 深度神经网络的困扰 梯度爆炸与梯度消失
深度神经网络的困扰 梯度爆炸与梯度消失
原始结构的RNN还不够处理较为复杂的序列建模问题,它存在较为严重的梯度消失问题,最直观的现象就是随着网络层数增加,网络会逐渐变得无法训练。长短期记忆网络(Long Short Time Memory,LSTM)正是为了解决梯度消失问题而设计的一种特殊的RNN结构。
深度神经网络的困扰:梯度爆炸与梯度消失
在此前的普通深度神经网络和深度卷积网络的讲解时,图1就是一个简单的两层普通网络,但当网络结构变深时,神经网络在训练时碰到梯度爆炸或者梯度消失的情况。那么什么是梯度爆炸和梯度消失呢?它们又是怎样产生的?
鉴于神经网络的训练机制,不管是哪种类型的神经网络,其训练都是通过反向传播计算梯度来实现权重更新的。通过设定损失函数,建立损失函数关于各层网络输入输出的梯度计算,当网络训练开动起来的时候,系统便按照反向传播机制来不断更新网络各层参数直到停止训练。但当网络层数加深时,这个训练系统并不是很稳,经常会出现一些问题。其中梯度爆炸和梯度消失便是较为严重的两个问题。
所谓梯度爆炸就是在神经网络训练过程中,梯度变得越来越大以使得神经网络权重得到疯狂更新的情形,这种情况很容易发现,因为梯度过大,计算更新得到的参数也会大到崩溃,这时候我们可能看到更新的参数值中有很多的NaN,这说明梯度爆炸已经使得参数更新出现数值溢出。这便是梯度爆炸的基本情况。
