 黄教主“真身”引爆黑科技,超强GPU、DPU、最快网卡芯片,打造未来“虚拟世界”
黄教主“真身”引爆黑科技,超强GPU、DPU、最快网卡芯片,打造未来“虚拟世界”
电子发烧友网报道(文/李弯弯)11月9日,黄仁勋在NVIDIA GTC上发表主题演讲,发布了一系列新品,包括ReOpt、cuQuantum、cuNumeric,以及Quantum-2平台、Modulus、Omniverse、Maxine、Clara Holoscan等等。
ReOpt
ReOpt,一款针对运筹优化问题(比如车辆路线安排和仓库拣选与包装)的加速求解器,配送14个披萨的路径有870亿种,因此对于达美乐来说,要在30分钟内将披萨送达并非易事,运筹优化对于最后一公里配送来说是必需的,对于仓储及制造物流而言也是如此。
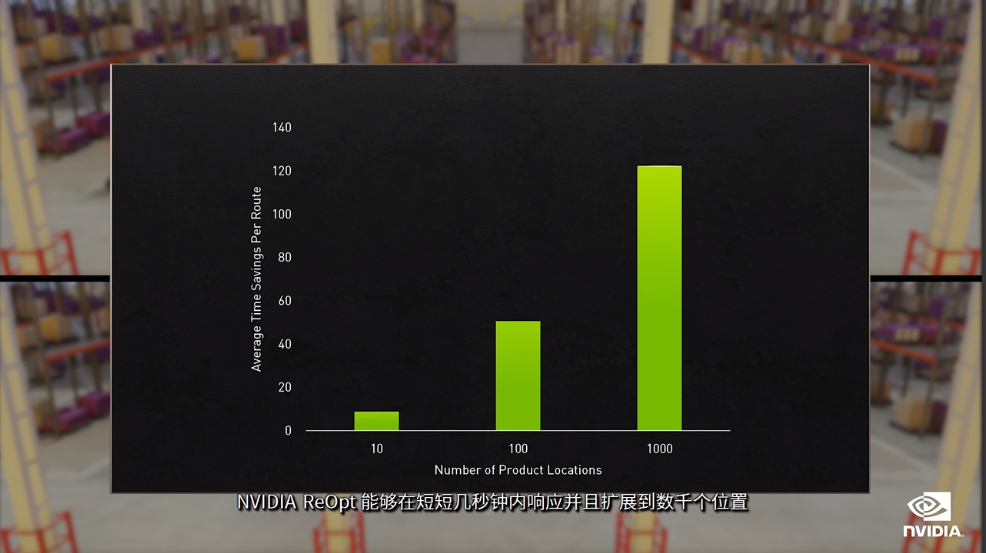
路线规划是一个极其棘手的物流问题,应用到行业里,即使是小规模的路线优化也能节省数十亿美元,示例,使用NVIDIA Omniverse中的虚拟仓库,来展示优化路线在自动订单拣选场景中带来的影响,优化后的规划能够使订单拣选节省一半的时间和路程,当前路线优化求解器在收到新的订单后,需要数小时来重新运行和响应,NVIDIA ReOpt能够持续运行并实时动态地进行重新优化。
cuQuantum
量子计算依靠的是,叠加和纠缠的自然量子物理现象,因此有潜力解决伴随组合复杂性增加而出现的问题,在世界各地的大学、科学实验室、企业和初创公司中,有近100个团队正在致力于量子处理器、系统、模拟器和算法的研究,但预计还需要十到二十年才能制造出一台实用的量子计算机。同时,该行业还需要一个超高速的量子模拟器来验证其研究。
NVIDIA创建了cuQuantum DGX设备,该设备配备有针对量子计算工作流的加速库,可以使用态矢量和张量网络的方法,来加速量子电路模拟。曾经需要耗费几个月时间的模拟现在只需要几天就可以完成,,NVIDIA将在第1季度推出cuQuantum DGX设备。
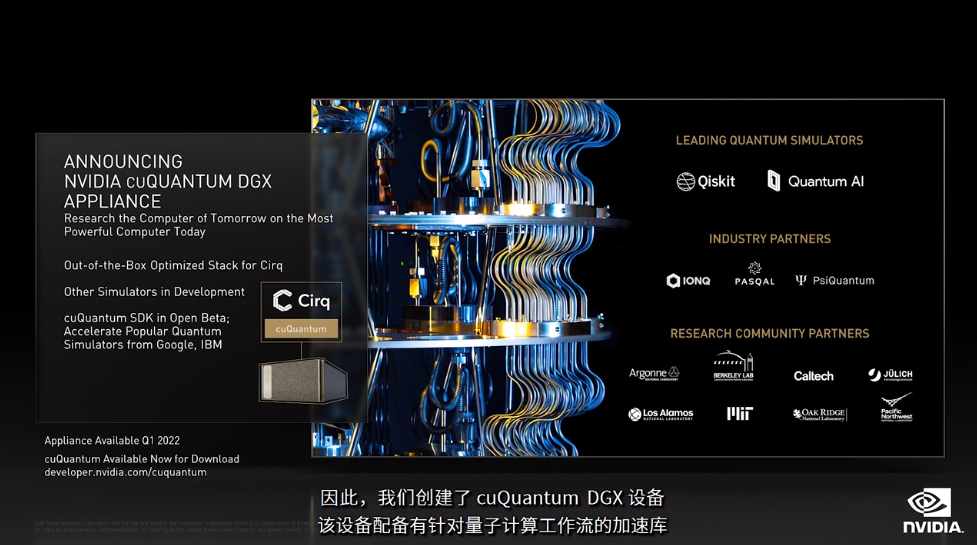
通过DGX上的cuQuantum,量子计算机和算法研究人员可以使用当今速度最快的计算机来发明未来的计算机,NVIDIA将在第1季度推出cuQuantum DGX设备。
cuNumeric
Python是科学家、机器学习与AI研究人员使用的编程语言,Python拥有丰富的库生态系统,包括用于DataFrame进行数据分析的Pandas,用于n维数组与矩阵运算的NumPy,用于机器学习的Scikit-Learn,用于科学计算的SciPy,用于深度学习的PyTorch。Python拥有近2000万名用户。
在会上还宣布推出NumPy的插入式加速库cuNumeric,cuNumeric加速了NumPy从单一GPU扩展到多GPU,扩展到多节点集群,进而扩展到世界上最大的超级计算机,其并行性以隐含的方式自动完成。

