 聚焦IO,从存储的角度剖析vim原理
聚焦IO,从存储的角度剖析vim原理
故事起因
无意间用 vim 打开了一个 10 G 的文件,改了一行内容,:w 保存了一下,慢的我哟,耗费的时间够泡几杯茶了。这引起了我的好奇,vim 打开和保存究竟做了啥?
vim — 编辑器之神
vim 号称编辑器之神,以极其强大的扩展性和功能闻名。vi/vim 作为标准的编辑器存在于 Linux 的几乎每一种发行版里。vim 的学习曲线比较陡峭的,前期必须有一个磨炼的过程。
vim 是一个终端编辑器,在可视化的编辑器横行的今天,为什么 vim 还如此重要?
因为有些场景非它不可,比如线上服务器终端,除 vi/vim 这种终端编辑器,你别无选择。
vim 的历史很悠久,Github 有个文档归纳了 vim 的历史进程:vim 历史,Github 开源代码:代码仓库。
笔者今天不讲 vim 的用法,这种文章网上随便搜一大把。笔者将从 vim 的存储 IO 原理的角度来剖析下 vim 这个神器。
思考几个小问题,读者如果感兴趣,可以继续往下读哦:
vim 编辑文件的原理是啥,用了啥黑科技吗?
vim 打开一个 10G 的大型文件,为什么这么慢,里面做了啥?
vim 修改一个 10G 的大型文件,:w 保存的时候,感觉更慢了?为什么?
vim 好像会产生多余的文件?~ 文件 ?.swp 文件 ?都是做啥的呢?
划重点:由于 vim 的功能过于强大,一篇分享根本说不完,本篇文章聚焦 IO,从存储的角度剖析 vim 原理。
vim 的 io 原理
声明,系统和 Vim 版本如下:
操作系统版本:Ubuntu 16.04.6 LTSVIM 版本:VIM - Vi IMproved 8.2 (2019 Dec 12, compiled Jul 25 2021 0854)测试文件名:test.txt
vim 就是一个二进制程序而已。读者朋友也可以 Github 下载,编译,自己调试哦,效果更佳。
一般使用 vim 编辑文件很简单,只需要 vim 后面跟文件名即可:
vimtest.txt
这样就打开了文件,并且可以进行编辑。这个命令敲下去,一般情况下,我们就能很快在终端很看到文件的内容了。
这个过程发生了什么?先明确下,vim test.txt 到底是啥意思?
本质就是运行一个叫做 vim 的程序,argv[1] 参数是 test.txt 嘛。跟你以前写的 helloworld 程序没啥不一样,只不过 vim 这个程序可以终端人机交互。
所以这个过程无非就是一个进程初始化的过程,由 main 开始,到 main_loop(后台循环监听)。
1vim 进程初始化
vim 有一个 main.c 的入口文件,main 函数就定义在这里。首先会做一下操作系统相关的初始化( mch 是 machine 的缩写):
mch_early_init();
然后会,做一下赋值参数,全局变量的初始化:
/* *Variousinitialisationssharedwithtests. */ common_init(¶ms);
举个例子 test.txt 这样的参数必定要赋值到全局变量中,因为以后是要经常使用的。
另外类似于命令的 map 表,是静态定义好了的:
staticstructcmdname { char_u*cmd_name;//nameofthecommand ex_func_Tcmd_func;//functionforthiscommand long_ucmd_argt;//flagsdeclaredabove cmd_addr_Tcmd_addr_type;//flagforaddresstype }cmdnames[]={ EXCMD(CMD_write,"write",ex_write, EX_RANGE|EX_WHOLEFOLD|EX_BANG|EX_FILE1|EX_ARGOPT|EX_DFLALL|EX_TRLBAR|EX_CMDWIN|EX_LOCK_OK, ADDR_LINES), }
