 一文带你深入了解KVM的基本原理
一文带你深入了解KVM的基本原理
一、 概述
KVM的全称是Kernel-based Virtual Machine,其是一种基于linux内核的采用硬件辅助虚拟化技术的全虚拟化解决方案。它最初由以色列的初创公司Qumranet开发,并在linux-2.6.20中开始被纳入在linux内核,成为内核源码的一部分。KVM自诞生之初就定位于基于硬件辅助的虚拟化来提供全虚拟化的支持,其以内核模块的形式被加载。加载KVM模块的linux内核相当于变成了一个Hypervisor,同时依赖linux内核提供的各种功能来实现硬件管理,拥有极高的兼容性及可扩展性。
上面提到KVM是作为一个内核模块出现的,所以它还得借助用户空间的程序来和用户进行交互,这就不得不提到大名鼎鼎的QEMU了。QEMU是一套由法布里斯·贝拉(Fabrice Bellard)所编写的以GPL许可证分发源码的模拟处理器,在GNU/Linux平台上使用广泛。
其本身是一个纯软件的支持CPU虚拟化、内存虚拟化及I/O虚拟化等功能的用户空间程序。其借助KVM提供的虚拟化支持可以将CPU、内存等虚拟化工作交由KVM处理,自己则处理大多数I/O虚拟化的功能,可以实现极高的虚拟化效率。KVM及QEMU配合使用的整体接口如图1所示。
QEMU尽管非常的强大,但也正是应为它的强大导致其对初学者非常的不友好。这里推荐大家刚开始学习KVM时可以先学习kvm tool,这是一个基于C语言开发的KVM虚拟化工具,其代码非常精简易懂,同时也可以支持完整的linux虚拟化,非常适合初学者入门使用。其项目地址为https://github.com/kvmtool/kvmtool。
二、 ARM64虚拟化支持
arm最早在armv7-a引入硬件虚拟化支持。到了armv8中,arm抛弃了armv7时代的特权级,引入了全新的Exception Level(EL),其如图2所示(armv8.4-A引入了对安全世界虚拟化的支持)。

