 解决算力需求的主流方法?数据流架构让AI芯片利用率提升10倍以上
解决算力需求的主流方法?数据流架构让AI芯片利用率提升10倍以上
电子发烧友网报道(文/李弯弯)现在各种应用场景对算力的需求越来越大,为了满足需求,各厂商不断提升AI芯片的峰值算力,而传统指令集架构的芯片利用率却难以提升,大多数在10-40%,这让芯片的实测性能大打折扣,那么如何突破呢?
与指令集架构不同,数据流架构的显著特点就是依托数据流的流动次序控制计算执行次序,而非指令执行次序,因此把它用在AI上可以让芯片利用率大幅提升,芯片利用率直至逼近100%。
数据流架构如何提升芯片利用率
目前市场上的芯片主要有两种架构形式:一种是大家熟知的指令集架构,主要包括X86架构、ARM架构、精简指令集运算RISC-V开源架构,以及SIMD架构;另外一种就是数据流架构。
指令集架构采用冯诺依曼计算方式,通过指令执行次序控制计算顺序,并通过分离数据搬运与数据计算提供计算通用性。数据流架构采用数据流引擎计算,它允许编译器同时调度多个顺序循环和功能,具有更高的吞吐量和更低的延迟,显著特点是能够大幅提升芯片利用率。
如下图左侧,指令集架构首先执行函数A,完成之后再执行函数B,依次类推直至执行完所有程序。下图右侧,在数据流架构的情形下,编译器可以安排每个函数在数据可用时立即执行,这样可以大大缩短等待和间隔的时间。
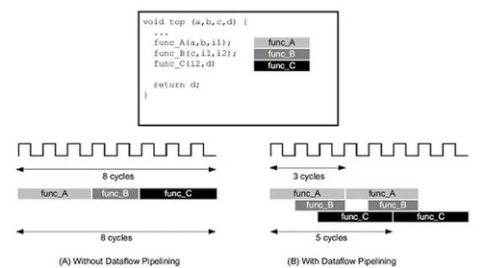
虽然数据流架构没有指令集架构那么广为人知,然而不可忽视的是,目前数据流架构已经在专用硬件中成功应用,比如数字信号处理、网络路由、图形处理、遥感检测、以及数据库处理等,在许多软件体系结构中,包括数据库引擎设计和并行计算框架,它也占据重要地位。
1994年,帝国理工学院教授、英国皇家工程院院士、鲲云科技联合创始人和首席科学家Wayne Luk陆永青院士率先将数据流架构定制化并运用到AI领域。如今国内外对数据流技术的关注日益增多,包括国外的SambaNova、Groq、Wave computing,以及国内的鲲云科技。鲲云科技已经于去年量产了全球首款数据流AI芯片CAISA,脱胎于斯坦福大学的SambaNova,产品处于小规模试用阶段,而前谷歌TPU核心团队创办的Groq,现在还未推出产品。
数据流架构如何提升芯片利用率?我们通过全球唯一量产数据流AI芯片的公司鲲云科技来看一下,鲲云的核心技术就是他们的定制数据流CAISA架构,这是一款为深度学习神经网络定制的高性能AI计算架构。CAISA架构通过数据流流动次序来控制计算顺序,消除指令操作导致的额外时间开销,让CNN网络的算子级数据流图可以实现高效流水线运算。同时CAISA可并行执行数据访问和数据计算,进一步减少计算单元的空闲时间,最大化地利用芯片的计算资源,从而提供更高的实测算力。
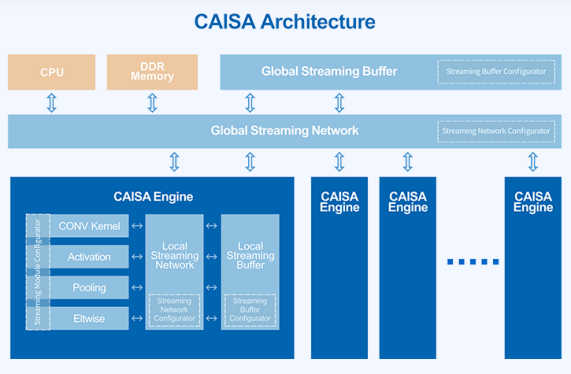
图片来自鲲云科技官网
鲲云科技合伙人、首席运营官王少军博士在接受电子发烧友网采访时表示,之所以投身于定制数据流架构芯片的研发,首先是鲲云科技有数据流架构技术研发基础,公司创始团队来自数据流技术的源头实验室,该实验室是全球三大定制计算实验室之一,从90年代开始就深耕数据流架构与不同领域的领域专用架构研发,具备深厚的研发和迭代积累。
其次更为重要的是底层芯片技术存在算力瓶颈,随着摩尔定律发展,依靠摩尔定律提升芯片性能的成本越来越高,比如一款5nm芯片的研发成本就高达数亿美元,针对特定领域实现领域专用架构的性能获益会越来越高,直到大幅领先通用计算芯片,鲲云科技认为在算力猛增的时代,行业需要一颗高算力性价比的人工智能专用芯片,数据流架构的重大意义在于它突破了传统芯片架构对芯片利用率的约束,最大化发挥芯片本身的峰值性能。
因此鲲云科技在早期数据流架构技术的积累下,针对人工智能领域开发出CAISA架构,并最终实现从0到1完成首颗数据流AI芯片量产。
鲲云CAISA芯片利用率高达95.4%
鲲云科技于去年6月正式量产了全球首款数据流AI芯片CAISA,芯片利用率达到95.4%,面向数据中心和边缘端AI推断应用,该芯片采用28nm工艺,这个制程并不高,不过因为芯片利用率高,即使在比较低的制程情况下,CAISA芯片也可以带来很高的实测性能。

