 光子芯片,突破摩尔定律的蹊径?
光子芯片,突破摩尔定律的蹊径?
提到人工智能,最先想到的参数往往是算力。无论是传统的CPU、GPU还是FPGA或ASIC加速卡,都在竭尽所能地想要成为“算力怪兽”,满足机器学习中大规模数据集的处理和云端AI服务在计算上的需求。
然而在目前的AI世界里,硬件都基于传统的数字电子架构,虽然已经有不少厂商在准备跳出冯诺依曼架构的限制,比如开发神经形态加速器等。但它们并没有跳出电子传输速率上的限制,因此不仅处理器主频上仍然受限,要想实现百亿亿级乃至千亿亿级的算力,也只能从增加系统规模上入手。
在这种困境下,从光子学出发的方案正在不断涌现,硅光技术让CMOS制造高集成的光子芯片成为了可能。光子芯片基本都是基于马赫-曾德干涉仪(MZI)制作的,用光信号来进行线性计算,不仅没有复杂的逻辑门,在传输上的能耗也远小于电信号。
不少研究人员都在近年发表了在光学计算的突破,也有少数公司在这个方向发力,打算以全新的架构来跳出这些限制,让AI与神经网络运算更进一步,甚至是打破传统的摩尔定律。
Lightmatter
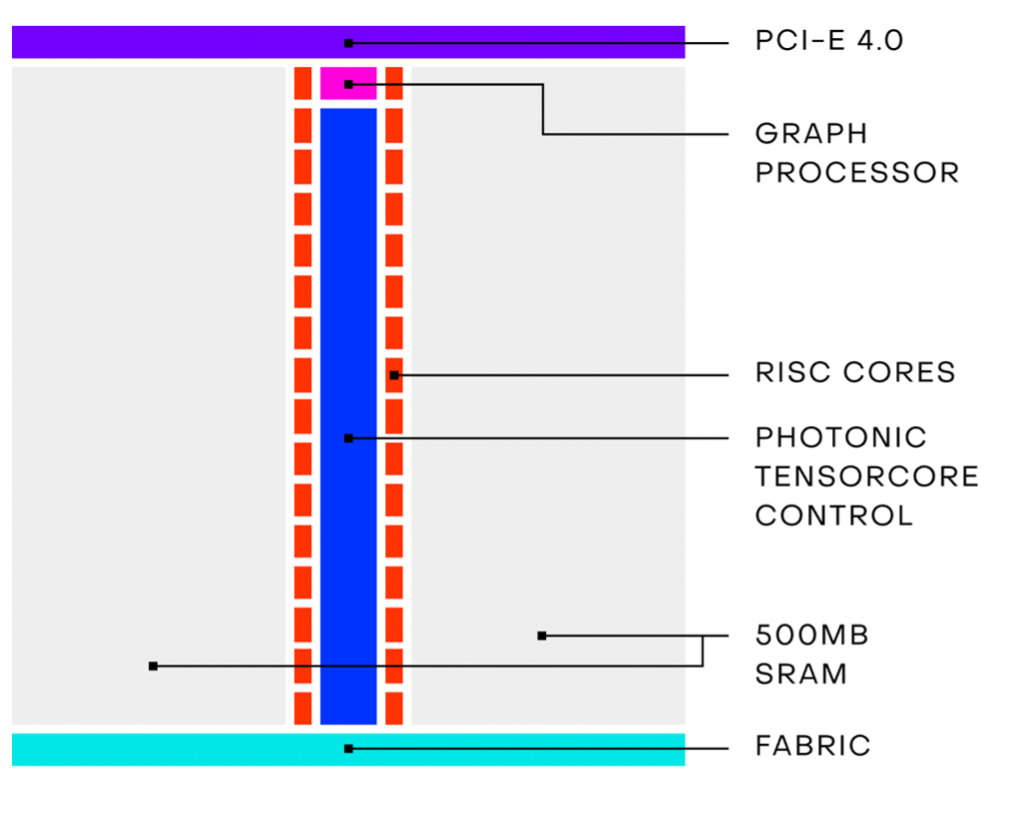
Envise / Lightmatter
专注于AI光子芯片的初创公司Lightmatter在今年推出了Envise,首个通用AI光子加速器,也是去年在Hot chips上发布的Mars原型芯片的改进版。该加速器结合了光电系统,从他们的芯片构造中也可以看出,除了光子核以外,还包含了图形处理器、RISC核心和SRAM。Envise支持INT8、INT16和bfloat16三种数字格式,也支持ReLU、GELU和sigmoid等神经网络中常见的激活函数。
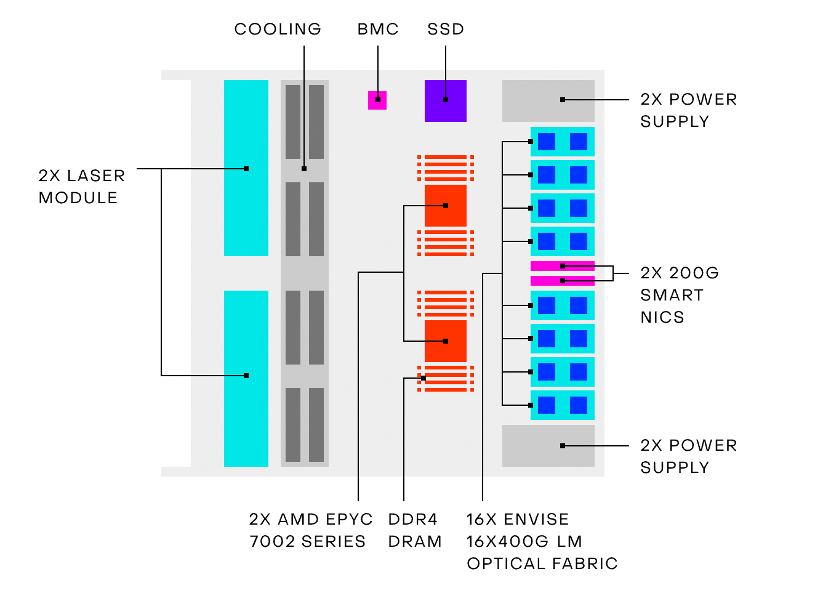
Envise服务器构造 / Lightmatter
据Lightmatter给出的数据,以16个Envise芯片和2个AMD EPYC 7002芯片组成的4-U服务器,仅有3kW的功耗,在Resnet-50模型的测试结果中,推理速度却是英伟达DGX-A100的四倍,而DGX-A100的最高功耗可是有6.5kW。
为了解决扩展性的问题,Lightmatter也在推出了自己的高速互联技术Passage。Passage是一种晶圆级可编程的光子互联技术,让异构芯片以大带宽和高能效互相通信,支持CPU、内存和专用加速器。Lightmatter宣称Passage比现有的芯片互联方案要快上百倍,芯片间最大的传输延迟仅有2ns。
Lightelligence
除了国外的Lightmatter以外,国内也有一家专注于光子芯片的公司Lightelligence(曦智科技)。成立一年后,曦智科技就在2019年正式发布了全球首款光子芯片原型板卡,处理MINIST数据集的准确率达到97%以上。据了解,曦智科技目前主要的技术方案专注于光计算和光传输,以高集成度的光子芯片去辅助现有的数字电子芯片,支持到更快的机器学习运算,数字电子芯片负责简单的逻辑运算,实现高算力的同时做到低功耗。
