 一文了解Cortex-M中断向量表对齐原则
一文了解Cortex-M中断向量表对齐原则
来源 | 痞子衡嵌入式
一、Cortex-M中断向量表对齐原则
中断向量表就是一个集中保存系统全部中断处理函数(xxxIRQHandler)地址的常量数组(函数地址要占 4 个字节,因此数组中每个元素大小为 4 字节),表中元素编号如下:
1. 中断向量表第 0 - 1 个向量比较特殊,是程序初始 SP 和 PC 值
2. 中断向量表第 2 - 15 个向量是系统中断,IRQ 编号为 -14 到 -1
3. 中断向量表第 16 个向量开始是厂商自定义外设中断,IRQ 编号为 0 到 n
- 对于 Cortex-M0/0+/1, ARM 建议的 n 值最大为 15(实际一般厂商都会扩展)
- 对于 Cortex-M3/4/7/23, ARM 建议的 n 值最大为 239
- 对于 Cortex-M33/35P/55, ARM 建议的 n 值最大为 479
Cortex-M 内核(除了CM0)模块 SCB 里有个专门的 VTOR 寄存器用来控制中断向量表首地址,程序运行起来后用户可以配置 SCB->VTOR 寄存器来重设中断向量表地址。
SCB->VTOR 寄存器低 7bit 是保留的(永远0),所以中断向量表首地址一定要是 128 字节(0x80)对齐的,这个毫无疑问!但是仅仅 128 字节对齐就行了吗?这个是要看情况的,如下 Cortex-M Generic User Guide 手册里关于 VTOR 寄存器描述里有这样一段话(红框内),这段话的意思是向量表首地址需要按 0x80 向上对齐(还得是 2 的整数幂)以覆盖项目中实际用到的数值最大中断号(xxx_IRQn)。
- Note: 比如项目中实际用到最大外设中断为 IRQ20,则最小向量表大小为(16 + 21)* 4 字节,那么向量表首地址需要至少以 0x100 对齐。
二、Cortex-M中断向量表不对齐的后果
如果中断向量表首地址没有按规定对齐,会发生什么后果呢?我们找一块板卡来实测下,选择的芯片是恩智浦 i.MXRT1011,这是颗 Cortex-M7 内核的 MCU,除了 16 个系统中断外,还包含 80 个外设中断,中断向量表里一共 96 个有效中断。
因为 i.MXRT1011 里一共 96 个中断,按规定,中断向量表首地址至少要按 0x200 对齐。我们现在故意不按规定来设对齐,先选择一个测试工程 SDK_2.10.0_EVK-MIMXRT1010oardsevkmimxrt1010demo_appshello_worldiar(flexspi_nor_build),修改 hello_world.c 文件,加一个 relocate_vector_table() 函数,将中断向量表重定向到 NEW_VECTOR_ADDRESS:
#defineNEW_VECTOR_ADDRESS(0x00000080)
externuint32_t__VECTOR_TABLE[];
voidrelocate_vector_table(void)
{
__disable_irq();
//将0x60002000处的初始中断向量表拷贝到新地址NEW_VECTOR_ADDRESS
