 图像处理硬件加速引擎是什么 如何提高CPU芯片性能
图像处理硬件加速引擎是什么 如何提高CPU芯片性能
什么是硬件加速引擎?
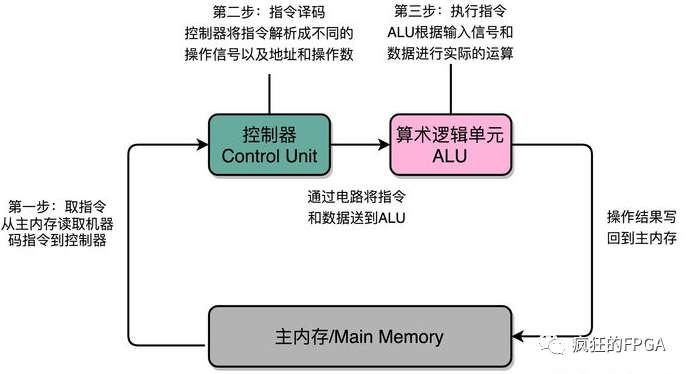
软件在CPU上执行,首先是从控制器从存储器取指(Fetch),接着控制器进行译码(Decode),然后由算数逻辑单元(ALU)执行指令(Execute),这就是指令周期,如下图所示。因此CPU每执行一个运算,都是一个流水线式调用计算的过程。普通计算机用指令运算速度衡量计算性能,而超算通常用浮点运算速度来衡量其性能。但不管是指令运算还是浮点运算,在CPU上都是线程的运算,并且要耗费n个指令周期。线程的机制决定了运算只能按部就班,执行完当前的操作才能进行下一个,所以经常电脑会卡住,因为性能不足以快速执行当前的运算。
想要提高CPU芯片性能,最简单粗暴的办法:要么提升主频,要么增加核数:
1)提高主频:当前流片的制程限制了主频,我们一直徘徊在3-5GHz,且进一步提高主频,功耗和散热也是很大的问题。
2)增加核数:无限制的增加核数是一种非常笨拙的办法 ,并且软件不好优化,同时又受面积、功耗、散热、成本的制约,芯片良品率也将会进一步降低。
除非是云服务器类芯片等以为追求性能为目标,对能耗比不敏感的芯片,否则消费类芯片核心竞争力仍以能耗比和性价比为主。这意味着随着摩尔定律的终结,我们很难再从通用CPU榨出更多的性能,那么架构的演进也许才能突破限制——采用硬件加速器引擎(协处理器),比如采用GPU/DSP/DPU等专用处理单元加速器来完成特定的功能,提升处理的效率。
典型的在2020.11.11,apple在WWDC上发布了采用自研SOC的全芯Macbook系列产品,使用的就是最新自研的号称地表最强的M1芯片。该芯片采用了apple的手机SOC架构,由TSMC最新5nm制程工艺代工,集成了8个CPU,8个GPU(128个执行单元,可同时执行24576个线程,运算能力高达2.6TFLOPS),以及16核的神经网络加速引擎Neural Engine(即上述所谓DPU,每秒可进行11万亿次操作),硬件编解码核(硬件完成AVS、264/5等制式视频的编解码)。
这款地表最强的SOC,在同等功耗下,号称达到了2倍目前最快的CPU性能,再次刷新了数据。这里的GPU与Neural Engine,硬件编解码核等,这就我们所谓的硬件加速器。芯片充分利用硬件加速引擎,有效缓解了CPU线程运算的压力。GPU是专用的图形处理单元,Neural Engine是专用的卷积神经网络计算单元,硬件编解码是专用的视频编解码处理单元,三者异曲同工,无非就是将原本要用CPU计算的卷积/浮点运算进行了硬化,采用门电路进行并行加速运算,而非传统CPU的指令运算流程。
文章出处:【微信公众号:FPGA自习室】
责任编辑:gt
-
控制器
+关注
关注
112文章
16332浏览量
177806 -
cpu
+关注
关注
68文章
10854浏览量
211578 -
引擎
+关注
关注
1文章
361浏览量
22546
原文标题:图像处理硬件加速引擎——不断突破限制(上)
文章出处:【微信号:FPGA_Study,微信公众号:FPGA自习室】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于 DSP5509 进行数字图像处理中 Sobel 算子边缘检测的硬件连接电路图
适用于数据中心应用中的硬件加速器的直流/直流转换器解决方案

图形图像硬件加速器卡设计原理图:270-VC709E 基于FMC接口的Virtex7 XC7VX690T PCIeX8 接口卡
基于FPGA的图像采集与显示系统设计
工业级HMI芯片Model3芯片详解(二)图像显示

PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
基于FPGA的实时边缘检测系统设计,Sobel图像边缘检测,FPGA图像处理
新思科技硬件加速解决方案技术日在成都和西安站成功举办
Elektrobit利用其首创的硬件加速软件优化汽车通信网络的性能

330-基于FMC接口的Kintex-7 XC7K325T PCIeX4 3U PXIe接口卡 图形图像硬件加速器
【国产FPGA+OMAPL138开发板体验】(原创)7.硬件加速Sora文生视频源代码
音视频解码器硬件加速:实现更流畅的播放效果






 工商网监
工商网监
评论