 如何在Colab中使用SQL
如何在Colab中使用SQL
如今,编码测试在数据科学面试过程中几乎是标准的。
作为一名数据科学招聘经理,我发现一个20-30分钟的现场编码测试和一些准备好的任务能够有效地识别那些能够胜任职位的候选人。
Google Colab[https://colab.research.google.com/notebooks/intro.ipynb?utm_source=scs-index]是各种离线和实时数据科学编码的优秀工具,因为它熟悉的笔记本环境和并且方便共享。但是Colab几乎只限于Python(还有一些黑客攻击)。
根据我个人的经验,SQL是成为一名成功的数据科学家的关键技能。深度学习是很好的,但是如果你不能编写SQL查询,你可能永远都会被你的猫对狗分类器所困扰。
因此,我开始寻找进行实时SQL编码测试的方法,瞧!我偶然发现了这种在Colab(或任何Python环境)中运行SQL的简单方法,实际上只有2个helper函数。
在本文中,我将介绍两个Python函数,我们可以使用它们在Google Colab中设置和运行SQL,具体如下:
在Google Colab中创建一个数据库并将数据帧上传到该数据库中的一个表中
在GoogleColab中对该数据库和表编写和执行SQL查询。
所有代码都可以在我的Github帐户上找到。你也可以直接在谷歌Colab上打开代码, 单击此链接:
https://colab.research.google.com/github/stephenleo/medium-python-hacks/blob/main/02_sql_on_colab/main.ipynb
SQLite
失败是成功之母
在这次搜索之前,我只隐约听说过SQLite,但从未需要深入研究它。
SQLite…实现了一个小型、快速、自包含、高可靠性、功能齐全的SQL数据库引擎。
SQLite是世界上使用最多的数据库引擎。SQLite内置于所有手机和大多数计算机中,并捆绑在人们每天使用的应用程序中。
听起来很有希望!SQLite的工作原理是创建一个本地的.db文件,我们可以像普通的SQL数据库一样连接到该文件。然后我们可以在这个.db文件上创建表、上传数据和查询数据。
另外,用于创建SQLite并与之交互的Python模块(sqlite3)也是Python标准库的一部分。所以它在Colab上是开箱即用的。
首先,让我们导入sqlite3和pandas模块,它们是我们任务的唯一需求
importsqlite3
importpandasaspd
函数1:将Dataframe转换为SQL DB表
我们的第一个任务是创建一个数据库,并将一个数据帧上传到该数据库中的一个表中。
下面的代码将其作为一个函数实现,我将逐步介绍。该函数将输入数据帧、表名称和数据库名称(.db)作为输入,并运行以下步骤。
-
设置一些日志以跟踪函数的执行
-
查找数据框中的所有列。这是必要的,因为我们需要在创建表和将数据上载到表时提供此信息。
-
连接到.db文件(如果存在)。如果文件不存在,请在本地计算机上创建新文件。
-
在.db文件中创建一个表,我们在上一步中连接到该表(或刚刚创建)
-
将 input_df 中的数据行上传到我们在上一步中刚刚创建的表中
-
提交更改并关闭与数据库的连接
defpd_to_sqlDB(input_df:pd.DataFrame,
table_name:str,
db_name:str='default.db')->None:
'''
取一个数据帧'input_df'并将其上传到'table_name'SQLITE表
Args:
input_df(pd.DataFrame):包含要上传到SQLITE的数据的数据帧
table_name(str):要上传的SQLITE表的名称
db_name (str, optional):创建表的SQLITE数据库的名称。
默认为“default.db”
'''
#步骤1:设置本地日志
importlogging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s%(levelname)s:%(message)s',
datefmt='%Y-%m-%d%H:%M:%S')
#步骤2:在数据帧中查找列
cols=input_df.columns
cols_string=','.join(cols)
val_wildcard_string=','.join(['?']*len(cols))
#步骤3:如果DB文件存在,连接到它,否则创建一个新文件
con=sqlite3.connect(db_name)
cur=con.cursor()
logging.info(f'SQLDB{db_name}created')
#步骤4:创建表
sql_string=f"""CREATETABLE{table_name}({cols_string});"""
cur.execute(sql_string)
logging.info(f'SQLTable{table_name}createdwith{len(cols)}columns')
#步骤5:上传数据帧
rows_to_upload=input_df.to_dict(orient='split')['data']
sql_string=f"""INSERTINTO{table_name}({cols_string})VALUES({val_wildcard_string});"""
cur.executemany(sql_string,rows_to_upload)
