 Prometheus、InfluxDB与Grafana打造监控平台怎么样
Prometheus、InfluxDB与Grafana打造监控平台怎么样
在本文中,我将把几个常用的监控部分给梳理一下。前面我们提到过,在性能监控图谱中,有操作系统、应用服务器、中间件、队列、缓存、数据库、网络、前端、负载均衡、Web 服务器、存储、代码等很多需要监控的点。显然这些监控点不能在一个专栏中全部覆盖并一一细化,我只能找最常用的几个,做些逻辑思路的说明,同时也把具体的实现描述出来。如果你遇到了其他的组件,也需要一一实现这些监控。
在本篇中,主要想说明白下图的这个监控逻辑。
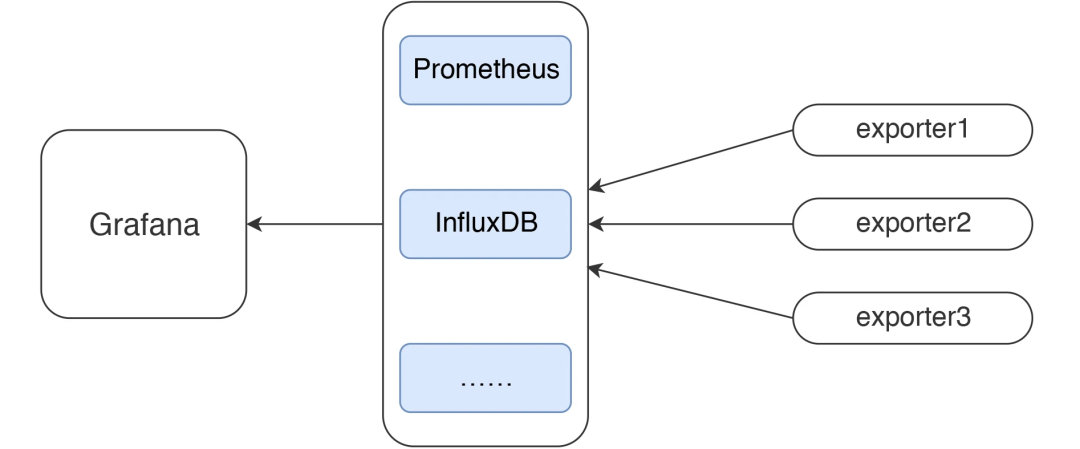
这应该是现在最流行的一套监控逻辑了吧。我今天把常见的使用 Grafana、Prometheus、InfluxDB、Exporters 的数据展示方式说一下,如果你刚进入性能测试领域,也能有一个感性的认识。
有测试工具,有监控工具,才能做后续的性能分析和瓶颈定位,所以有必要把这些工具的逻辑跟你摆一摆。
所有做性能的人都应该知道一点,不管数据以什么样的形式展示,最要紧的还是看数据的来源和含义,以便做出正确的判断。
