 秒杀几道运用Dijkstra算法的题目
秒杀几道运用Dijkstra算法的题目
读完本文,可以去力扣解决如下题目:
743. 网络延迟时间(中等)
1514. 概率最大的路径(中等)
1631. 最小体力消耗路径(中等)
其实,很多算法的底层原理异常简单,无非就是一步一步延伸,变得看起来好像特别复杂,特别牛逼。
但如果你看过历史文章,应该可以对算法形成自己的理解,就会发现很多算法都是换汤不换药,毫无新意,非常枯燥。
比如,我们说二叉树非常重要,你把这个结构掌握了,就会发现 动态规划,分治算法,回溯(DFS)算法,BFS 算法框架,Union-Find 并查集算法,二叉堆实现优先级队列 就是把二叉树翻来覆去的运用。
那么本文又要告诉你,Dijkstra 算法(一般音译成迪杰斯特拉算法)无非就是一个 BFS 算法的加强版,它们都是从二叉树的层序遍历衍生出来的。
这也是为什么我在 学习数据结构和算法的框架思维 中这么强调二叉树的原因。
下面我们由浅入深,从二叉树的层序遍历聊到 Dijkstra 算法,给出 Dijkstra 算法的代码框架,顺手秒杀几道运用 Dijkstra 算法的题目。
图的抽象
前文 图论第一期:遍历基础 说过「图」这种数据结构的基本实现,图中的节点一般就抽象成一个数字(索引),图的具体实现一般是「邻接矩阵」或者「邻接表」。
比如上图这幅图用邻接表和邻接矩阵的存储方式如下:
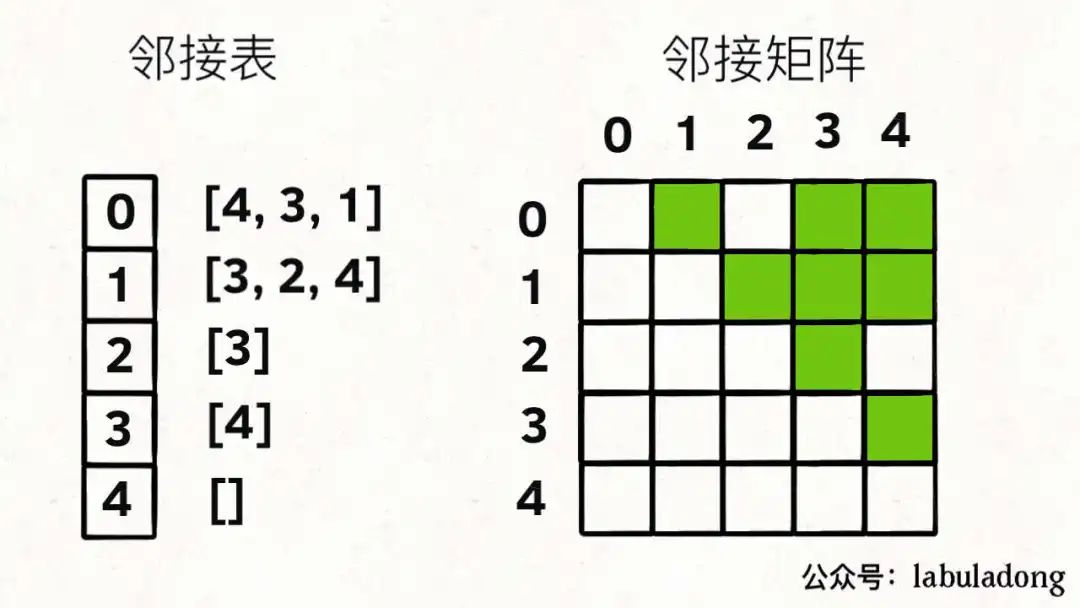
前文 图论第二期:拓扑排序 告诉你,我们用邻接表的场景更多,结合上图,一幅图可以用如下 Java 代码表示:
// graph[s] 存储节点 s 指向的节点(出度)
List《Integer》[] graph;
如果你想把一个问题抽象成「图」的问题,那么首先要实现一个 APIadj:
// 输入节点 s 返回 s 的相邻节点List《Integer》 adj(int s);
类似多叉树节点中的children字段记录当前节点的所有子节点,adj(s)就是计算一个节点s的相邻节点。
比如上面说的用邻接表表示「图」的方式,adj函数就可以这样表示:
List《Integer》[] graph;
// 输入节点 s,返回 s 的相邻节点List《Integer》 adj(int s) {
return graph[s];
}
当然,对于「加权图」,我们需要知道两个节点之间的边权重是多少,所以还可以抽象出一个weight方法:
// 返回节点 from 到节点 to 之间的边的权重int weight(int from, int to);
这个weight方法可以根据实际情况而定,因为不同的算法题,题目给的「权重」含义可能不一样,我们存储权重的方式也不一样。
有了上述基础知识,就可以搞定 Dijkstra 算法了,下面我给你从二叉树的层序遍历开始推演出 Dijkstra 算法的实现。
二叉树层级遍历和 BFS 算法
我们之前说过二叉树的层级遍历框架:
// 输入一棵二叉树的根节点,层序遍历这棵二叉树void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue《TreeNode》 q = new LinkedList《》();
q.offer(root);
int depth = 1;
// 从上到下遍历二叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i 《 sz; i++) {
TreeNode cur = q.poll();
printf(“节点 %s 在第 %s 层”, cur, depth);
// 将下一层节点放入队列
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
depth++;
}
}
我们先来思考一个问题,注意二叉树的层级遍历while循环里面还套了个for循环,为什么要这样?
