 ARM攒机指南 - 基础篇
ARM攒机指南 - 基础篇
本文转载于极术社区
极术专栏:ARM攒机指南
作者:djygrdzh
CCI400是怎么做到硬件一致性的呢?简单来说,就是处理器组C1,发一个包含地址信息的特殊读写的命令到总线,然后总线把这个命令转给另一个处理器组C2。C2收到请求后,根据地址逐步查找二级和一级缓存,如果发现自己也有,那么就返回数据或者做相应的缓存一致性操作,这个过程称作snooping(监听)。
具体的操作我不展开,ARM使用MOESI一致性协议,里面都有定义。在这个过程中,被请求的C2中的处理器核心并不参与这个过程,所有的工作由缓存和总线接口单元BIU等部件来做。
为了符合从设备不主动发起请求的定义,需要两组主从设备,每个处理器组占一个主和一个从。这样就可以使得两组处理器互相保持一致性。而有些设备如DMA控制器,它本身不包含缓存,也不需要被别人监听,所以它只包含从设备,如上图桔黄色的部分。在ARM的定义中,具有双向功能的接口被称作ACE,只能监听别人的称作ACE-Lite。它们除了具有AXI的读写通道外,还多了个监听通道。
多出来的监听通道,同样也有地址(从到主),回应(主到从)和数据(主到从)。每组信号内都包含和AXI一样的标志符,用来支持多OT。如果在主设备找到数据(称为命中),那么数据通道会被使用,如果没有,那告知从设备未命中就可以了,不需要传数据。由此,对于上文的DMA控制器,它永远不可能传数据给别人,所以不需要数据组,这也就是ACE和ACE-Lite的主要区别。
我们还可以看到,在读通道上有个额外的线RACK,它的用途是,当从设备发送读操作中的数据给主,它并不知道何时主能收到这个数据,因为我们说过插入寄存器会导致总线延迟变长。万一这个时候,对同样的地址A,它需要发送新的监听请求给主,就会产生一个问题:主是不是已经收到前面发出的地址A的数据了呢?如果没收到,那它可能会告知监听未命中。但实际上地址A的数据已经发给主了,它该返回命中。加了这个RACK后,从设备在收到主给的确认RACK之前,不会发送新的监听请求给主,从而避免了上述问题。写通道上的WACK同样如此。
我们之前计算过NIC400上的延迟,有了CCI400的硬件同步,是不是访问更快了呢?首先,硬件一致性的设计目的不是为了更快,而是软件更简单。而实际上,它也未必就快。因为给定一个地址,我们并不知道它是不是在另一组处理器的缓存内,所以无论如何都需要额外的监听动作。当未命中的时候,这个监听动作就是多余的,因为我们还是得从内存去抓数据。这个多余的动作就意味着额外的延迟,10加10一共20个总线周期,增长了100%。当然,如果命中,虽然总线总共上也同样需要10周期,可是从缓存拿数据比从内存拿快些,所以此时是有好处的。综合起来看,当命中大于一定比例,总体还是受益的。
可从实际的应用程序情况来看,除了特殊设计的程序,通常命中不会大于10%。所以我们必须想一些办法来提高性能。一个办法就是,无论结果是命中还是未命中,都让总线先去内存抓数据。等到数据抓回来,我们也已经知道监听的结果,再决定把哪边的数据送回去。这个办法的缺点,功耗增大,因为无论如何都要去读内存。第二,在内存访问本身就很频繁的时候,这么做会降低总体性能。
