 当“大”模型遇上“小”数据
当“大”模型遇上“小”数据
“ 或许自上次N篇ACL事件后,不少人会突然发现我销声匿迹了。的确,我20年论文断供整整一年。这一年我经历了论文从量变到质变的痛苦蜕变过程,而今天这一篇论文就是在这个过程后的第一个我略微满意的工作Child-Tuning,推荐给大家。”
自BERT火了以后,基本上现在所有NLP领域都all in Pre-training & Fine-tuning了吧?但当“大”规模预训练模型遇上“小”规模标注数据时,往往直接Fine-tuning会存在过拟合现象,进一步会影响Fine-tune完后模型的Generalization能力。如何更好地应对这一问题呢?
我们提出的Child-Tuning给出了一种新的解法--在Fine-tuning过程中仅更新预训练模型中部分网络的参数(这部分网络本文就叫做Child Network),这么简单直接的做法却效果奇赞,结果在GLUE上相较标准Fine-tune有0.5~8.6个点的效果提升,但却只需要几行代码的修改,你不想试试吗?目前,该论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》已被EMNLP‘21接收。
01—
当“大”模型遇上“小”数据
自BERT提出以来,预训练模型的参数量从最开始的3亿,逐渐攀升到了GPT-2的15亿,再到火出NLP圈的1750亿参数的GPT-3。一方面模型越来越大,但另一方面,下游任务的标注数据量有些情况下却很少。如果直接将“大”模型在下游“小”数据上进行标准的Fine-tune,将模型迁移到目标任务中去,会导致什么情况呢?
由于这种“大”与“小”的不匹配,往往容易出现过拟合的现象,导致模型在下游任务中的表现差、不稳定、泛化性能差等现象,从而影响我们对于预训练模型的使用[1]。因此,越来越多工作开始聚焦于如何解决这种不匹配现象,缓解大规模预训练模型在下游任务中的过拟合。
本文介绍的Child-Tuning围绕这个问题进行探究,从backward参数更新的角度思考问题,提出一种新的Fine-tuning策略,在Fine-tuning过程中仅更新对应的Child Network,在不同下游任务中相比Vanilla Fine-tuning有明显提高,如基于BERT模型在四个不同数据集中平均带来1.5个点的提升,在ELETRA上甚至提升8.6个点。
02—
Child-Tuning 简单有效的微调算法
在Fine-tuning过程中,我们一方面想利用大规模预训练模型提供的强大知识,另一方面又想解决“海量参数”与“少量标注样本”的不匹配问题,那么能否采用这样的方式来解决问题呢?在forward的时候保持与正常Fine-tune一样,利用整个模型的参数来编码输入样本;在backward更新参数的时候,无需调整海量庞大的参数,而是仅仅其中中的一部分,即网络中的一个Child Network。基于这个想法,本文提出一个新的Fine-tuning的策略——Child-Tuning。Child-Tuning的想法很简单,做法也很简单,概括性地讲可以分为两个步骤:
Step1:在预训练模型中发现确认Child Network,并生成对应的Weights的Gradients 0-1 Mask;
Step2:在后向传播计算完梯度之后,仅仅对Child Network中的参数进行更新,而其他参数保持不变。
在前面提到的Child-Tuning的两个步骤中,Step2即仅对Child Network中的参数进行更新相对简单。我们可以通过一个梯度掩码(Gradients Mask)来实现,即在计算出各个参数位置的梯度之后将其乘以一个0-1矩阵的梯度掩码,属于Child Network中参数的位置对应为1,而不属于的对应为0,之后再进行参数的更新。
那问题的关键就落到了,怎么识别Step1提到的Child Network呢?本文探索了两种算法。一种是与下游任务无关的Child-Tuning_F方法,另一种则是与下游任务相关、能够自适应感知下游任务特点的Child-Tuning_D,这两种方式各有优缺点。