然后是梯度消失。与梯度爆炸相反的是,梯度消失就是在神经网络训练过程中梯度变得越来越小以至于梯度得不到更新的一种情形。当网络加深时,网络深处的误差很难因为梯度的减小很难影响到前层网络的权重更新,一旦权重得不到有效的更新计算,神经网络的训练机制也就失效了。
为什么神经网络训练过程中梯度怎么就会变得越来越大或者越来越小?可以用本书第一讲的神经网络反向传播推导公式为例来解释。
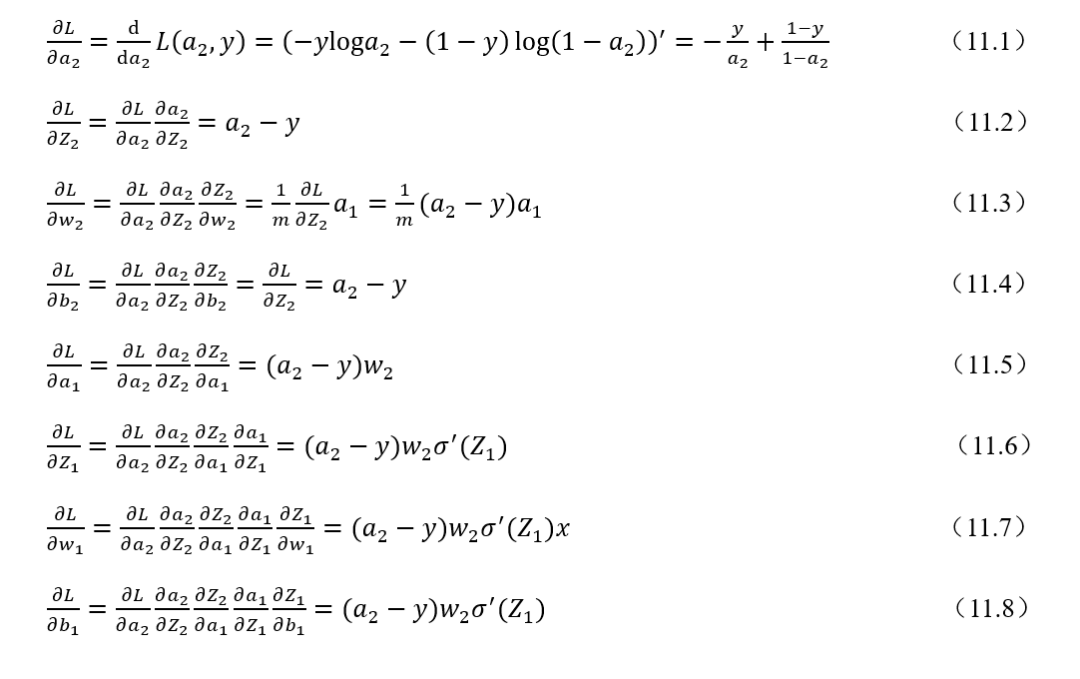
式(11.1)~-式(11.8)是一个两层网络的反向传播参数更新公式推导过程。离输出层相对较远的是输入到隐藏层的权重参数,可以看到损失函数对于隐藏层输出输入到隐藏层权重和偏置的梯度计算公式,一般而言都会转换从下一层的权重乘以激活函数求导后的式子。如果激活函数求导后的结果和下一层权重的乘积大于1或者说远远大于1的话,在网络层数加深时,层层递增的网络在做梯度更新时往往就会出现梯度爆炸的情况。如果激活函数求导和下一层权重的乘积小于1的话,在网络加深时,浅层的网络梯度计算结果会越来越小往往就会出现梯度消失的情况。