 如何改进双塔模型才能更好的提升你的算法效果
如何改进双塔模型才能更好的提升你的算法效果
来自:对白的算法屋
今天写点技术干货来回馈一下我的粉丝们。本来想继续写对比学习(Contrastive Learing)相关类型的文章,以满足我出一本AI前沿技术书籍的梦想,但奈何NIPS2021接收的论文一直未公开,在arxiv上不停地刷,也只翻到了零碎的几篇。于是,我想到该写一下双塔模型了,刚进美团的第一个月我就用到了Sentence-BERT。
为什么呢?因为双塔模型在NLP和搜广推中的应用实在太广泛了。不管是校招社招,面试NLP或推荐算法岗,这已经是必问的知识点了。
接下来,我将从模型结构,训练样本构造,模型目标函数三个方面介绍双塔模型该如何改进,才能更好的提升业务中的效果。
一、双塔模型结构改进
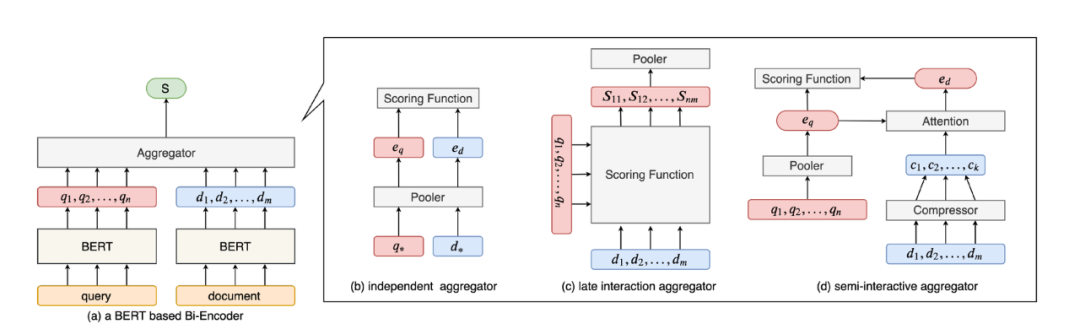
如图所示,目前主流的双塔模型结构主要可以归为三类。
第一类在离线阶段直接将BERT编码的document映射为固定长度的向量,在线阶段将query映射为固定长度的向量,然后通过打分函数计算最后的得分,例如:Sentence-BERT,DPR。
第二类
模型在离线阶段将BERT编码document得到的多个向量(每个向量对应一个token)全部保留,在线阶段利用BERT将query编码成多个向量,和离线阶段保留的document的多个向量进行交互打分(复杂度O(mn)),得到最后的得分,代表工作,Col-BERT。
第三类
