 存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
比如在有线连接的VR应用中,图形需要经过电脑进行处理,再经有线传输显示在VR屏幕上,这就引发了高延迟和长读取时间等问题。这不禁让人开始遐想,在CPU、GPU和存储都已经革新换代的情况下,我们是否真正有效地应用了硬件性能?为此微软和英伟达都提出了直接存储的概念来改善IO的现状。
微软:Windows上的DirectStorage
微软在不久前的Windows 11发布会上重点提到了DirectStorage技术,这是一个最初为主机设计的DirectX API,如今微软也将把这一技术带到PC上。
在当前NVMe SSD和PCIe技术的演进下,存储带宽远超旧式的硬盘存储技术,过去10MB每秒的速度已经达到数GB每秒。但PC上的图形工作量也在逐步进化,数据量的增加对于读取提出了更高的要求。过去大量数据的读取只需要少量的IO请求,但如今的图形渲染会将材质等资源分成小块,只有在场景提出要求时载入所需的部分,如此一来虽然提高了效率,却引入了更多IO请求。

当前的GPU资源读取流程 / 微软
而目前的存储API并没有对大量IO请求作出优化,因此拖累了NVMe,使得读写瓶颈愈发明显。即便采用高端的PC硬件,也无法饱和利用存储带宽优势。除此之外,这些数据往往需要经过压缩传输下一个环节,传入内存后,还要CPU进行一部分解压工作,最后再传入GPU显存里,这样一来每个节点都存在效率损失。
而DirectStorage采用了全新的路径,从存储读取的数据传给内存后,直接传给GPU显存。而GPU对于这些数据的解压速度远快于CPU,所以极大地优化了IO性能。
英伟达:RTX IO和Magnum IO GPUDirect Storage
英伟达在RTX 30系列显卡上引入了RTX IO,面向消费市场,提升游戏场景下的读取速度。英伟达称RTX IO将与微软的DirectStorage结合,与传统硬盘下的存储API相比,可将IO性能提高百倍。过去需要数十个CPU内核的工作全部交由RTX GPU来处理。
值得一提的是,英伟达的RTX IO虽然也用到了微软的DirectStorage,但该技术并没有将数据传输到内存,而是直接由SSD转向GPU。微软一名图形开发者在GSL 2021大会上表示,未来DirectStorage的目标也是绕过系统内存。
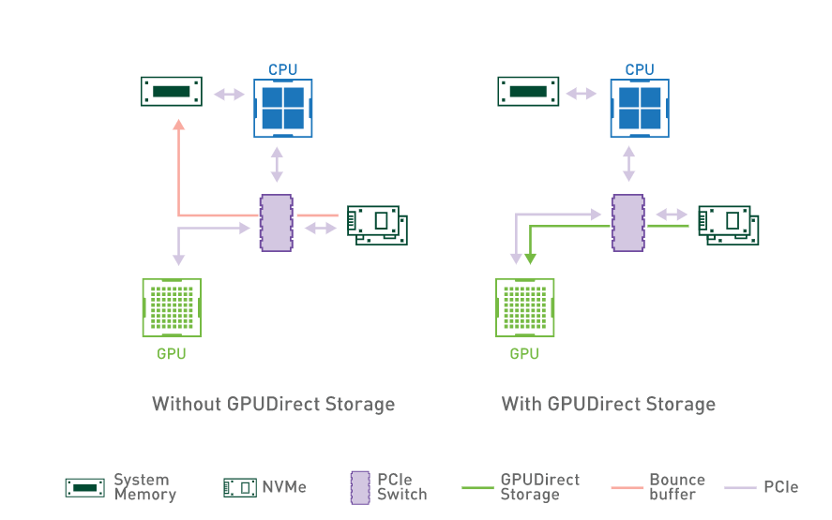
GDS技术 / 英伟达
除了消费市场外,英伟达在HPC市场也推出了对应的直接存储技术,Magnum IO GPUDirect Storage(GDS)。GDS技术同样是一个绕过CPU的技术,与消费级GPU不同,HPC场景下往往要用到多块GPU,如此一来受IO延迟和CPU的影响更大。GDS在本地存储与GPU显存之间建立直接的数据通道,消除了CPU引入的延迟和读写瓶颈。
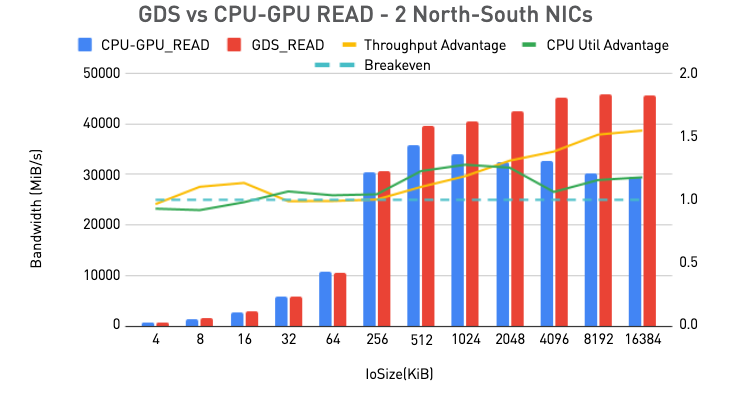
GDS与CPU传输至GPU读取性能对比 / 英伟达
在运用GDS后,带宽提升达到1.5倍,与传统CPU回弹缓冲的数据路径相比,CPU利用率也有2.8倍的提升。
目前英伟达已经将这一技术加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已经开始了相关产品的量产,而IBM、美光等五家厂商也在积极引入这一技术。三星、铠侠、西数和戴尔等厂商也开始了GDS的早期集成与认证计划。
小结
直接存储技术进一步放大了GPU厂商与存储厂商的优势,目前HPC市场前景巨大,英伟达在相关业务上的盈利已经让其看到了商机。不仅是GPU,英伟达采用Arm架构的Grace CPU同样引入了NVLink这样的数据传输改善方案。在这样的性能改善下,即便存储方案不同,英伟达的GPU也很可能成为HPC应用的首选。
伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
