 NLP中Prompt的产生和兴起
NLP中Prompt的产生和兴起
导读:本文目标是对近期火爆异常的Prompt相关研究作一些追溯和展望,内容主要参考论文《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》,并掺杂了笔者的一些个人见解,欢迎大家积极讨论~所用图片均来自该论文。
论文的arxiv链接如下:
https://arxiv.org/abs/2107.13586
本文的内容框架如下:
一、Prompt的产生和兴起
二、什么是Prompt
三、Prompt的设计方法
四、Prompt的挑战和展望
一、Prompt的产生和兴起
近几年来,有关预训练语言模型(PLM)的研究比比皆是,自然语言处理(NLP)也借着这股春风获得了长足发展。尤其是在2017-2019年间,研究者们的重心逐渐从传统task-specific的有监督模式转移到预训练上。基于预训练语言模型的研究思路通常是“pre-train, fine-tune”,即将PLM应用到下游任务上,在预训练阶段和微调阶段根据下游任务设计训练对象并对PLM本体进行调整。
随着PLM体量的不断增大,对其进行fine-tune的硬件要求、数据需求和实际代价也在不断上涨。除此之外,丰富多样的下游任务也使得预训练和微调阶段的设计变得繁琐复杂,因此研究者们希望探索出更小巧轻量、更普适高效的方法,Prompt就是一个沿着此方向的尝试。
融入了Prompt的新模式大致可以归纳成”pre-train, prompt, and predict“,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model, 在文本情感分类任务中,对于 “I love this movie.” 这句输入,可以在后面加上prompt “The movie is ___” 这样的形式,然后让PLM用表示情感的答案填空如 “great”、“fantastic” 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。
因此,合适的prompt对于模型的效果至关重要。大量研究表明,prompt的微小差别,可能会造成效果的巨大差异。研究者们就如何设计prompt做出了各种各样的努力——自然语言背景知识的融合、自动生成prompt的搜索、不再拘泥于语言形式的prompt探索等等,笔者将会在第三节进行进一步讨论。
二、什么是Prompt
Prompt刚刚出现的时候,还没有被叫做Prompt,是研究者们为了下游任务设计出来的一种输入形式或模板,它能够帮助PLM“回忆”起自己在预训练时“学习”到的东西,因此后来慢慢地被叫做Prompt了。
对于输入的文本,有函数,将转化成prompt的形式,即:
该函数通常会进行两步操作:
使用一个模板,模板通常为一段自然语言,并且包含有两个空位置:用于填输入的位置和用于生成答案文本的位置。
把输入填到的位置。
还用前文提到的例子。在文本情感分类的任务中,假设输入是
“ I love this movie.”
使用的模板是
“ [X] Overall, it was a [Z] movie.”
那么得到的就应该是 “I love this movie. Overall it was a [Z] movie.”
在实际的研究中,prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。和的位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。
另外,上面的例子中prompts都是有意义的自然语言,但实际上其形式并不一定要拘泥于自然语言。现有相关研究使用虚拟单词甚至直接使用向量作为prompt,笔者将会在第三节讲到。
下一步会进行答案搜索,顾名思义就是LM寻找填在处可以使得分数最高的文本 。最后是答案映射。有时LM填充的文本并非任务需要的最终形式,因此要将此文本映射到最终的输出。例如,在文本情感分类任务中,“excellent”, “great”, “wonderful” 等词都对应一个种类 “++”,这时需要将词语映射到标签再输出。
三、Prompt的设计
Prompt大致可以从下面三个角度进行设计:
Prompt的形状
手工设计模板
自动学习模板
Prompt的形状