另外一个方法就是,如果预先知道数据不在别的处理器组缓存,那就可以让发出读写请求的主设备,特别注明不需要监听,总线就不会去做这个动作。这个方法的缺点就是需要软件干预,虽然代价并不大,分配操作系统页面的时候设下寄存器就可以,可是对程序员的要求就高了,必须充分理解目标系统。
CCI总线还使用了一个新的方法来提高性能,那就是在总线里加入一个监听过滤器(SnoopFilter)。这其实也是一块缓存(TAG RAM),把它所有处理器组内部一级二级缓存的状态信息都放在里面。数据缓存(DATA RAM)是不需要的,因为它只负责查看命中与否。这样做的好处就是,监听请求不必发到各组处理器,在总线内部就可以完成,省了将近10个总线周期,功耗也优于访问内存。它的代价是增加了一点缓存(一二级缓存10%左右的容量)。并且,如果监听过滤器里的某行缓存被替换(比如写监听命中,需要无效化(Invalidate)缓存行,MOESI协议定义),同样的操作必须在对应处理器组的一二级缓存也做一遍,以保持一致性。这个过程被称作反向无效化,它添加了额外的负担,因为在更新一二级缓存的时候,监听过滤器本身也需要追踪更新的状态,否则就无法保证一致性。幸好,在实际测试中发现,这样的操作并不频繁,一般不超过5%的可能性。当然,有些测试代码会频繁的触发这个操作,此时监听过滤器的缺点就显出来了。
以上的想法在CCI500中实现,示意图如下:
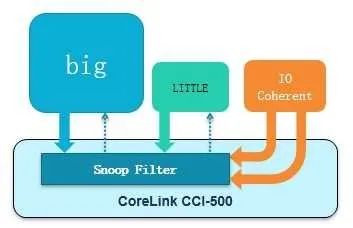
在经过实际性能测试后,CCI设计人员发现总线瓶颈移到了访问这个监听过滤器的窗口,这个瓶颈其实掩盖了上文的反向无效化问题,它总是先于反向无效化被发现。把这个窗口加大后,又在做测试时发现,如果每个主从接口都拼命灌数据(主从设备都是OT无限大,并且一主多从有前后交叉),在主从设备接口处经常出现等待的情况,也就是说,明明数据已经准备好了,设备却来不及接收。于是,又增加了一些缓冲来存放这些数据。其代价是稍大的面积和功耗。请注意,这个缓冲和存放OT的状态缓冲并不重复。
根据实测数据,在做完所有改进后,新的总线带宽性能同频增加50%以上。而频率可以从500Mhz提高到1GMhz。当然这个结果只是一个模糊的统计,如果我们考虑处理器和内存控制器OT数量有限,被监听数据的百分比有不同,命中率有变化,监听过滤器大小有变化,那肯定会得到不同的结果。
作为一个手机芯片领域的总线,需要支持传输的多优先级也就是QoS。因为显示控制器等设备对实时性要求高,而处理器组的请求也很重要。支持QoS本身没什么困难,只需要把各类请求放在一个缓冲,根据优先级传送即可。但是在实际测试中,发现如果各个设备的请求太多太频繁,缓冲很快就被填满,从而阻塞了新的高优先级请求。为了解决这个问题,又把缓冲按优先级分组,每一组只接受同等或更高优先级的请求,这样就避免了阻塞。