while循环和for循环的配合正是这个遍历框架设计的巧妙之处
while循环控制一层一层往下走,for循环利用sz变量控制从左到右遍历每一层二叉树节点。
注意我们代码框架中的depth变量,其实就记录了当前遍历到的层数。换句话说,每当我们遍历到一个节点cur,都知道这个节点属于第几层。
算法题经常会问二叉树的最大深度呀,最小深度呀,层序遍历结果呀,等等问题,所以记录下来这个深度depth是有必要的。
基于二叉树的遍历框架,我们又可以扩展出多叉树的层序遍历框架:
// 输入一棵多叉树的根节点,层序遍历这棵多叉树void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue《TreeNode》 q = new LinkedList《》();
q.offer(root);
int depth = 1;
// 从上到下遍历多叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i 《 sz; i++) {
TreeNode cur = q.poll();
printf(“节点 %s 在第 %s 层”, cur, depth);
// 将下一层节点放入队列
for (TreeNode child : root.children) {
q.offer(child);
}
}
depth++;
}
}
基于多叉树的遍历框架,我们又可以扩展出 BFS(广度优先搜索)的算法框架:
// 输入起点,进行 BFS 搜索int BFS(Node start) {
Queue《Node》 q; // 核心数据结构
Set《Node》 visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录搜索的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散一步 */
for (int i = 0; i 《 sz; i++) {
Node cur = q.poll();
printf(“从 %s 到 %s 的最短距离是 %s”, start, cur, step);
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
step++;
}
}
如果对 BFS 算法不熟悉,可以看前文 BFS 算法框架,这里只是为了让你做个对比,所谓 BFS 算法,就是把算法问题抽象成一幅「无权图」,然后继续玩二叉树层级遍历那一套罢了。
注意,我们的 BFS 算法框架也是while循环嵌套for循环的形式,也用了一个step变量记录for循环执行的次数,无非就是多用了一个visited集合记录走过的节点,防止走回头路罢了。
为什么这样呢?
所谓「无权图」,与其说每条「边」没有权重,不如说每条「边」的权重都是 1,从起点start到任意一个节点之间的路径权重就是它们之间「边」的条数,那可不就是step变量记录的值么?
再加上 BFS 算法利用for循环一层一层向外扩散的逻辑和visited集合防止走回头路的逻辑,当你每次从队列中拿出节点cur的时候,从start到cur的最短权重就是step记录的步数。
但是,到了「加权图」的场景,事情就没有这么简单了,因为你不能默认每条边的「权重」都是 1 了,这个权重可以是任意正数(Dijkstra 算法要求不能存在负权重边),比如下图的例子:
如果沿用 BFS 算法中的step变量记录「步数」,显然红色路径一步就可以走到终点,但是这一步的权重很大;正确的最小权重路径应该是绿色的路径,虽然需要走很多步,但是路径权重依然很小。
其实 Dijkstra 和 BFS 算法差不多,不过在讲解 Dijkstra 算法框架之前,我们首先需要对之前的框架进行如下改造:
想办法去掉while循环里面的for循环。
为什么?有了刚才的铺垫,这个不难理解,刚才说for循环是干什么用的来着?