所以可是说是反向传播的机制本身造就梯度爆炸和梯度消失这两种不稳定因素。例如,一个100层的深度神经网络,假设每一层的梯度计算值都为1.1,经过由输出到输入的反向传播梯度计算可能最后的梯度值就变成= 13780.61234,这是一个极大的梯度值了,足以造成计算溢出问题。若是每一层的梯度计算值为 0.9,反向传播输入层的梯度计算值则可能为= 0.000026561398,足够小到造成梯度消失。本例只是一个简化的假设情况,实际反向传播计算要更为复杂。
所以总体来说,神经网络的训练中梯度过大或者过小引起的参数过大过小都会导致神经网络失效,那我们的目的就是要让梯度计算回归到正常的区间范围,不要过大也不要过小,这也是解决这两个问题的一个思路。
那么如何解决梯度爆炸和梯度消失问题?梯度爆炸较为容易处理,在实际训练的时候对梯度进行修剪即可,但是梯度消失的处理就比较麻烦了,由上述的分析我们知道梯度消失一个关键在于激活函数。Sigmoid激活函数本身就更容易产生这种问题,所以一般而言,我们换上更加鲁棒的ReLu激活函数以及给神经网络加上归一化激活函数层(BN层),一般问题都能得到很好的解决,但也不是任何情形下都管用,例如,RNN网络,具体在下文中我们再做集中探讨。
以上便是梯度爆炸和梯度消失这两种问题的基本解释,下面我们回归正题,来谈谈本文的主角——LSTM。