模型是前两种的折中,将离线阶段BERT编码得到的document向量进行压缩,保留k个(k《m)个向量,并且使用一个向量来表示query(一般query包含的信息较少),在线阶段计算一个query向量和k个document向量的交互打分(复杂度O(k)),代表工作:Poly-BERT,PQ-BERT。
总结这类工作的主要思想是增强双塔模型的向量表示能力,由于document较长,可能对应多种语义,而原始双塔模型对query和document只使用一个向量表示,可能造成语义缺失。那么可以使用多个向量来表示document,在线阶段再进行一些优化来加速模型的推断。
二、训练样本构造
检索任务中,相对于整体document库,每个query所对应的相关document是很少的一部分。在训练时,模型往往只接收query对应的相关文档(正样本)以及少量query的不相关文档(负样本),目标函数是区分正样本和负样本。然而在模型推断时,模型需要对document库中的所有document进行打分。如果模型在训练时读取的document和document库中的一些document之间的语义距离相差较大,则可能造成模型在推断阶段表现不佳。因此,如何构造训练样本是一个重要的研究方向。
方法一:(1) 首先介绍一个比较简单的trick,In-batch negatives。顾名思义,在训练时,假设一个batch中包含b个query,每个query(q_i)都有一个对应的正样本dp_i和负样本dq_i,那么在这个batch中,每个q_i除了自己所对应的负样本,还可以将batch中其他query所对一个的正样本和负样本都作为当前query所对应的负样本,大大提高了训练数据的利用率。实验表明,该trick在各种检索任务上都能提高模型的效果。
