 在不更改模型结构和不修改数据的情况下提升智能体
在不更改模型结构和不修改数据的情况下提升智能体
2018 年 Anderson 等人提出了视觉语言导航(Vision-and-Language Navigation,VLN)任务和对应的基准数据集(Room-to-Room Dataset)。该任务旨在探究智能体是否能在仿真模拟环境中遵循自然语言指令,因此可以形式化的评估智能体是否具有跨模态的理解能力。先前的工作取得了长足的进步,然而少有工作专注于探究智能体是否充分学习了数据中的信息,或者说,智能体是一个好学生吗?在计算机视觉领域,Hlynsson 等人试图通过衡量数据效率来回答这个问题。具体而言,该工作将模型性能作为数据集大小的函数,并衡量在不同规模数据集上模型的性能。在视觉语言导航领域,Huang 等人开发了基于神经网络的数据鉴别器(discriminator),可以过滤低质量的指令路径对以提升智能体的学习效率。而在本文中,我们试图回答:能否在不更改模型结构和不修改数据的情况下进一步提升智能体?
我们监控了智能体在导航过程中所犯的第一个错误,并在下图中展示了不同错误的比率。我们发现当智能体导航失败时,大约 50% 的错误是由代理错误地预测下一个室内方向引起的。此类错误的比例随着导航任务跨越更多房间而降低,但仍保持在一个较高水平。这些现象表明导航智能体受限于它在一个房间内和两个房间之间导航的能力。因此,我们认为传统学习过程使得智能体不能充分地学习数据中的信息,采用类似范式进行训练的导航智能体很可能被低估了。
02 Methods
智能体在这些简单案例上的糟糕表现激励我们借鉴课程学习的想法。课程学习是一类关注数据集中样本难度的分布的训练范式,由 Bengio 于 2009 年提出,主要思想是模仿人类学习的特点,让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。本文借鉴了课程学习的理念,首创性地提出了基于课程的 VLN 训练范式。
首先,我们为导航任务设计了合适的课程。从抽象角度看,课程被视为一系列训练准则。每个训练准则都与训练样本上的一组不同的权重相关联,或更普遍地,与训练样本分布的重新加权有关。要定义课程,首先需要定义样本的难度。对于人类来说,很容易在很小的范围内找到特定物体或地点。在经过简单的探索后,人类就可以利用有关环境的知识来完成更艰巨的任务。因此,我们假设路径 可以覆盖的房间数量 主导了导航任务的难度级别。我们建议根据 对基准数据集R2R数据集进行重新划分,划分后的数据集如下表所示:
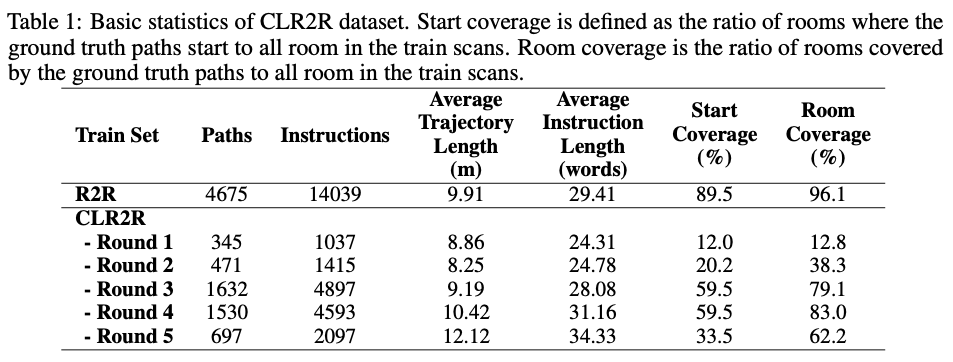
我们认为从简单到困难的数据集划分方式使得对智能体在这些子集上的学习与玩街机游戏非常相似,因此我们根据子集中样本的难度将训练集的各个子集命名为第一回合(Round 1)至第五回合(Round 5)。从平均路径长度、平均指令长度和全景图覆盖率可以看出,我们划分的数据子集呈现出明显的阶梯特征。这说明我们对数据集难度的划分是合理的。新数据集被称为为课程学习设计的R2R数据集(R2R for curriculum learning dataset,CLR2R dataset)。
有许多方法可以应用在 CLR2R 数据集上。如果我们将每个子集都视为一个课程,则 CLR2R 适用于自动课程学习。如果我们将整个数据集视为一个大课程,则每个回合中的样本应被赋予相同的优先级,因此可以使用自定进度的课程学习。在本文中,我们将重点放在后一种模式上。