划重点::w,:write,:saveas 这样的 vim 命令,其实是对应到定义好的 c 回调函数:ex_write 。 ex_write 函数是数据写入的核心函数。再比如,:quit 对应 ex_quit ,用于退出的回调。
换句话说,vim 里面支持的类似 :w ,的命令,其实在初始化的时候就确定了。人为的交互只是输入字符串,vim 进程从终端读到字符串之后,找到对应的回调函数,执行即可。再来,会初始化一些 home 目录,当前目录等变量。
init_homedir();//findrealvalueof$HOME //保存交互参数 set_argv_var(paramp->argv,paramp->argc);
配置一下跟终端窗口显示相关的东西,这部分主要是一些终端库相关的:
//初始化终端一些配置 termcapinit(params.term);//setterminalnameandgetterminal //初始化光标位置 screen_start();//don'tknowwherecursorisnow //获取终端的一些信息 ui_get_shellsize();//initsRowsandColumns
再来会加载 .vimrc 这样的配置文件,让你的 vim 与众不同。
//Sourcestartupscripts. source_startup_scripts(¶ms);
还会加载一些 vim 插件 source_in_path ,使用 load_start_packages 加载 package 。
下面这个就是第一个交互了,等待用户敲下 enter 键:
wait_return(TRUE);
我们经常看见的:“Press ENTER or type command to continue“ 就是在这里执行的。确认完,就说明你真的是要打开文件,并显示到终端了。
怎么打开文件?怎么显示字符到终端屏幕?
这一切都来自于 create_windows 这个函数。名字也很好理解,就是初始化的时候创建终端窗口来着。
/* *Createtherequestednumberofwindowsandeditbuffersinthem. *Alsodoesrecoveryif"recoverymode"set. */ create_windows(¶ms);
这里其实涉及到两个方面:
把数据读出来,读到内存;
把字符渲染到终端;
怎么把数据从磁盘上读出来,就是 IO。怎么渲染到终端这个我们不管,这个使用的是 termlib 或者 ncurses 等终端编程库来实现的,感兴趣的可以了解下。
这个函数会调用到我们的第一个核心函数:open_buffer ,这个函数做两个时间:
create memfile:创建一个 memory + .swp 文件的抽象层,读写数据都会过这一层;
read file:读原始文件,并解码(用于显示到屏幕);
函数调用栈:
->readfile ->open_buffer ->create_windows ->vim_main2 ->main
真正干活的是 readfile 这个函数,吐槽一下,readfile 是一个 2533 行的函数。。。。。。
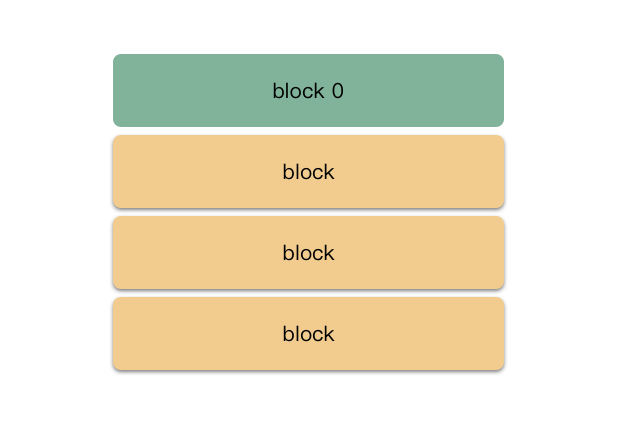
readfile 里面会择机创建 swp 文件(以前有的话,可以用于恢复数据),调用的是 ml_open_file 这个函数,文件创建好之后,size 占用 4k,里面主要是一些特定的元数据(用来恢复数据用的)。
划重点:.{文件名}.swp 这个隐藏文件是有格式的,前 4k 为 header,后面的内容也是按照一个个block 组织的。
再往后走,会调用到 read_eintr 这个函数,读取数据的内容:
long
read_eintr(intfd,void*buf,size_tbufsize)
{
longret;
for(;;){
ret=vim_read(fd,buf,bufsize);
if(ret>=0||errno!=EINTR)
break;
}
returnret;
}
这是一个最底层的函数,是系统调用 read 的一个封装,读出来之后。这里回答了一个关键问题:vim 的存储原理是啥?