曦智科技CEO沈亦晨在去年的EmTech China大会上表示,光子芯片技术可以更快实现产业化,因为光子芯片对制程的依赖不强,因此甚至可以用28nm的芯片做到7nm芯片的性能。从这点来看,光子芯片或许也是一个摆脱制程受限的发力方向。根据其官网的消息,曦智科技目前正在与早期客户紧密合作,预计在2022年开始光学AI加速的正式部署。
光子卷积加速器
今年1月,来自澳大利亚的几名研究人员在《自然》杂志上发表了一篇名为《用于光学神经网络的11 TOPS光学卷积加速器》的文章。卷积神经网络(CNN)启发自生物视觉皮层系统,这种神经网络提取了原始数据的层次特征,极大降低了网络参数的复杂度,提高了预测的准确性。CNN已经在计算机视觉、语音识别和医疗诊断中获得了广泛的应用,但仍被电子架构的性能给限制。
这篇文章中的研究人员展示了一个通用的光学向量卷积加速器。该加速器集成了克尔光频梳提供的大量波长通道,实现了11 TOPS的运算速度,也可以同时生成8-bit分辨率25万像素图像的卷积,足以用于人脸图像识别。研究人员还利用相同的硬件,依次组成了一个具有10个输出神经元的深度光学CNN,完成了500张MINIST手写数字图片的识别,准确率达到88%以上。
结语
除了以上提到的几家公司和研究外,市场上还有不少开始攻克光子芯片的公司,比如受到比尔盖茨投资的初创企业Luminous Computing,不过其CEO Marcus Gomez在2019年的一次采访中提到,其产品预计要在2022年至2025年的区间内才会面世。英特尔也在今年公布了两份相关专利,其中之一便是将光子加速器与Xeon核心异构集成。
目前光子芯片依然在走光电结合的方向,光学计算主要是为神经网络等应用起到辅助加速。这是因为受到光学元件的限制,尤其是马MZI的布线特点,要想实现MZI互联的话,就很难兼顾尺寸了,所以全光子的方案在扩展性上还是要差上一筹。且我们平常接触到的多为数字信号,少不了光电转换的过程,因此光子芯片的成功归根结底还是需要光电工程师的共同努力。至于通用计算什么时候能用上光子芯片,仍是一个未知数。
然而在目前的AI世界里,硬件都基于传统的数字电子架构,虽然已经有不少厂商在准备跳出冯诺依曼架构的限制,比如开发神经形态加速器等。但它们并没有跳出电子传输速率上的限制,因此不仅处理器主频上仍然受限,要想实现百亿亿级乃至千亿亿级的算力,也只能从增加系统规模上入手。
在这种困境下,从光子学出发的方案正在不断涌现,硅光技术让CMOS制造高集成的光子芯片成为了可能。光子芯片基本都是基于马赫-曾德干涉仪(MZI)制作的,用光信号来进行线性计算,不仅没有复杂的逻辑门,在传输上的能耗也远小于电信号。