LSTM:让RNN具备更好的记忆机制
前面说了很多铺垫,全部都是为了来讲LSTM。梯度爆炸和梯度消失,普通神经网络和卷积神经网络有,那么循环神经网络RNN也有吗?必须有。而且梯度消失和梯度爆炸的问题之于RNN来说伤害更大。当RNN网络加深时,因为梯度消失的问题使得前层的网络权重得不到更新,RNN就会在一定程度上丢失记忆性。为此,在传统的RNN网络结构基础上,研究人员给出一些著名的改进方案,因为这些改进方案都脱离不了经典的RNN架构,所以一般来说我们也称这些改进方案为RNN变种网络。比较著名的就是GRU(循环门控单元)和LSTM(长短期记忆网络)。GRU和LSTM二者结构基本一致,但有部分不同的地方,本讲以更有代表性的LSTM来进行详解。
在正式深入LSTM的技术细节之前,先要明确几点。第一,LSTM的本质是一种RNN网络。第二,LSTM在传统的RNN结构上做了相对复杂的改进,这些改进使得LSTM相对于经典RNN能够很好的解决梯度爆炸和梯度消失问题,让循环神经网络具备更强更好的记忆性能,这也是LSTM的价值所在。那咱们就来重点看一下LSTM的技术细节。
咱们先摆一张经典RNN结构与LSTM结构对比图,这样能够有一个宏观的把握,然后再针对LSTM结构图中各个部分进行拆解分析。图2所示是标准RNN结构,图3所示是LSTM结构。