logging.info(f'{len(rows_to_upload)}rowsuploadedto{table_name}')
#步骤6:提交更改并关闭连接
con.commit()
con.close()
函数2:对数据帧的SQL查询
我们的第二个任务是在第一个任务中创建的数据库和表上编写和执行SQL查询。
下面的代码将其作为另一个函数实现,我也将逐步介绍。该函数将sql_query_string和db_name(.db file)作为输入,运行以下步骤,并返回一个dataframe作为输出。
-
连接到.DB文件中的SQL DB
-
在SQL查询字符串中执行SQL查询
-
运行SQL查询后获取结果数据和输出的列名
-
关闭与数据库的连接
-
将结果作为数据帧返回
defsql_query_to_pd(sql_query_string:str,db_name:str='default.db')->pd.DataFrame:
'''执行一个SQL查询,并以数据帧的形式返回结果
Args:
sql_query_string(str):要执行的SQL查询字符串
db_name(str,optional)::要执行查询的SQLITE数据库的名称
默认为“default.db”
Returns:
pd.DataFrame:数据帧中SQL查询的结果
'''
#步骤1:连接SQL数据库
con=sqlite3.connect(db_name)
#步骤2:执行SQL查询
cursor=con.execute(sql_query_string)
#步骤3:获取数据和列名
result_data=cursor.fetchall()
cols=[description[0]fordescriptionincursor.description]
#步骤4:关闭连接
con.close()
#步骤5:返回数据帧
returnpd.DataFrame(result_data,columns=cols)
差不多就是这样!我们现在有两个函数,可以粘贴到任何Colab笔记本中,以解决我们的两个任务。让我们通过一个例子来看看如何使用这两个函数
使用这两个函数在Colab中运行SQL
由于新冠病毒基本上是我们这些天谈论的唯一话题,我从Kaggle下载了一个新冠病毒疫苗样本数据集,以测试我们的两个函数函数的使用非常简单,如下所示
-
将下载的csv文件加载到数据帧中
-
使用我们的第一个函数pd_to_sqlDB函数将我们在上一步中加载的数据帧上载到名为default.DB的数据库中名为 country_vaccination 的表中
-
在名为 sql_query_string 的字符串变量中编写SQL查询。正如你在下面的代码片段中所看到的,我们可以编写任何可以想到的复杂SQL查询。
-
使用第二个函数sql_query_to_pd在default.db上执行上一步的sql查询,并将结果保存在result_df数据框中
#步骤1:读取csv文件到一个数据帧
#数据集来自https://www.kaggle.com/gpreda/covid-world-vaccination-progress
input_df=pd.read_csv('country_vaccinations.csv')
#步骤2:上传数据帧到SQL表
pd_to_sqlDB(input_df,
table_name='country_vaccinations',
db_name='default.db')
#步骤3:在字符串变量中写入SQL查询
sql_query_string="""
SELECTcountry,SUM(daily_vaccinations)astotal_vaccinated
FROMcountry_vaccinations
WHEREdaily_vaccinationsISNOTNULL
GROUPBYcountry
ORDERBYtotal_vaccinatedDESC
"""
#步骤4:执行SQL查询
result_df=sql_query_to_pd(sql_query_string,db_name='default.db')
result_df

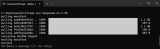
从结果中,我们可以看到(在撰写本文时),中国的接种人数居世界首位,其次是印度和美国。我们通过在GoogleColab中对DB执行SQL查询得到了这些结果!
给你。现在,你可以在下次面试中展示你卓越的Python和SQL知识了!
另外,节省一些时间,直接使用我在本文开头链接的GoogleColab笔记本,它包含上述函数和示例查询。
-
SQL
+关注
关注
1文章
775浏览量
44317 -
函数
+关注
关注
3文章
4350浏览量
63079 -
代码
+关注
关注
30文章
4841浏览量
69225 -
python
+关注
关注
56文章
4811浏览量
85124
原文标题:在Colab中使用SQL
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在MATLAB中使用DeepSeek模型
如何在Windows中使用MTP协议
如何在RS-485网络中使用MSP430和MSP432 eUSCI和USCI模块

如何在显示器设计中使用TPS6598x I2C控制TUSB564
如何在IMC300系列中使用开环控制?
请问cmakelists中的变量如何在程序中使用?
工业计算机是什么?如何在不同行业中使用?






 工商网监
工商网监
评论