此外,为了支持多时钟和电源域,使得每一组处理器都可以动态调节电压和时钟频率,CCI系列总线还可以搭配异步桥ADB(Asynchronous Domain Bridge)。它对于性能有一定的影响,在倍频是2的时候,信号穿过它需要一个额外的总线时钟周期。如果是3,那更大些。在对于访问延迟有严格要求的系统里面,这个时间不可忽略。如果不需要额外的电源域,我们可以不用它,省一点延迟。NIC/CCI/CCN/NoC总线天然就支持异步传输。
和一致性相关的是访存次序和锁,有些程序员把它们搞混了。假设我们有两个核C0和C1。当C0和C1分别访问同一地址A0,无论何时,都要保证看到的数据一致,这是一致性。然后在C0里面,它需要保证先后访问地址A0和A1,这称作访问次序,此时不需要锁,只需要壁垒指令。如果C0和C1上同时运行两个线程,当C0和C1分别访问同一地址A0,并且需要保证C0和C1按照先后次序访问A0,这就需要锁。所以,单单壁垒指令只能保证单核单线程的次序,多核多线程的次序需要锁。而一致性保证了在做锁操作时,同一变量在缓存或者内存的不同拷贝,都是一致的。
ARM的壁垒指令分为强壁垒DSB和弱壁垒DMB。我们知道读写指令会被分成请求和完成两部分,强壁垒要求上一条读写指令完成后才能开始下一个请求,弱壁垒则只要求上一条读写指令发出请求后就可以继续下一条读写指令的请求,且只能保证,它之后的读写指令完成时,它之前的读写指令肯定已经完成了。显然,后一种情况性能更高,OT》1。但测试表明,多个处理器组的情况下,壁垒指令如果传输到总线,只能另整体系统性能降低,因此在新的ARM总线中是不支持壁垒的,必须在芯片设计阶段,通过配置选项告诉处理器自己处理壁垒指令,不要送到总线。但这并不影响程序中的壁垒指令,处理器会在总线之前把它过滤掉。
具体到CCI总线上,壁垒机制是怎么实现的呢?首先,壁垒和读写一样,也是使用读写通道的,只不过它地址总是0,且没有数据。标志符也是有的,此外还有额外的2根线BAR0/1,表明本次传输是不是壁垒,是哪种壁垒。他是怎么传输的呢?先看弱壁垒,如下图:
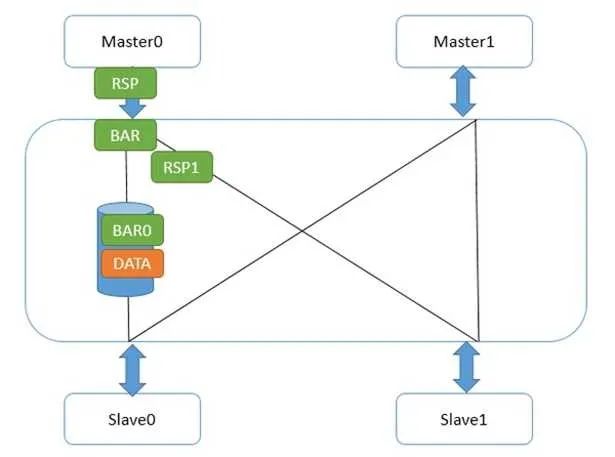
Master0写了一个数据data,然后又发了弱壁垒请求。CCI和主设备接口的地方,一旦收到壁垒请求,立刻做两件事,第一,给Master0发送壁垒响应;第二,把壁垒请求发到和从设备Slave0/1的接口。Slave1接口很快给了壁垒响应,因为它那里没有任何未完成传输。而Slave0接口不能给壁垒响应,因为data还没发到从设备,在这条路径上的壁垒请求必须等待,并且不能和data的写请求交换次序。这并不能阻挠Master0发出第二个数据,因为它已经收到它的所有下级(Master0接口)的壁垒回应,所以它又写出了flag。如下图:
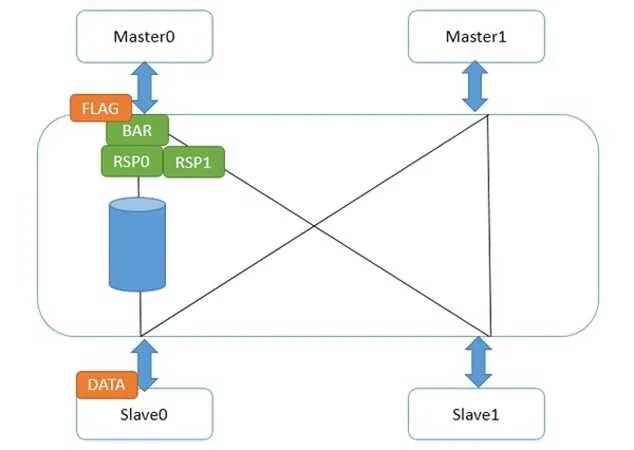
此时,flag在Master0接口中等待它的所有下一级接口的壁垒响应。而data达到了Slave0后,壁垒响应走到了Master0接口,flag继续往下走。此时,我们不必担心data没有到slave0,因为那之前,来自Slave0接口的壁垒响应不会被送到Master0接口。这样,就做到了弱壁垒的次序保证,并且在壁垒指令完成前,flag的请求就可以被送出来。