划重点:本质上调用 read,write,lseek 这样朴素的系统调用,而已。
readfile 会把二进制的数据读出来,然后进行字符转变编码(按照配置的模式),编码不对就是乱码喽。每次都是按照一个固定 buffer 读数据的,比如 8192 。
划重点:readfile 会读完文件。这就是为什么当 vim 打开一个超大文件的时候,会非常慢的原因。
这里提一点题外话:memline 这个封装是文件之上的,vim 修改文件是修改到内存 buffer ,vim 按照策略来 sync memfile 到 swp 文件,一个是防止丢失未保存的数据,第二是为了节省内存。
mf_write 把内存数据写到文件。在 .test.txt.swp 中的就是这样的数据结构:
block 0 的 header 主要标识:
vim 的版本;
编辑文件的路径;
字符编码方式;
这里实现提一个重要知识点:swp 文件里存储的是 block,block 的管理是以一个树形结构进行管理的。block 有 3 种类型:
block0:头部 4k ,主要是存储一些文件的元数据,比如路径,编码模式,时间戳等等;
pointer block:树形内部节点;
data block:树形叶子节点,存储用户数据;
2敲下 :w 背后的原理
进程初始化我们讲完了,现在来看下 :w 触发的调用吧。用户敲下 :w 命令触发 ex_write 回调(初始化的时候配置好的)。所有的流程皆在 ex_write ,我们来看下这个函数做了什么。
先撇开代码实现来说,用户敲下 :w 命令其实只是想保存修改而已。
那么第一个问题?用户的修改在哪里?
在 memline 的封装,只要没执行过 :w 保存,那么用户的修改就没修改到原文件上(注意哦,没保存之前,一定没修改原文件哦),这时候,用户的修改可能在内存,也可能在 swp 文件。存储的数据结构为 block 。所以,:w 其实就是把 memline 里面的数据刷到用户文件而已。怎么刷?
重点步骤如下(以 test.txt 举例):
创建一个 backup 文件( test.txt~ ),把原文件拷贝出来;
把原文件 test.txt truancate 截断为 0,相当于清空原文件数据;
从 memline (内存 + .test.txt.swp)拷贝数据,重新写入原文件 test.txt;
删除备份文件 test.txt~;
以上就是 :w 做的所有事情了,下面我们看下代码。
触发的回调是 ex_write ,核心的函数是 buf_write ,这个函数 1987 行。
在这函数,会使用 mch_open 创建一个 backup 文件,名字后面带个 ~ ,比如 test.txt~ ,
bfd=mch_open((char*)backup
拿到 backup 文件的句柄,然后拷贝数据(就是一个循环喽), 每 8K 操作一次,从 test.txt 拷贝到 test.txt~ ,以做备份。
划重点:如果是 test.txt 是超大文件,那这里就慢了哦。
backup 循环如下:
//buf_write
while((write_info.bw_len=read_eintr(fd,copybuf,WRITEBUFSIZE))>0)
{
if(buf_write_bytes(&write_info)==FAIL)
//如果失败,则终止
//否则直到文件结束
}
}
我们看到,干活的是 buf_write_bytes ,这是 write_eintr 的封装函数,其实也就是系统调用 write 的函数,负责写入一个 buffer 的数据到磁盘文件。
longwrite_eintr(intfd,void*buf,size_tbufsize){
longret=0;
longwlen;
while(ret< (long)bufsize) {
// 封装的系统调用 write
wlen = vim_write(fd, (char *)buf + ret, bufsize - ret);
if (wlen < 0) {
if (errno != EINTR)
break;
} else
ret += wlen;
}
return ret;
}
backup 文件拷贝完成之后,就可以准备动原文件了。
思考:为什么要先文件备份呢?