我先说明一下 JMeter 和 node_exporter 到 Grafana 的数据展示逻辑。至于其他的 Exporter,我就不再解释这个逻辑了,只说监控分析的部分。
JMeter + InfluxDB + Grafana 的数据展示逻辑
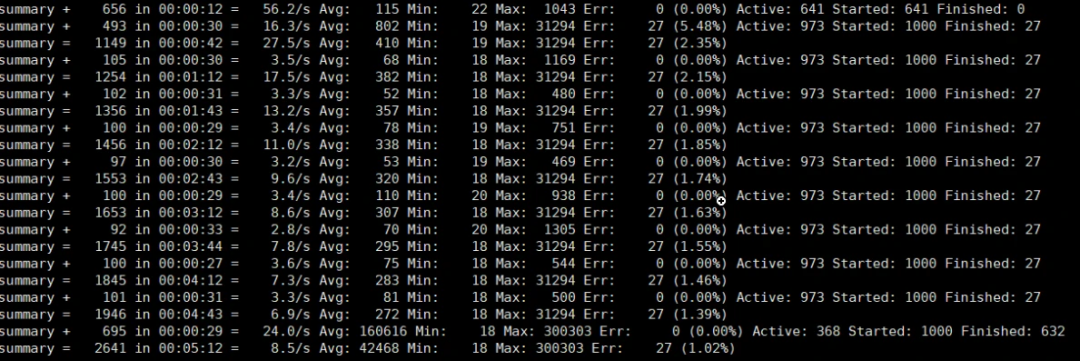
一般情况下,我们用 JMeter 做压力测试时,都是使用 JMeter 的控制台来查看结果。如下图所示:
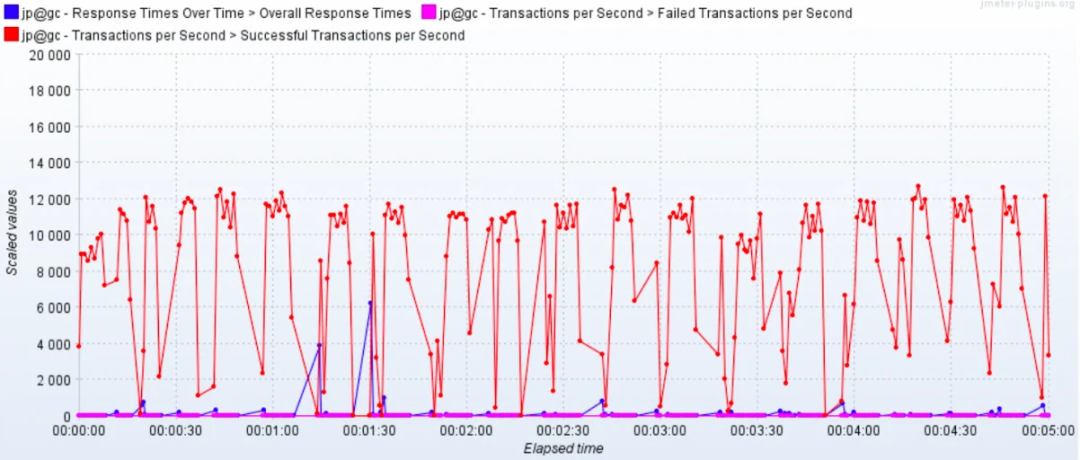
或者装个插件来看结果:
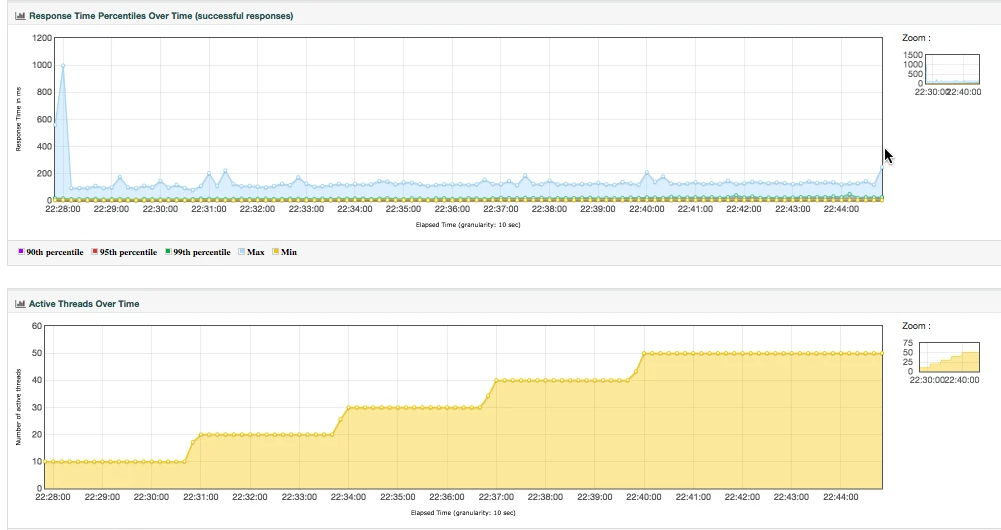
或者用 JMeter 来生成 HTML:
这样看都没有问题,我们在前面也强调过,对于压力工具来说,我们最多只关心三条曲线的数据:TPS(T 由测试目标定义)、响应时间、错误率。这里的错误率还只是辅助排查问题的曲线,没有问题时,只看 TPS 和响应时间即可。不过采取以上三种方式有几个方面的问题。
整理结果时比较浪费时间。
在 GUI 用插件看曲线,做高并发时并不现实。
在场景运行时间比较长的时候,采用生成 HTML 的方式,会出现消耗内存过大的情况,而实际上,在生成的结果图中,有很多生成的图我们并不是那么关注。
生成的结果保存之后再查看比较麻烦,还要一个个去找。
那么如何解决这几个问题呢?