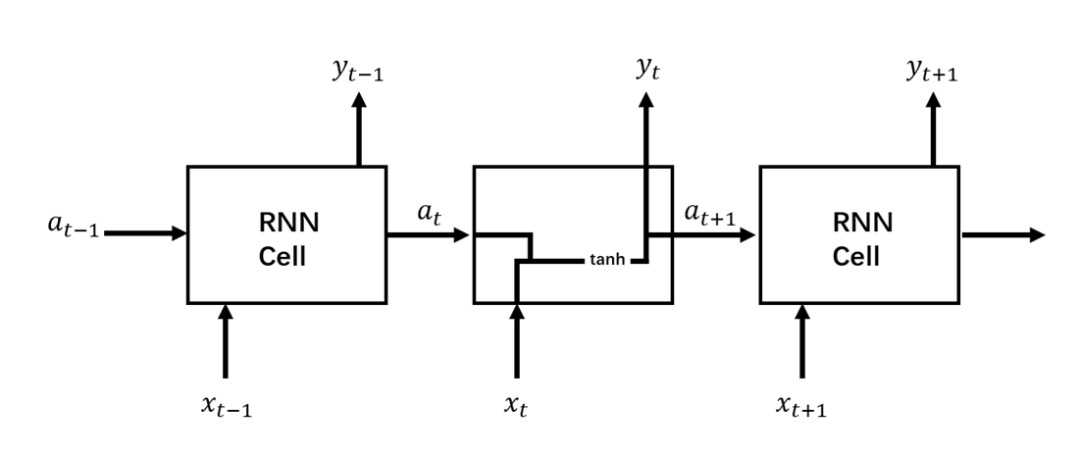
图2 RNN结构
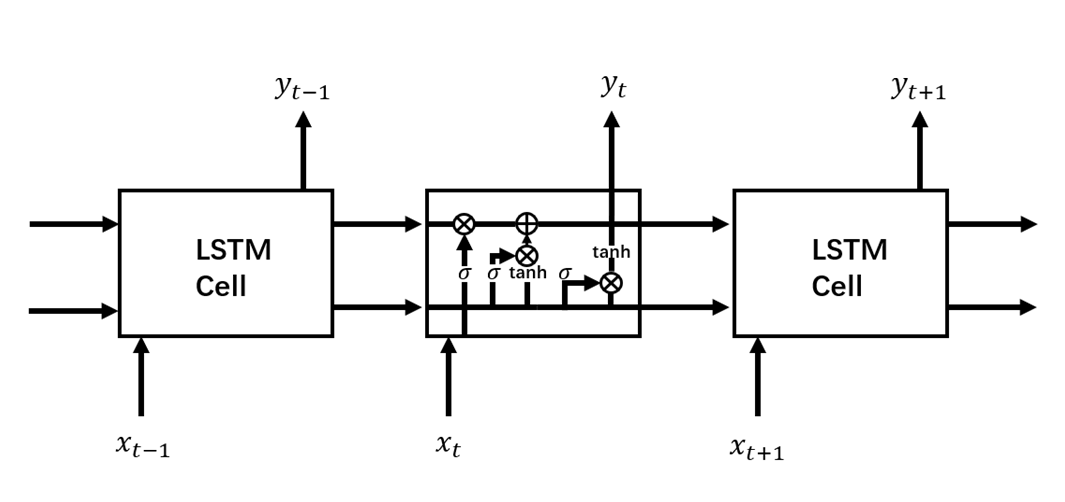
图3 LSTM结构
从图3中可以看到,相较于RNN单元,LSTM单元要复杂许多。每个LSTM单元中包含了4个交互的网络层,现在将LSTM单元放大,并标注上各个结构名称,如图4所示。
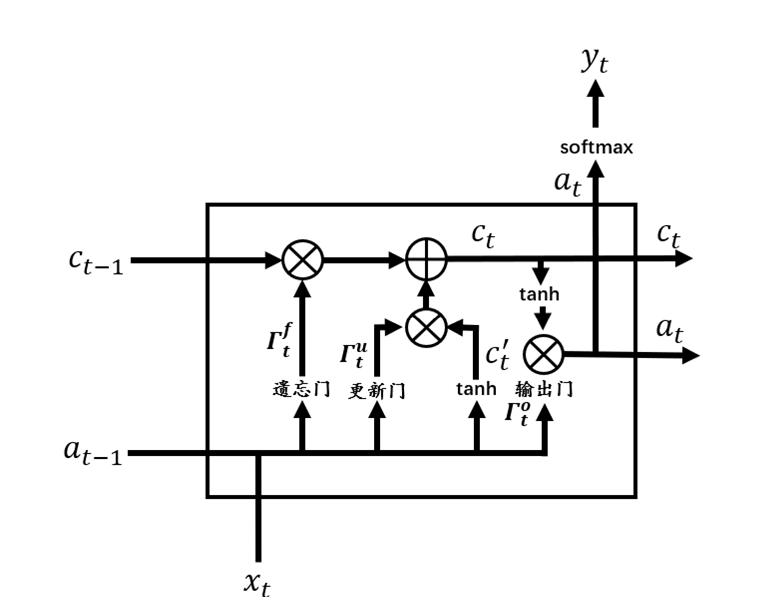
图4 LSTM单元
根据图4,一个完整的LSTM单元可以用式(11.9)~(11.14)来表示,其中符号表示两个向量合并。
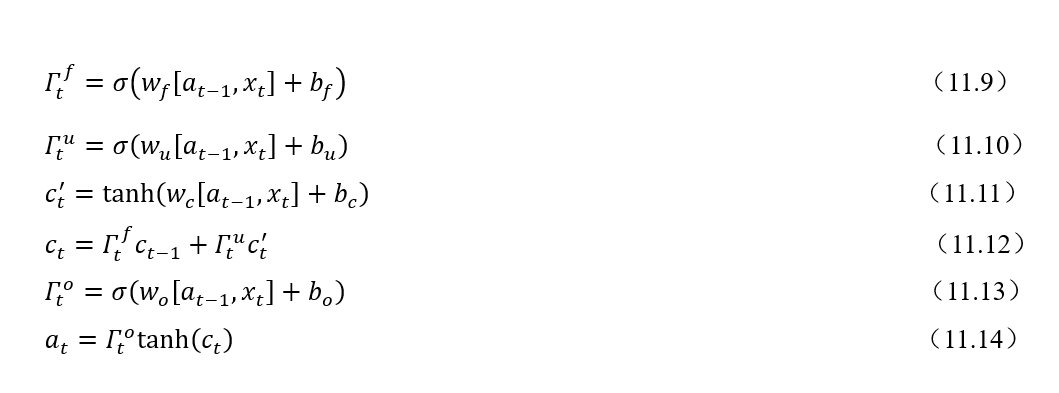
现在我们将LSTM单元结构图进行分解,根据结构图和公式来逐模块解释LSTM。
1. 记忆细胞
如图5红色部分所示,可以看到在LSTM单元的最上面部分有一条贯穿的箭头直线,这条直线由输入到输出,相较于RNN,LSTM提供了c作为记忆细胞输入。记忆细胞提供了记忆的功能,在网络结构加深时仍能传递前后层的网络信息。这样贯穿的直线使得记忆信息在网络各层之间保持下去很容易。