任务无关算法Child-Tuning_F对于下游任务无关算法Child-Tuning_F(F for Task-Free) ,其最大的优点是简单有效,在Fine-tune的过程中,只需要在每一步更新的迭代中,从伯努利分布中采样得到一个Gradients Mask (M_t)即可,相当于在对网络参数更新的时候随机地将一部分梯度丢弃。
尽管方式简单,我们从理论上证明(详细见原论文)这种方法可以有效提高模型更新量的方差,有利于模型逃离局部最优点,最终收敛于一个相对比较平坦的损失曲面上,从而提高模型的泛化能力。任务相关算法Child-Tuning_D然而对于下游任务无关微调算法Child-Tuning_F,也有一个缺点,就是它对于不同的下游任务的策略都是一样的,对于模型中的不同参数也都平等对待。
为此,我们提出了一个任务相关的Child-Tuning_D (D for Task-Driven ),让选取Child Network的策略能够针对不同的下游任务自适应地进行调整,选择出与下游任务最相关最重要的参数来充当Child Network。具体的,我们引入Fisher Information Matrix(FIM)[2] 来估计每个参数对于下游任务的重要性程度,并与前人工作一致近似采用FIM的对角矩阵(即假设参数之间互相独立)来计算各个参数相对下游任务的重要性分数[3],之后选择分数最高的那部分参数作为我们的Child-Network。
尽管Child-Tuning_D拥有感知下游任务特性的能力,但同时计算Fisher Information也降低了方法的效率,我们不可能在每次迭代的时候都重新计算估计一次Child Network。
因此,我们采用的策略是在Fine-tuning一开始的时候识别出Child Network,并在接下来的迭代中都保持不变,也就是整个Fine-tuning过程只有这部分参数会被更新,我们的实验证明了这种近似手段同样可以取得不错的效果(我们曾经尝试过在每个epoch之后重新估计一次,但是效果反而不如自始自终保持一致的这种方式)。
02—
Child-Tuning 实现仅需几行代码
总的来说,(在基于Adam优化器下的)Child-Tuning的伪代码如图4所示,最关键的部分在于红框内的内容,即发现Child Network,以及根据Child Network生成梯度掩模,从而实现仅对Child Network中的参数进行更新。
具体到代码实现层面,就只需要在原来optimizer里加入简单几行代码:
for p in model.parameters(): grad = p.grad.data
## Child-Tuning_F Begin
## reserve_p = 0.2 # the ratio of gradients that are reserved. grad_mask = Bernoulli(grad.new_full(size=grad.size(), fill_value=reserve_p))grad *= grad_mask.sample() / reserve_p
## Child-Tuning_F End ## # the followings are the original code of optimizer 。。..Child-Tuning代码已开源到阿里预训练体系AliceMind,关于实现的更多细节可以参看:https://github.com/alibaba/AliceMind/tree/main/ChildTuning。
03—
实验结果
我们做的实验主要探究了微调后模型的效果和泛化性能(更多有趣实验可以参见论文:https://arxiv.org/pdf/2109.05687.pdf):
下游任务效果
我们选取了BERT-large, XLNet-large,RoBERTa-large和ELECTRA-large四个不同的预训练模型,并在四个GLUE基准集上的任务,即CoLA,RTE,MRPC跟STS-B上进行实验。从下表中可以看到,相比传统微调算法(Vanilla Fine-tuning),使用Child-Tuning的两个不同版本(Task-Free和Task-Driven)都能带来提高,BERT平均提升+1.5,ELETRA平均提升+8.6。