不少研究人员都在近年发表了在光学计算的突破,也有少数公司在这个方向发力,打算以全新的架构来跳出这些限制,让AI与神经网络运算更进一步,甚至是打破传统的摩尔定律。
Lightmatter
Envise / Lightmatter
专注于AI光子芯片的初创公司Lightmatter在今年推出了Envise,首个通用AI光子加速器,也是去年在Hot chips上发布的Mars原型芯片的改进版。该加速器结合了光电系统,从他们的芯片构造中也可以看出,除了光子核以外,还包含了图形处理器、RISC核心和SRAM。Envise支持INT8、INT16和bfloat16三种数字格式,也支持ReLU、GELU和sigmoid等神经网络中常见的激活函数。
Envise服务器构造 / Lightmatter
据Lightmatter给出的数据,以16个Envise芯片和2个AMD EPYC 7002芯片组成的4-U服务器,仅有3kW的功耗,在Resnet-50模型的测试结果中,推理速度却是英伟达DGX-A100的四倍,而DGX-A100的最高功耗可是有6.5kW。
为了解决扩展性的问题,Lightmatter也在推出了自己的高速互联技术Passage。Passage是一种晶圆级可编程的光子互联技术,让异构芯片以大带宽和高能效互相通信,支持CPU、内存和专用加速器。Lightmatter宣称Passage比现有的芯片互联方案要快上百倍,芯片间最大的传输延迟仅有2ns。
Lightelligence
除了国外的Lightmatter以外,国内也有一家专注于光子芯片的公司Lightelligence(曦智科技)。成立一年后,曦智科技就在2019年正式发布了全球首款光子芯片原型板卡,处理MINIST数据集的准确率达到97%以上。据了解,曦智科技目前主要的技术方案专注于光计算和光传输,以高集成度的光子芯片去辅助现有的数字电子芯片,支持到更快的机器学习运算,数字电子芯片负责简单的逻辑运算,实现高算力的同时做到低功耗。
曦智科技CEO沈亦晨在去年的EmTech China大会上表示,光子芯片技术可以更快实现产业化,因为光子芯片对制程的依赖不强,因此甚至可以用28nm的芯片做到7nm芯片的性能。从这点来看,光子芯片或许也是一个摆脱制程受限的发力方向。根据其官网的消息,曦智科技目前正在与早期客户紧密合作,预计在2022年开始光学AI加速的正式部署。
光子卷积加速器
今年1月,来自澳大利亚的几名研究人员在《自然》杂志上发表了一篇名为《用于光学神经网络的11 TOPS光学卷积加速器》的文章。卷积神经网络(CNN)启发自生物视觉皮层系统,这种神经网络提取了原始数据的层次特征,极大降低了网络参数的复杂度,提高了预测的准确性。CNN已经在计算机视觉、语音识别和医疗诊断中获得了广泛的应用,但仍被电子架构的性能给限制。