是为了让二叉树一层一层往下遍历,让 BFS 算法一步一步向外扩散,因为这个层数depth,或者这个步数step,在之前的场景中有用。
但现在我们想解决「加权图」中的最短路径问题,「步数」已经没有参考意义了,「路径的权重之和」才有意义,所以这个for循环可以被去掉。
怎么去掉?就拿二叉树的层级遍历来说,其实你可以直接去掉for循环相关的代码:
// 输入一棵二叉树的根节点,遍历这棵二叉树所有节点void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue《TreeNode》 q = new LinkedList《》();
q.offer(root);
// 遍历二叉树的每一个节点
while (!q.isEmpty()) {
TreeNode cur = q.poll();
printf(“我不知道节点 %s 在第几层”, cur);
// 将子节点放入队列
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
}
但问题是,没有for循环,你也没办法维护depth变量了。
如果你想同时维护depth变量,让每个节点cur知道自己在第几层,可以想其他办法,比如新建一个State类,记录每个节点所在的层数:
class State {
// 记录 node 节点的深度
int depth;
TreeNode node;
State(TreeNode node, int depth) {
this.depth = depth;
this.node = node;
}
}
// 输入一棵二叉树的根节点,遍历这棵二叉树所有节点void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue《State》 q = new LinkedList《》();
q.offer(new State(root, 1));
// 遍历二叉树的每一个节点
while (!q.isEmpty()) {
State cur = q.poll();
TreeNode cur_node = cur.node;
int cur_depth = cur.depth;
printf(“节点 %s 在第 %s 层”, cur_node, cur_depth);
// 将子节点放入队列
if (cur_node.left != null) {
q.offer(new State(cur_node.left, cur_depth + 1));
}
if (cur_node.right != null) {
q.offer(new State(cur_node.right, cur_depth + 1));
}
}
}
这样,我们就可以不使用for循环也确切地知道每个二叉树节点的深度了。
如果你能够理解上面这段代码,我们就可以来看 Dijkstra 算法的代码框架了。
Dijkstra 算法框架
首先,我们先看一下 Dijkstra 算法的签名:
// 输入一幅图和一个起点 start,计算 start 到其他节点的最短距离int[] dijkstra(int start, List《Integer》[] graph);
输入是一幅图graph和一个起点start,返回是一个记录最短路径权重的数组。
比方说,输入起点start = 3,函数返回一个int[]数组,假设赋值给distTo变量,那么从起点3到节点6的最短路径权重的值就是distTo[6]。
是的,标准的 Dijkstra 算法会把从起点start到所有其他节点的最短路径都算出来。
当然,如果你的需求只是计算从起点start到某一个终点end的最短路径,那么在标准 Dijkstra 算法上稍作修改就可以更高效地完成这个需求,这个我们后面再说。
其次,我们也需要一个State类来辅助算法的运行:
class State {
// 图节点的 id
int id;
// 从 start 节点到当前节点的距离
int distFromStart;
State(int id, int distFromStart) {
this.id = id;
this.distFromStart = distFromStart;
}
}
类似刚才二叉树的层序遍历,我们也需要用State类记录一些额外信息,也就是使用distFromStart变量记录从起点start到当前这个节点的距离。
刚才说普通 BFS 算法中,根据 BFS 的逻辑和无权图的特点,第一次遇到某个节点所走的步数就是最短距离,所以用一个visited数组防止走回头路,每个节点只会经过一次。
加权图中的 Dijkstra 算法和无权图中的普通 BFS 算法不同,在 Dijkstra 算法中,你第一次经过某个节点时的路径权重,不见得就是最小的,所以对于同一个节点,我们可能会经过多次,而且每次的distFromStart可能都不一样,比如下图:
我会经过节点5三次,每次的distFromStart值都不一样,那我取distFromStart最小的那次,不就是从起点start到节点5的最短路径权重了么?
