 OpenCV新增描述子BEBLID
OpenCV新增描述子BEBLID
在前不久发布的OpenCV4.5中更新了很多新特性:
- 从4.5版本开始,OpenCV将正式使用Apache2协议,从而避免专利算法带来的潜在纠纷
- SIFT专利到期,代码被移到主库
- 对RANSAC算法进行了改进
- 新增了实时单目标跟踪算法SiamRPN++
还有其他重要更新,这里就不再叙述。值得一提的是,BELID描述子也被添加进去了。
BEBLID全称是Boosted Efficient Binary Local Image Descriptor,多项实验证明能够提高图像匹配精度,同时减少执行时间。
#CommentoruncommenttouseORBorBEBLID
descriptor=cv.xfeatures2d.BEBLID_create(0.75)
#descriptor=cv.ORB_create()
kpts1,desc1=descriptor.compute(img1,kpts1)
kpts2,desc2=descriptor.compute(img2,kpts2)
更多细节可以参考:
https://towardsdatascience.com/improving-your-image-matching-results-by-14-with-one-line-of-code-b72ae9ca2b73
https://github.com/iago-suarez/beblid-opencv-demo/blob/main/demo.ipynb
CODE:https://github.com/iago-suarez/BEBLID.git
PDF:http://www.dia.fi.upm.es/~pcr/publications/PRL_2020_web_BEBLID.pdf
这里说一下结论吧,经过这个作者测试,将ORB描述符替换为BEBLID,就可以将这两个图像的匹配结果提高14%.
下面详细介绍一下这个BEBLID描述子.
“作者提出了一种有效的图像描述符BELID。其有效性的关键是对一组图像特征进行有区别的选择,且计算量要求非常低。实验是在电脑和智能手机上进行,BELID的精确度与SIFT相似,执行时间与最快的算法ORB相当。
”
介绍
局部图像是用于匹配存在强烈外观变化的图像,如光照变化或几何变换。它们是许多计算机视觉任务的基本组成部分,如3D重建、SLAM、图像检索、位姿估计等。它们是最流行的图像表示方法,因为局部特征是独特的,视点不变的。
为了产生一个局部图像表示,我们必须检测一组显著的图像结构,并为每个结构提供描述。对于各种如角、线和区域,有大量非常有效的检测器,它们可以用实数或二进制描述符来描述。目前SIFT描述子仍然被认为是“黄金标准”技术。
本文给出了一种有效的描述子。特征使用积分图像来有效地计算一对图像正方形区域的平均灰度值之间的差。作者使用一个增强算法来区分地选择一组特征,并将它们组合起来产生强描述。实验结果表明,该方法提高了计算速度,执行时间接近ORB,精度与SIFT相似,它能够为手头的任务选择最佳的特征。
BELID
在本节中,作者提出了一种描述图像局部区域的有效算法,其速度和SIFT一样快。其速度的关键是使用少量、快速和选择性的特征。描述子使用一组使用BoostedSCC算法选择的K个特征,该算法是对AdaBoost的改进。
设是由一对对图像patches组成的训练集,标记{−1,1}。其中= 1表示两个patch对应相同的显著性图像结构,=−1表示不同的显著性图像结构.