留条后路呀,搞错了还有的恢复,这个才是真正的备份文件。
修改原文件之前的第一步,ftruncate 原文件到 0,然后,从 memline (内存 + swp)中拷贝数据,写回原文件。
划重点:这里又是一次文件拷贝,超大文件的时候,这里可能巨慢哦。
for(lnum=start;lnum<= end; ++lnum)
{
// 从 memline 中获取数据,返回一个内存 buffer( memline 其实就是内存和 swap 文件的一个封装)
ptr = ml_get_buf(buf, lnum, FALSE) - 1;
// 将这个内存 buffer 写到原文件
if (buf_write_bytes(&write_info) == FAIL)
{
end = 0; // write error: break loop
break;
}
// ...
}
划重点:vim 并不是调用 pwrite/pread 这样的调用来修改原文件,而是把整个文件清空之后,copy 的方式来更新文件。涨知识了。
这样就完成了文件的更新啦,最后只需要删掉 backup 文件即可。
//Removethebackupunless'backup'optionissetortherewasa //conversionerror. mch_remove(backup);
这个就是我们数据写入的完整流程啦。是不是没有你想的那么简单!
简单小结下:当修改了 test.txt 文件,调用 :w 写入保存数据的时候发生了什么?
人机交互,:w 触发调用 ex_write 回调函数,于 do_write -> buf_write 完成写入 ;
具体操作是:先备份一个 test.txt~ 文件出来(全拷贝);
接着,原文件 test.txt 截断为 0,从 memline( 即 内存最新数据 + .test.txt.swap 的封装)拷贝数据,写入 test.txt (全拷贝) ;
数据组织结构
之前讲的太细节,我们从数据组织的角度来解释下。vim 针对用户对文件的修改,在原文件之上,封装了两层抽象:memline,memfile 。分别对应文件 memline.c ,memfile.c 。
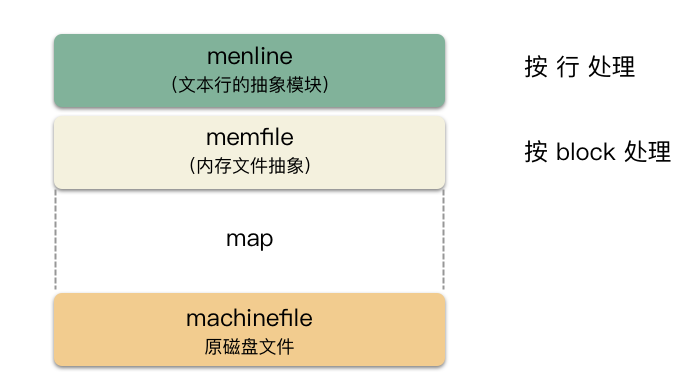
先说 memline 是啥?
对应到文本文件中的每一行,memline 是基于 memfile 的。
memline 基于 memfile,那 memfile 又是啥?