memcpy((void*)NEW_VECTOR_ADDRESS,(void*)__VECTOR_TABLE,0x180);
//将VTOR指向NEW_VECTOR_ADDRESS
SCB->VTOR=NEW_VECTOR_ADDRESS;
__enable_irq();
}
intmain(void)
{
relocate_vector_table();
//其余代码
}
万事俱备,我们现在需要使能一些中断来验证,痞子衡分别选取了 SysTick、LPUART1、GPT2、WDOG2、TEMP_LOW_HIGH、WDOG1 六个中断,它们的使能代码都可以从 SDKoardsevkmimxrt1010driver_examples 里找到,这里不予赘述。
2.1 测试以 0x80 对齐的中断向量表
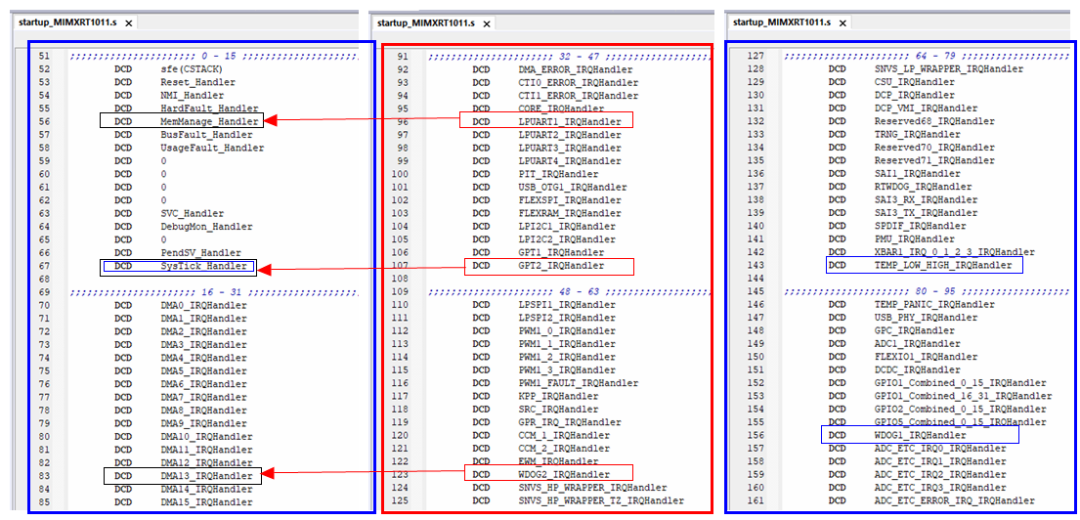
将 NEW_VECTOR_ADDRESS 设为 ITCM 偏移 0x80 处,则中断向量表被重定向到了按 0x80 对齐的地方,分别测试选定的 6 个中断,最终结果如下:SysTick、TEMP_LOW_HIGH、WDOG1 中断响应是正常的,而 LPUART1、GPT2、WDOG2 实际响应的中断函数却是 MemManage、SysTick、DMA13 位置,这里出现了异常。
#defineNEW_VECTOR_ADDRESS(0x00000080)
2.2 测试以 0x100 对齐的中断向量表
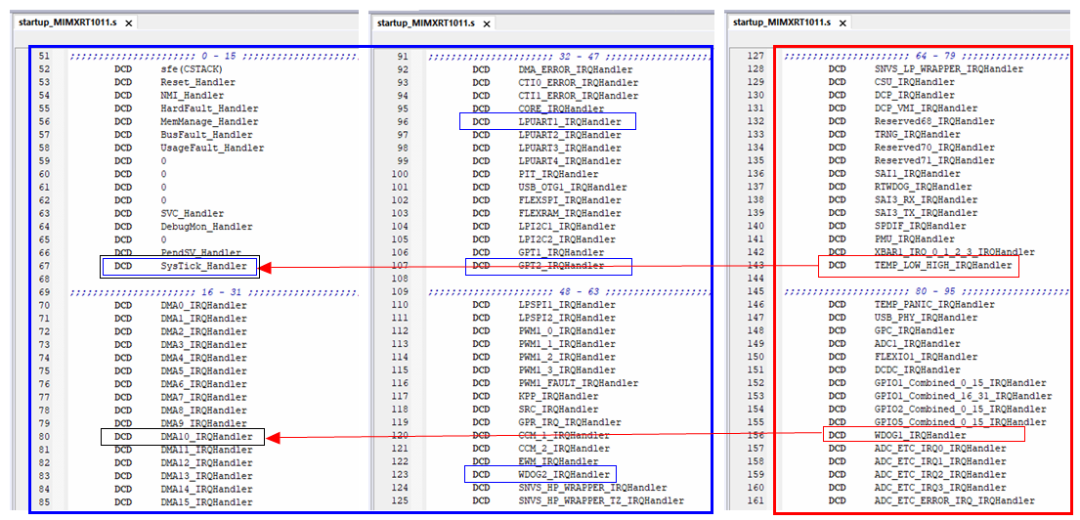
将 NEW_VECTOR_ADDRESS 设为 ITCM 偏移 0x100 处,则中断向量表被重定向到了按 0x100 对齐的地方,分别测试选定的 6 个中断,最终结果如下:SysTick、LPUART1、GPT2、WDOG2 中断响应是正常的,而 TEMP_LOW_HIGH、WDOG1 实际响应的中断函数却是 SysTick、DMA10 位置,还是出现了异常。
#defineNEW_VECTOR_ADDRESS(0x00000100)
2.3 测试以 0x180 对齐的中断向量表
将 NEW_VECTOR_ADDRESS 设为 ITCM 偏移 0x180 处,则中断向量表被重定向到了按 0x180 对齐的地方,实测效果跟 2.1 节一致。
#defineNEW_VECTOR_ADDRESS(0x00000180)
2.4 测试以 0x200 对齐的中断向量表
将 NEW_VECTOR_ADDRESS 设为 ITCM 偏移 0x200 处,则中断向量表被重定向到了按 0x200 对齐的地方,6 个中断都能正常响应,毕竟是符合 ARM 手册里对齐规定。
#defineNEW_VECTOR_ADDRESS(0x00000200)
2.5 测试结果总结
因为 i.MXRT1011 最多仅 96 个有效中断,有些对齐测试不能完全覆盖,痞子衡后来又在 i.MXRT1176 上(最多 234 个有效中断)以同样方式测了一遍,最终总结到现象如下(该现象可用来精简向量表,下文再聊):