对于强壁垒指令来说,仅仅有一个区别,就是Master0接口在收到所有下一级接口的壁垒响应前,它不会发送自身的壁垒响应给Master0。这就造成flag发不出来,直到壁垒指令完成。如下图:
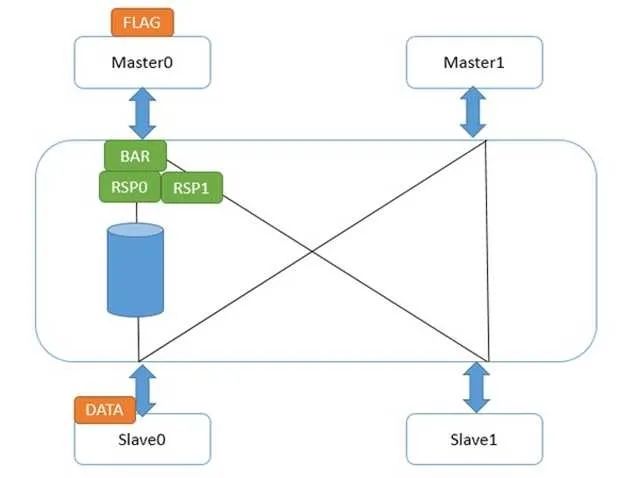
这样,就保证了强壁垒完成后,下一条读写指令才能发出请求。此时,强壁垒前的读写指令肯定是完成了的。
另外需要特别注意的是,ARM的弱壁垒只是针对显式数据访问的次序。什么叫显式数据访问?读写指令,缓存,TLB操作都算。相对的,什么是隐式数据访问?在处理器那一节,我们提到,处理器会有推测执行,预先执行读写指令;缓存也有硬件预取机制,根据之前数据访问的规律,自动抓取可能用到的缓存行。这些都不包含在当前指令中,弱壁垒对他们无能为力。因此,切记,弱壁垒只能保证你给出的指令次序,并不能保证在它们之间没有别的模块去访问内存,哪怕这个模块来自于同一个核。
简单来说,如果只需要保证读写次序,用弱壁垒;如果需要某个读写指令完成才能做别的事情,用强壁垒。以上都是针对普通内存类型。当我们把类型设成设备时,自动保证强壁垒。
我们提到,壁垒只是针对单核。在多核多线程时,哪怕使用了壁垒指令,也没法保证读写的原子性。解决办法有两个,一个是软件锁,一个是原子操作。AXI/ACE协议不支持原子操作。所以手机通常需要用到软件锁。
软件锁中有个自旋锁,能用一个ARM硬件机制exclusive access来实现。当使用特殊指令对一个地址写入值,相应缓存行上会做一个特殊标记,表示还没有别的核去写这行缓存。然后下条指令读这个行,如果标记没变,说明写和读之间没有人打扰,那么就拿到锁了。如果变了,那么回到写的过程重新获取锁。由于缓存一致性,这个锁变量可以被多个核与线程使用。当然,过程中还是需要壁垒指令来保证次序。
在支持ARMv8.2和AMBA 5.0 CHI接口的系统中,原子操作被重新引入。在硬件层面,其实原子操作非常容易理解,如果某个数据存在于自己的缓存,那就直接修改;如果存在于别人的缓存,那对所有其他缓存执行Eviction操作,踢出后,放到自己的缓存继续操作。这个过程其实和exclusive access非常类似。
对于普通内存,还会产生一个问题,就是读写操作可能会经过缓存,你不知道数据是否最终写到了内存中。通常我们使用clean操作来刷缓存。但是刷缓存本身是个模糊的概念,缓存存在多级,有些在处理器内,有些在总线之后,到底刷到哪里算是终结呢?还有,为了保证一致性,刷的时候是不是需要通知别的处理器和缓存?为了把这些问题规范化,ARM引入了Point of Unification/Coherency,Inner/Outer Cacheable和System/Inner/Outer/Non Shareable的概念。
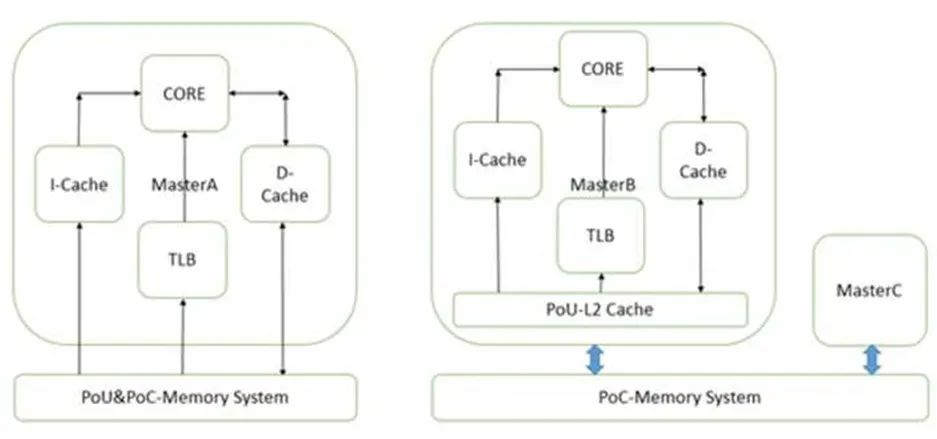
