意力引导蒙板(Spatial Attention Guided Mask),该网络的结构如下:
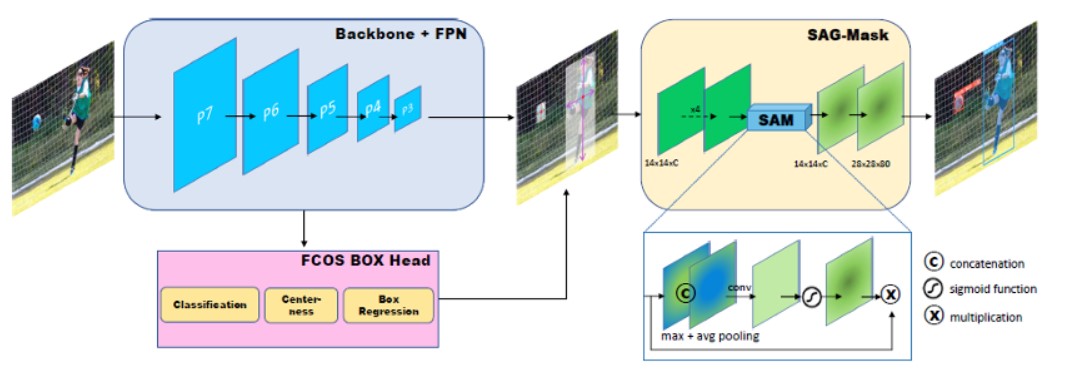
图-7(来自CenterMask论文)
OpenVINO 支持Mask-RCNN模型
OpenVINO 中支持两种实例分割模型分别是Mask-RCNN与YOLACT模型,其中Mask-RCNN模型支持来自英特尔官方库文件、而YOLACT则来自公开的第三方提供。我们这里以官方的Mask-RCNN模型instance-segmentation-security-0050为例说明,该模型基于COCO数据集训练,支持80个类别的实例分割,加上背景为81个类别。
OpenVINO 支持部署Faster-RCNN与Mask-RCNN网络时候输入的解析都是基于两个输入层,它们分别是:
im_data : NCHW=[1x3x480x480]
im_info: 1x3 三个值分别是H、W、Scale=1.0
输出有四个,名称与输出格式及解释如下:
name: classes, shape: [100, ] 预测的100个类别可能性,值在[0~1]之间
name: scores: shape: [100, ] 预测的100个Box可能性,值在[0~1]之间
name: boxes, shape: [100, 4] 预测的100个Box坐标,左上角与右下角,基于输入的480x480
name: raw_masks, shape: [100, 81, 28, 28] Box ROI区域的实例分割输出,81表示类别(包含背景),28x28表示ROI大小,注意:此模型输出大小为14x14
模型实例分割代码演示
因为模型的加载与推理部分的代码跟前面系列文章的非常相似,这里就不再给出。代码演示部分重点在输出的解析,为了简化,我用了两个for循环设置了输入与输出数据精度,然后直接通过hardcode的输出层名称来获取推理之后各个输出层对应的数据部分,首先获取类别,根据类别ID与Box的索引,直接获取实例分割mask,然后随机生成颜色,基于mask实现与原图BOX ROI的叠加,产生了实例分割之后的效果输出。解析部分的代码首先需要获取推理以后的数据,获取数据的代码如下:
float w_rate = static_cast
float h_rate = static_cast
auto scores = infer_request.GetBlob("scores");
auto boxes = infer_request.GetBlob("boxes");
auto clazzes = infer_request.GetBlob("classes");
auto raw_masks = infer_request.GetBlob("raw_masks");
const float* score_data = static_cast
const float* boxes_data = static_cast
const float* clazzes_data = static_cast
const auto raw_masks_data = static_cast
const SizeVector scores_outputDims = scores->getTensorDesc().getDims();
const SizeVector boxes_outputDims = boxes->getTensorDesc().getDims();
const SizeVector mask_outputDims = raw_masks->getTensorDesc().getDims();
const int max_count = scores_outputDims[0];
const int object_size = boxes_outputDims[1];
printf("mask NCHW=[%d, %d, %d, %d] ", mask_outputDims[0], mask_outputDims[1], mask_outputDims[2], mask_outputDims[3]);
int mask_h = mask_outputDims[2];
int mask_w = mask_outputDims[3];
size_t box_stride = mask_h * mask_w * mask_outputDims[1];
然后根据输出数据格式开始解析Box框与Mask,这部分的代码如下:
for (int n = 0; n < max_count; n++) {
float confidence = score_data[n];
float xmin = boxes_data[n*object_size] * w_rate;
float ymin = boxes_data[n*object_size + 1] * h_rate;
float xmax = boxes_data[n*object_size + 2] * w_rate;
float ymax = boxes_data[n*object_size + 3] * h_rate;
if (confidence > 0.5) {
cv::Scalar color(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));
cv::Rect box;
float x1 = std::max(0.0f, xmin), static_cast
float y1 = std::max(0.0f, ymin), static_cast
float x2 = std::max(0.0f, xmax), static_cast
float y2 = std::max(0.0f, ymax), static_cast
box.x = static_cast
box.y = static_cast
box.width = static_cast
box.height = static_cast
int label = static_cast
std::cout << "confidence: " << confidence << " class name: " << coco_labels[label] << std::endl;
// 解析mask
float* mask_arr = raw_masks_data + box_stride * n + mask_h * mask_w * label;
cv::Mat mask_mat(mask_h, mask_w, CV_32FC1, mask_arr);
cv::Mat roi_img = src(box);
cv::Mat resized_mask_mat(box.height, box.width, CV_32FC1);
cv::resize(mask_mat, resized_mask_mat, cv::Size(box.width, box.height));
cv::Mat uchar_resized_mask(box.height, box.width, CV_8UC3, color);
roi_img.copyTo(uchar_resized_mask, resized_mask_mat <= 0.5);
cv::addWeighted(uchar_resized_mask, 0.7, roi_img, 0.3, 0.0f, roi_img);
cv::putText(src, coco_labels[label].c_str(), box.tl() + (box.br() - box.tl()) / 2, cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
其中Mask部分的时候有个技巧的地方,首先获取类别,然后根据类别,直接获取Mask中对应的通道数据生成二值Mask图像,添加上颜色,加权混合到ROI区域即可得到输出结果。
责任编辑:lq6
-
图像
+关注
关注
2文章
1091浏览量
40732
原文标题:OpenVINO™ 实现图像实例分割
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
分布式存储有哪几种类型?
常见的有源变压器有哪几种?
卡尔曼滤波在图像处理中的应用实例 如何调优卡尔曼滤波参数
语义分割25种损失函数综述和展望

画面分割器怎么连接
图像语义分割的实用性是什么
图像分割与目标检测的区别是什么
图像识别算法有哪几种
图像分割与语义分割中的CNN模型综述
机器人视觉技术中常见的图像分割方法
机器人视觉技术中图像分割方法有哪些
断路器有哪几种
STM32单片机有哪几种常见的开发环境?

常见的医学图像读取方式和预处理方法





 工商网监
工商网监
评论