方法二:(2) 上述方法的目标是在训练过程中利用更多的负样本,让模型的鲁棒性更强。然而训练过程能遍历的负样本始终是有限的,那么如何在有限的训练样本中构造更有利于模型训练的负样本是一个重要的研究问题。
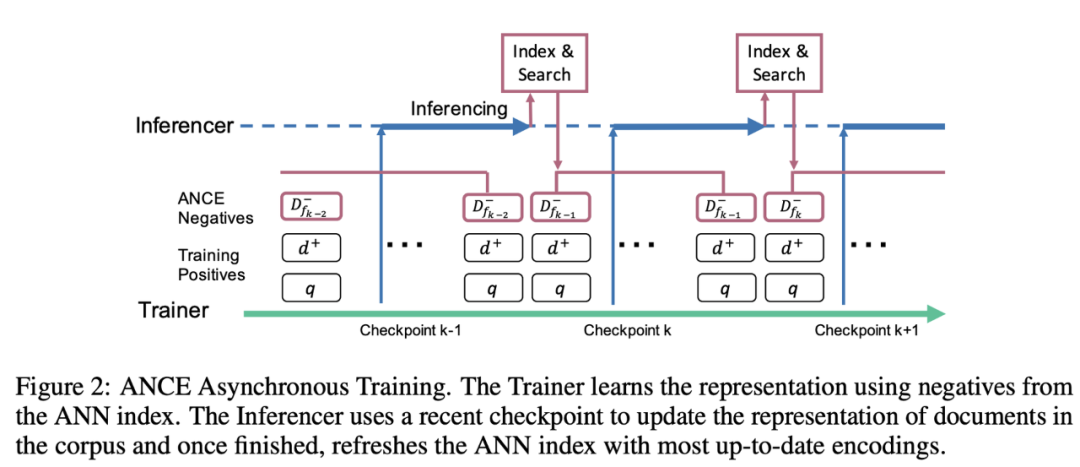
ANCE提出了一种迭代式生成负样本的思路:随着训练的进行,模型对于文本的表示也会变化,之前对于模型较难的负样本可能变得不那么难,而之前没见过的负样本对于模型可能会较难区分。该工作以此为出发点,同时进行train和inference,在训练的同时,利用上一个checkpoint中的模型进行inference,对训练数据生成新的负样本,在inference完成后,使用新的负样本进行训练。这样可以渐进的训练模型,保持负样本的难度,更充分的训练模型。
方法三:(3) 除了利用模型本身来生成负样本,还可以利用比双塔模型复杂的交互模型来生成训练数据。RocketQA提出了基于交互模型来增强数据的方法。由于交互模型的表现更强,作者使用交互模型来标注可能成为正样本的文档(这些文档未经过标注),以及筛选更难的训练双塔模型的样本。具体的训练过程如下图所示:
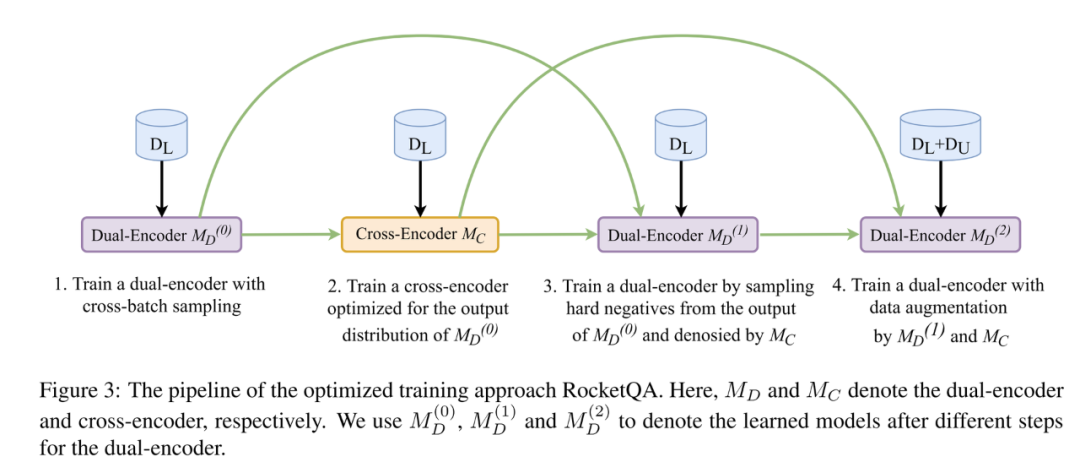
总结:这类工作从训练数据着手,弥补原有的训练模式对于缺少负样本优化的不足。个人角度认为这类工作提升可能更为显著。
三、训练目标改进
训练目标上的改进比较灵活,有多种不同的改进方式,首先介绍利用交互模型改进双塔模型的工作。
相对于双塔模型,交互模型的表现更好,但复杂度更高,因此很多工作的idea是通过模型蒸馏将交互模型的文本表示能力迁移到双塔模型中,这方面有很多类似的工作。这里选取一个SIGIR2021的最新文章作为代表。