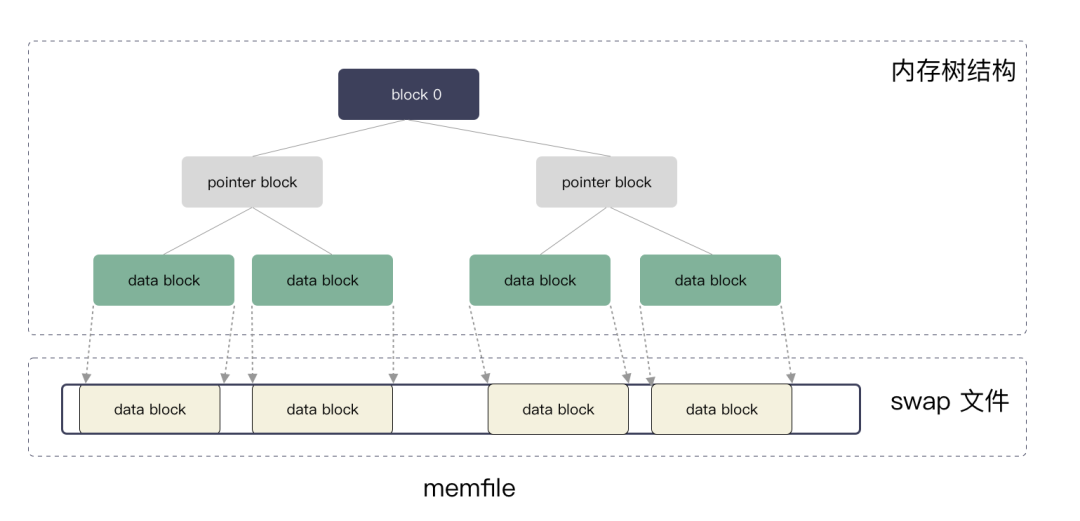
这个是一个虚拟内存空间的实现,vim 把整个文本文件映射到内存中,通过自己管理的方式。这里的单位为 block,memfile 用二叉树的方式管理 block 。block 不定长,block 由 page 组成,page 为定长 4k 大小。
这是一个典型虚拟内存的实现方案,编辑器的修改都体现为对 memfile 的修改,修改都是修改到 block 之上,这是一个线性空间,每个 block 对应到文件的要给位置,有 block number 编号,vim 通过策略会把 block 从内存中换出,写入到 swp 文件,从而节省内存。这就是 swap 文件的名字由来。
block 区分 3 种类型:
block 0 块:树的根,文件元数据;
pointer block:树的分支,指向下一个 block;
data block:树的叶子节点,存储用户数据;
swap 文件组织:
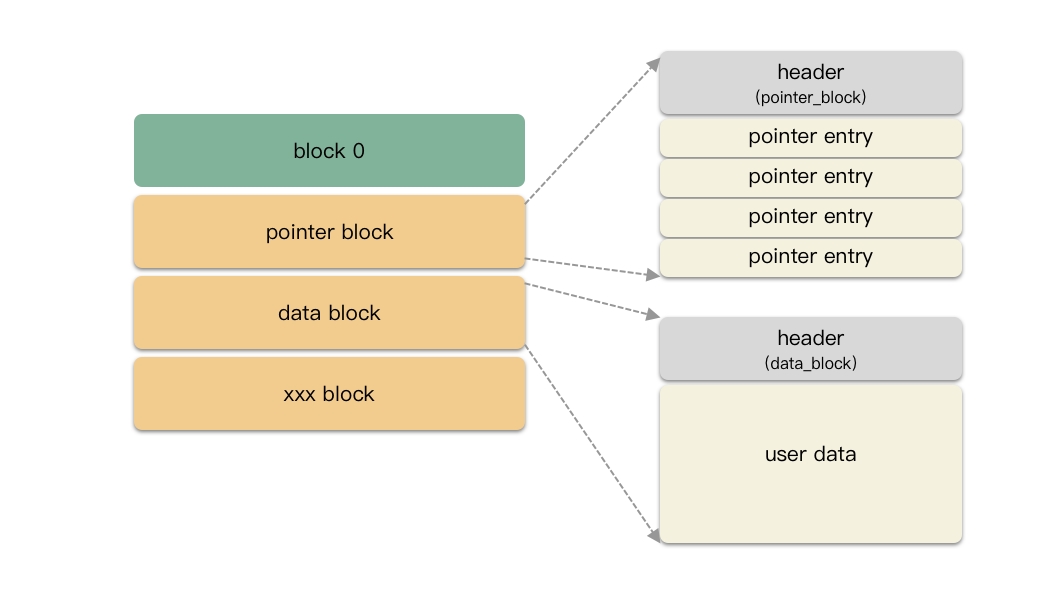
block 0 是特殊块,结构体占用 1024 个字节内存,写到文件是按照 1 个page 对齐的,所以是 4096 个字节。如下图:
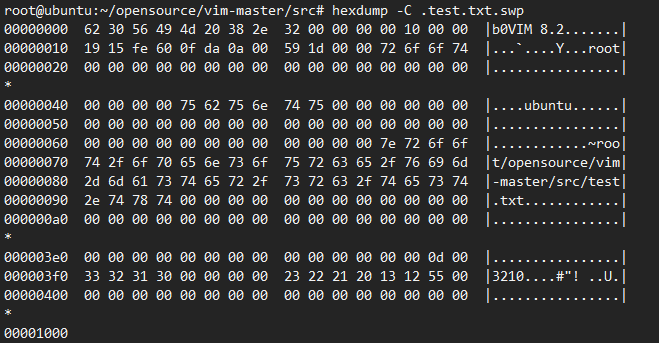
block 其他两种类型:
pointer 类型:这个是中间的分支节点,指向 block 的;
data 类型:这个是叶子节点;
#defineDATA_ID(('d'<< 8) + 'a') // data block id #define PTR_ID (('p' << 8) + 't') // pointer block id
这个 ID 相当于魔数,在 swp 文件中很容易识别出来,比如在下面的文件中第一个 4k 存储的是 block0,第二个 4k 存储的是 pointer 类型的 block。

第三,第四个 4k 存储的是一个 data 类型的 block ,里面存储了原文件数据。