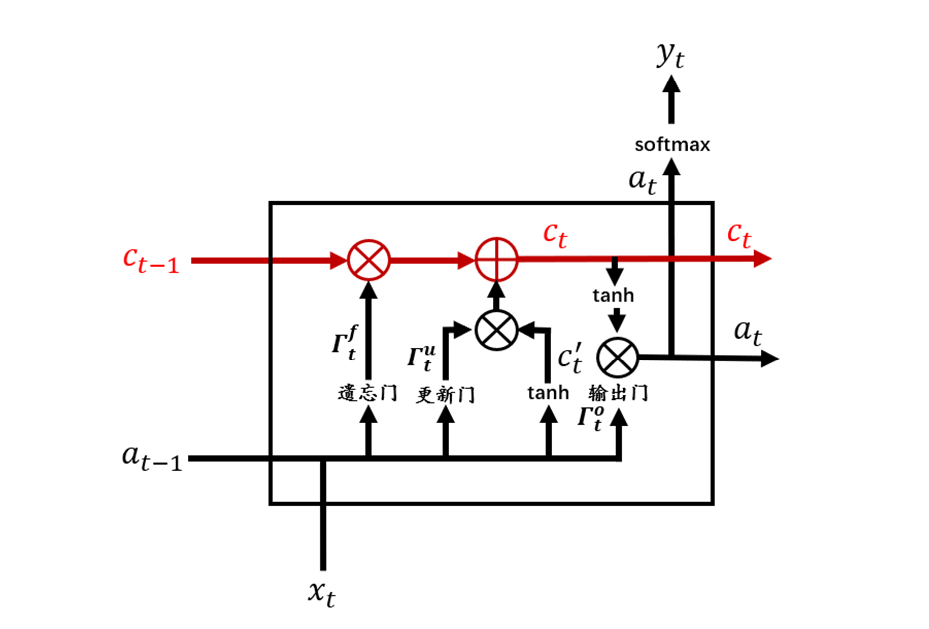
图5 LSTM记忆细胞
2. 遗忘门(Forget Gate)
遗忘门的计算公式如下:
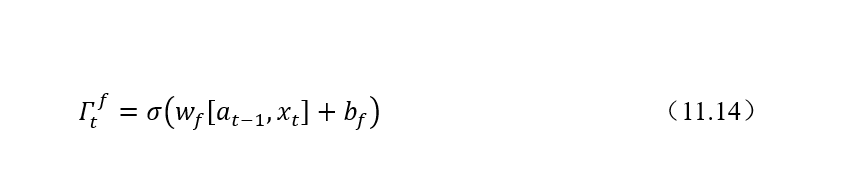
遗忘门的作用是要决定从记忆细胞c中是否丢弃某些信息,这个过程可以通过一个 Sigmoid函数来进行处理。遗忘门在整个结构中的位置如图11.6所示。可以看到,遗忘门接受来自输入和上一层隐状态的值进行合并后加权计算处理。
3. 记忆细胞候选值和更新门
更新门(Update Gate)表示需要将什么样的信息能存入记忆细胞中。除了计算更新门之外,还需要使用tanh计算记忆细胞的候选值。LSTM中更新门需要更加细心一点。记忆细胞候选值和更新门的计算公式如下:
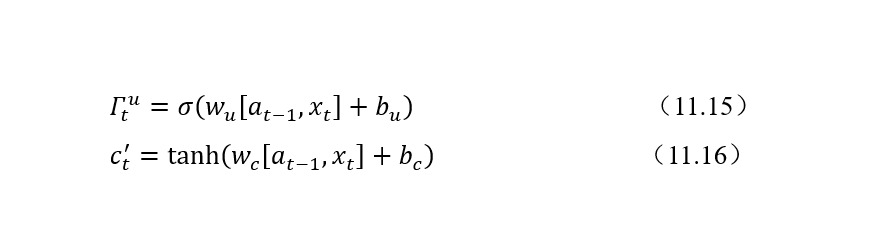
更新门和tanh在整个结构中的位置如图7所示。
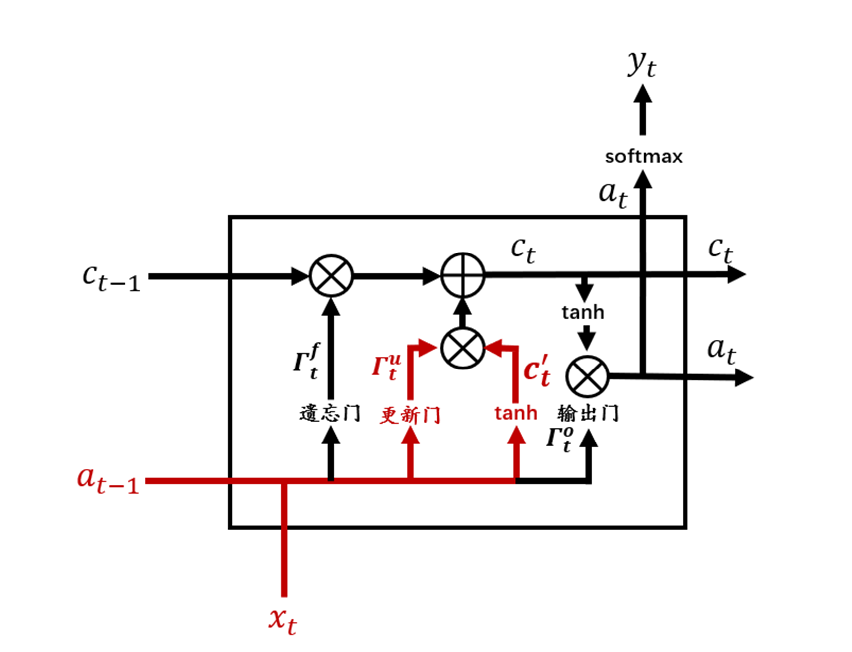
图7 记忆细胞候选值和更新门
4. 记忆细胞更新
结合遗忘门、更新门、上一个单元记忆细胞值和记忆细胞候选值来共同决定和更新当前细胞状态:
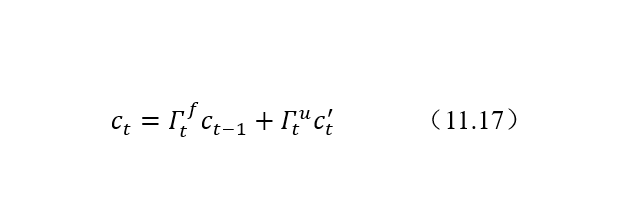