训练过程将损失降到最低
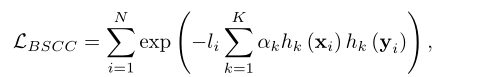
其中,它依赖于特征提取函数f: X→R和一个阈值T.给定f和T,通过含T的f(x)来定义weak learner,
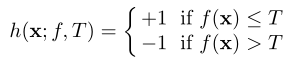
1. 阈值平均盒弱学习者
效率的关键是选择一个f(x),它既具有判别性,又能快速计算。我们定义特征提取函数f(x)
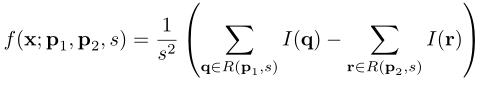
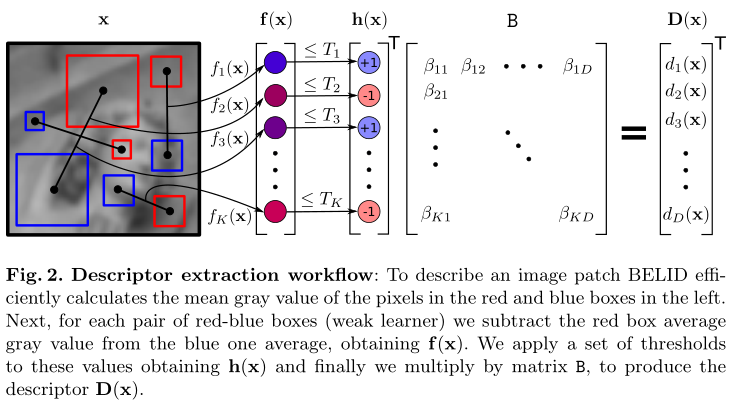
I(t)是像素的灰度值t和R (p, s)是大小的正方形盒子集中在带有尺寸s的像素p。因此,f计算像素的平均灰度值之间的差异(, s)和R(,s)。图2中的红色和蓝色方块代表,分别(, s)和R (, s)。加快f的计算,作者使用积分图像的输入图像。一旦S可用,方框中的灰度和可以通过4次内存访问和4次算术运算来计算。
检测器通常计算局部结构的方位和尺度。为了BEBLID描述符不受欧几里得变换的影响,作者用底层的局部结构来定位和缩放我们的测量值。
2. 优化弱学习者权值
BoostedSCC算法选择K个弱学习者及其相应的权值。等式1中BoostedSCC优化的损耗函数可以看作是一种度量学习方法,其中度量矩阵a是对角的
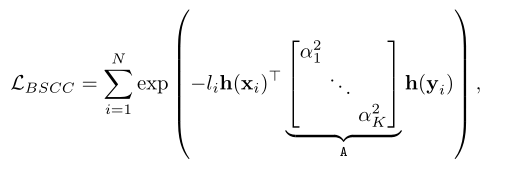
其中h(w)是K个弱学习者对图像patch的w响应向量。在这种情况下,不考虑不同弱学习者响应之间的依赖关系。此时,给定图像patch w的BELID-U(未优化)描述符计算为,其中使=
进一步,通过对特征之间的相关性进行建模,估计整个矩阵A可以改善相似函数。FP-Boost估计最小值
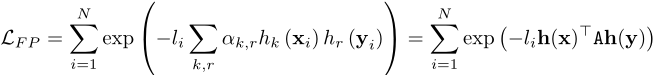
采用随机梯度下降法估计对称的a和是一项困难的工作。因此,该算法从K个弱学习器和由BoostedSCC找到的α开始。第二个学习步骤非常快,因为所有弱学习者的反应都可以预先计算出来
在未优化的描述符的情况下,必须分解相似函数s(x,y)来计算x和y的独立描述子。假设A是一个对称矩阵,可以使用它的特征分解来选择特征值最大的D个特征向量
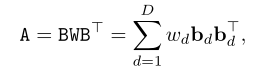
实验
不同的场景:巴黎圣母院,约塞米蒂国家公园和纽约的自由女神像。在SIFT检测到的局部结构周围裁剪PATCH。