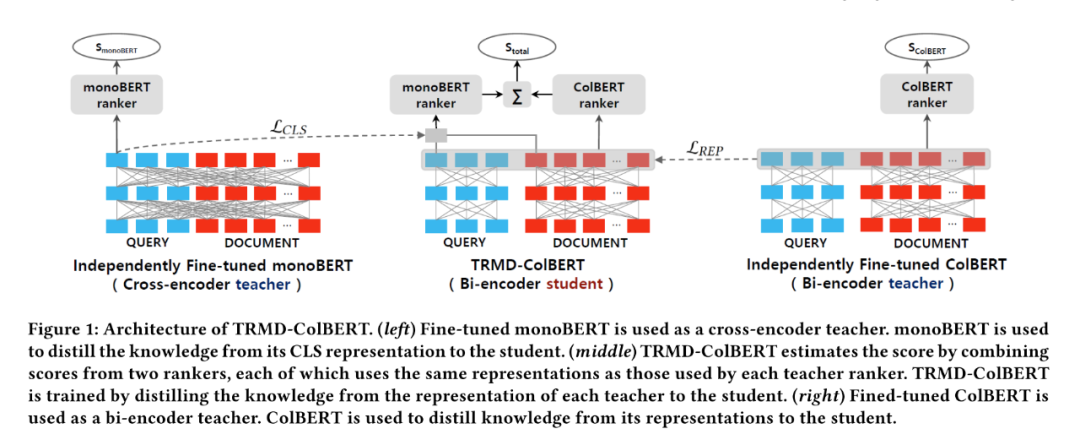
如上图所示,该模型不仅蒸馏了一个交互模型(monoBERT),同时还蒸馏了一个基于双塔的改进模型ColBERT。该模型使用monoBERT作为teacher,对模型的CLS位置向量进行蒸馏,使用ColBERT作为teacher,对模型的除了[CLS]位置的向量进行蒸馏,目标函数为以下三部分的加和:
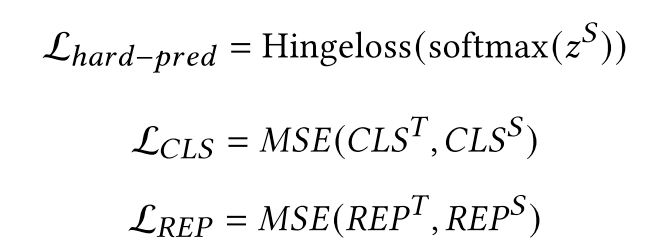
最后的打分函数是monoBERT和ColBERT的组合,即,首先使用document和query的CLS位置向量输入MLP,输出一个分数,同时使用document和query的其他位置表示向量输入到和ColBERT相同的打分函数中,最后使用两个分数的和作为最后打分。
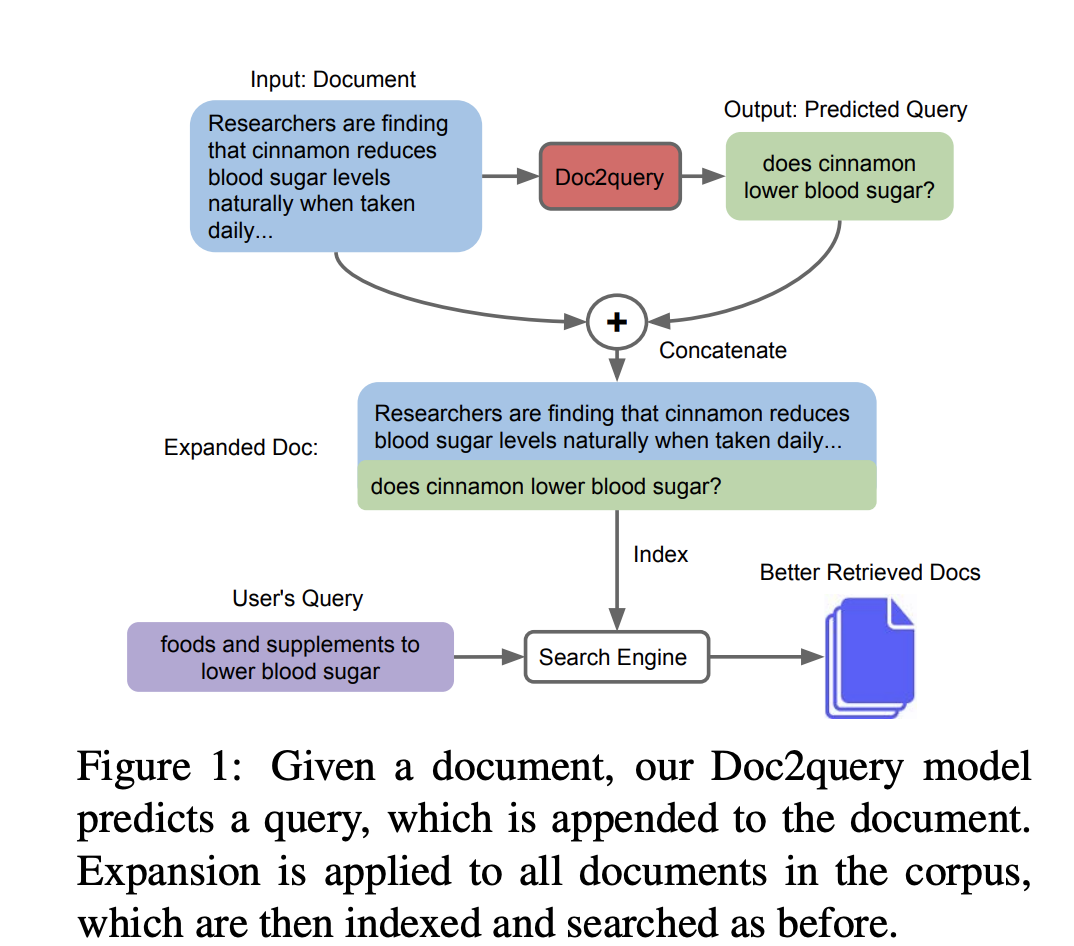
前文所述的工作都是将query和document的文本映射到稠密向量空间中,然后进行匹配。另外还有的工作是直接利用文字进行匹配。Doc2query使用一个基于seq2seq的预训练语言模型(比如T5),利用标注的document,query对进行finetune,目标是输入document输出对应的query,然后将输出的query和document本身进行拼接,扩展document。然后利用传统的检索方法,比如BM25,对扩展过的document建立索引并查找。过程示意如下图所示。在MSMARCO上的一些实验表明,这个方法可以和基于向量的搜索一起使用,提高模型的表现。
