 对 B+ 树与索引在 MySQL 中的认识
对 B+ 树与索引在 MySQL 中的认识

概述
本质:数据库维护某种数据结构以某种方式引用(指向)数据
索引取舍原则:索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数
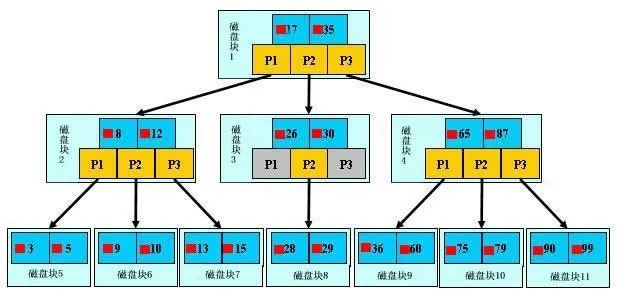
B树
满足的条件
d为大于1的一个正整数,称为B-Tree的度
h为一个正整数,称为B-Tree的高度
每个非叶子节点由n-1个key和n个指针组成,其中d《=n《=2d
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null
所有叶节点具有相同的深度,等于树高h
key和指针互相间隔,节点两端是指针
一个节点中的key从左到右非递减排列
所有节点组成树结构
每个指针要么为null,要么指向另外一个节点
一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key查找节点的个数的渐进复杂度为logd(N)
更新后的操作
插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质
B+树
每个节点的指针上限为2d而不是2d+1
内节点不存储data,只存储key
叶子节点不存储指针
在经典B+树的基础上,增加了顺序访问指针--》提高区间访问的性能
为什么使用B/B+树?
主存读取
当系统需要读取主存时,则将地址信号放到地址总线上传给主存
主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,供其它部件读取
主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响
磁盘存取原理
磁盘转动,每个磁头不动,负责读取内容
不过已经有了多磁头独立技术
局部性原理
磁盘预读:长度一般以页的整数倍为单位
MyISAM索引实现
使用B+树作为索引结构,data存放数据记录的地址
索引文件与数据文件分离
主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
非聚集:MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录
.MYI文件的组成
整个索引文件的基本信息state
各索引的限制信息base
各索引的定义信息keydef
各索引记录的概要信息recinfo
读取索引的流程
query请求,直接读取key cache中的cache block,有就返回
没有就到.MYI文件中以file block方式读取数据
再以相同的格式存取key cache
再将key cache中的数据返回
InnoDB索引实现
也是使用B+树
第一个与MyISAM的不同点
第一个重大区别是InnoDB的数据文件本身就是索引文件,表数据文件本身就是按B+Tree组织的一个索引结构
InnoDB的数据文件本身要按主键聚集
所以InnoDB要求表必须有主键(MyISAM可以没有)
没有显式指定,自动选择唯一标识列
不存在的话,生成6个字节长整型的隐含字段
第二个与MyISAM的不同点
InnoDB的辅助索引data域存储相应记录主键的值而不是地址
换句话说,InnoDB的所有辅助索引都引用主键作为data域
辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录
得出的优化点
不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大
用非单调的字段作为主键在InnoDB中也不好,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键就很不错了
聚簇索引键被更新造成的成本除了索引数据可能会移动,相关的所有记录数据也要移动
索引使用策略及优化
全列匹配
按照索引中所有列进行精确匹配(这里精确匹配指“=”或“IN”匹配)时,索引可以被用到
理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引
最左前缀匹配
当查询条件精确匹配索引的左边连续一个或几个列时,索引可以被用到
查询条件用到了索引中列的精确匹配,但是中间某个条件未提供
只能用到索引中,从中间断开前的列
应对
可以增加辅助索引
当中间条件选项较少时,用隔离列的方式,使用IN包含
看情况,比较建立
查询条件没有指定索引第一列
不满足使用索引的条件
匹配某列的前缀字符串
可以使用索引
如果通配符%不出现在开头,则可以用到索引,但根据具体情况不同可能只会用其中一个前缀
范围查询
范围列可以用到索引(必须是最左前缀),但是范围列后面的列无法用到索引
同时,索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引
仅用explain可能无法区分范围索引和多值匹配
查询条件中含有函数/表达式
一般不使用哦
手工算好再代入
索引选择性与前缀索引
MyISAM与InnoDB基数统计方式
MyisAM索引的基数值(Cardinality,show index 命令可以看见)是精确的,InnoDB则是估计值
MyisAM统计信息是保存磁盘中,在alter表或Analyze table操作更新此信息
而InnoDB则是在表第一次打开的时候估计值保存在缓存区内
不建议建立索引的情况
表记录比较少
索引的选择性低:不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值
前缀索引
用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销
缺点
不能用于ORDER BY和GROUP BY操作
也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)
InnoDB主键选择与插入优化
如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键
InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上
这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
如果使用非自增主键,每次插入近似随机,容易引起数据的移动,重新读目标页面,碎片也多了,虽然也可以用OPTIMIZE TABLE重建优化,但麻烦啊
参考资料
图片来源网络
《高性能MySQL》
作者:AnnsShadoW
https://www.cnblogs.com/annsshadow/p/5355090.html
编辑:jq
-
磁盘
+关注
关注
1文章
401浏览量
26589 -
数据库
+关注
关注
7文章
4082浏览量
68538 -
MySQL
+关注
关注
1文章
930浏览量
29746
原文标题:对 B+ 树与索引在 MySQL 中的认识
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
坤维科技完成B+轮融资,领跑人形机器人“力控感知”新赛道

发电机B+、D+、W、N端子接什么线
MySQL慢查询分析与索引调优全流程
润芯微科技完成近4亿元B+轮融资

工业数据中台支持接入MySQL数据库吗

Hudi系列:Hudi核心概念之索引(Indexs)
先楫半导体完成B+轮融资,中移和创投资加持

宜科MVT阀岛在宇树科技人形机器人中的应用
MySQL慢查询终极优化指南
2.88亿!滤波器明星企业新声半导体完成B+轮融资



评论