 memory compaction如何实现及原理分析
memory compaction如何实现及原理分析
作者简介
赵金生,linux内核爱好者,就职于杭州某大型安防公司,担任Linux BSP软件工程师。对进程调度,内存管理有所了解。希望能通过对linux的学习,提升产品软件性能及稳定性。该文章为私人学习总结,不存在公司网络安全问题。
一
随着系统的运行,经过不同用户的分配请求后,页框会变得十分分散,导致此段页框被这些正在使用的零散页框分为一小段一小段非连续页框,这使得在需要分配内存时很难找到物理上连续的页框。
现代处理器不再限于使用传统的4K大小的页框;它们可以在进程的部分地址空间中支持大得多的页(huge pages)。使用巨页会带来真正的性能优势,主要原因是减小了对处理器的转换后备缓冲区(translation lookaside buffer)的压力。但是使用巨页要求系统能够找到物理上连续的内存区域,这些区域不仅要足够大,而且还必须确保按适当方式满足字节对齐的要求。
在一个已经运行了一段时间的系统上会产生大量的不连续的page, 要想找到符合这些高阶(high-order)条件的内存空间非常具有挑战性,memory compaction的作用就是解决high-order内存分配失败问题,与buddy system机制做一个互补。
二
memory compaction原理
内存碎片整理以pageblock为单位。
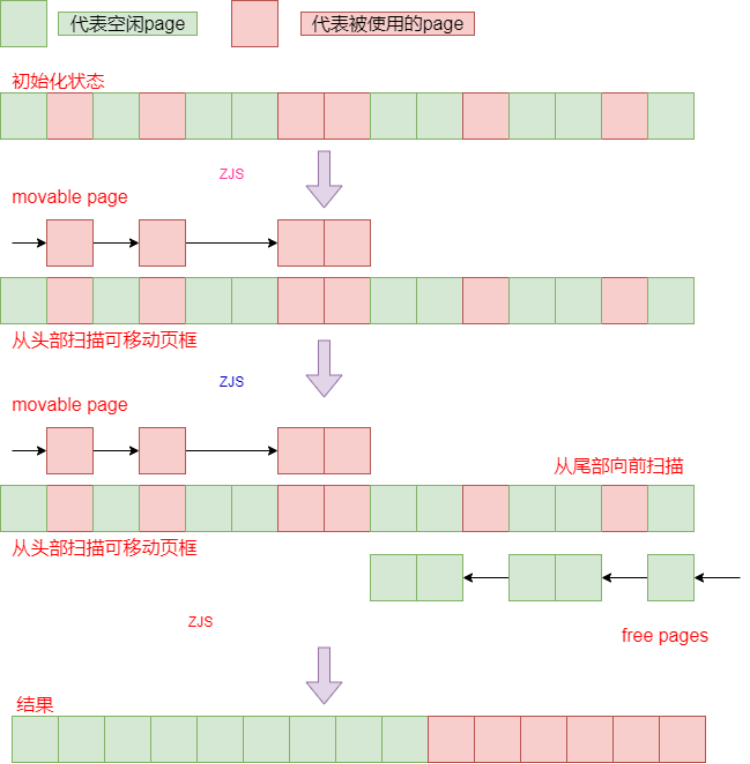
在内存碎片整理开始前,会在zone的头和尾各设置一个指针,头指针从头向尾扫描可移动的页,而尾指针从尾向头扫描空闲的页,当他们相遇时终止整理。
简单示意图:需要明确的是:实际情况并不是与图示的情况完全一致。头指针每次扫描一个符合要求的pageblock里的所有页框,当pageblock不为MIGRATE_MOVABLE、MIGRATE_CMA、MIGRATE_RECLAIMABLE时会跳过这些pageblock,当扫描完这个pageblock后有可移动的页框时,会变为尾指针以pageblock为单位向前扫描可移动页框数量的空闲页框,但是在pageblock中也是从开始页框向结束页框进行扫描,最后会将前面的页框内容复制到这些空闲页框中。
这里的移动是将页框中的数据copy拷贝到可移动的空闲页框当中,此时原有的movable page变成free page。所以并不是页框自身的移动而是数据的移动。
通过下图的操作就可以分配出一个order = 2或者是order = 3的连续的可用空间,可用于满足更high-order的内存分配。当然,这里展示的流程和真实系统比起来已经大大简化了。实际的内存域会大得多,这意味着扫描的工作量也会大很多,但由此获得的空闲区也可能更大。
实际的内存碎片,还有一个问题就是在整理算法中会将扫描中识别为不满足整理要求的内存块标识为 “可忽略”(“skip”,即不执行规整)。作为一种优化,目的是防止运行没必要的规整操作。
比如系统正在对zone进行内存碎片整理,首先,会从可移动页框开始位置向后扫描一个pageblock,得到一些可移动页框,然后空闲页框从开始位置向前扫描一个pageblock,得到一些空闲页框,然后将可移动页框移动到空闲页框中,之后再继续循环扫描。对一个pageblock进行扫描后,如果无法从此pageblock隔离出一个要求的页框,这时候就会将此pageblock标记为跳过(skip)。
假设内存碎片整理可移动页扫描是从zone的第一个页框开始,扫描完一个pageblock后,没有隔离出可移动页框,则标记此pageblock的跳过标记PB_migrate_skip,然后将zone-》compact_cached_migrate_pfn设置为此pageblock的结束页框。
这样,在下次对此zone进行内存碎片整理时,就会直接从此pageblock的下一个pageblock开始,把此pageblock跳过了。同理,对于空闲页扫描也是一样。这样就必须更新zone pageblock的起始地址与结束地址:
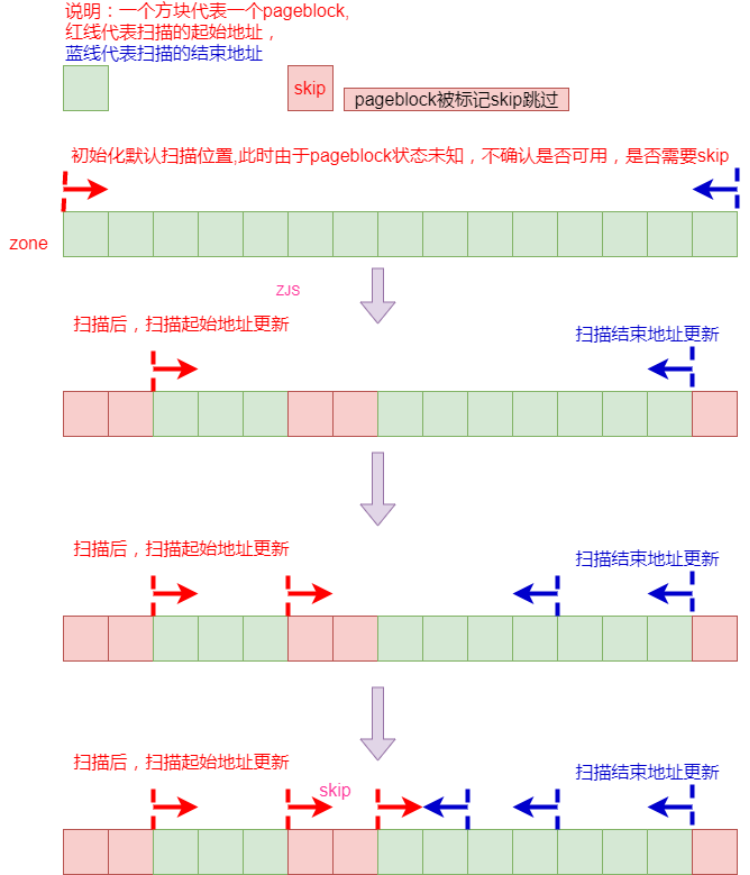
以上就是内存碎片整理的基本原理了。
三
memory compaction如何实现
3.1、数据结构
在内存碎片整理中,可以移动的页框有MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE与MIGRATE_CMA这三种类型的页框。
而因为内存碎片整理分为同步和异步。在异步过程中,只会移动MIGRATE_MOVABLE和MIGRATE_CMA这两种类型的页框。因为这两种类型的页框处理,是不会涉及到IO操作的。而在同步过程中,这三种类型的页框都会进行移动,因为MIGRATE_RECLAIMABLE基本上都是文件页,在移动过程中,有可能要将脏页回写,会涉及到IO操作,也就是在同步过程中,是会涉及到IO操作的。