作者用三种方法来比较性能:
- FPR-95.: 这是一个PATCH验证问题中95%的召回误报率。当开发BEBILD描述符时,作者希望能够匹配大部分的局部结构,比如说95%的召回率,但是有尽可能少的误报。因此,在PATCH验证问题中,描述符的FPR-95越低越好。
- AUC: PATCH验证问题中ROC曲线下的面积。它提供了一个良好的整体测量,因为它考虑了曲线上的所有操作点,而不是像FPR-95案例中只有一个。
- mAP.: 在PATCH验证、图像匹配和PATCH检索这三个任务中,每个任务的平均精度,在HPatches基准中定义。
作者已经在Python中实现了BoostedSCC、FP-Boost和阈值平均盒弱学习者的学习和测试部分。为了优化A矩阵,使用了固定学习率为10 - 8和批量2000个样本的随机梯度下降算法。同时也在c++中实现了使用OpenCV处理输入图像。作者使用这个实现来测量BELID在不同平台上的执行时间。
1. PATCH验证实验
在这里,首先探索维度数的影响。在图3中,显示了AUC和FPR-95值作为维数(“N维”)的函数。在BELID的例子中,使用K = 512,并计算B从512维减少到图中给出的一个。
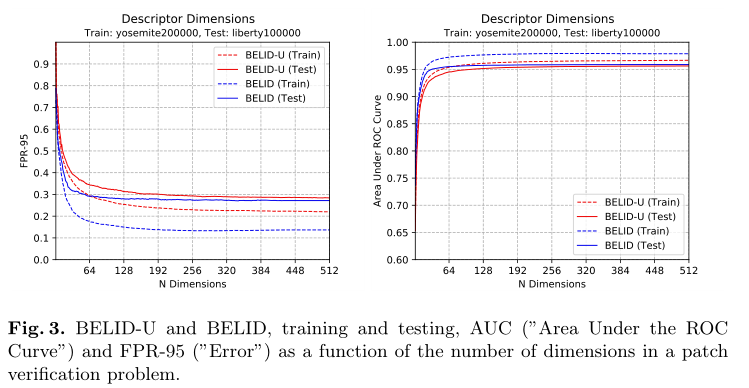
首先运行BoostedSSC来选择512个弱学习者。通过从这个初始集合中移除最后的弱学习者,作者改变了图3中BELID- u曲线的维数。对于BELID,丢弃了B的最后一列,它们对应于与最小特征值相关的缩放特征向量
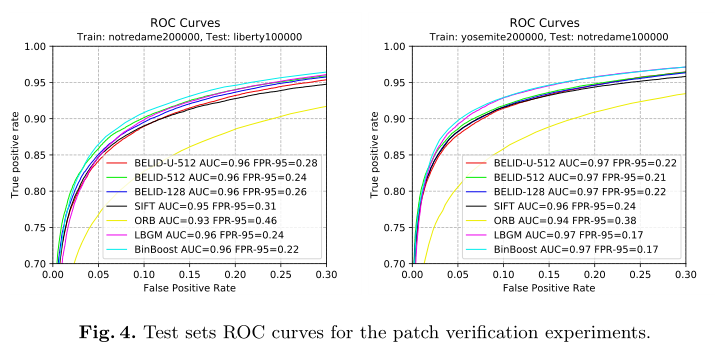
从图3可以看出,boosting过程选择的特征最多只在一点上对最终判别有贡献。在128个弱学习者之后,每个新特征提供的改进非常小。在256之后,没有得到任何改进,这意味着最后一个是多余的。优化后的BELID性能优于BELIDU,BELID得分最低FPR-95有128个尺寸。
2. Hpatches数据集实验
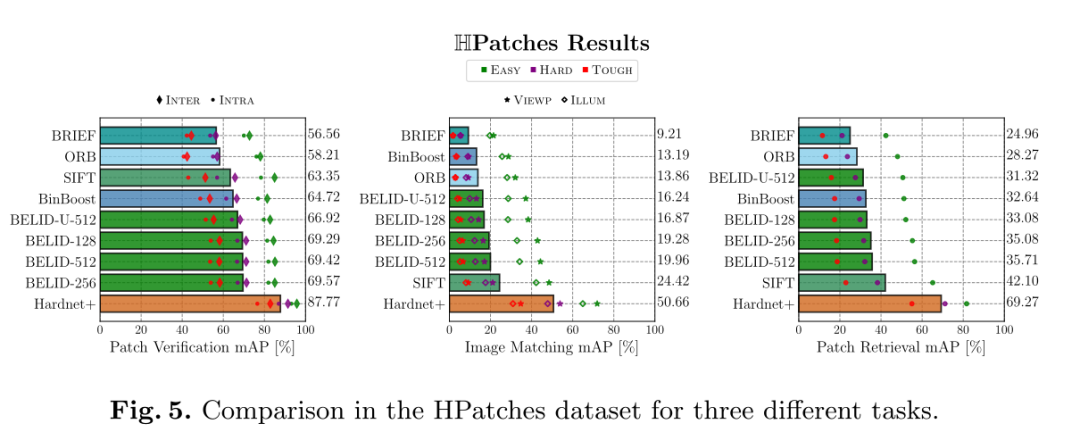
图5显示了用HPathces工具获得的各种BELID配置和其他竞争方法的结果。作者得到了与之前实验相同的情况,所有的BELID配置都比SIFT好,69.57 vs 63.35,比ORB好得多。
然而,在另外两个任务中,BEBILD描述子落后于SIFT。这是一个预期的结果,因为作者没有为这些任务优化描述子。总之,BELID在所有任务中提供的结果接近SIFT,并优于ORB。