PoU是指,对于某一个核Master,附属于它的指令,数据缓存和TLB,如果在某一点上,它们能看到一致的内容,那么这个点就是PoU。如上图右侧,MasterB包含了指令,数据缓存和TLB,还有二级缓存。指令,数据缓存和TLB的数据交换都建立在二级缓存,此时二级缓存就成了PoU。而对于上图左侧的MasterA,由于没有二级缓存,指令,数据缓存和TLB的数据交换都建立在内存上,所以内存成了PoU。还有一种情况,就是指令缓存可以去监听数据缓存,此时,不需要二级缓存也能保持数据一致,那一级数据缓存就变成了PoU。
PoC是指,对于系统中所有Master(注意是所有的,而不是某个核),如果存在某个点,它们的指令,数据缓存和TLB能看到同一个源,那么这个点就是PoC。如上图右侧,二级缓存此时不能作为PoC,因为MasterB在它的范围之外,直接访问内存。所以此时内存是PoC。在左图,由于只有一个Master,所以内存是PoC。
再进一步,如果我们把右图的内存换成三级缓存,把内存接在三级缓存后面,那PoC就变成了三级缓存。
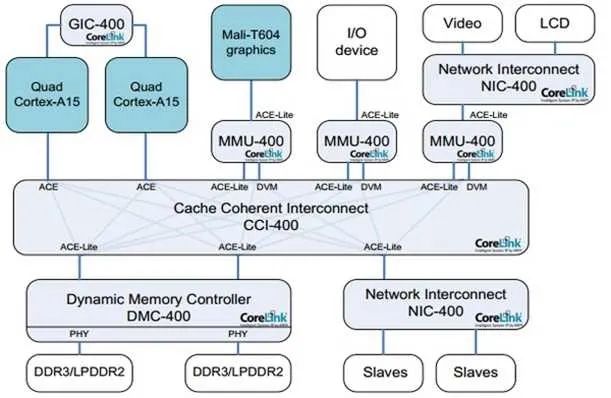
有了这两个定义,我们就可以指定TLB和缓存操作指令到底发到哪个范围。比如在下图的系统上,有两组A15,每组四个核,组内含二级缓存。系统的PoC在内存,而A15的PoU分别在它们自己组内的二级缓存上。在某个A15上执行Clean清指令缓存,范围指定PoU。显然,所有四个A15的一级指令缓存都会被清掉。那么其他的各个Master是不是受影响?那就要用到Inner/Outer/Non Shareable。
Shareable的很容易理解,就是某个地址的可能被别人使用。我们在定义某个页属性的时候会给出。Non-Shareable就是只有自己使用。当然,定义成Non-Shareable不表示别人不可以用。某个地址A如果在核1上映射成Shareable,核2映射成Non-Shareable,并且两个核通过CCI400相连。那么核1在访问A的时候,总线会去监听核2,而核2访问A的时候,总线直接访问内存,不监听核1。显然这种做法是错误的。
对于Inner和Outer Shareable,有个简单的的理解,就是认为他们都是一个东西。在最近的ARM A系列处理器上上,配置处理器RTL的时候,会选择是不是把inner的传输送到ACE口上。当存在多个处理器簇或者需要双向一致性的GPU时,就需要设成送到ACE端口。这样,内部的操作,无论inner shareable还是outer shareable,都会经由CCI广播到别的ACE口上。
说了这么多概念,你可能会想这有什么用处?回到上文的Clean指令,PoU使得四个A7的指令缓存中对应的行都被清掉。由于是指令缓存操作,Inner Shareable属性使得这个操作被扩散到总线。而CCI400总线会把这个操作广播到所有可能接受的口上。ACE口首当其冲,所以四个A15也会清它们对应的指令缓存行。对于Mali和DMA控制器,他们是ACE-Lite,本不必清。但是请注意它们还连了DVM接口,专门负责收发缓存维护指令,所以它们的对应指令缓存行也会被清。不过事实上,它们没有对应的指令缓存,所以只是接受请求,并没有任何动作。