1、migrate_mode迁移模式:
enum migrate_mode { MIGRATE_ASYNC, MIGRATE_SYNC_LIGHT, MIGRATE_SYNC,};
2、compact_priority
enum compact_priority { COMPACT_PRIO_SYNC_FULL, MIN_COMPACT_PRIORITY = COMPACT_PRIO_SYNC_FULL, COMPACT_PRIO_SYNC_LIGHT, MIN_COMPACT_COSTLY_PRIORITY = COMPACT_PRIO_SYNC_LIGHT, DEF_COMPACT_PRIORITY = COMPACT_PRIO_SYNC_LIGHT, COMPACT_PRIO_ASYNC, INIT_COMPACT_PRIORITY = COMPACT_PRIO_ASYNC};
3、compact_result用于压缩处理函数的返回值
enum compact_result { /* For more detailed tracepoint output - internal to compaction */ COMPACT_NOT_SUITABLE_ZONE,//trace用于调试输出或内部使用 /* * compaction didn‘t start as it was not possible or direct reclaim * was more suitable */ COMPACT_SKIPPED,//跳过压缩,因为无法执行压缩或直接回收更合适 /* compaction didn’t start as it was deferred due to past failures */ COMPACT_DEFERRED,
/* compaction not active last round */ COMPACT_INACTIVE = COMPACT_DEFERRED,
/* For more detailed tracepoint output - internal to compaction */ COMPACT_NO_SUITABLE_PAGE, /* compaction should continue to another pageblock */ COMPACT_CONTINUE,
/* * The full zone was compacted scanned but wasn‘t successfull to compact * suitable pages. */ COMPACT_COMPLETE,//已完成所有区域的压缩,但是尚未确保可以通过压缩分配的页面 /* * direct compaction has scanned part of the zone but wasn’t successfull * to compact suitable pages. */ COMPACT_PARTIAL_SKIPPED,
/* compaction terminated prematurely due to lock contentions */ COMPACT_CONTENDED,
/* * direct compaction terminated after concluding that the allocation * should now succeed */ COMPACT_SUCCESS,//在确保可分配页面安全后,直接压缩结束};
4、compact_control需要进行内存碎片整理时,总是需要初始化该结构体
struct compact_control { /* 扫描到的空闲页的页的链表 */ struct list_head freepages; /* List of free pages to migrate to */ /* 扫描到的可移动的页的链表 */ struct list_head migratepages; /* List of pages being migrated */ /* 空闲页链表中的页数量 */ unsigned long nr_freepages; /* Number of isolated free pages */ /* 可移动页链表中的页数量 */ unsigned long nr_migratepages; /* Number of pages to migrate */ /* 空闲页框扫描所在页框号 */ unsigned long free_pfn; /* isolate_freepages search base */ /* 可移动页框扫描所在页框号 */ unsigned long migrate_pfn; /* isolate_migratepages search base */ /* 内存碎片整理使用的模式: 同步,轻同步,异步 */ enum migrate_mode mode; /* Async or sync migration mode */ /* 是否忽略pageblock的PB_migrate_skip标志对需要跳过的pageblock进行扫描 ,并且也不会对pageblock设置跳过 * 只有两种情况会使用 * 1.