这篇文章中的研究人员展示了一个通用的光学向量卷积加速器。该加速器集成了克尔光频梳提供的大量波长通道,实现了11 TOPS的运算速度,也可以同时生成8-bit分辨率25万像素图像的卷积,足以用于人脸图像识别。研究人员还利用相同的硬件,依次组成了一个具有10个输出神经元的深度光学CNN,完成了500张MINIST手写数字图片的识别,准确率达到88%以上。
结语
除了以上提到的几家公司和研究外,市场上还有不少开始攻克光子芯片的公司,比如受到比尔盖茨投资的初创企业Luminous Computing,不过其CEO Marcus Gomez在2019年的一次采访中提到,其产品预计要在2022年至2025年的区间内才会面世。英特尔也在今年公布了两份相关专利,其中之一便是将光子加速器与Xeon核心异构集成。
目前光子芯片依然在走光电结合的方向,光学计算主要是为神经网络等应用起到辅助加速。这是因为受到光学元件的限制,尤其是马MZI的布线特点,要想实现MZI互联的话,就很难兼顾尺寸了,所以全光子的方案在扩展性上还是要差上一筹。且我们平常接触到的多为数字信号,少不了光电转换的过程,因此光子芯片的成功归根结底还是需要光电工程师的共同努力。至于通用计算什么时候能用上光子芯片,仍是一个未知数。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
芯片
+关注
关注
454文章
50689浏览量
423014 -
摩尔定律
+关注
关注
4文章
634浏览量
78982 -
光子芯片
+关注
关注
3文章
98浏览量
24415
发布评论请先 登录
相关推荐
击碎摩尔定律!英伟达和AMD将一年一款新品,均提及HBM和先进封装
电子发烧友网报道(文/吴子鹏)摩尔定律是由英特尔创始人之一戈登·摩尔提出的经验规律,描述了集成电路上的晶体管数量和性能随时间的增长趋势。根据摩尔定律,集成电路上可容纳的晶体管数目约每隔18个月便会

后摩尔定律时代,提升集成芯片系统化能力的有效途径有哪些?
电子发烧友网报道(文/吴子鹏)当前,终端市场需求呈现多元化、智能化的发展趋势,芯片制造则已经进入后摩尔定律时代,这就导致先进的工艺制程虽仍然是芯片性能提升的重要手段,但效果已经不如从前,先进封装

高算力AI芯片主张“超越摩尔”,Chiplet与先进封装技术迎百家争鸣时代
越来越差。在这种情况下,超越摩尔逐渐成为打造高算力芯片的主流技术。 超越摩尔是后摩尔定律时代三大技术路线之一,强调利用层堆叠和高速接口技术将处理、模拟/射频、光电、能源、传感等功能

“自我实现的预言”摩尔定律,如何继续引领创新
未来的自己制定了一个远大但切实可行的目标一样, 摩尔定律是半导体行业的自我实现 。虽然被誉为技术创新的“黄金法则”,但一些事情尚未广为人知……. 1. 戈登·摩尔完善过摩尔定律的定义 在1965年的文章中,戈登·
封装技术会成为摩尔定律的未来吗?