由 Jiang 等人提出的自定进度课程学习(Self-Paced Curriculum Learning,SPCL)是一种“师生协作”学习方法,它在统一框架中考虑了训练之前人类对于数据的先验知识和训练过程中智能体对数据的学习进度。具体而言,SPCL 的目标损失函数定义为
其中 表示参数化的导航智能体, 是反映样本重要性的权重变量。 称为控制学习方案的自定进度函数, 是限制学习速度的超参数。 是编码预定课程表(predetermined curriculum)信息的可行区域。本文将 CLR2R 数据集看作一个完整的课程。因此每个回合中的样本应被赋予相同的课程等级。因此,在 CLR2R 数据集上只需 5 个标量就足以定义课程区域的参数向量。Jiang 等人讨论了一些自定进度函数的具体形式,在本文中, 我们主要关注两种较为简单的自定进度函数:二进制方案(binary scheme)和线性方案(linear scheme)。
容易发现,公式(1)中的两个参数是可以交替优化的。具体而言,对于参数 的优化是一个凸优化问题,
在 和简单自定进度函数的条件下具有封闭解。本质上公式(2)是一个线性约束凸优化问题。对于一般的课程区域 我们可以应用投影梯度下降法(Projected Gradient Descent,PGD)来获得最优权重 。
通常, 公式(1)中的优化问题可以采用交替凸搜索算法(Alternative Convex Search,ACS)求解。原始算法的主要问题是在第 4 步,其中使用固定的最新权重向量 来学习最佳模型参数 。在基于神经网络的导航智能体的训练中,由于梯度下降方法优化的神经网络缺乏全局最优保证以及计算复杂度问题,我们不可能计算的确切最优值。因此本文建议无需计算确切的最小值,将原算法中的第 4 步替换为机器学习训练范式中的多个梯度下降更新步骤。这样做能使算法的速度加快,并且此时权重向量 实际上是通过考虑 “当前”学习进度而不是 “最终” 学习进度来更新的。
03 Experiments
3.1 Setup
在实验中,我们采用了三种训练范式
机器学习: 对训练数据集进行一致采样(Uniform Sampling),采样得到的数据作为批数据(mini-batch)呈递给模型进行学习。
朴素课程学习(Naïve Curriculum Learning):对训练集中的样本从易到难进行排序,按照从易到难的顺序将样本呈递给模型进行学习。具体而言, 智能体首先在 CLR2R 数据集的 Round 1 子集上进行学习, 然后在 Round 1~2 子集上进行学习, 最终在集合 Round 1~5 (也就是 R2R 的训练集) 上进行学习。
自定进度课程学习(Self-Paced Curriculum Learning):如前所述,为了应用 SPCL 算法,我们需要首先确定课程区域和自定进度函数。对于课程区域,我们假设 CLR2R 数据集中每个 Round 子集中的样本都具有相同的难度,因此我们设置 Round 。对于自定进度的函数,由于在导航任务中每个样本对于的损失 是不受限的,因此我们选择二进制方案和线性方案。
3.2 Results
主要结果:下表提供三个 SOTA 智能体在不同的训练设置下在验证集的上的实验结果。实验表明,采用自定进度课程学习训练的智能体在已见和未见的验证划分上都可以达到最佳性能。
学习速率:整体而言,相比于传统机器学习,采用自定进度课程学习训练的智能体在迭代相同的次数之后可以获得更优的性能表现。相同精度的结果,采用自定进度课程学习所需要的循环次数大大减少。这说明自定进度课程学习不仅可以提升模型的性能,还可以优化模型的训练效率。