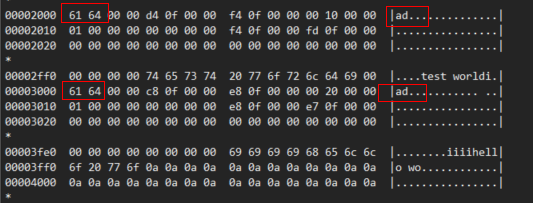
当用户修改一行的时候,对应到 memline 的一个 line 的修改,对应到这行 line 在哪个 block 的修改,从而定期的刷到 swap 文件。
vim 特殊的文件 ~ 和 .swp ?
假设原文件名称:test.txt 。
1test.txt~ 文件
test.txt~ 文件估计很多人都没见过,因为消失的太快了。这个文件在修改原文件之前生成,修改原文件之后删除。作用于只存在于 buf_write ,是为了安全备份的。
划重点:test.txt~ 和 test.txt 本质是一样的,没有其他特定格式,是用户数据。
读者朋友试试 vim 一个 10 G的文件,然后改一行内容,:w 保存,应该很容易发现这个文件(因为备份和回写时间巨长 )。
2.test.txt.swp 文件
这个文件估计绝大多数人都见过,.swp 文件生命周期存在于整个进程的生命周期,句柄是一直打开的。很多人认为 .test.txt.swp 是备份文件,其实准确来讲并不是备份文件,这是为了实现虚拟内存空间的交换文件,test.txt~ 才是真正的备份文件。swp 是 memfile 的一部分,前面 4k 为 header 元数据,后面的为 一个个 4k 的数据行封装。和用户数据并不完全对应。
memfile = 内存 + swp 才是最新的数据。
思考解答
1vim 存储原理是啥?
没啥,就是用的 read,write 这样的系统调用来读写数据而已。
2vim 的过程有两种冗余的文件?
test.txt~ :是真正的备份文件,诞生于修改原文件之前,消失于修改成功之后;.test.txt.swp :swap 文件,由 block 组成,里面可能由用户未保存的修改,等待:w 这种调用,就会覆盖到原文件;
3vim 编辑超大文件的时候为什么慢?
一般情况下,你能直观感受到,慢在两个地方:
vim 打开的时候;
修改了一行内容,:w 保存的时候;
先说第一个场景:vim 一个 10G 的文件,你的直观感受是啥?