cuNumeric具有很好的可扩展性,在著名的CFD Python教学代码中,cuNumeric能够扩展至1000个GPU,而扩展效率仅比线性扩展效率损失了20%。

黄仁勋表示,ReOpt、cuQuantum、cuNumeric,三个极佳的新库。
Quantum-2平台
在分布式计算中,网络是计算机的重要中枢神经系统,网络将数以千计的GPU连接成一个巨型的超级计算机,是其扩展能力和最终性能的决定因素。
Quantum-2是一个400Gbps的InfiniBand平台,由Quantum-2交换机,ConnectX-7网卡、BlueField-3 DPU以及一整套面向这种新架构的软件组成,Quantum-2是首个集超级计算机的性能和云计算的多租户共享能力于一身的网络平台。

黄仁勋表示,在Quantum-2之前,我们只能在裸机的高性能或安全的多租户之间选其一,无法两者兼得,Quantum-2平台的出现,使超级计算机拥有了原生云的能力,并得到更好的优化。如果NVIDIA 的Selene DGX超级计算机,如今也配备Quantum-2,则总带宽将达到每秒224000GB/s,大约是互联网总流量的1.5倍。
Quantum-2平台的InfiniBand交换机芯片,共计570亿个晶体管,采用台积电7nm制程,和NVIDIA的A100 GPU相近,支持64个400Gbps端口或128个200Gbps端口,一个基于Quantum-2的系统可连接多达2048个端口,相较于800个端口的Quantum-1的交换容量多了5倍。