四、双塔模型预训练
一般的预训练模型使用的目标函数主要是MLM或者seq2seq,这种预训练目标和双塔的匹配任务还是有一些不一致。并且已有的预训练模型即使有匹配任务(比如NSP),也是使用交互而非双塔的工作方式。为了使用预训练提高双塔模型的效果,SimCSE通过对比学习,提升模型对句子的表示能力。
该方法的实现很简单,假设提取一个batch的句子,通过模型自带的dropout,将每个句子输入到预训练模型中,dropout两次,将同一个句子dropout后的结果作为正样本,不同句子的dropout结果作为负样本,拉近正样本的距离,拉远负样本的距离,每个句子的向量由BERT的CLS位置向量表示。如下图所示:
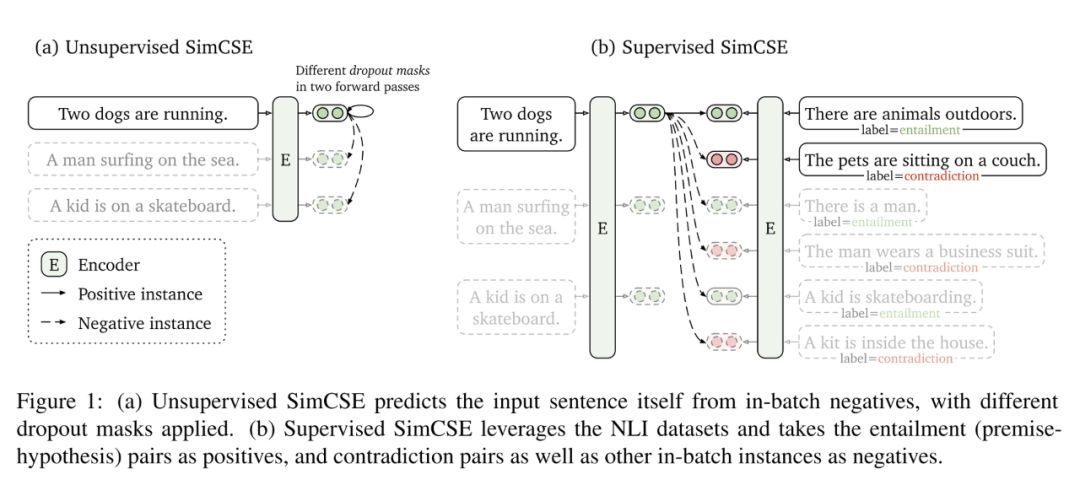
模型虽然很简单,但是在句子匹配任务上取得了很好的效果。该模型在检索任务上的效果还需实验。
还有的工作是针对检索任务的预训练。ICLR2020一篇论文Pre-training Tasks for Embedding-based Large-scale Retrieval提出了一些预训练任务,这些任务主要是针对Wikipedia的,不一定具有普适性。如下图所示,紫色d框出来的代表document,q1,q2,q3代表不同任务构造的的query,q1是ICT,即利用document所在的一句话作为query,q2是BFS,即利用document所在网页的第一段中的一句话作为query,q3是WLP,使用document中的某个超链接页面的第一句话作为query。任务目标是匹配q1,q2,q3和d。

Condenser