我的直观感受是:命令敲下之后,可以去泡杯茶,等茶凉了一点,差不多就能看到界面了。为什么?
在进程初始化的时候,初始化窗口之前,create_windows -> open_buffer 里面调用 readfile 会把整个文件读一遍(完整的读一遍),在屏幕上展示编码过的字符。
划重点:初始化的时候,readfile 会把整个文件读一遍。 10 G的文件,你可想而知有多慢。我们可以算一下,按照单盘硬件 100 M/s 的带宽来算,也要 102 秒的时间。
再说第二个场景:喝了口茶,改了一个单词,:w 保存一下,妈呀,命令敲下之后,又可以去泡杯茶了?为什么?
先拷贝出一个 10G 的 test.txt~ 备份文件,102 秒就过去了;
test.txt 截断为 0,再把 memfile( .test.txt.swp )拷贝回 test.txt ,数据量 10 G,102 秒过去了(第一次可能更慢哦);
4vim 编辑大文件的时候,会有空间膨胀?
是的,vim 一个 test.txt 10 G 的文件,会存在某个时刻,需要 >=30 G 的磁盘空间。
原文件 test.txt 10 G
备份文件 test.txt~ 10G
swap 文件 .test.txt.swp >10G
总结
vim 编辑文件并不没有用黑魔法,还是用的 read,write,朴实无华;
vim 编辑超大文件,打开很慢,因为会读一遍文件( readfile ),保存的时候很慢,因为会读写两遍文件(backup 一次,memfile 覆盖写原文件一次);
memfile 是 vim 抽象的一层虚拟存储空间(物理上由内存 block 和 swp 文件组成)对应一个文件的最新修改,存储单元由 block 构成。:w 保存的时候,就是从 memfile 读,写到原文件的过程;
memline 是基于 memfile 做的另一层封装,把用户的文件抽象成“行”的概念;
.test.txt.swp 文件是一直 open 的,memfile 会定期的交换数据进去,以便容灾恢复;
test.txt~ 文件才是真正的备份文件,诞生于 :w 覆盖原文件之前,消失于成功覆写原文件之后;
vim 基本都是整个文件的处理,并不是局部处理,大文件的编辑根本不适合 vim ,话说回来,正经人谁会用 vim 编辑 10 G 的文件?vim 就是个文本编辑器呀;
一个 readfile 函数 2533 行,一个 buf_write 函数 1987 行代码。。。不是我打击各位的积极性,这。。。反正我不想再看见它了。。。
后记
对于 vim 的好奇让笔者撸了一遍源码,学习了下其中的 IO 知识,不想被动辄几千行一个的函数教育了一番。我再也不想撸它了。。你学 fei 了吗?
编辑:hfy
-
存储
+关注
关注
13文章
4247浏览量
85627 -
Linux
+关注
关注
87文章
11217浏览量
208815
原文标题:Linux 编辑器之神 vim 的 IO 存储原理
文章出处:【微信号:gh_3980db2283cd,微信公众号:开关电源芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
从数电的角度去分析几种IO口模式
结构深、角度大、反射差?用共聚焦显微镜就对啦!
VIM培训教程
VIM for windows
剖析Windows系统中的VSS存储技术
Vim使用技巧总结
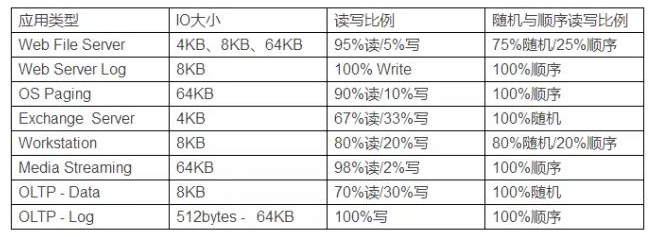
不同应用程序的存储IO类型解析

Vim之父去世后,Vim项目谁来接管?





 工商网监
工商网监
评论