调用alloc_contig_range()尝试分配一段指定了开始页框号和结束页框号的连续页框时; * 2.通过写入1到sysfs中的/vm/compact_memory文件手动实现同步内存碎片整理。 */ bool ignore_skip_hint; /* Scan blocks even if marked skip */ /* 本次内存碎片整理是否隔离到了空闲页框,会影响zone的空闲页扫描起始位置 */ bool finished_update_free; /* True when the zone cached pfns are * no longer being updated */ /* 本次内存碎片整理是否隔离到了可移动页框,会影响zone的可移动页扫描起始位置 */ bool finished_update_migrate; /* 申请内存时需要的页框的order值 */ int order; /* order a direct compactor needs */ const gfp_t gfp_mask; /* gfp mask of a direct compactor */ /* 扫描的管理区 */ struct zone *zone; /* 保存结果,比如异步模式下是否因为需要阻塞而结束了本次内存碎片整理 */ int contended; /* Signal need_sched() or lock * contention detected during * compaction */};
5、Node zone 扫描推迟
struct zone{ 。。。。。 unsigned int compact_considered; unsigned int compact_defer_shift; int compact_order_failed; 。。。。。。}
当一个zone要进行内存碎片整理时,首先会判断本次整理需不需要推迟,如果本次内存碎片整理使用的order值小于zone内存碎片整理失败最大order值compact_order_failed时,不用进行推迟,可以直接进行内存碎片整理;
当order值大于zone内存碎片整理失败最大order值compact_order_failed,会增加内存碎片整理推迟计数器compact_considered,如果内存碎片整理推迟计数器compact_considered未达到内存碎片整理推迟阀值defer_limit,则会跳过本次内存碎片整理,如果达到了,那就需要进行内存碎片整理。
总结:也就是当order小于zone内存碎片整理失败最大order值时,不用进行推迟,而order大于zone内存碎片整理失败最大order值时,才考虑是否进行推迟,此时推迟就是continue扫描node当中的下一个zone区域,这里并不是想下文一下设置zone SKIP标志。
6、Pageblock skip
struct zone{ 。。。。。。 unsigned long compact_cached_free_pfn; /* pfn where async and sync compaction migration scanner should start */ unsigned long compact_cached_migrate_pfn[2];
。。。。。。}
3.2、源码分析
内存碎片整理移动发生条件:
内存分配不足时触发direct compact整理内存
Kswapd内存回收后唤醒kcompactd内核线程执行compact操作,获取连续内存
手动设置echo 1 》 /proc/sys/vm/compact_memory
分析的重点就放在内存分配不足的情况,入口函数从try_to_compact_pages开始
对源码详细分析参见代码:https://github.com/linuxzjs/linux-4.14
重点分析5个关键函数:
1、compaction_suitable
/* 判断该zone是否可以做内存碎片压缩整理 */enum compact_result compaction_suitable(struct zone *zone, int order, unsigned int alloc_flags, int classzone_idx){ enum compact_result ret; int fragindex; /* * 根据watermask判断zone中离散的page是否满足2^order的内存分配请求。