好了,明白上面的几点,我们可以来看看 Dijkstra 算法的代码模板。
其实,Dijkstra 可以理解成一个带 dp table(或者说备忘录)的 BFS 算法,伪码如下:
// 返回节点 from 到节点 to 之间的边的权重int weight(int from, int to);
// 输入节点 s 返回 s 的相邻节点List《Integer》 adj(int s);
// 输入一幅图和一个起点 start,计算 start 到其他节点的最短距离int[] dijkstra(int start, List《Integer》[] graph) {
// 图中节点的个数
int V = graph.length;
// 记录最短路径的权重,你可以理解为 dp table
// 定义:distTo[i] 的值就是节点 start 到达节点 i 的最短路径权重
int[] distTo = new int[V];
// 求最小值,所以 dp table 初始化为正无穷
Arrays.fill(distTo, Integer.MAX_VALUE);
// base case,start 到 start 的最短距离就是 0
distTo[start] = 0;
// 优先级队列,distFromStart 较小的排在前面
Queue《State》 pq = new PriorityQueue《》((a, b) -》 {
return a.distFromStart - b.distFromStart;
});
// 从起点 start 开始进行 BFS
pq.offer(new State(start, 0));
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
if (curDistFromStart 》 distTo[curNodeID]) {
// 已经有一条更短的路径到达 curNode 节点了
continue;
}
// 将 curNode 的相邻节点装入队列
for (int nextNodeID : adj(curNodeID)) {
// 看看从 curNode 达到 nextNode 的距离是否会更短
int distToNextNode = distTo[curNodeID] + weight(curNodeID, nextNodeID);
if (distTo[nextNodeID] 》 distToNextNode) {
// 更新 dp table
distTo[nextNodeID] = distToNextNode;
// 将这个节点以及距离放入队列
pq.offer(new State(nextNodeID, distToNextNode));
}
}
}
return distTo;
}
对比普通的 BFS 算法,你可能会有以下疑问:
1、没有visited集合记录已访问的节点,所以一个节点会被访问多次,会被多次加入队列,那会不会导致队列永远不为空,造成死循环?
2、为什么用优先级队列PriorityQueue而不是LinkedList实现的普通队列?为什么要按照distFromStart的值来排序?
3、如果我只想计算起点start到某一个终点end的最短路径,是否可以修改算法,提升一些效率?
我们先回答第一个问题,为什么这个算法不用visited集合也不会死循环。
对于这类问题,我教你一个思考方法:
循环结束的条件是队列为空,那么你就要注意看什么时候往队列里放元素(调用offer)方法,再注意看什么时候从队列往外拿元素(调用poll方法)。
while循环每执行一次,都会往外拿一个元素,但想往队列里放元素,可就有很多限制了,必须满足下面这个条件:
// 看看从 curNode 达到 nextNode 的距离是否会更短if (distTo[nextNodeID] 》 distToNextNode) {
// 更新 dp table
distTo[nextNodeID] = distToNextNode;
pq.offer(new State(nextNodeID, distToNextNode));
}
这也是为什么我说distTo数组可以理解成我们熟悉的 dp table,因为这个算法逻辑就是在不断的最小化distTo数组中的元素:
如果你能让到达nextNodeID的距离更短,那就更新distTo[nextNodeID]的值,让你入队,否则的话对不起,不让入队。
因为两个节点之间的最短距离(路径权重)肯定是一个确定的值,不可能无限减小下去,所以队列一定会空,队列空了之后,distTo数组中记录的就是从start到其他节点的最短距离。
接下来解答第二个问题,为什么要用PriorityQueue而不是LinkedList实现的普通队列?
如果你非要用普通队列,其实也没问题的,你可以直接把PriorityQueue改成LinkedList,也能得到正确答案,但是效率会低很多。
Dijkstra 算法使用优先级队列,主要是为了效率上的优化,类似一种贪心算法的思路。
为什么说是一种贪心思路呢,比如说下面这种情况,你想计算从起点start到终点end的最短路径权重:
你下一步想遍历那个节点?就当前的情况来看,你觉得哪条路径更有「潜力」成为最短路径中的一部分?