要这么复杂的定义有什么用?用处是,精确定义TLB/缓存维护和读写指令的范围。如果我们改变一下,总线不支持Inner/Outer Shareable的广播,那么就只有A7处理器组会清缓存行。显然这么做在逻辑上不对,因为A7/A15可能运行同一行代码。并且,我们之前提到过,如果把读写属性设成Non-Shareable,那么总线就不会去监听其他主,减少访问延迟,这样可以非常灵活的提高性能。
再回到前面的问题,刷某行缓存的时候,怎么知道数据是否最终写到了内存中?对不起,非常抱歉,还是没法知道。你只能做到把范围设成PoC。如果PoC是三级缓存,那么最终刷到三级缓存,如果是内存,那就刷到内存。不过这在逻辑上没有错,按照定义,所有Master如果都在三级缓存统一数据的话,那就不必刷到内存了。
简而言之,PoU/PoC定义了指令和命令的所能抵达的缓存或内存,在到达了指定地点后,Inner/Outer Shareable定义了它们被广播的范围。
再来看看Inner/Outer Cacheable,这个就简单了,仅仅是一个缓存的前后界定。一级缓存一定是Inner Cacheable的,而最外层的缓存,比如三级,可能是Outer Cacheable,也可能是Inner Cacheable。他们的用处在于,在定义内存页属性的时候,可以在不同层的缓存上有不同的处理策略。
在ARM的处理器和总线手册中,还会出现几个PoS(Point of Serialization)。它的意思是,在总线中,所有主设备来的各类请求,都必须由控制器检查地址和类型,如果存在竞争,那就会进行串行化。这个概念和其他几个没什么关系。
纵观整个总线的变化,还有一个核心问题并没有被提及,那就是动态规划re-scheduling与合并Merging。处理器和内存控制器中都有同样的模块,专门负责把所有的传输进行分类,合并,调整次序,甚至预测未来可能接收到的读写请求地址,以实现最大效率的传输。这个问题在分析性能时会重新提到。但是在总线这层,软件能起的影响很小。清楚了总线延迟和OT最大的好处是可以和性能计数器的统计结果精确匹配,看看是不是达到预期了。
现在手机和平板上最常见的用法,CCI连接CPU和GPU,作为子网,网内有硬件一致性。NoC连接子网,同时连接其余的设备,包括多个内存控制器和视频,显示控制器,不需要一致性。优点是兼顾一致性,大带宽和灵活性,缺点是CPU/GPU到内存控制器要跨过两个网,延迟有点大。
访存路径的最后一步是内存。有的程序员认为内存是一个所有地址访问时间相等的设备,是这样的么?这要看情况。
DDR地址有三个部分组成,行,bank,列。一旦这三个部分定了,那么就可以选中确定的一个物理页,通常有2-8KB大小。我们买内存的时候,有3个性能参数,比如10-10-10。这个表示访问一个地址所需要的三个操作时间,行有效(包括选bank),列选通(命令/数据访问),还有预充电。前两个好理解,第三个的意思是,某个内存物理页暂时用不着,必须关闭,保持电容电压,否则再次使用这页数据就丢失了。如果连续的内存访问都是在同行同bank,那么第一和第三个10都可以省略,每一次访问只需要10单位时间;同行不同bank,表示需要打开一个新的页,只有第三个10可以省略,共20单位时间;不同行同bank,那么需要关闭老页面,打开一个新页面,预充电没法省,共30单位时间。