图2
其中4个异常等级中的EL2留给Hypervisor用于各种虚拟化功能的访问及配置,如:stage 2转换、EL1/EL0指令和寄存器访问、注入虚拟异常等。
三、 CPU虚拟化
CPU被称为计算机的大脑,是计算机系统中最核心的模块。在没有CPU硬件虚拟化技术之前都是使用二进制指令动态翻译技术来实现对客户机操作系统中执行的执行(例如qemu的软件虚拟化),其不仅实现复杂而且效率非常低下。因此硬件虚拟化技术应运而生,为KVM的诞生创造了必要的条件。
有时Hypervisor需要模拟一些操作,例如VM里运行的软件试图配置处理器的一些属性,如电源管理或是缓存一致性时。通常你不会允许VM直接配置这些属性,因为这会打破隔离性,从而影响其他VMs。这就需要通过以陷入的方式产生异常,在异常处理程序中做相应的模拟。armv8包含一些陷入控制来帮助实现陷入(trapping) – 模拟(emulating)。如果对相应操作配置了陷入,则这种操作发生时会陷入到更高的异常级别。
例如,正常我们在执行WFI指令时会使CPU进入一个低功耗的状态,但是对于HOST OS来说,如果让CPU真正进入低功耗状态,显然会影响其他VM的运行。如果我们配置了HCR_EL2.TWI==1时,那么Guest OS在执行WFI时就会触发EL2的异常,然后陷入Hypervisor,那么此时Hypervisor就可以将对应VCPU所处的线程调出出去,将CPU让给其他的VCPU线程使用。
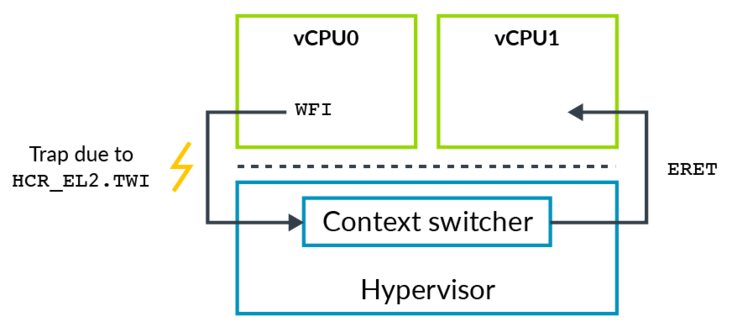
图3
四、 内存虚拟化
内存虚拟化的目的是给虚拟客户机操作系统提供一个从0开始的连续的地址空间,同时在多个客户机之间实现隔离与调度。
arm主要通过Stage 2转换来提供对内存虚拟化的支持,其允许Hypervisor控制虚拟机的内存视图,而在这之前则是使用及其复杂的影子页表技术来实现。Stage 2转换可以控制虚拟机是否可以访问特定的某一块物理内存,以及该内存块出现在虚拟机内存空间的位置。这种能力对于虚拟机的隔离和沙箱功能来说至关重要。
这使得虚拟机只能看到分配给它自己的物理内存。为了支持Stage 2 转换, 需要增加一个页表,我们称之为Stage 2页表。操作系统控制的页表转换称之为stage 1转换,负责将虚拟机视角的虚拟地址转换为虚拟机视角的物理地址。而stage 2页表由Hypervisor控制,负责将虚拟机视角的物理地址转换为真实的物理地址。虚拟机视角的物理地址在Armv8中有特定的词描述,叫中间物理地址(intermediate Physical Address, IPA)。
stage 2转换表的格式和stage 1的类似,但也有些属性的处理不太一样,例如,判断内存类型 是normal 还是 device的信息被直接编码进了表里,而不是通过查询MAIR_ELx寄存器。
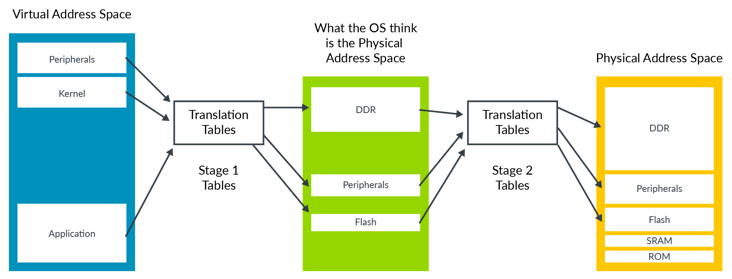
图4
五、 I/O虚拟化
I/O设备作为一种外部设备,其虚拟化的实现相较于前面的CPU虚拟化及内存虚拟化有些不同,其目前主要有以下四种虚拟化方案。
1、 设备模拟:
在虚拟机监控器中模拟具体的I/O设备的特性,例如qemu。在KVM和qemu的组合中通过Hypervisor捕获Guest OS的I/O请求交给用户空间的qemu进行模拟,然后将结果再通过Hypervisor传递给Guest OS。这种方式能够提供非常好的兼容性但是性能太差,同时模拟设备的功能特性支持不够多。
2、 前后端驱动接口
在Hypervisor和Guest OS之间定义一种权限的适用于虚拟机的交互接口,比如virtio技术。这个方案相较于设备模拟在性能上有所提高,但是兼容性较差,而且在高I/O负载场景,后端驱动的CPU占用较高。
3、 设备直接分配
将一个物理设备直接分配给Guest OS使用。此方式的性能显而易见,要比上面两种好很多,但是需要硬件设备支持,且无法共享和动态迁移。
4、 设备共享分配
此方式是设备直接分配的一个扩展,其主要就是让一个物理设备可以支持多个虚拟机功能接口,将不同的接口地址独立分配给不同的Guest OS使用。如SR-IOV协议。
参考文献:
1、《KVM实战:原理、进阶与性能调优》
2、https://segmentfault.com/a/1190000022797518
3、https://www.cnblogs.com/LoyenWang/
编辑:jq
-
ARM
+关注
关注
134文章
9105浏览量
367922 -
cpu
+关注
关注
68文章
10873浏览量
212106 -
KVM
+关注
关注
0文章
188浏览量
12958 -
驱动接口
+关注
关注
0文章
10浏览量
2627
原文标题:KVM原理简介
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何为不同的电机选择合适的驱动芯片?纳芯微带你深入了解!

RNN的基本原理与实现
神经网络的基本原理
电压比较器的基本原理和应用领域
数字源表的基本原理与结构组成
倍频器的基本原理、分类及应用领域
5.8G WiFi和2.4G WiFi如何选择?一文带你深度了解

拆解FPGA芯片,带你深入了解其原理
工业以太网的基本原理及优势
晶振电路中电容电阻的一些基本原理和作用解析






 工商网监
工商网监
评论