从目前的情况来看,显然橙色路径的可能性更大嘛,所以我们希望节点2排在队列靠前的位置,优先被拿出来向后遍历。
所以我们使用PriorityQueue作为队列,让distFromStart的值较小的节点排在前面,这就类似我们之前讲 贪心算法 说到的贪心思路,可以很大程度上优化算法的效率。
大家应该听过 Bellman-Ford 算法,这个算法是一种更通用的最短路径算法,因为它可以处理带有负权重边的图,Bellman-Ford 算法逻辑和 Dijkstra 算法非常类似,用到的就是普通队列,本文就提一句,后面有空再具体写。
接下来说第三个问题,如果只关心起点start到某一个终点end的最短路径,是否可以修改代码提升算法效率。
肯定可以的,因为我们标准 Dijkstra 算法会算出start到所有其他节点的最短路径,你只想计算到end的最短路径,相当于减少计算量,当然可以提升效率。
需要在代码中做的修改也非常少,只要改改函数签名,再加个 if 判断就行了:
// 输入起点 start 和终点 end,计算起点到终点的最短距离int dijkstra(int start, int end, List《Integer》[] graph) {
// 。..
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
// 在这里加一个判断就行了,其他代码不用改
if (curNodeID == end) {
return curDistFromStart;
}
if (curDistFromStart 》 distTo[curNodeID]) {
continue;
}
// 。..
}
// 如果运行到这里,说明从 start 无法走到 end
return Integer.MAX_VALUE;
}
因为优先级队列自动排序的性质,每次从队列里面拿出来的都是distFromStart值最小的,所以当你从队头拿出一个节点,如果发现这个节点就是终点end,那么distFromStart对应的值就是从start到end的最短距离。
这个算法较之前的实现提前 return 了,所以效率有一定的提高。
时间复杂度分析
Dijkstra 算法的时间复杂度是多少?你去网上查,可能会告诉你是O(ElogV),其中E代表图中边的条数,V代表图中节点的个数。
因为理想情况下优先级队列中最多装V个节点,对优先级队列的操作次数和E成正比,所以整体的时间复杂度就是O(ElogV)。
不过这是理想情况,Dijkstra 算法的代码实现有很多版本,不同编程语言或者不同数据结构 API 都会导致算法的时间复杂度发生一些改变。
比如本文实现的 Dijkstra 算法,使用了 Java 的PriorityQueue这个数据结构,这个容器类底层使用二叉堆实现,但没有提供通过索引操作队列中元素的 API,所以队列中会有重复的节点,最多可能有E个节点存在队列中。
所以本文实现的 Dijkstra 算法复杂度并不是理想情况下的O(ElogV),而是O(ElogE),可能会略大一些,因为图中边的条数一般是大于节点的个数的。
不过就对数函数来说,就算真数大一些,对数函数的结果也大不了多少,所以这个算法实现的实际运行效率也是很高的,以上只是理论层面的时间复杂度分析,供大家参考。
秒杀三道题目
以上说了 Dijkstra 算法的框架,下面我们套用这个框架做几道题,实践出真知。
第一题是力扣第 743 题「网络延迟时间」,题目如下:
函数签名如下:
// times 记录边和权重,n 为节点个数(从 1 开始),k 为起点// 计算从 k 发出的信号至少需要多久传遍整幅图int networkDelayTime(int[][] times, int n, int k)
让你求所有节点都收到信号的时间,你把所谓的传递时间看做距离,实际上就是问你「从节点k到其他所有节点的最短路径中,最长的那条最短路径距离是多少」,说白了就是让你算从节点k出发到其他所有节点的最短路径,就是标准的 Dijkstra 算法。
在用 Dijkstra 之前,别忘了要满足一些条件,加权有向图,没有负权重边,OK,可以用 Dijkstra 算法计算最短路径。
根据我们之前 Dijkstra 算法的框架,我们可以写出下面代码:
public int networkDelayTime(int[][] times, int n, int k) {
// 节点编号是从 1 开始的,所以要一个大小为 n + 1 的邻接表
List《int[]》[] graph = new LinkedList[n + 1];
for (int i = 1; i 《= n; i++) {
graph[i] = new LinkedList《》();