比如在有线连接的VR应用中,图形需要经过电脑进行处理,再经有线传输显示在VR屏幕上,这就引发了高延迟和长读取时间等问题。这不禁让人开始遐想,在CPU、GPU和存储都已经革新换代的情况下,我们是否真正有效地应用了硬件性能?为此微软和英伟达都提出了直接存储的概念来改善IO的现状。
微软:Windows上的DirectStorage
微软在不久前的Windows 11发布会上重点提到了DirectStorage技术,这是一个最初为主机设计的DirectX API,如今微软也将把这一技术带到PC上。
在当前NVMe SSD和PCIe技术的演进下,存储带宽远超旧式的硬盘存储技术,过去10MB每秒的速度已经达到数GB每秒。但PC上的图形工作量也在逐步进化,数据量的增加对于读取提出了更高的要求。过去大量数据的读取只需要少量的IO请求,但如今的图形渲染会将材质等资源分成小块,只有在场景提出要求时载入所需的部分,如此一来虽然提高了效率,却引入了更多IO请求。
当前的GPU资源读取流程 / 微软
而目前的存储API并没有对大量IO请求作出优化,因此拖累了NVMe,使得读写瓶颈愈发明显。即便采用高端的PC硬件,也无法饱和利用存储带宽优势。除此之外,这些数据往往需要经过压缩传输下一个环节,传入内存后,还要CPU进行一部分解压工作,最后再传入GPU显存里,这样一来每个节点都存在效率损失。
而DirectStorage采用了全新的路径,从存储读取的数据传给内存后,直接传给GPU显存。而GPU对于这些数据的解压速度远快于CPU,所以极大地优化了IO性能。
英伟达:RTX IO和Magnum IO GPUDirect Storage
英伟达在RTX 30系列显卡上引入了RTX IO,面向消费市场,提升游戏场景下的读取速度。英伟达称RTX IO将与微软的DirectStorage结合,与传统硬盘下的存储API相比,可将IO性能提高百倍。过去需要数十个CPU内核的工作全部交由RTX GPU来处理。
值得一提的是,英伟达的RTX IO虽然也用到了微软的DirectStorage,但该技术并没有将数据传输到内存,而是直接由SSD转向GPU。微软一名图形开发者在GSL 2021大会上表示,未来DirectStorage的目标也是绕过系统内存。
GDS技术 / 英伟达
除了消费市场外,英伟达在HPC市场也推出了对应的直接存储技术,Magnum IO GPUDirect Storage(GDS)。GDS技术同样是一个绕过CPU的技术,与消费级GPU不同,HPC场景下往往要用到多块GPU,如此一来受IO延迟和CPU的影响更大。GDS在本地存储与GPU显存之间建立直接的数据通道,消除了CPU引入的延迟和读写瓶颈。
GDS与CPU传输至GPU读取性能对比 / 英伟达
在运用GDS后,带宽提升达到1.5倍,与传统CPU回弹缓冲的数据路径相比,CPU利用率也有2.8倍的提升。
目前英伟达已经将这一技术加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已经开始了相关产品的量产,而IBM、美光等五家厂商也在积极引入这一技术。三星、铠侠、西数和戴尔等厂商也开始了GDS的早期集成与认证计划。
小结
直接存储技术进一步放大了GPU厂商与存储厂商的优势,目前HPC市场前景巨大,英伟达在相关业务上的盈利已经让其看到了商机。不仅是GPU,英伟达采用Arm架构的Grace CPU同样引入了NVLink这样的数据传输改善方案。在这样的性能改善下,即便存储方案不同,英伟达的GPU也很可能成为HPC应用的首选。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
微软
+关注
关注
4文章
6642浏览量
104793 -
gpu
+关注
关注
28文章
4828浏览量
129728 -
HPC
+关注
关注
0文章
328浏览量
23926 -
英伟达
+关注
关注