我们得到什么结论?如果控制好物理地址,就能使某段时间内的访存都集中在一个页内,从而节省大量的时间。根据经验,在突发访问时,最多可以省50%。那怎么做到这一点?去查查芯片手册中物理内存地址到内存管脚的映射,就可以得到需要的物理地址。然后调用系统函数,为这个物理地址分配虚拟地址,就可以使得程序只访问某个固定的物理内存页。
在访问有些数据结构时,特定的大小和偏移有可能会不小心触发不同行同bank这个条件。这样可能每次访问都是最差情况。为了避免这种最差情况的产生,有些内存控制器可以自动让最终地址哈希化,打乱原有的不同行同bank条件,从而在一定程度上减少延迟。我们也可以通过计算和调整软件物理地址来避免上述情况的发生。
在实际的访问中,通常无法保证访问只在一个页中。DDR内存支持同时打开多个页,比如4个。而通过交替访问,我们可以同时利用这4个页,不必等到上一次完成就开始下一个页的访问。这样就可以减少平均延迟。如下图:
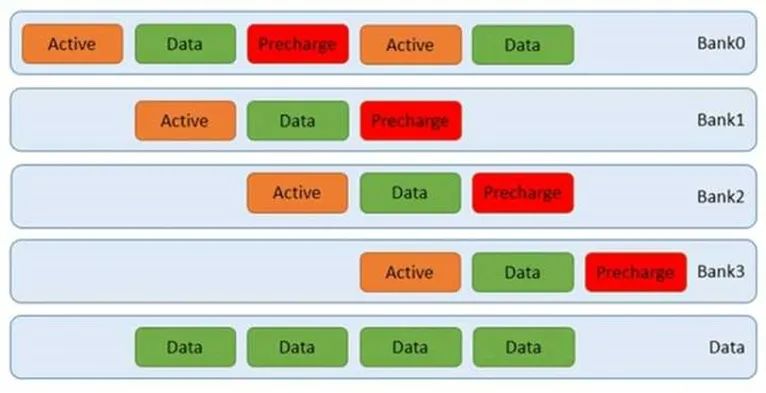
我们可以通过突发访问,让上图中的绿色数据块更长,那么相应的利用率就越高。此时甚至不需要用到四个bank,如下图:
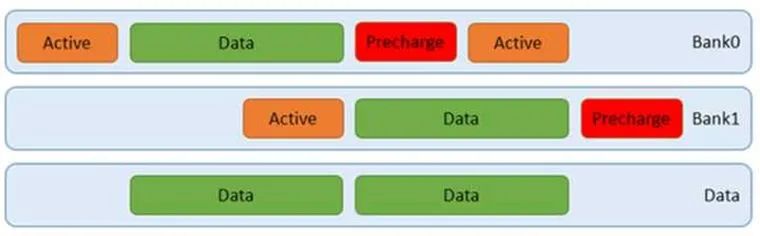
如果做的更好些,我们可以通过软件控制地址,让上图中的预充电,甚至行有效尽量减少,那么就可以达到更高的效率。还有,使用更好的内存颗粒,调整配置参数,减少行有效,列选通,还有预充电的时间,提高DDR传输频率,也是好办法,这点PC机超频玩家应该有体会。此外,在DDR板级布线的时候,控制每组时钟,控制线,数据线之间的长度差,调整好走线阻抗,做好自校准,设置合理的内存控制器参数,调好眼图,都有助于提高信号质量,从而可以使用更短的时序参数。
如果列出所有数据突发长度情况,我们就得到了下图:
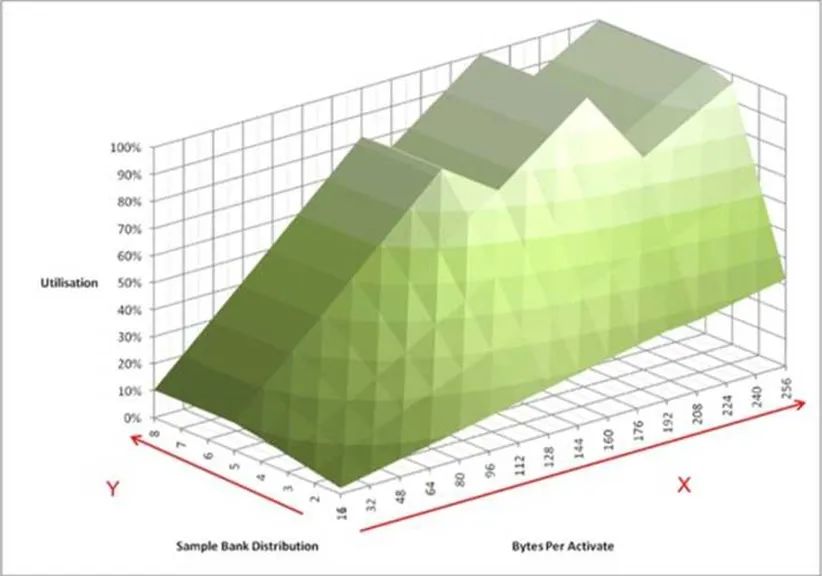
上面这个图包含了更直观的信息。它模拟内存控制器连续不断的向内存颗粒发起访问。X轴表示在访问某个内存物理页的时候,连续地址的大小。这里有个默认的前提,这块地址是和内存物理页对齐的。Y轴表示同时打开了多少个页。Z轴表示内存控制器访问内存颗粒时带宽的利用率。我们可以看到,有三个波峰,其中一个在128字节,利用率80%。而100%的情况下,访问长度分别为192字节和256字节。这个大小恰恰是64字节缓存行的整数倍,意味着我们可以利用三个或者四个8拍的突发访问完成。此时,我们需要至少4个页被打开。
还有一个重要的信息,就是X轴和Z轴的斜率。它对应了DDR时序参数中的tFAW,限定单位时间内同时进行的页访问数量。这个数字越小,性能可能越低,但是同样的功耗就越低。