用 JMeter 的 Backend Listener 帮我们实时发送数据到 InfluxDB 或 Graphite 可以解决这样的问题。
Graphite Backend Listener 的支持是在 JMeter 2.13 版本,InfluxdDB Backend Listener 的支持是在 JMeter 3.3 的版本,它们都是用异步的方式把数据发送出来,以便查看。
其实有这个 JMeter 发送给 InfluxDB 的数据之后,我们不需要看上面的那些 HTML 数据,也可以直观地看到系统性能的性能趋势。
并且这样保存下来的数据,在测试结束后想再次查看也比较方便比对。
JMeter + InfluxDB + Grafana 的结构如下:
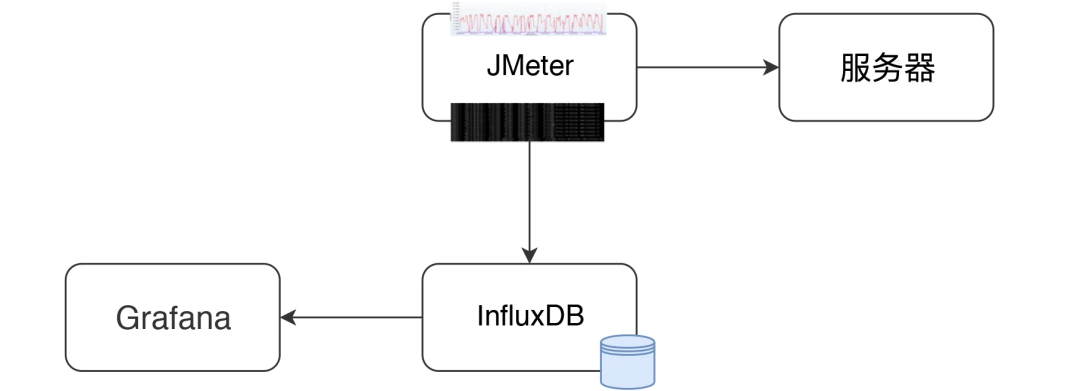
在这个结构中,JMeter 发送压力到服务器的同时,统计下 TPS、响应时间、线程数、错误率等信息。默认每 30 秒在控制台输出一次结果(在 jmeter.properties 中有一个参数 #summariser.interval=30 可以控制)。
配置了 Backend Listener 之后,将统计出的结果异步发送到 InfluxDB 中。最后在 Grafana 中配置 InfluxDB 数据源和 JMeter 显示模板。
然后就可以实时查看 JMeter 的测试结果了,这里看到的数据和控制台的数据是一样。
但如果这么简单就说完了,这篇文章也就没价值了。下面我们来说一下,数据的传输和展示逻辑。
JMeter 中 Backend Listener 的配置
下面我们就 InfluxDB 的 Backend Listener 做个说明。它的配置比较简单,在脚本中加上即可。
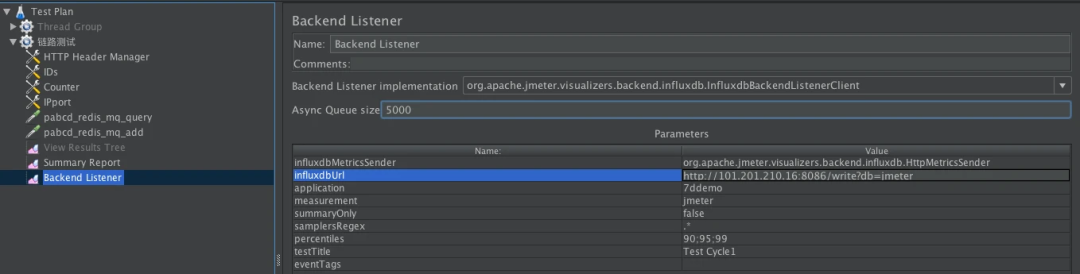
我们先配置好 InfluxDB URL、Application 等信息,Application 这个配置可以看成是场景名。
那么 JMeter 如何将数据发给 InfluxDB 呢?请看源码中的关键代码,如下所示:
privatevoidaddMetrics(Stringtransaction,SamplerMetricmetric){ //FORALLSTATUS addMetric(transaction,metric.getTotal(),metric.getSentBytes(),metric.getReceivedBytes(),TAG_ALL,metric.getAllMean(),metric.getAllMinTime(), metric.getAllMaxTime(),allPercentiles.values(),metric::getAllPercentile); //FOROKSTATUS addMetric(transaction,metric.getSuccesses(),null,null,TAG_OK,metric.getOkMean(),metric.getOkMinTime(), metric.getOkMaxTime(),okPercentiles.values(),metric::getOkPercentile); //FORKOSTATUS