22文章
3872浏览量
92403
发布评论请先 登录
相关推荐
2024年GPU出货量增长显著,超越CPU
近日,根据知名市场研究机构Jon Peddie Research(JPR)最新发布的报告,2024年全球GPU(包括集成显卡和独立显卡)市场呈现出强劲的增长态势。报告显示,该年度GPU总出货量实现了
λ-IO:存储计算下的IO栈设计
动机和背景 存储计算存储资源的充分利用。IO栈是管理存储器的的基本组件,包括设备驱动、块接口层、文件系统,目前一些用户空间IO库(如S

GPU在虚拟现实中的表现 低功耗GPU的优缺点
GPU在虚拟现实中的表现 虚拟现实(VR)技术的发展离不开高性能的图形处理单元(GPU)。GPU在VR中扮演着至关重要的角色,它负责渲染复杂
NPU与GPU的性能对比
NPU(Neural Processing Unit,神经网络处理单元)与GPU(Graphics Processing Unit,图形处理单元)在性能上各有千秋,它们各自的设计初衷和优化方向决定了
DM6446+TLV320AIC33录音功能不好,表现为能听到录制的声音,但声音小,是哪里出了问题?
我现在平台是DM6446+TLV320AIC33,用来实现录音和播放功能,输入为麦克风,输出为耳机。现在播放功能是正常额,在耳机里能清楚地听到播放的wav文件,问题是录音功能不好,表现为能听到录制的声音,但声音小。请教大家有可能是哪里出了问题?
发表于 11-08 07:38
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片GPU
本篇阅读学习第七、八章,了解GPU架构演进及CPGPU存储体系与线程管理
█从图形到计算的GPU架构演进
GPU图像计算发展
●从三角形开始的几何阶段
在现代图形渲染中,三角形是最常用
发表于 11-03 12:55
如何提高GPU性能
在当今这个视觉至上的时代,GPU(图形处理单元)的性能对于游戏玩家、图形设计师、视频编辑者以及任何需要进行高强度图形处理的用户来说至关重要。GPU不仅是游戏和多媒体应用的心脏,它还在科学计算、深度
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
经典 GPU 算力芯片解读
10.1 NVIDIAGPU芯片
10.2 AMDGPU芯片
10.3 IntelXeGPU架构
10.3.4 超大芯片Ponte Vecchio
第11章 存储与互连总线
发表于 10-15 22:08
TLV320AIC3100IRHBR的MIC接口功能异常,主要表现为MIC管脚对GND的阻抗非常低,为什么?
TLV320AIC3100IRHBR的MIC接口功能异常,主要表现为MIC管脚对GND的阻抗非常低,一般这个是由什么原因造成的?
发表于 10-15 07:12
韩企存储芯片在华热销,营收翻倍增长
2024年上半年,韩国存储芯片巨头三星电子与SK海力士在中国市场的表现极为亮眼,营收均实现了超过100%的显著增长。这一骄人成绩主要得益于全球存储芯片市场需求的强劲复苏以及产品价格的持
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
设计。在GPU和NPU等加速器部分,介绍了GPU为何能从单纯的图形任务处理器变成通用处理器。GPU在设计逻辑、存储体系、线程管理,以及面向A
发表于 09-02 10:09
为什么倍压整流电路输出电流不随倍压倍数增加而成倍增加?
倍压整流电路是一种特殊的电源电路,它能够将输入的低电压交流信号转换为高电压直流信号,但其输出电流并不随倍压倍数的增加而成倍增加。
全方位性能对比 | 远距离Wi-Fi VS 传统Wi-Fi
应用。然而在物联网设备成倍增长的今天,更多的应用场景对通信的连接距离、功耗、穿透性、接入量方面有了更高的要求,需要一种更符合场景需要的可靠通信方式来保持联通。自连远距






 工商网监
工商网监
评论