对于不同的DDR,上面的模型会不断变化。而设计DDR控制器的目的,就是让利用率尽量保持在100%。要做到这点,需要不断的把收到的读写请求分类,合并,调整次序。而从软件角度,产生更多的缓存行对齐的读写,保持地址连续,尽量命中已打开页,减少行地址和bank地址切换,都是减少内存访问延迟的方法。
交替访问也能提高访存性能。上文已经提到了物理页的交替,还可以有片选信号的交替访问。当有两个内存控制器的时候,控制器之间还可以交替。无论哪种交替访问,都是在前一个访问完成前,同时开始下一个传输。当然,前提必须是他们使用的硬件不冲突。物理页,片选,控制器符合这一个要求。交替访问之后,原本连续分布在一个控制器的地址被分散到几个不同的控制器。最终期望的效果如下图:
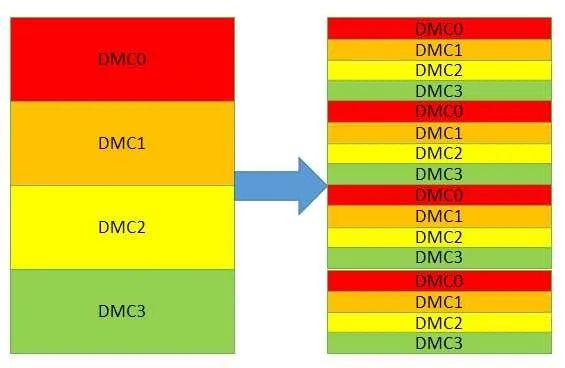
这种方法对连续的地址访问效果最好。但是实际的访存并没有上图那么理想,因为哪怕是连续的读,由于缓存中存在替换eviction和硬件预取,最终送出的连续地址序列也会插入扰动,而如果取消缓存直接访存,可能又没法利用到硬件的预取机制和额外的OT资源。
实测下来,可能会提升30%左右。此外,由于多个主设备的存在,每一个主都产生不同的连续地址,使得效果进一步降低。因此,只有采用交织访问才能真正的实现均匀访问多个内存控制器。
当然,此时的突发长度和粒度要匹配,不然粒度太大也没法均匀,就算均匀了也未必是最优的。对于某个内存控制来说,最好的期望是总收到同一个物理页内的请求。
还有一点需要提及。如果使用了带ecc的内存,那么最好所有的访问都是ddr带宽对齐(一般64位)。因为使能ecc后,所有内存访问都是带宽对齐的,不然ecc没法算。如果你写入小于带宽的数据,内存控制器需要知道原来的数据是多少,于是就去读,然后改动其中一部分,再计算新的ecc值,再写入。这样就多了一个读的过程。根据经验,如果访存很多,关闭ecc会快8%。
编辑:jq
-
处理器
+关注
关注
68文章
19223浏览量
229523 -
数据
+关注
关注
8文章
6957浏览量
88905 -
总线
+关注
关注
10文章
2875浏览量
88027
原文标题:技术分享 | ARM攒机指南 - 基础篇
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
迅为iTOP-RK3568开发板驱动开发指南-第十八篇 PWM
【北京迅为】i.mx8mm嵌入式linux开发指南第四篇 嵌入式Linux系统移植篇第六十九章uboot移植

从Renesas RL78到基于Arm的MSPM0的迁移指南

安森美光伏逆变器系统设计指南
【《大语言模型应用指南》阅读体验】+ 基础篇
【《大语言模型应用指南》阅读体验】+ 俯瞰全书
文档更新 |迅为 RK3568开发板驱动指南-第十五/十六篇
RT-Thread驱动开发指南进阶篇-动手驱动先楫未适配的外设LCD
RK3568驱动指南|驱动基础进阶篇-进阶5 自定义实现insmod命令实验

GD32W515系列 32位ARM® Cortex® -M33 MCU选择指南





 工商网监
工商网监
评论