如果满足则继续对zone进行内存的compact整理zone的内存碎片 * 说明该zone时可以做内存碎片的压缩整理的。 */ ret = __compaction_suitable(zone, order, alloc_flags, classzone_idx,zone_page_state(zone, NR_FREE_PAGES));
/* 如果return返回值为COMPACT_CONTINUE,且order 》 PAGE_ALLOC_COSTLY_ORDER(3)则进入一下判断当中 */ if (ret == COMPACT_CONTINUE && (order 》 PAGE_ALLOC_COSTLY_ORDER)) { /* * 为了确定zone区域是否执行压缩,找到所请求区域zone和顺序的碎片系数。
* 如果碎片系数值返回-1000,则存在要分配的页面,因此不需要压缩。 * 在其他情况下,该值在0到500的范围内,并且如果它小于sysctl_extfrag_threshold,则直接return COMPACT_NOT_SUITABLE_ZONE不执行压缩 */ fragindex = fragmentation_index(zone, order); if (fragindex 》= 0 && fragindex 《= sysctl_extfrag_threshold) ret = COMPACT_NOT_SUITABLE_ZONE; }。。。。。 return ret;}
由此可以知道,判断是否执行内存的碎片整理,需要满足以下三个条件:在__compaction_suitable当中可以得出:
减去申请的页面,空闲页面数将低于水印值;或者虽然大于等于水印值,但是没有一个足够大的连续的空闲页块;
空闲页面减去两倍的申请页面,高于水印值;在fragmentation_index中:
申请的order大于PAGE_ALLOC_COSTLY_ORDER时,计算碎片指数fragindex来判断;
2、compact_finished
通过该函数判断zone区域碎片整理compact是否完成
static enum compact_result __compact_finished(struct zone *zone,struct compact_control *cc){ unsigned int order; /* 获取zone的移动类型 */const int migratetype = cc-》migratetype;。。。。。 /* Compaction run completes if the migrate and free scanner meet */ /* 当cc-》free_pfn 《= cc-》migrate_pfn空闲扫描于可移动页面扫描相遇则说明zone碎片扫描压缩完成 */ if (compact_scanners_met(cc)) { /* Let the next compaction start anew. */ /* 重置压缩扫描起始地址于结束地址的位置 */ reset_cached_positions(zone);
/* 如果是直接压缩模式则设置compact_blockskip_flush = true,清除PG_migrate_skip的skip属性 */ if (cc-》direct_compaction) zone-》compact_blockskip_flush = true; /* * 如果whole_zone = 1说明zone是从头开始扫描,扫描zone整个区域 return COMPACT_COMPLETE,表示zone扫描完成 * 如果whole_zone = 0说明zone是从局部开始扫描的,也就是在zone的更新的free_page或者是migrate_page当中扫描 * 也就是也就是局部的pageblock的扫描,return COMPACT_PARTIAL_SKIPPED表示跳过该pageblock,扫描下一个pageblock */ if (cc-》whole_zone)
return COMPACT_COMPLETE; else return COMPACT_PARTIAL_SKIPPED; } /* 执行压缩时,将返回COMPACT_CONTINUE以强制压缩整个块,这个于手动模式有关 * echo 1》 /proc/sys/vm/compact_memory */ if (is_via_compact_memory(cc-》order)) return COMPACT_CONTINUE; /* 如果扫描完成,则进入判断当中,做进一步判断验证 */if (cc-》finishing_block) { /* 再次检查迁移扫描程序与pageblock是否对齐,如果对齐则说明页面压缩已经完成重置cc-》finishing_block = false * 如果没有对齐则,并返回COMPACT_CONTINUE以继续扫描进行zone的页面扫描压缩操作 */ if (IS_ALIGNED(cc-》migrate_pfn, pageblock_nr_pages)) cc-》finishing_block = false; else return COMPACT_CONTINUE; }