记忆细胞更新在LSTM整个结构中位置如图8所示:
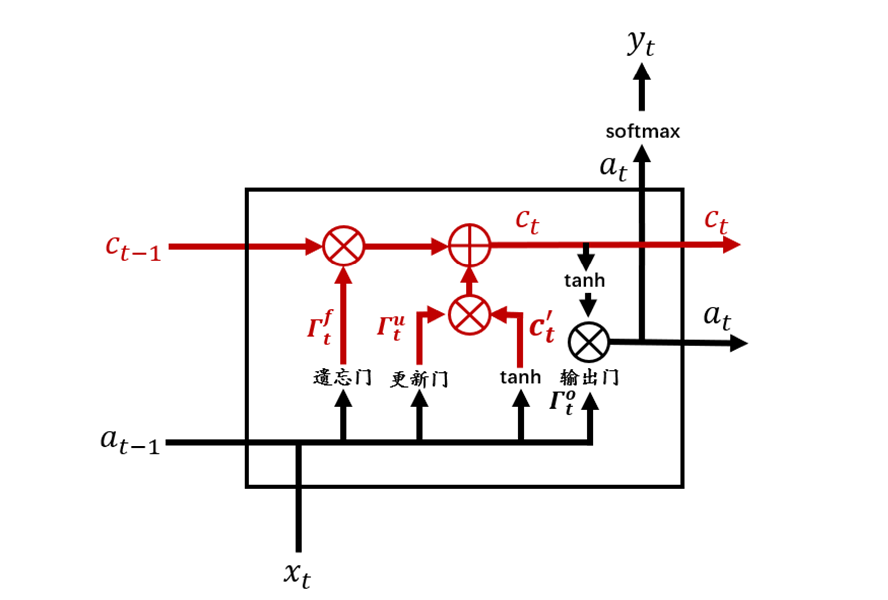
图8 记忆细胞更新
5. 输出门
LSTM 提供了单独的输出门(Output Gate)。计算公式如下:
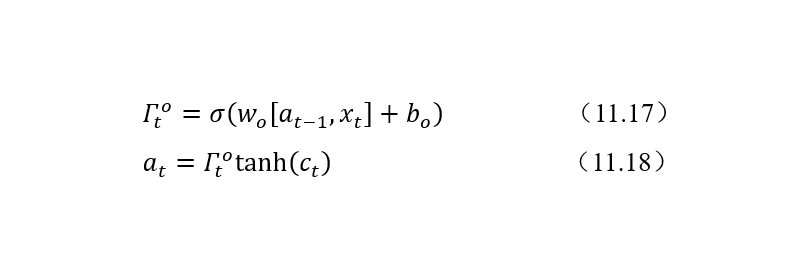
输出门的位置如图9所示。
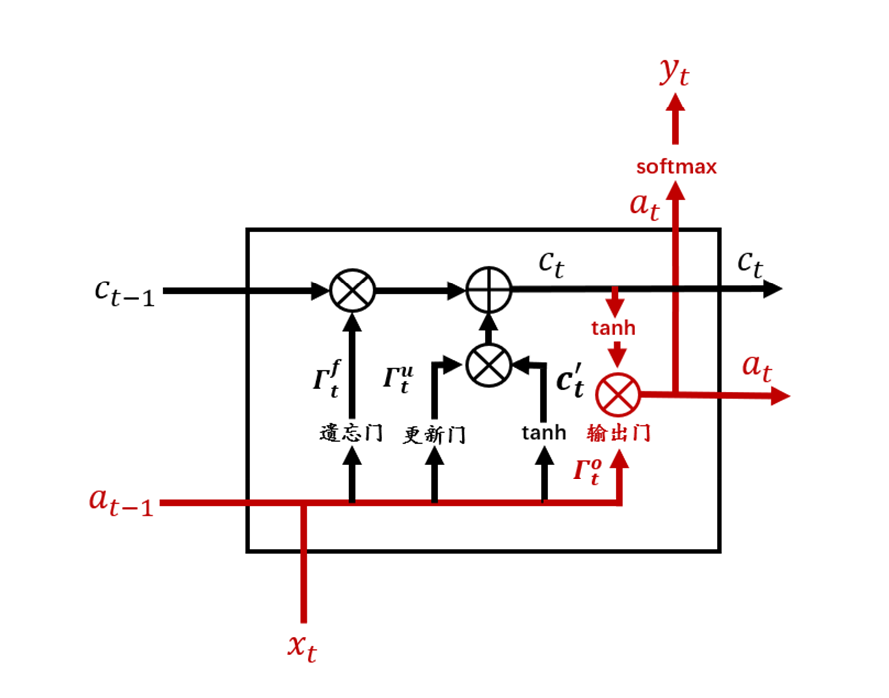
图9 输出门
以上便是完整的LSTM结构。虽然复杂,但经过逐步解析之后也就基本清晰了。LSTM 在自然语言处理、问答系统、股票预测等等领域都有着广泛而深入的应用。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4793浏览量
102029 -
LSTM
+关注
关注
0文章
60浏览量
3925
原文标题:深入理解LSTM
文章出处:【微信号:sessdw,微信公众号:三星半导体互动平台】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习模型在传感器数据处理中的应用(二):LSTM





 工商网监
工商网监
评论