SPCL 超参数鲁棒性:为了理解权重 初始化和步长 的选择对自定进度课程学习的影响,我们对这两个超参数进行网格搜索,结果如图所示。下图表明,自定进度课程学习对权重初始化和步长选择并不敏感,在大多数情况下采用自定进度课程学习训练的导航智能体在验证集上的结果都要优于机器学习基准。
损失地形:为了探究自定进度课程学习为何能够提升导航智能体的性能,我们遵循计算机视觉分析批归一化采用的方法,通过计算最大和最小损失之间的距离来研究智能体训练期间的损失地形。结果如图所示。一般而言,我们的实验结果与理论结果一致,即课程学习可以有效地平滑优化环境、改善损失地形。
迁移学习:使用课程学习训练 的智能体既可以保持在 R2R 数据集上的导航性能,也能够迁移到 RxR-en 数据集上完成更难的导航任务。
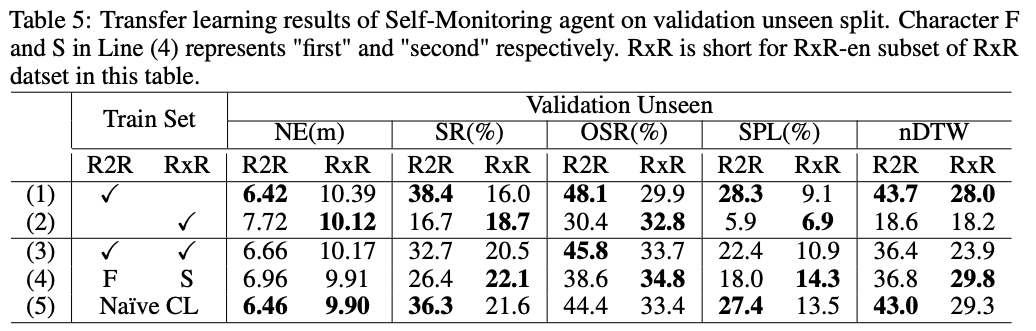
与预训练方法结合:为了探究采用课程学习范式训练的导航智能体是否也可以从预训练方法中受益,我们将智能体与基于视觉语言 Transformer 的模型 VLN-BERT(Majumdar 等,2020)相结合。我们将束搜索大小限制为 5,并纯粹使用 VLN-BERT 模型来评分和选择路径-指令对。在未见验证划分上的结果如图所示。Beam search 和 VLN-BERT 都可以提高智能体的导航性能。通过基于课程的方法训练的导航智能体获得更多改进。
04 Conclusion
我们首先建议将有关训练样本的人类先验知识整合到导航智能体的训练过程中,首先提出采用课程学习对导航智能体进行训练。
我们为视觉语言导航任务设计了第一个课程,并基于 Room-to-Room ( ) 数据集构建了可用于课程学习的第一个 VLN 数据集。
我们采用自定进度课程学习提出了一种导航智能体的训练范式。这种训练范式能在不增加模型复杂度的前提下提高智能体的训练效率和性能。
我们验证了课程学习的作用是平滑损失函数 (smooth loss landscape),从而加速学习进度、使智能体收敛到更好的局部最优点。
我们进一步的实验表明,课程学习适用于迁移学习,并能与预训练方法相结合。
责任编辑:haq
-
机器视觉
+关注
关注
161文章
4320浏览量
119968 -
导航
+关注
关注
7文章
517浏览量
42322
原文标题:NeurlPS2021 | 视觉语言导航的课程学习
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

为什么电容在低电压情况下会发热

在不破坏ESP8266的情况下,ADC的最大电压是多少?

如何在不修改起始地址的情况下,运行SCRCFG为0xA且起始地址为0x0的SCR?
如何在不修改起始地址的情况下,运行SCRCFG为0xA且起始地址为0x0的SCR?
无功补偿装置在不投入电容的情况下显示负数
如何在不更换固件的情况下控制cyusb3014在USB 2.0和USB 3.0模式下的读写速度?
使用TC275 CPU看门狗,在不喂狗的情况下只能复位一次,然后再次复位时,就直接死机了是什么情况?
在什么情况下应选择使用环形变压器而不是其他类型的变压器?
weblogic修改数据源需要重启吗
什么是always on buffer?什么情况下需要插always on buffer?





 工商网监
工商网监
评论