/* Direct compactor: Is a suitable page free? */ /* * 从当前order开始扫描,order -》 MAX_ORDER进行, */ for (order = cc-》order; order 《 MAX_ORDER; order++) { /* 根据order获取free_area */ struct free_area *area = &zone-》free_area[order]; bool can_steal;
/* Job done if page is free of the right migratetype */ /* 如果该area-》free_list[migratetype])不为NULL,不为空则COMPACT_SUCCESS压缩扫描成功 */ if (!list_empty(&area-》free_list[migratetype])) return COMPACT_SUCCESS; /* 如果定义了CONFIG_CMA如果移动类型为MIGRATE_MOVABLE可移动类型,且area-》free_list[MIGRATE_CMA])不为空则return COMPACT_SUCCESS */#ifdef CONFIG_CMA /* MIGRATE_MOVABLE can fallback on MIGRATE_CMA */ if (migratetype == MIGRATE_MOVABLE && !list_empty(&area-》free_list[MIGRATE_CMA])) return COMPACT_SUCCESS;#endif /* 如果area-》free_list[migratetype]以及area-》free_list[MIGRATE_CMA])均为空则取对应的migratetype的fallback当中寻找合适可用的page * 判断是否能够完成页面的压缩。 */ if (find_suitable_fallback(area, order, migratetype, true, &can_steal) != -1) {
/* movable pages are OK in any pageblock */ /* 如果可移动类型为MIGRATE_MOVABLE则直接return COMPACT_SUCESS * 说明只要是可以移动的page都可用作页面压缩功能。 */ if (migratetype == MIGRATE_MOVABLE) return COMPACT_SUCCESS;
/* 如果正在执行aync异步压缩,或者如果迁移扫描程序已完成一页代码块,则返回COMPACT_SUCCESS */ if (cc-》mode == MIGRATE_ASYNC || IS_ALIGNED(cc-》migrate_pfn, pageblock_nr_pages)) { return COMPACT_SUCCESS; } /* 如果fallback当中没有找到合适可用的page则设置cc-》finishing_block = true;return COMPACT_CONTINUE zone还需要继续扫描, * skip到下一个pageblock或者是下一个zone */ cc-》finishing_block = true; return COMPACT_CONTINUE; } } /* 如果从order -》 max_order都没有找到可用的page用作直接的页面迁移压缩则return COMPACT_NO_SUITABLE_PAGE表明没有可用的页面用于压缩 */ return COMPACT_NO_SUITABLE_PAGE;}
3、isolate_migratepages
在zone当中以pageblock为单位,扫描找到migratepage可移动页,并将page添加struct compact_control *cc的migratepages链表当中,便于后边做页面内容的拷贝移动。其实隔离的作用就是将可移动页面拿出来,单独存放,与之前的pageblock分开
4、isolate_freepages
freepages的过程与migratepages的过程基本上是完全一致的,隔离结束的条件基本上也是一致的。
不同点就是freepage在找到pageblock的page进行isolate隔离操作前会判断这个page是如何组成的,是一个复合page还是非复合页,如果不是要获取这个page的order。