}
// 构造图
for (int[] edge : times) {
int from = edge[0];
int to = edge[1];
int weight = edge[2];
// from -》 List《(to, weight)》
// 邻接表存储图结构,同时存储权重信息
graph[from].add(new int[]{to, weight});
}
// 启动 dijkstra 算法计算以节点 k 为起点到其他节点的最短路径
int[] distTo = dijkstra(k, graph);
// 找到最长的那一条最短路径
int res = 0;
for (int i = 1; i 《 distTo.length; i++) {
if (distTo[i] == Integer.MAX_VALUE) {
// 有节点不可达,返回 -1
return -1;
}
res = Math.max(res, distTo[i]);
}
return res;
}
// 输入一个起点 start,计算从 start 到其他节点的最短距离int[] dijkstra(int start, List《int[]》[] graph) {}
上述代码首先利用题目输入的数据转化成邻接表表示一幅图,接下来我们可以直接套用 Dijkstra 算法的框架:
class State {
// 图节点的 id
int id;
// 从 start 节点到当前节点的距离
int distFromStart;
State(int id, int distFromStart) {
this.id = id;
this.distFromStart = distFromStart;
}
}
// 输入一个起点 start,计算从 start 到其他节点的最短距离int[] dijkstra(int start, List《int[]》[] graph) {
// 定义:distTo[i] 的值就是起点 start 到达节点 i 的最短路径权重
int[] distTo = new int[graph.length];
Arrays.fill(distTo, Integer.MAX_VALUE);
// base case,start 到 start 的最短距离就是 0
distTo[start] = 0;
// 优先级队列,distFromStart 较小的排在前面
Queue《State》 pq = new PriorityQueue《》((a, b) -》 {
return a.distFromStart - b.distFromStart;
});
// 从起点 start 开始进行 BFS
pq.offer(new State(start, 0));
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
if (curDistFromStart 》 distTo[curNodeID]) {
continue;
}
// 将 curNode 的相邻节点装入队列
for (int[] neighbor : graph[curNodeID]) {
int nextNodeID = neighbor[0];
int distToNextNode = distTo[curNodeID] + neighbor[1];
// 更新 dp table
if (distTo[nextNodeID] 》 distToNextNode) {
distTo[nextNodeID] = distToNextNode;
pq.offer(new State(nextNodeID, distToNextNode));
}
}
}
return distTo;
}
你对比之前说的代码框架,只要稍稍修改,就可以把这道题目解决了。
感觉这道题完全没有难度,下面我们再看一道题目,力扣第 1631 题「最小体力消耗路径」:
函数签名如下:
// 输入一个二维矩阵,计算从左上角到右下角的最小体力消耗int minimumEffortPath(int[][] heights);
我们常见的二维矩阵题目,如果让你从左上角走到右下角,比较简单的题一般都会限制你只能向右或向下走,但这道题可没有限制哦,你可以上下左右随便走,只要路径的「体力消耗」最小就行。
如果你把二维数组中每个(x, y)坐标看做一个节点,它的上下左右坐标就是相邻节点,它对应的值和相邻坐标对应的值之差的绝对值就是题目说的「体力消耗」,你就可以理解为边的权重。
这样一想,是不是就在让你以左上角坐标为起点,以右下角坐标为终点,计算起点到终点的最短路径?Dijkstra 算法是不是可以做到?