Prompt的形状主要指的是和的位置和数量。上文提到过cloze prompt和prefix prompt的区别,在实际应用过程中选择哪一种主要取决于任务的形式和模型的类别。cloze prompts和Masked Language Model的训练方式非常类似,因此对于使用MLM的任务来说cloze prompts更加合适;对于生成任务来说,或者使用自回归LM解决的任务,prefix prompts就会更加合适;Full text reconstruction models较为通用,因此两种prompt均适用。另外,对于文本对的分类,prompt模板通常要给输入预留两个空,和。
手工设计模板
Prompt最开始就是从手工设计模板开始的。手工设计一般基于人类的自然语言知识,力求得到语义流畅且高效的模板。例如,Petroni等人在著名的LAMA数据集中为知识探针任务手工设计了cloze templates;Brown等人为问答、翻译和探针等任务设计了prefix templates。手工设计模板的好处是较为直观,但缺点是需要很多实验、经验以及语言专业知识,代价较大。
自动学习模板
为了解决手工设计模板的缺点,许多研究开始探究如何自动学习到合适的模板。自动学习的模板又可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。离散的主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续的则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning。
离散Prompts
自动生成离散Prompts指的是自动生成由自然语言的词组成的Prompt,因此其搜索空间是离散的。目前大致可以分成下面几个方法:
Prompt Mining. 该方法需要一个大的文本库支持,例如Wikipedia。给定输入和输出,要找到和之间的中间词或者依赖路径,然后选取出现频繁的中间词或依赖路径作为模板,即“[X] middle words [Z]”。
Prompt Paraphrasing. Paraphrasing-based方法是基于释义的,主要采用现有的种子prompts(例如手动构造),并将其转述成一组其他候选prompts,然后选择一个在目标任务上达到最好效果的。一般的做法有:将提示符翻译成另一种语言,然后再翻译回来;使用同义或近义短语来替换等。
Gradient-based Search. 梯度下降搜索的方法是在单词候选集里选择词并组合成prompt,利用梯度下降的方式不断尝试组合,从而达到让PLM生成需要的词的目的。
Prompt Generation. 既然Prompt也是一段文本,那是否可以用文本生成的方式来生成Prompt呢?该类方法就是将标准的自然语言生成的模型用于生成prompts了。例如,Gao等人将T5引入了模板搜索的过程,让T5生成模板词;Ben-David 等人提出了一种域自适应算法,训练T5为每个输入生成一种唯一的域相关特征,然后把输入和特征连接起来组成模板再用到下游任务中。
Prompt Scoring. Davison等人在研究知识图谱补全任务的时候为三元组输入(头实体,关系,尾实体)设计了一种模板。首先人工制造一组模板候选,然后把相应的[X]和[Z]都填上成为prompts,并使用一个双向LM给这些prompts打分,最后选取其中的高分prompt。
连续Prompts
既然构造Prompt的初衷是能够找到一个合适的方法,让PLM更“听话”地得出我们想要的结果,那就不必把prompt的形式拘泥于人类可以理解的自然语言了,只要机器可以理解就好了。因此,还有一些方法探索连续型prompts——直接作用到模型的embedding空间。连续型prompts去掉了两个约束条件:
模板中词语的embedding可以是整个自然语言的embedding,不再只是有限的一些embedding。
模板的参数不再直接取PLM的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整。
目前的连续prompts方法大致可以分为下面几种:
Prefix Tuning. Prefix Tuning最开始由Li等人提出,是一种在输入前添加一串连续的向量的方法,该方法保持PLM的参数不动,仅训练合适的前缀(prefix)。它的形式化定义是,在给定一个可训练的前缀矩阵和一个固定的参数化为的PLM的对数似然目标上进行优化。
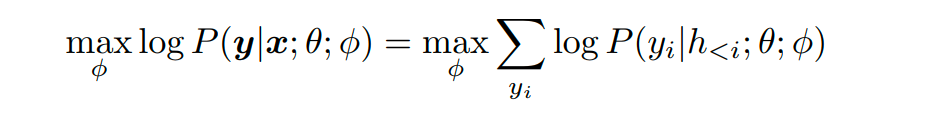
其中
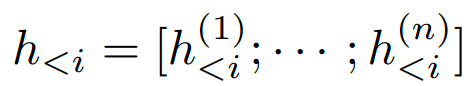
指的是所有神经网络层在第i个时间步的连接。如果对应的时间步在前缀中,则它可以直接从前缀矩阵中复制过来;否则需要使用PLM进行计算。