同时鲲云科技还基于CAISA芯片推出三款高性能计算平台,包括面向边缘端的星空X3加速卡、面向数据中心的星空X9加速卡、面向边缘AI应用的星空X6A边缘小站。星空X3加速卡面向8-16路视频实时结构化分析,星空X6A边缘小站面向8路视频处理应用。
目前CAISA芯片及加速卡产品已在多领域实现应用,包括智慧安监、智能制造、智慧电力、智慧城市等。王少军博士认为,对于这些场景,特别是国民生产支柱行业而言,“降本增效”是刚需,比如在油田的应用场景,传统的安防监控系统已经比较成熟,端侧的摄像头监控系统基本部署完成,但视频结构化利用率低,单纯依靠人工巡检,作业区域广,环境复杂,耗时长,数据采集维度单一,人工识别难度大,而且预警不及时,漏报概率高,事后取证难。
针对这些行业痛点,鲲云科技提供算法算力平台一体化方案,基于数据流AI芯片的底层算力优势,以及算力和算法联合优化的技术优势,对现场接入的500路视频进行数据处理,对漏油、安全帽、工服、抽烟、打电话、人员闯入和采油设备运行状态进行识别,可以做到从视频流获取到输出报警时间为1s,为油区的生产情况提供更可靠的安全保障。在油田智能化升级过程中,数据流AI芯片就凸显出了其市场价值,可以充分利旧、快速部署、控制成本。
未来解决算力需求的主流方法
数据流AI芯片的商用落地,证实了数据流和深度学习融合的价值,王少军博士认为数据流架构具备成为下一代计算平台的潜力。他谈到,在计算平台的演进过程中,十倍核心性能指标的提升,是计算架构代际更替的主要指标,比如,从X86到RISC计算平台,能效比提升了10倍以上;从X86到CUDA计算平台,峰值算力也提升了超过10倍。
从历史脉络来看,相对上一代主流算力平台,新的算力平台在某个指标上需要高出10倍,才能实现实测性能的大幅提升,随着摩尔定律的放缓,业界越来越关注下一代芯片应该如何发展,而底层架构创新是这几年业界的共识,行业需要新的技术路线来实现底层算力的突破。
王少军博士认为,下一代有望带来10倍以上突破的指标就是芯片利用率,这可能是未来解决算力需求的主流方法,而数据流架构可以实现这一点,鲲云科技认为未来会有更多新兴AI芯片厂商加入到数据流AI技术路线中。对于现有芯片厂商来说,技术路线的选择是公司的一大核心战略,而其已有的开发生态和技术积累使其很难转换赛道,但有些玩家也看到了数据流技术的价值,比如英伟达就推出了TensorCore,在指令集架构的基础上,该模块采用了数据流技术的原理,来提升其在特定领域的芯片利用效率。
总结
整体来说,数据流架构可以大幅提升芯片利用率,鲲云定制数据流CAISA新芯片的量产商用,也证实了数据流与深度学习融合的价值,给AI带来了一个新的技术研究方向,相信未来会有更多AI芯片厂商加入到数据流架构技术的研究中。
现在AI芯片在很多场景都有落地刚需,尤其在边缘端,很多场景还存在“碎片化”需求,因此厂商除了考虑提升芯片利用率,做到更高算力性价比之外,还需要思考如何提升更通用、软件易用性等,全面提升芯片性能,促进专用AI芯片规模化量产,赋能各产业智能化升级。
-
鲲云科技
+关注
关注
0文章
40浏览量
3853 -
算力
+关注
关注
1文章
1012浏览量
14939
发布评论请先 登录
相关推荐
《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变
理解ECU数据流的分析方法
华纳云:什么是负载均衡?优化资源利用率的策略
交换机内存利用率过高会是什么问题
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
今日看点丨小鹏自研芯片流片!算力是同行三倍;加拿大将对中国电动汽车征收100%关税

QPS提升10倍的sql优化
DC/AC电源模块:提升光伏发电系统的能源利用率

存内计算WTM2101编译工具链 资料
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
恒讯科技全面解析:如何有效降低服务器CPU利用率?
NAND Flash供应商产能利用率提升,今年有望盈利
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型开发效率提升10倍





 工商网监
工商网监
评论