// 输入起点 start 和终点 end,计算起点到终点的最短距离int dijkstra(int start, int end, List《Integer》[] graph)
只不过,这道题中评判一条路径是长还是短的标准不再是路径经过的权重总和,而是路径经过的权重最大值。
明白这一点,再想一下使用 Dijkstra 算法的前提,加权有向图,没有负权重边,求最短路径,OK,可以使用,咱们来套框架。
二维矩阵抽象成图,我们先实现一下图的adj方法,之后的主要逻辑会清晰一些:
// 方向数组,上下左右的坐标偏移量int[][] dirs = new int[][]{{0,1}, {1,0}, {0,-1}, {-1,0}};
// 返回坐标 (x, y) 的上下左右相邻坐标
List《int[]》 adj(int[][] matrix, int x, int y) {
int m = matrix.length, n = matrix[0].length;
// 存储相邻节点
List《int[]》 neighbors = new ArrayList《》();
for (int[] dir : dirs) {
int nx = x + dir[0];
int ny = y + dir[1];
if (nx 》= m || nx 《 0 || ny 》= n || ny 《 0) {
// 索引越界
continue;
}
neighbors.add(new int[]{nx, ny});
}
return neighbors;
}
类似的,我们现在认为一个二维坐标(x, y)是图中的一个节点,所以这个State类也需要修改一下:
class State {
// 矩阵中的一个位置
int x, y;
// 从起点 (0, 0) 到当前位置的最小体力消耗(距离)
State(int x, int y, int effortFromStart) {
this.x = x;
this.y = y;
this.effortFromStart = effortFromStart;
}
}
接下来,就可以套用 Dijkstra 算法的代码模板了:
// Dijkstra 算法,计算 (0, 0) 到 (m - 1, n - 1) 的最小体力消耗int minimumEffortPath(int[][] heights) {
int m = heights.length, n = heights[0].length;
// 定义:从 (0, 0) 到 (i, j) 的最小体力消耗是 effortTo[i][j]
int[][] effortTo = new int[m][n];
// dp table 初始化为正无穷
for (int i = 0; i 《 m; i++) {
Arrays.fill(effortTo[i], Integer.MAX_VALUE);
}
// base case,起点到起点的最小消耗就是 0
effortTo[0][0] = 0;
// 优先级队列,effortFromStart 较小的排在前面
Queue《State》 pq = new PriorityQueue《》((a, b) -》 {
return a.effortFromStart - b.effortFromStart;
});
// 从起点 (0, 0) 开始进行 BFS
pq.offer(new State(0, 0, 0));
while (!pq.isEmpty()) {
State curState = pq.poll();
int curX = curState.x;
int curY = curState.y;
int curEffortFromStart = curState.effortFromStart;
// 到达终点提前结束
if (curX == m - 1 && curY == n - 1) {
return curEffortFromStart;
}
if (curEffortFromStart 》 effortTo[curX][curY]) {
continue;
}
// 将 (curX, curY) 的相邻坐标装入队列
for (int[] neighbor : adj(heights, curX, curY)) {
int nextX = neighbor[0];
int nextY = neighbor[1];
// 计算从 (curX, curY) 达到 (nextX, nextY) 的消耗
int effortToNextNode = Math.max(
effortTo[curX][curY],
Math.abs(heights[curX][curY] - heights[nextX][nextY])
);
// 更新 dp table
if (effortTo[nextX][nextY] 》 effortToNextNode) {
effortTo[nextX][nextY] = effortToNextNode;
pq.offer(new State(nextX, nextY, effortToNextNode));
}
}
}
// 正常情况不会达到这个 return
return -1;
}
你看,稍微改一改代码模板,这道题就解决了。
最后看一道题吧,力扣第 1514 题「概率最大的路径」,看下题目:
函数签名如下:
// 输入一幅无向图,边上的权重代表概率,返回从 start 到达 end 最大的概率double maxProbability(int n, int[][] edges, double[] succProb, int start, int end)
我说这题一看就是 Dijkstra 算法,但聪明的你肯定会反驳我:
1、这题给的是无向图,也可以用 Dijkstra 算法吗?
2、更重要的是,Dijkstra 算法计算的是最短路径,计算的是最小值,这题让你计算最大概率是一个最大值,怎么可能用 Dijkstra 算法呢?
问得好!
首先关于有向图和无向图,前文 图算法基础 说过,无向图本质上可以认为是「双向图」,从而转化成有向图。
重点说说最大值和最小值这个问题,其实 Dijkstra 和很多最优化算法一样,计算的是「最优值」,这个最优值可能是最大值,也可能是最小值。
标准 Dijkstra 算法是计算最短路径的,但你有想过为什么 Dijkstra 算法不允许存在负权重边么?