如果该page是由2^order个单独的page组合起来的还要将这个page拆分成单独的page也就是order = 0的这种情况,然后将单独的page移动到freepages链表上,并设置page新的类型为MIGRATE_MOVABLE供后续使用。
5、migrate_pages
当完成freepages、migratepages完成隔离后就调migrate_pages完成两个链表的页面迁移。
err = migrate_pages(&cc-》migratepages, compaction_alloc,
compaction_free, (unsigned long)cc, cc-》mode,
MR_COMPACTION);
compact_alloc函数,从zone区域当中扫描freepages并提填充到cc-》freepages链表当中,再从cc-》freepages链表中取出一个空闲页
static struct page *compaction_alloc(struct page *migratepage, unsigned long data, int **result){ struct compact_control *cc = (struct compact_control *)data; struct page *freepage;
/* * Isolate free pages if necessary, and if we are not aborting due to * contention. */ /* 如果cc中的空闲页框链表为空 */ if (list_empty(&cc-》freepages)) { if (!cc-》contended) isolate_freepages(cc);/* 从cc-》free_pfn开始向前获取空闲页 */
if (list_empty(&cc-》freepages)) return NULL; } /* 从cc-》freepages链表取出一个空闲的freepages */ freepage = list_entry(cc-》freepages.next, struct page, lru); /* 将该page从lru链表当中删除 */ list_del(&freepage-》lru); cc-》nr_freepages--; /* 返回空闲页框 */ return freepage;}static void compaction_free(struct page *page, unsigned long data){ struct compact_control *cc = (struct compact_control *)data;
list_add(&page-》lru, &cc-》freepages); cc-》nr_freepages++;}
这里先避开PageHuge不谈,migrate_pages通过调用unmap_and_move、__unmap_and_move、move_to_new_page、try_to_unmap完成页面最终的整理工作。这里面涉及的rmap反向映射这里不再展开。
四
memory compaction总结
分析过reclaim内存回收代码就会发现,在内存回收当中同样会wakeup_kcompactd触发compaction碎片整理机制,在kswpad异步内存回收当中存在同样的操作。
同时与kswapd机制类似目前内核在node节点当中也引入了kcompactd线程机制,定时的休眠唤醒该内核线程完成内存碎片的整理,在新的patch当中更是将kswapd与kcompactd结合起来共同完成内存碎片的整理。内存回收工作。
编辑:jq
-
Memory
+关注
关注
1文章
77浏览量
29016
原文标题:memory compaction原理、实现与分析
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
不同类型PROM器件的比较分析
EEPROM存储功能的实现方式
中低压开关柜如何实现健康分析

为什么有些TINA-TI仿真可以实现稳态求解法分析,而有些不行?
STM8S使用IAR编译时出现SWIM PROG error [4]: Memory write error的原因?
广告投放公司运用大数据分析,实现精准投放
stm32l476 QSPI如何退出 Memory_Mapped MODE?
罗彻斯特携手Intelligent Memory提供传统DRAM和NAND存储解决方案
CW32L052单片机支持DMA实现高速数据传输
超低功耗液晶显示屏-无需背光阳光下可视SHARP Memory LCD选型表
ADIS16227的FFT AVERAGING选择后,存储在FFT RECORDS—NONVOLATILE FLASH MEMORY中的数据是否有次数限制?
基于工业物联网的设备产能监控与分析系统如何实现






 工商网监
工商网监
评论