,性能也随之增强。这不仅是一条观察法则,更像是一道命令,催促着整个行业向着更小、更快、更便宜的方向发展。01但这些年来,摩尔定律好像遇到了壁垒。我们的芯片已经小得难

AMD硅芯片设计中112G PAM4串扰优化分析
在当前高速设计中,主流的还是PAM4的设计,包括当前的56G,112G以及接下来的224G依然还是这样。突破摩尔定律2.5D和3D芯片的设计又给高密度高速率芯片设计带来了空间。
发表于 03-11 14:39
•1038次阅读
功能密度定律是否能替代摩尔定律?摩尔定律和功能密度定律比较
众所周知,随着IC工艺的特征尺寸向5nm、3nm迈进,摩尔定律已经要走到尽头了,那么,有什么定律能接替摩尔定律呢?
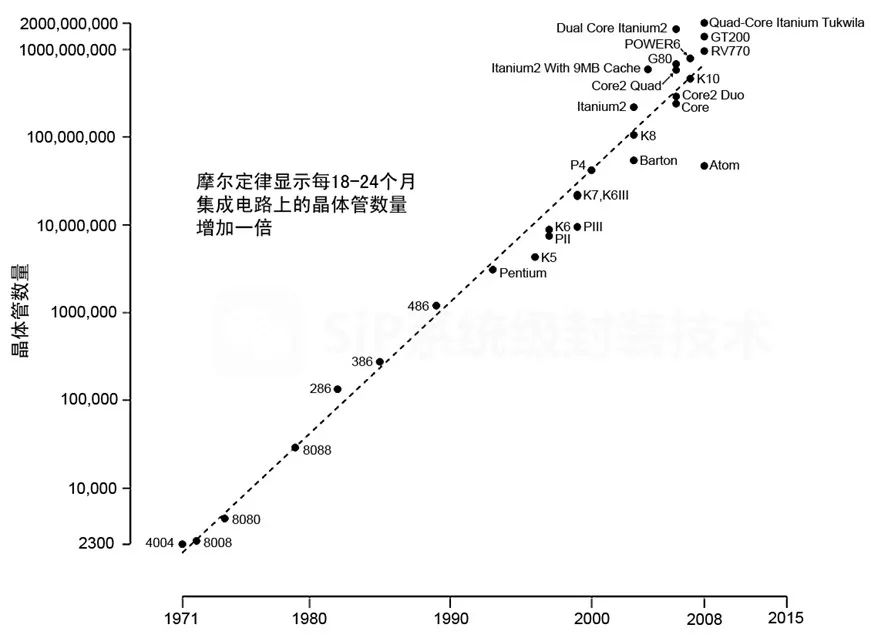
摩尔定律的终结:芯片产业的下一个胜者法则是什么?
在动态的半导体技术领域,围绕摩尔定律的持续讨论经历了显着的演变,其中最突出的是 MonolithIC 3D 首席执行官Zvi Or-Bach于2014 年的主张。

中国团队公开“Big Chip”架构能终结摩尔定律?
摩尔定律的终结——真正的摩尔定律,即晶体管随着工艺的每次缩小而变得更便宜、更快——正在让芯片制造商疯狂。
先进封装技术引领芯片制造新趋势
英特尔创始人戈登·摩尔提出集成电路上的晶体管数量大约每两年增涨1倍的“摩尔定律”后,芯片制造业迅猛发展,然而,缩小芯片体积难度加大,成本提升。
英特尔CEO基辛格:摩尔定律放缓,仍能制造万亿晶体
帕特·基辛格进一步预测,尽管摩尔定律显著放缓,到2030年英特尔依然可以生产出包含1万亿个晶体管的芯片。这将主要依靠新 RibbonFET晶体管、PowerVIA电源传输、下一代工艺节点以及3D芯片堆叠等技术实现。目前单个封装的
英特尔CEO基辛格:摩尔定律仍具生命力,且仍在推动创新
摩尔定律概念最早由英特尔联合创始人戈登·摩尔在1970年提出,明确指出芯片晶体管数量每两年翻一番。得益于新节点密度提升及大规模生产芯片的能力。
后摩尔定律时代,Chiplet落地进展和重点企业布局
电子发烧友网报道(文/吴子鹏)几年前,全球半导体产业的重心还是如何延续摩尔定律,在材料和设备端进行了大量的创新。然而,受限于工艺、制程和材料的瓶颈,当前摩尔定律发展出现疲态,产业的重点开始逐步转移到





 工商网监
工商网监
评论