微调后模型的泛化性能
我们通过两种不同的方式来探究模型的泛化能力:域迁移实验(Domain Transfer)和任务迁移实验(Task Transfer),如果模型的泛化能力更好,产生的编码表示更具有泛化性,那么在相应的迁移实验里边将会在目标任务中取得更好的效果。对于域迁移实验(Domain Transfer),我们在一个NLI数据集上Fine-tune模型,之后直接将其在其他不同的NLI数据集上进行测试。
下表展现的是在源数据集MNLI跟SNLI(为模拟少样本情况,均降采样到5k)迁移到其他目标数据集上的结果。可以看到,相比Vanilla Fine-tuning,Child-Tuning在目标数据集上都拥有更好的效果,这说明了使用Child-Tuning能够有效提高模型泛化能力,防止在源数据集上过拟合。
类似地我们还进行了任务迁移实验(Task Transfer),即在一个源任务上进行Fine-tune,之后将预训练模型的参数冻结住,并迁移到另一个目标任务上,仅仅Fine-tune与目标任务相关的最顶层的线性分类器。下图展示了在以MRPC为源任务,迁移到CoLA,STS-B,QNLI和QQP任务上的实验结果,Child-Tuning相比Vanilla Fine-tuning在任务迁移实验上同样具有明显的优势,说明模型通过Child-Tuning的方法有效提高了泛化能力。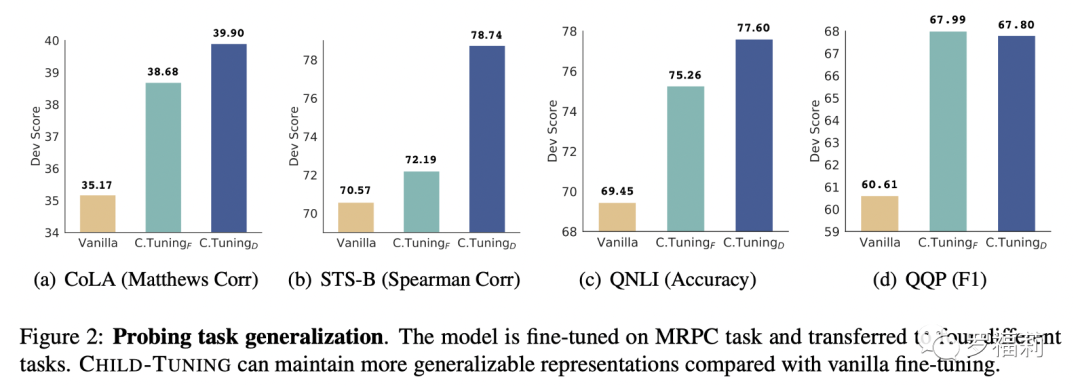
04—
小彩蛋:关于Rebuttal
这篇论文一开始的分数是4/4/3.5,经过rebuttal之后总共提高了1.5分,变成了4.5/4.5/4(满分5分)。Reviewer主要关心的点就是本文与相关工作的区分度,比如Adapter[4],以及DIff-Pruning[5]等工作的对比。其实Child-Tuning跟这些工作还是就是有较大不同的,主要体现在:
a) 动机不同:这些工作主要聚焦于微调尽量少的参数而模型效果不会损失太多(所谓的paramter efficient learning),而Child-Tuning主要关注如何更好的提高模型的效果与泛化性能;
b) 方法不同:Adapter引入了额外的参数模块,Diff-pruning则通过L0范数约束参数更新量,而Child-Tuning不需要额外的新模块,只需要在模型内识别确定Child Network即可;
c) 效果不同:Adapter跟Diff-pruning仅仅取得的效果与原模型相当/可比,而Child-Tuning则明显提升了模型在下游任务中的表现。
点评:分别从“动机-》方法-》结果”这三个方面阐释清楚文章的贡献的这个模板大家可以沿用到reviewer “质疑你文章novelty” 或者 “跟xxx文章很相似” 的评审意见中。From:罗福莉
当我们从这三方面做了非常详细的clarify,充分解答了reviewer的最大疑惑之后,reviewer对我们的评价也就相应地提高了。所以,rebuttal的时候抓住reviewer最关心的(而不是回复全部的问题),才更有可能影响reviewer提分哦~
ps:文章的最后感谢本文共一的实习生 润昕,看到你的飞速成长,比我自己发了论文还开心!期待以及相信你有更好的未来~
责任编辑:haq
-
数据
+关注
关注
8文章
7067浏览量
89108 -
模型
+关注
关注
1文章
3254浏览量
48878 -
代码
+关注
关注
30文章
4791浏览量
68685
原文标题:极简单但贼有效的Fine-tuning算法,几行代码最高涨点8%
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「大模型启示录」阅读体验】营销领域大模型的应用
AI模型部署边缘设备的奇妙之旅:目标检测模型
【「大模型启示录」阅读体验】如何在客服领域应用大模型
使用AI大模型进行数据分析的技巧
当PLC遇上IOT网关可以解决什么问题


LLM模型和LMM模型的区别
当消费遇上AI:大模型如何成为行业“网红”?






 工商网监
工商网监
评论