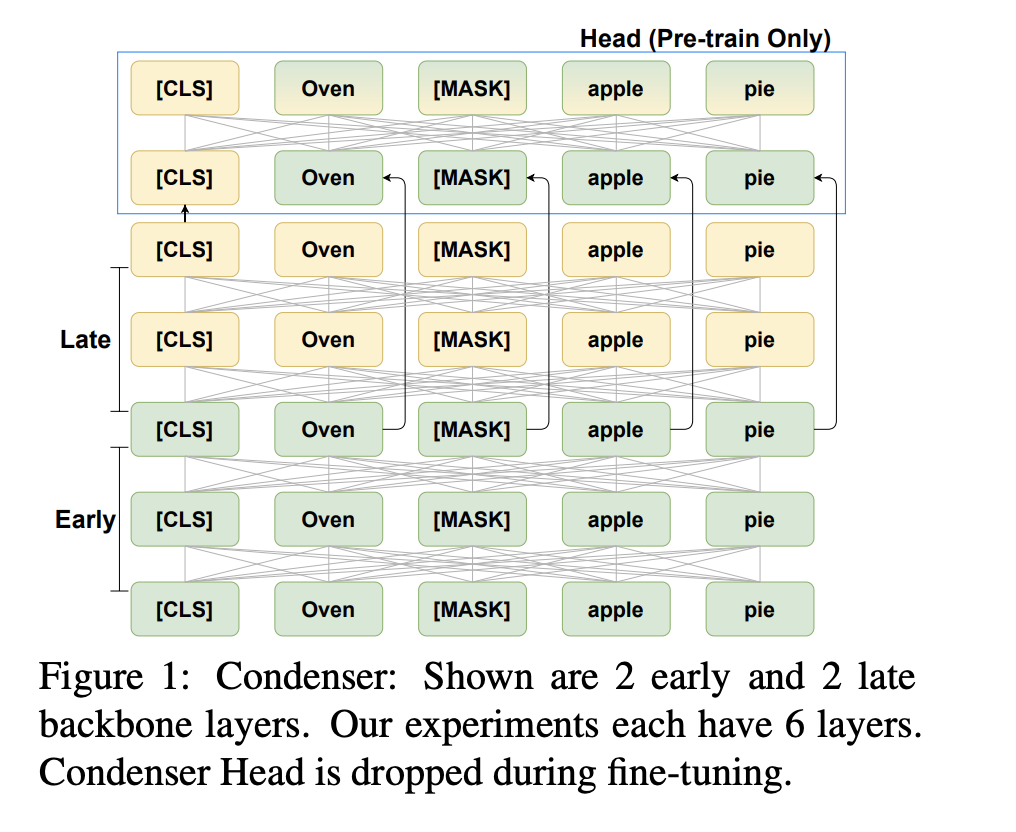
传统的MLM预训练任务如下图所示,该任务没有特别强制训练CLS位置的向量表示能力。为了将整个序列的信息压缩到CLS位置上,Condenser将模型分成两部分,第一部分和普通的Transformer一样,第二部分使用经过更多交互后的[CLS]位置向量(黄色部分)来预测[MASK]的token,强制模型的[CLS]编码可以具有还原其他token的能力。
编辑:jq
-
AI
+关注
关注
87文章
31099浏览量
269435 -
编码
+关注
关注
6文章
946浏览量
54870 -
CLS
+关注
关注
0文章
9浏览量
9718 -
nlp
+关注
关注
1文章
489浏览量
22053
原文标题:业界总结 | 如何改进双塔模型,才能更好的提升你的算法效果?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI模型部署边缘设备的奇妙之旅:目标检测模型
如何提升ASR模型的准确性
如何提升AIC3254 AEC的录音效果?
如何评估AI大模型的效果
未来AI大模型的发展趋势
通过两级OPA656实现微弱光电信号的放大,如何才能更好的抑制噪声呢?
大电流绕线电感选择什么规格的效果会更好
图像识别算法的提升有哪些
ai大模型和算法有什么区别
yolox_bytetrack_osd_encode示例自带的yolox模型效果不好是怎么回事?
深度学习模型训练过程详解
【大语言模型:原理与工程实践】大语言模型的应用
【大语言模型:原理与工程实践】揭开大语言模型的面纱
为什么深度学习的效果更好?






 工商网监
工商网监
评论