3. 不同平台的执行时间
在最后的实验中,作者测试了c++实现的BELID处理图像的时间,呈现了由来自8个不同场景的48张800×640图像组成的Mikolajczyk数据集的执行时间。
作者将执行时间与OpenCV库中的其他相关描述子进行比较。为此运行ORB ,、SIFT 、 LBGM和BinBoost。结果在表1中。
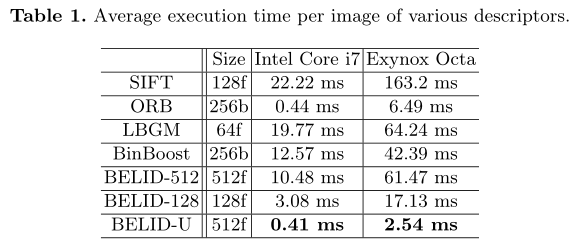
就速度而言,BELID-U与ORB相当。事实上,BELID-U在桌面环境下和ORB一样快(0.41 ms vs 0.44 ms),在有限的CPU环境下更快(2.54 ms vs 6.49 ms)。这是意料之中的,因为两者都使用一组灰度值差异作为特征。LBGM使用与BELID相同的特征选择算法,但具有较慢的特征。因此,这个描述符需要与桌面设置中的SIFT相同的处理时间(19.77 ms vs 22.22 ms),但FPR-95稍好。
在桌面CPU上,BELID-128只需要3.08毫秒,大约是BELID-U和ORB的7倍。在智能手机CPU中,BELID128的时间也比BELID-U慢7倍左右。
结论本文提出了一种有效的图像描述符BELID。在实验中,作者证明了它有非常低的计算要求,在准确度方面,BELID优于ORB,接近SIFT。
-
代码
+关注
关注
30文章
4788浏览量
68603 -
SLAM
+关注
关注
23文章
424浏览量
31830 -
OpenCV
+关注
关注
31文章
635浏览量
41347 -
orb
+关注
关注
0文章
21浏览量
9896
原文标题:OpenCV新增描述子BEBLID:提高图像匹配精度,减少执行时间
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Vivado设计流程分析 Vivado HLS实现OpenCV的开发流程

最新OpenCV专题出炉啦~最全OpenCV教程及各种图像处理、目标跟踪、识别案例
SE5盒子上安装了libsophon、和sophon-mw的包之后运行opencv resize报错如何解决?
最全OpenCV教程及图像处理、目标跟踪、识别案例

opencv备忘单
基于Pivots的有效图像块描述子
一种改进的SIFT描述子在图像配准中的应用
图像局部特征描述方法
一种全新的特征组合二值描述子算法
一种事件相机描述子——DART






 工商网监
工商网监
评论