采用Dragonfly拓扑,基于Quantum-2的网络可以仅用3个hop就扩展到100万个节点,这比当前一代增加了6.5倍,这种网络速度、交换容量和可扩展性对于需要构建的巨型HPC系统来说来得正是时候,目前Quantum-2交换机正处于样机阶段。
Quantum-2平台在主机端提供两个选项:ConnectX-7和BlueFied-3。黄仁勋称,ConnectX-7将是速度最快的网卡,包含80亿个晶体管,采用台积电7nm制程,是目前世界上速度最快的网络芯片,比上一代ConnectX-6快两倍。ConnectX-7样品将于明年1月问世。
Quantum-2平台还提供BlueFied-3 InfiniBand系列方案,通过16个64位Arm CPU来卸载和隔离数据中心基础设施栈操作,BlueFied-3采用台积电7nm制程,包含220亿个晶体管,BlueFied-3样品将于明年5月问世。
黄仁勋说:“Quantum-2是迄今为止构建的非常先进的网络平台,将由顶级计算机制造商提供,这将大大推动高性能计算。”
Modulus
NVIDIA Modulus是一种开发Physics-ML模型的框架,它使用物理原理以及源自原理型模型和观测结构的数据训练Physics-ML模型,Modulus已经过优化,可以在多个GPU和多个节点上进行训练,由此生成的模型,其物理仿真的速度比模拟快1000到10万倍。

借助Modulus,科学家能够创建数字孪生模型,以前所未有的方式更好地理解大型系统,Modulus可以用来解决的一个重要问题,即是气候科学。黄仁勋介绍:“我们可以创造地球的数字孪生模型,它可以持续运行以预测未来,用观测到的数据进行校准并改进预测,然后再预测。”
研究人员利用欧洲中期天气预报中心的ERA5大气数据训练Physics-ML模型,该模型在128个A100 GPU上训练需要4个小时,训练后的模型能以30公里的空间分辨率,预测飓风的严重程度和路径,原本需要7天才能完成的预测,如今在一个GPU上只需四分之一秒。
虚拟世界模拟引擎Omniverse
Omniverse面向数据中心规模设计,Omniverse的门户是USD(通用场景描述),本质上是一个数字虫洞,将人和计算机链接到Omniverse,并将一个Omniverse世界链接到另一个世界,公司可以在Omniverse中建立虚拟工厂,并使用虚拟机器人进行运营。虚拟工厂和机器人是其物理复制品的数字孪生。
自去年年底推出以来,Omniverse已被500家公司的设计师下载了70000次,社区、公司和工具供应商与NVIDIA一起构建Omniverse连接器,14个已经投入运行,还有15个即将推出,Bentley宣布带有Omniverse的iTwin现在正处于抢先体验阶段,另外还有宝马和爱立信。
Clara Holoscan
NVIDIA Clara Holoscan,一款软件定义的可编程影响平台,以及全新的高速传感器处理机器人芯片Orin。

基础Holoscan平台由Orin和ConnectX-7组成,Orin可以在单个芯片中处理整个机器人流水线,即传感器、物理、AI、成像和图形,12个Arm CPU,5.2TFLOPS(FP32),用于AI的250TOPS,740Gbps高速IO用于连接传感器,使用者可以选择添加A6000 Ampere GPU获得另外39TFLOPS(FP32)和超过500TOPS的AI推理性能。

Holoscan平台是开放的,第三方可以在Holoscan的界面和API的基础上进行构建,研究人员可以从事重要的新科学研究、仪器制造商可以将Holoscan集成到他们的解决方案中,Holoscan应用程序可以完整部署在设备内、医院的数据中心或者两者结合,这使得公司可以开放比设备本身需要更多算力的应用程序,或者升级部署多年的已安装基础设备。
黄仁勋在演讲的最后表示还有一项公告要发布,“我们将构建一个数字孪生模型来模拟和预测气候变化,上一台超级计算机名为Cambridge 1,即C-1,这台新的超级计算机将名为E-2。Earth Two ,地球的数字孪生,能够在Omniverse中以Million-X百万倍的速度运行,目前发明的所有技术,均是实现Earth Two必不可少的,我想象不出笔者更宏伟、更重要的用途。”
-
NVIDIA
+关注
关注
14文章
4985浏览量
103034 -
gpu
+关注
关注
28文章
4736浏览量
128932 -
AI
+关注
关注
87文章
30851浏览量
269019
发布评论请先 登录
相关推荐
AI智能网卡在AI网络中的作用
全球首颗!中国移动联合产业伙伴发布全调度以太网(GSE)DPU芯片

GPU在虚拟现实中的表现 低功耗GPU的优缺点
GPU与VR技术结合应用
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
rt-thread如何解决添加虚拟网卡?
中科驭数发布高性能DPU芯片K2-Pro
基于芯启源NFP3800DPU芯片的深信服安全加速卡XSX40FNN网卡

一文看懂DPU与CPU、GPU的关系


FPGA-Based DPU网卡的发展和应用





 工商网监
工商网监
评论