类似地,Lester等人在输入序列前面加上特殊的token来组成一个模板,然后直接调整这些token的embedding。 和上面的Prefix Tuning的方法相比,他们的方法相对来说参数较少,因为没有在每一层网络中引入额外的参数。
Tuing Initialized with Discrete Prompts. 这类方法中连续prompts是用已有的prompts初始化的,已有的prompts可以是手工设计的,也可以是之前搜索发现的离散prompts。Zhong 等人先用一个离散prompt搜索方法定义了一个模板,然后基于该模板初始化虚拟的token,最后微调这些token的embedding以提高准确率。
Hard-Soft Prompt Hybrid Tuning. 这类方法可以说是手工设计和自动学习的结合,它通常不单纯使用可学习的prompt模板,而是在手工设计的模板中插入一些可学习的embedding。Liu等人提出了“P-Tuning”方法,通过在input embedding中插入可训练的变量来学习连续的prompts。并且,该方法使用BiLSTM的输出来表示prompt embeddings,以便让prompt tokens之间有一定的交互。P-tuning还引入了任务相关的anchor tokens(例如关系提取中的“capital”)来进一步提高效果,这些anchor tokens不参与后续的调优。Han等人提出了Prompt Tunning with Rules(PTR)方法,使用手工指定的子模板按照逻辑规则组装成完整的模板。为了增强生成的模板的表示能力,该方法还插入了几个虚拟token,这些虚拟token的embeddings可以和PLM的参数一起被调整,PTR的模板token既有实际token也有虚拟token 。实验结果证明了该方法在关系分类任务中的有效性。四、Prompt的挑战与展望
尽管Prompt相关研究搞得如火如荼,但目前仍存在许多问题,值得研究者们去探索。
Prompt的设计问题。目前使用Prompt的工作大多集中育分类任务和生成任务,其它任务则较少,因为如何有效地将预训练任务和prompt联系起来还是一个值得探讨的问题。另外,模板和答案的联系也函待解决。模型的表现同时依赖于使用的模板和答案的转化,如何同时搜索或者学习出两者联合的最好效果仍然很具挑战性。
Prompt的理论分析和可解释性。尽管Prompt方法在很多情况下都取得了成功,但是目前prompt-based learning的理论分析和保证还很少,使得人们很难了解Prompt为什么能达到好的效果,又为什么在自然语言中意义相近的Prompt有时效果却相差很大。
Prompt在PLM debias方面的应用。由于PLM在预训练过程中见过了大量的人类世界的自然语言,所以很自然地受到了影响。拿一个简单的例子来说,可能不太恰当,比如说训练语料中有很多的“The capital of China is ”Beijing.“,导致模型认为下次看到”capital“ 的时候都会预测出”Beijing“,而不是着重看到底是哪个国家的首都。在应用的过程中,Prompt还暴露了PLM学习到的很多其它bias,比如种族歧视、恐怖主义、性别对立等等。已有相关研究关注是否可以利用Prompt来对这些bias进行修正,但还处在比较初级的阶段,这也会是一个值得研究的方向。
五、引用
[1] Liu P, Yuan W, Fu J, et al. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing[J]。 arXiv preprint arXiv:2107.13586, 2021.
责任编辑:haq
-
神经网络
+关注
关注
42文章
4732浏览量
100373 -
nlp
+关注
关注
1文章
483浏览量
21984
原文标题:NLP新宠——浅谈Prompt的前世今生
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
霍尔效应中磁场怎么产生的
nlp逻辑层次模型的特点
nlp神经语言和NLP自然语言的区别和联系
nlp自然语言处理框架有哪些
nlp自然语言处理的主要任务及技术方法
nlp自然语言处理模型怎么做
nlp自然语言处理的应用有哪些
NLP技术在机器人中的应用
NLP技术在人工智能领域的重要性
什么是自然语言处理 (NLP)
负电压是什么?它在电路中是怎么产生的?负电压产生的意义
如何从训练集中生成候选prompt 三种生成候选prompt的方式
NLP领域的语言偏置问题分析






 工商网监
工商网监
评论