 如何制作数据可视化大屏
如何制作数据可视化大屏
经常有小伙伴问,如何制作数据可视化大屏?
今天将手把手带你爬取奥运会相关信息,并利用可视化大屏为你展示奥运详情。让一个没关注过奥运会的朋友,也能够秒懂奥运会。
1、项目背景
奥运会刚刚过去,你是否已经看过2020东京奥运会呢?
2、奥运会相关信息爬取
- 爬取字段: 国家、国家ID、排名、金牌数、银牌数、铜牌数、奖牌总数、项目名、运动员、获奖类型、获奖时间;
- 爬取说明: 基于两个接口的数据爬取【json格式的数据】,直接采用键值对的方式获取相关数据;
- 使用工具: Pandas+requests
本文是基于两个接口的数据爬取,相对容易的多。
#这个链接主要展示:各国的金银铜牌及其总数!
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
#这个链接主要展示:每个参赛队员的参赛项目和获得的奖牌情况!
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
① 导入相关库
importrequests
importpandasaspd
frompprintimportpprint
requests库用于发起网页请求,获取网页中的源代码;
pandas库用于存储和读取获取到的信息;
pprint库是漂亮的打印,对于json格式的数据,能够很好的展示结构,方便我们解析;
② 爬虫讲解
url='https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609'
data=requests.get(url).json()
pprint(data)
三行代码就可以获取到网页的源代码,利用pprint库,可以清晰的展示json结构,对于我们解析数据很有帮助。
我们要的数据,都存在于body键下面的allMedalData键中,allMedalData键的值是一个列表,里面有很多字典组成的键值对信息,就是我们要爬取的数据。
直接利用键获取对应的值信息,代码如下:
df1=pd.DataFrame()
forinfoindata1['body']['allMedalData']:
name=info['countryName']
name_id=info['countryId']
rank=info['rank']
gold=info['goldMedalNum']
silver=info['silverMedalNum']
bronze=info['bronzeMedalNum']
total=info['totalMedalNum']
#组织数据
orangized_data=[[name,name_id,rank,gold,silver,bronze,total]]
#然后追加df
df1=df1.append(orangized_data)
df1.columns=['名称','ID','排名','金牌','银牌','铜牌','奖牌总数']
df1
对于另外一个网页,我们采取同样的方式。
url='https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609'
data2=requests.get(url).json()
pprint(data2)
是不是此时感觉结构更清楚了?
df2=pd.DataFrame()
forinfoindata2['body']['medalTableDetail']:
english_name=info['countryName']
name_id=info['countryId']
award_time=info['awardTime']
item_name=info['bigItemName']
sports_name=info['sportsName']
medal_type=info['medalType']
#组织数据
orangized_data=[[english_name,name_id,award_time,item_name,sports_name,medal_type]]
#然后追加df
df2=df2.append(orangized_data)
df2.columns=['英文缩写','ID','获奖时间','项目名','运动员','金牌类型']
df2
3、数据预处理
对于爬取到的数据,往往是有问题的,我们需要提前预处理一下,方便后续做可视化展示。
① 数据拼接
对我们共有三个表格,分别存储着不同的信息。我们需要对其进行合适的拼接,方便最后可视化。
表格df1表示各国奖牌数,数据是这样的:
表格df3表示国家名中英文对照表,数据是这样的:
利用上述两张表,我们可以左连接,将英文名称添加到df1表上。
df4=pd.merge(df1,df3,on="名称",how="left")
df4.head(10)
最终效果如下:
表格df5表示运动项目获奖详情,数据是这样的:
此时,我们又可以将df4和df5做一个左连接,将这两张表合成一张大表,就可以得到不同国家不同项目获得的奖牌数。
df6=pd.merge(df4,df5,on="名称",how="left")
df6.head(10)
② 关于金牌类型的说明
上面得到的表df6,其实还不是最后的表,因为上述表中金牌类型是数字1、2、3,但是我们需要的是金牌、银牌、铜牌。因此,我们自己再定义一个df7。
x={"获奖名次":["金牌","银牌","铜牌"],"金牌类型":[1,2,3]}
df7=pd.DataFrame(x)
df7
效果如下:
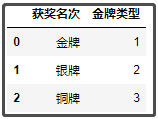
因此,我们拿df6与自己构造得到的df7再做一个左连接,就可以的到最后完整的表了。
df8=pd.merge(df6,df7,on="名称",how="left")
df8.head(10)
③ 中英文名映射转换
由于使用pyecharts绘制世界地图时,名称必须是英文的,所以我们需要将这里的中文名称映射为英文名称。于是我在网上找到了下面这个文件:
我们要做的就是将它与表格中的数据,做个映射转换。先把它转换为一个Excel文件吧,方便我们以后直接使用。
withopen("国家名中英文对照表.txt","r",encoding="utf-8")asf:
x=f.read()
df3=pd.DataFrame()
foriinx.split("
"):
x=i.split(":")[0].strip()
y=i.split(":")[1].strip()
orangined_data=[[x,y]]
df3=df3.append(orangined_data)
df3.columns=["名称","英文名称"]
df3.to_excel("国家名中英文对照表.xlsx",index=None)
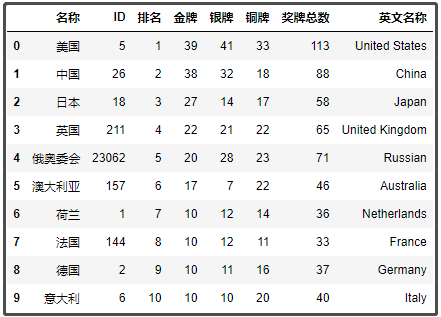
然后,在和上述的df2表格做一个左连接即可。
df4=pd.merge(df2,df3,on="名称",how="left")
df4
结果如下:
4、可视化展示
关于可视化部分,使用的是pyecharts库。这部分一共分以下8个主题:
- ① 2020东京奥运会各国奖牌分布图;
- ② 2020东京奥运会奖牌榜详情;
- ③ 2020东京奥运会奖牌榜总数前十名;
- ④ 2020东京奥运会金牌榜总数前十名;
- ⑤ 2020东京奥运会中国各项目获奖详情;
- ⑥ 中国选手每日获得奖牌数;
- ⑦ 中国选手每日获得金牌数;
- ⑧ 中国选手夺金详细数据;
说明: 这里就不做结果分析了,因为通过上图,相信大家应该能够很清晰的了解到2020东京奥运会,哪怕你没看过。
责任编辑:haq-
可视化
+关注
关注
1文章
1210浏览量
21238 -
python
+关注
关注
56文章
4813浏览量
85316
原文标题:用 Python 制作可视化大屏,特简单!
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
七款经久不衰的数据可视化工具!

智慧能源可视化监管平台——助力可视化能源数据管理

大屏数据可视化 开源
如何实现园区大屏可视化?








 工商网监
工商网监
评论