addMetric(transaction,metric.getFailures(),null,null,TAG_KO,metric.getKoMean(),metric.getKoMinTime(), metric.getKoMaxTime(),koPercentiles.values(),metric::getKoPercentile); metric.getErrors().forEach((error,count)->addErrorMetric(transaction,error.getResponseCode(), error.getResponseMessage(),count)); }
从这段代码可以看出,站在全局统计的视角来看,这里把 JMeter 运行的统计结果,比如事务的 Total 请求、发送接收字节、平均值、最大值、最小值等,都加到 metric 中,同时也会把成功和失败的事务信息添加到 metric 中去。 在源码中,还有更多的添加 metric 的步骤,你有兴趣的话,也可以看一下 JMeter 源码中的InfluxdbBackendListenerClient.java。 保存了 metric 之后,再使用 InfluxdbMetricsSender 发送到 InfluxDB 中去。发送关键代码如下:
@OverridepublicvoidwriteAndSendMetrics(){ ........if(!copyMetrics.isEmpty()){try{if(httpRequest==null){ httpRequest=createRequest(url); } StringBuildersb=newStringBuilder(copyMetrics.size()*35);for(MetricTuplemetric:copyMetrics){//AddTimeStampinnanosecondfromepoch(defaultinInfluxDB) sb.append(metric.measurement) .append(metric.tag) .append("")//$NON-NLS-1$ .append(metric.field) .append("") .append(metric.timestamp+"000000") .append(" ");//$NON-NLS-1$ } StringEntityentity=newStringEntity(sb.toString(),StandardCharsets.UTF_8); httpRequest.setEntity(entity); lastRequest=httpClient.execute(httpRequest,newFutureCallback
InfluxDB 中的存储结构
然后我们再来看下 InfluxDB 中如何存储:
>showdatabases name:databases name ---- _internal jmeter >usejmeter Usingdatabasejmeter > >showMEASUREMENTS name:measurements name ---- events jmeter >select*fromeventswhereapplication='7ddemo' name:events timeapplicationtexttitle ------------------------ 15752554628060000007ddemoTestCycle1startedApacheJMeter 15752564638200000007ddemoTestCycle1endedApacheJMeter .............. n>select*fromjmeterwhereapplication='7ddemo'limit10 name:jmeter timeapplicationavgcountcountErrorendedThitmaxmaxATmeanATminminATpct90.0pct95.0pct99.0rbresponseCoderesponseMessagesbstartedTstatuttransaction --------------------------------------------------------------------------------------------------------------------------------------------- 15752554628210000007ddemo00000internal 15752554678180000007ddemo232.8235294117647217017849122384.999999999999684984900allall 15752554678240000007ddemo232.8235294117647217849122384.999999999999684984900all0_openIndexPage 15752554678260000007ddemo232.8235294117647217849122384.9999999999996849849ok0_openIndexPage 15752554678290000007ddemo01111internal 15752554728110000007ddemo205.441860465116326026849122252.6271.484900allall 15752554728120000007ddemo01111internal 15752554728120000007ddemo205.441860465116326849122252.6271.4849ok0_openIndexPage 15752554728120000007ddemo205.441860465116326849122252.6271.484900all0_openIndexPage 15752554778110000007ddemo198.214285714285727027849117263.79999999999995292.350000000000184900allall 这段代码也就是说,在 InfluxDB 中,创建了两个 MEASUREMENTS,分别是 events 和 jmeter。这两个各自存了数据,我们在界面中配置的 testtile 和 eventTags 放在了 events 这个 MEASUREMENTS 中。在模板中这两个值暂时都是不用的。 在 JMeter 这个 MEASUREMENTS 中,我们可以看到 application 和事务的统计信息,这些值和控制台一致。在 Grafana 中显示的时候,就是从这个表中取出的数据,根据时序做的曲线。