因为 Dijkstra 计算最短路径的正确性依赖一个前提:路径中每增加一条边,路径的总权重就会增加。
这个前提的数学证明大家有兴趣可以自己搜索一下,我这里只说结论,其实你把这个结论反过来也是 OK 的:
如果你想计算最长路径,路径中每增加一条边,路径的总权重就会减少,要是能够满足这个条件,也可以用 Dijkstra 算法。
你看这道题是不是符合这个条件?边和边之间是乘法关系,每条边的概率都是小于 1 的,所以肯定会越乘越小。
只不过,这道题的解法要把优先级队列的排序顺序反过来,一些 if 大小判断也要反过来,我们直接看解法代码吧:
double maxProbability(int n, int[][] edges, double[] succProb, int start, int end) {
List《double[]》[] graph = new LinkedList[n];
for (int i = 0; i 《 n; i++) {
graph[i] = new LinkedList《》();
}
// 构造邻接表结构表示图
for (int i = 0; i 《 edges.length; i++) {
int from = edges[i][0];
int to = edges[i][1];
double weight = succProb[i];
// 无向图就是双向图;先把 int 统一转成 double,待会再转回来
graph[from].add(new double[]{(double)to, weight});
graph[to].add(new double[]{(double)from, weight});
}
return dijkstra(start, end, graph);
}
class State {
// 图节点的 id
int id;
// 从 start 节点到达当前节点的概率
double probFromStart;
State(int id, double probFromStart) {
this.id = id;
this.probFromStart = probFromStart;
}
}
double dijkstra(int start, int end, List《double[]》[] graph) {
// 定义:probTo[i] 的值就是节点 start 到达节点 i 的最大概率
double[] probTo = new double[graph.length];
// dp table 初始化为一个取不到的最小值
Arrays.fill(probTo, -1);
// base case,start 到 start 的概率就是 1
probTo[start] = 1;
// 优先级队列,probFromStart 较大的排在前面
Queue《State》 pq = new PriorityQueue《》((a, b) -》 {
return Double.compare(b.probFromStart, a.probFromStart);
});
// 从起点 start 开始进行 BFS
pq.offer(new State(start, 1));
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
double curProbFromStart = curState.probFromStart;
// 遇到终点提前返回
if (curNodeID == end) {
return curProbFromStart;
}
if (curProbFromStart 《 probTo[curNodeID]) {
// 已经有一条概率更大的路径到达 curNode 节点了
continue;
}
// 将 curNode 的相邻节点装入队列
for (double[] neighbor : graph[curNodeID]) {
int nextNodeID = (int)neighbor[0];
// 看看从 curNode 达到 nextNode 的概率是否会更大
double probToNextNode = probTo[curNodeID] * neighbor[1];
if (probTo[nextNodeID] 《 probToNextNode) {
probTo[nextNodeID] = probToNextNode;
pq.offer(new State(nextNodeID, probToNextNode));
}
}
}
// 如果到达这里,说明从 start 开始无法到达 end,返回 0
return 0.0;
}
好了,到这里本文就结束了,总共 6000 多字,这三道例题都是比较困难的,如果你能够看到这里,真得给你鼓掌。
还是那句话,做题在质不在量,希望大家能够透彻理解最基本的数据结构,以不变应万变。
责任编辑:haq
-
数据
+关注
关注
8文章
7026浏览量
89026 -
网络
+关注
关注
14文章
7565浏览量
88778 -
模板
+关注
关注
0文章
108浏览量
20563
原文标题:我写了一个模板,把 Dijkstra 算法变成了默写题
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【面试题】人工智能工程师高频面试题汇总:机器学习深化篇(题目+答案)
【「从算法到电路—数字芯片算法的电路实现」阅读体验】+内容简介
【「从算法到电路—数字芯片算法的电路实现」阅读体验】+介绍基础硬件算法模块
11.11福利加码!新增爆款商品与大额优惠券秒杀,全场1折起,错过等一年!

AIC3262 CODEC能否在安卓下运用?
请问GDE中的NR算法反应慢怎么解决?
名单公布!【书籍评测活动NO.46】从算法到电路 | 数字芯片算法的电路实现
怎么运用耦合电容的同时防止自激?
AGV系统设计解析:布局-车体-对接-数量计算-路径规划

新疆维吾尔自治区矿山智能化政策文件对AI算法模型的要求

中国铁路网的Dijkstra算法实现案例






 工商网监
工商网监
评论