1. 当中断向量表以 0x80 对齐时:
- 表中 (2n*0x80)/4 处开始的连续 32 个中断均能够正常响应,n 可取值 0 - 7
- 表中 ((2n+1)*0x80)/4 处开始的连续 32 个中断发生时,实际响应的却是表中((2n*0x80)/4 处对应的连续 32 个中断函数
2. 当中断向量表以 0x100 对齐时:
- 表中 (2n*0x100)/4 处开始的连续 64 个中断均能够正常响应,n 可取值 0 - 4
- 表中 ((2n+1)*0x100)/4 处开始的连续 64 个中断发生时,实际响应的却是表中((2n*0x100)/4 处对应的连续 64 个中断函数
3. 当中断向量表以 0x200 对齐时:
- 表中 (2n*0x200)/4 处开始的连续 128 个中断均能够正常响应,n 可取值 0 - 1
- 表中 ((2n+1)*0x200)/4 处开始的连续 128 个中断发生时,实际响应的却是表中((2n*0x200)/4 处对应的连续 128 个中断函数
4. 当中断向量表以 0x400 对齐时:
- 表中前 256 个中断均能够正常响应
- 推测表中第 256 - 511 个中断发生时,实际响应的是表中 0 - 255 个中断函数
5. 当中断向量表以 0x800 对齐时:
- 表中前 512 个中断均能够正常响应
6. 当中断向量表以 0x180 对齐时:未详尽测试,效果似乎与以 0x80 对齐一致
7. 当中断向量表以 0x280 对齐时:未详尽测试,第 100 个中断误触发第 68 个中断函数,第 136 个中断触发 HardFault
8. 当中断向量表以 0x300 对齐时:未详尽测试,第 100/136 个中断均触发 HardFault
...
至此,Cortex-M中断向量表对齐原则介绍完了~~~
-
寄存器
+关注
关注
31文章
5343浏览量
120419 -
函数
+关注
关注
3文章
4332浏览量
62651 -
Cortex-M
+关注
关注
2文章
229浏览量
29771
原文标题:一文了解Cortex-M中断向量表对齐原则
文章出处:【微信号:strongerHuang,微信公众号:strongerHuang】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用Ozone分析Cortex-M异常
【GD32 MCU 入门教程】GD32 MCU 常见外设介绍(3)NVIC 介绍
TMS320C6701如何自己更改中断向量的入口地址?
调试stm8s105的时候,如何在中断向量表中设置自己的中断?
请问STM8L052R8的USART2中断向量在哪?
求助,关于STM8S103中断向量重定义问题
STM32F103CB将中断向量表放到RAM后就不正常了,为什么?
STM32F4和STM32F7的复位序列介绍
请问中断向量重复定义怎么处理?
stm32cubeide更改ld文件中的Flash偏移和中断向量表的宏VECT_TAB_OFFSET后,编译出来的bin文件与之前不同为什么?
什么是中断向量偏移,为什么要做中断向量偏移?





 工商网监
工商网监
评论