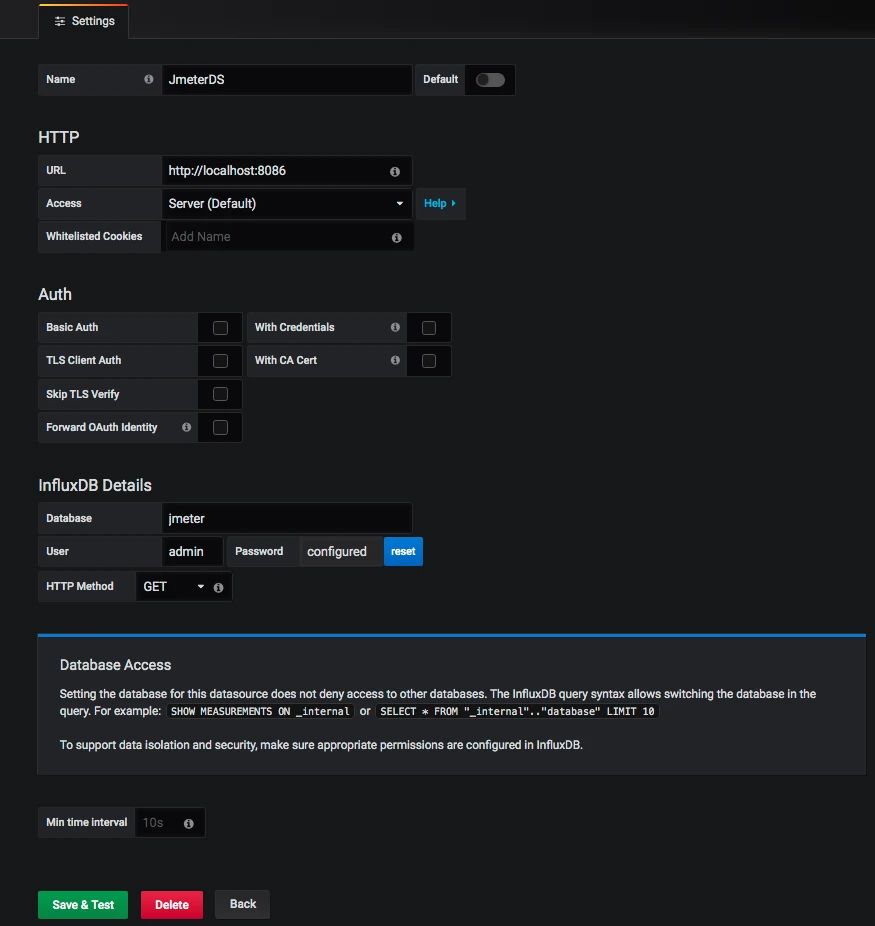
Grafana 中的配置
有了 JMeter 发送到 InfluxDB 中的数据,下面就来配置一下 Grafana 中的展示。首先,要配置一个 InfluxDB 数据源。如下所示
SELECTlast("count")/$send_intervalFROM"$measurement_name"WHERE("transaction"=~/^$transaction$/AND"statut"='ok')AND$timeFilterGROUPBYtime($__interval)
上面这个就是 Total TPS 了,在这里称为 throughput。 关于这个概念,我在第一篇中就已经有了说明,这里再次提醒,概念的使用在团队中要有统一的认识,不要受行业内一些传统信息的误导。 这里取的数据来自 MEASUREMENTS 中成功状态的所有事务。 响应时间曲线:SELECTmean("pct95.0")FROM"$measurement_name"WHERE("application"=~/^$application$/)AND$timeFilterGROUPBY"transaction",time($__interval)fill(null)
这里是用 95 pct 内的响应时间画出来的曲线。
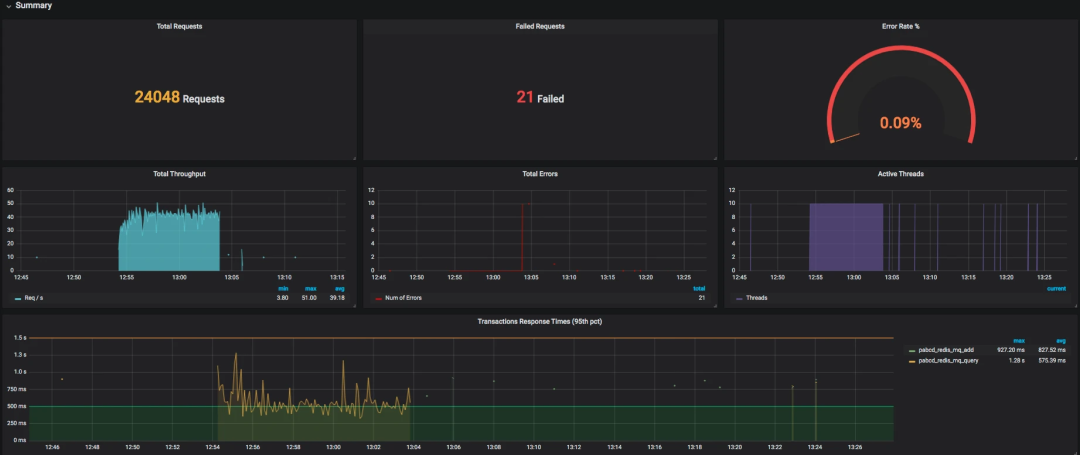
整体展示出来的效果如下:
数据比对
首先,我们在 JMeter 中配置一个简单的场景。10 个线程,每个线程迭代 10 次,以及两个 HTTP 请求。
也就是说,这时会产生 10x10x2=200 次请求。我们用 JMeter 跑起来看一下。

看到了吧,这个请求数和我们预想的一样。下面我们看一下 Grafana 中展示出来的结果。
还有针对每个事务的统计情况。
至此,JMeter 到 Grafana 的展示过程就完成了。以后我们就不用再保存 JMeter 的执行结果了,也不用等着 JMeter 输出 HTML 了。
node_exporter + Prometheus + Grafana 的数据展示逻辑
对性能测试来说,在常用的 Grafana + Prometheus + Exporter 的逻辑中,第一步要看的就是操作系统资源了。所以在这一篇中,我们将以 node_exporter 为例来说明一下操作系统抽取数据的逻辑,以便知道监控数据的来源,至于数据的含义,我们将在后续的文章中继续描述。
首先,我们还是要画一个图。
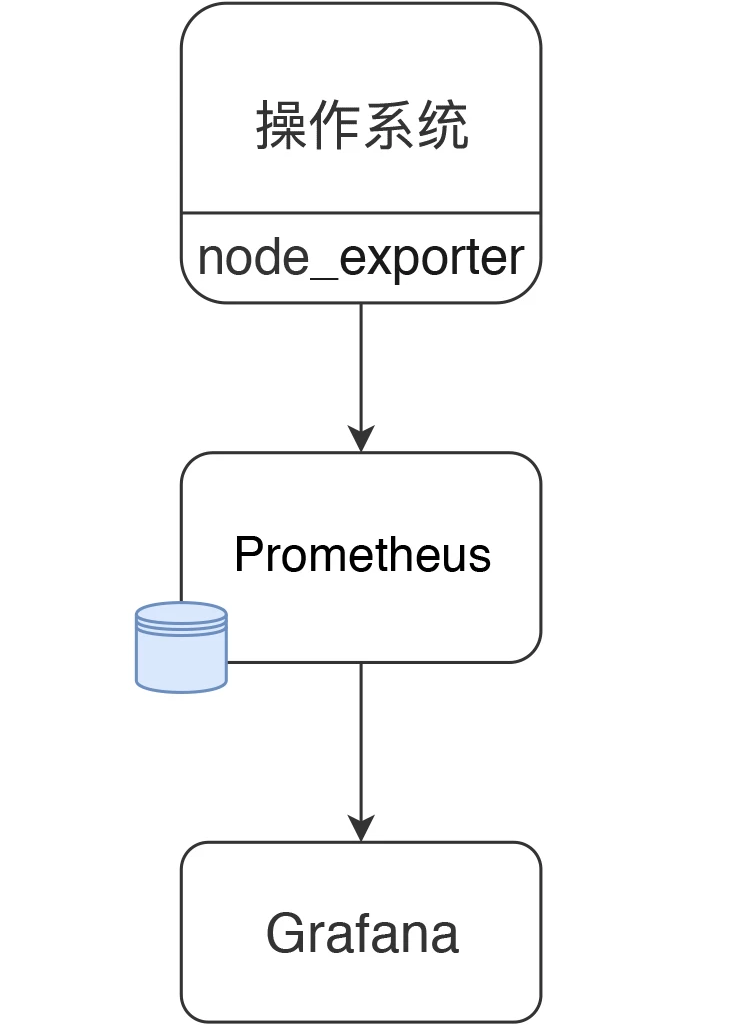
现在 node_exporter 可以支持很多个操作系统了。官方列表如下:
当然不是说只支持这些,你也可以扩展自己的 Exporter。
配置 node_exporter
node_exporter 目录如下:
[root@7dgroup2node_exporter-0.18.1.linux-amd64]#ll total16524 -rw-r--r--13434343411357Jun500:50LICENSE -rwxr-xr-x13434343416878582Jun500:41node_exporter -rw-r--r--134343434463Jun500:50NOTICE}
启动:[root@7dgroup2node_exporter-0.18.1.linux-amd64]#./node_exporter--web.listen-address=:9200&
是不是很简洁?如果想看更多的功能 ,可以查看下它的帮助。 配置 Prometheus 先下载 Prometheus:[root@7dgroup2data]#wget-chttps://github.com/prometheus/prometheus/releases/download/v2.14.0/prometheus-2.14.0.linux-amd64.tar.gz .......... 100%[=============================================================================================>]58,625,125465KB/sin6m4s 2019-11-291516(157KB/s)-‘prometheus-2.14.0.linux-amd64.tar.gz’saved[58625125/58625125] [root@7dgroup2data]
解压之后,我们可以看到目录结构如下:[root@7dgroup2prometheus-2.11.1.linux-amd64]#ll total120288 drwxr-xr-x.2343434344096Jul1023:26console_libraries drwxr-xr-x.2343434344096Jul1023:26consoles drwxr-xr-x.3rootroot4096Nov3012:55data -rw-r--r--.13434343411357Jul1023:26LICENSE -rw-r--r--.1rootroot35Aug723:19node.yml -rw-r--r--.1343434342770Jul1023:26NOTICE -rwxr-xr-x.13434343476328852Jul1021:53prometheus -rw-r--r--1343434341864Sep2109:36prometheus.yml -rwxr-xr-x.13434343446672881Jul1021:54promtool [root@7dgroup2prometheus-2.11.1.linux-amd64]#
在prometheus.yml中添加如下配置,以取数据:-job_name:'s1' static_configs: -targets:['172.17.211.143:9200']
启动:[root@7dgroup2data]#./prometheus--config.file=prometheus.yml&
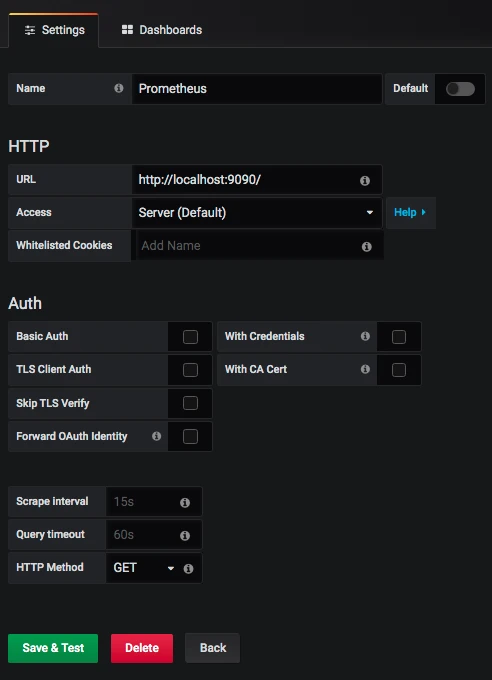
这样就行了吗?当然不是。根据上面的流程图,我们还需要配置 Grafana。 配置 Grafana 首先配置一个数据源,非常简单。如下所示:
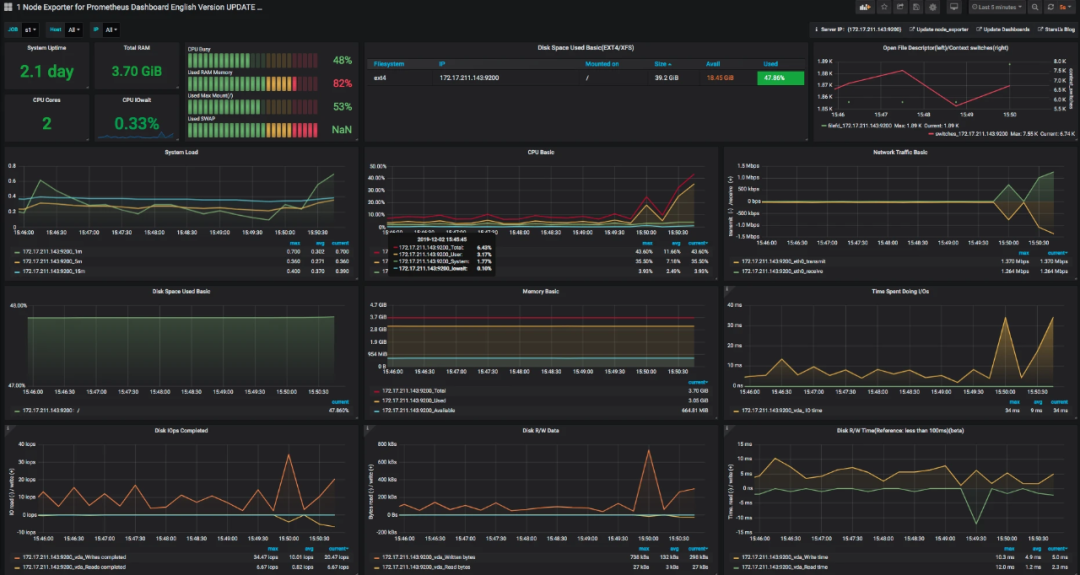
avg(irate(node_cpu_seconds_total{instance=~"$node",mode="system"}[30m]))by(instance)avg(irate(node_cpu_seconds_total{instance=~"$node",mode="user"}[30m]))by(instance)avg(irate(node_cpu_seconds_total{instance=~"$node",mode="iowait"}[30m]))by(instance)1-avg(irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[30m]))by(instance)
这些都是从 Prometheus 中取出来的数据,查询语句读了 Prometheus 中node_cpu_seconds_total的不同的模块数据。 下面我们来看一下,node_exporter暴露出来的计数器。
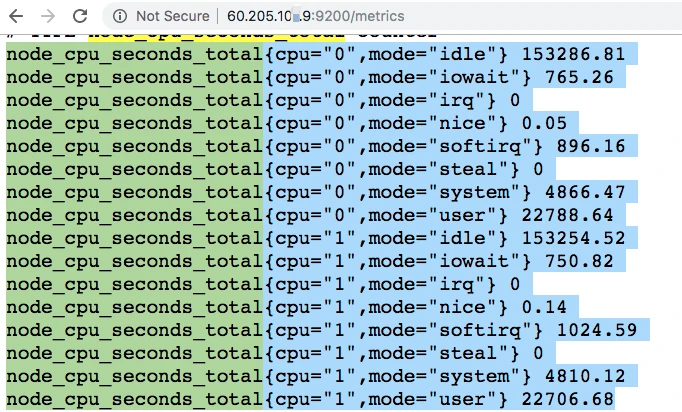
总结
为什么要解释数据的逻辑呢?因为最近在工作中遇到一些情况,有人觉得有了 Prometheus + Grafana + Exportor 这样的组合工具之后,基本上都不再用手工执行什么命令了。但我们要了解的是,对于监控平台来说,它取的所有的数据必然是被监控者可以提供的数据,像 node_exporter 这样小巧的监控收集器,它可以获取的监控数据,并不是整个系统全部的性能数据,只是取到了常见的计数器而已。这些计数器不管是用命令查看,还是用这样炫酷的工具查看,它的值本身都不会变。所以不管是在监控平台上看到的数据,还是在命令行中看到的数据,我们最重要的是要知道含义以及这些值的变化对性能测试和分析的下一步骤的影响。
原文链接:https://www.cnblogs.com/siguadd/p/14878035.html-
数据
+关注
关注
8文章
7030浏览量
89038 -
网络
+关注
关注
14文章
7565浏览量
88792 -
GUI
+关注
关注
3文章
660浏览量
39681 -
Web 服务器
+关注
关注
0文章
3浏览量
1459
原文标题:基于 Prometheus、InfluxDB 与 Grafana 打造监控平台
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
可与MES系统集成的数据采集监控平台
EasyRoCE统一监控面板:一站式运维体验

devops使用最广泛的集成工具盘点
安科瑞电力智能监控平台的应用
工业互联网远程监控平台是什么
动环监控系统平台功能
设备监控物联网SaaS平台是什么?设备监控物联网SaaS平台的功能
PLC远程监控维护平台是什么
LabVIEW操作InfluxDB数据库应用特点和原理概念

电缆隧道综合监控管理平台的规划设置和特性
基于物联网平台与边缘计算网关,打造高效能工厂设备监控系统方案

如何快速打造属于自己的工业物联网云平台

Prometheus监控业务指标详解





 工商网监
工商网监
评论