 华为云Stack发布用于虚拟网络监控的主动链路监控系统
华为云Stack发布用于虚拟网络监控的主动链路监控系统
背景
在云数据中心环境下,IAAS云网络是数据中心所有业务的通信基础;云网络的稳定保障,需要全面、高性能、实时的监控能力,能够覆盖所有转发网元、路径和业务,这套能力一定是多手段的、多维度的和多层次的,目前还没有一种监控方案或工具能满足所有的监控诉求,我们在一些实际案例中发现由于缺失网元/云服务的某些监控指标,无法及时发现一些业务故障。
案例1:某客户进行新版本的云平台网络组件升级,升级后各组件的指标监控以及其他监控测试方法没有发现异常,但是由于升级导致EndPoint转发网元的某个组件异常,小概率场景使用到这个网元的时候会导致流量中断,当前监控体系没有做到能力覆盖,导致当客户的实际业务使用时发生业务故障,而阻塞业务超过1个小时。
案例2:某项目物理网络进行了变更,物理网络变更引入一个路由拒收问题,从物理网络的监控没有发现问题,但是实际影响了业务流量,导致业务故障长达2小时。
案例3:某项目站点某租户突发流量导致网关转发性能到达瓶颈,影响其他租户的时延高达20ms,网络监控无法及时发现此时延问题,直到其他租户业务报障。
上面的案例都有一个共同特点:单个网元和交换机的指标正常,但是综合用到这些网元和交换机的网络服务有问题,华为云Stack不断致力于在网络监控上增加监控指标,不断补充监控手段,我们发布了用于虚拟网络监控的主动链路监控系统,通过点-》线-》面的逻辑构建整个网络服务监控系统。
“点”:包括物理网元和软件网元,主要监控单个网元的CPU、内存、收发报文、错包处理/丢包、转发相关的表项、规格和资源占用情况等。“点”的监控能够监控当前网元的KPI是否正常,是否具备符合预期的业务能力。
“线”:包括监控物理链路,虚拟链路和租户业务流。
1)物理链路监控:是指从一个计算节点到另外一个计算节点的物理转发路径的KPI是否正常,或者从一个物理交换机到另外一个物理交换机的路径KPI是否符合预期。
2)虚拟链路监控:是从云服务的维度,检测某个网络服务的服务通道是否正常,云网络下的网络服务链路是物理网元和软件网元配合完成的一个整体链路。
3)租户业务流监控:将物理链路和虚拟链路比作道路,那么租户业务流可以认为是这条路上跑的汽车。物理链路和虚拟链路的监控可以保证大部分的汽车运行正常,不会有大规模的阻塞问题,但是并不代表某辆汽车的运行一定是正常的。租户业务流监控是在物理物理监控和虚拟物理监控的基础上补充对某个业务实例的监控。
“面”:是从云服务的维度对网络监控进行统一的整理和展示,一个标准网络服务的组件包括管理面组件,数据面组件和租户实例。以华为云Stack为例,其支持的云服务数量众多,网络服务就有10多种,每种网络服务有不同的组件,为了帮助运维管理员管理好这些服务,按照云服务的角度,把资源、拓扑、告警、性能、规格、日志、配置、拨测等进行统一整理和分类,做到一站式监控整个云服务的运维能力。
表1 网络监控对比

虚拟链路监控杀手锏:主动链路监控
云网络大部分都是软件化部署,仅仅监控物理网络的质量是不够的,更重要的是监控虚拟网络端到端的质量,比如VPC服务网络质量(从ECS到ECS),VPC-Peer服务网络质量(ECS-vRouter-ECS),ELB服务网络质量(client-LVS-member)等,虚拟网络链路是云网络的本质转发路径,云网络下的虚拟网络监控对于网络转发,应用质量保障非常重要。
华为云Stack面向政企市场,为了监控虚拟链路质量,提供了智能化的主动链路监控系统,客户不需要理解复杂的云网络/的内部原理,只需要傻瓜式的启动这个系统,主动链路监控系统能够根据项目业务场景和客户组网,自动计算需要监控的虚拟网络对象,主动规划学习监控路径,自动上报网络监控指标和告警网络故障。
通过主动链路监控,可以及时发现前面案例中的各种故障,故障发现时间从不确定走向确定,故障定界定位时间从小时级变成分钟级。
一、黄金指标:丢包率和时延
网络监控的指标很多,但是最能代表网络质量的是丢包率和时延两个指标。丢包率和时延是网络转发能力和业务质量体验的最直接指标,丢包会导致报文重传,会引起网络震荡,对业务的影响表现为业务不平稳,有抖动。时延高会导致网络传输慢,导致页面卡顿、应用反应迟缓。丢包率和时延的检测需要通过主动或者被动的方式来动态测量,不能通过直接查询或者采集交换机或者服务器的某个指标获取,相关的网络测量技术有很多,在此不做过多赘述。为了获取到设备级、Fabric级、整个DC和跨DC的时延和丢包率指标,各个厂家都设计了自己的工具系统,比如微软的Pingmesh,Facebook的NETNORAD,百度的NetRadar,阿里的vTrace等,都是为了监控整个数据中心网络质量的系统方案,其中最重要的输出指标就是丢包率和时延。
二、链路检测根技术
黑盒检测方法是计算时延和丢包率最常用,最简单的方法。传统的黑盒拨测通常只关注最后拨测的结果通或者不通,如图1所示,通过发送ICMP request和TCP SYN,关注 ICMP replay和TCP ACK报文是否有回应,发送和接受报文间RTT时延,由此计算整条探测路径的丢包率和时延。如果中间某个交换机或者网元有了故障,并且网元已经自我隔离了,对外的服务质量并没有中断,这种情况下通过普通的黑盒探测是无法探测的。基于染色报文的拨测常用于出现问题后对问题进行复现时候的故障定界定位,如图2所示,在每个网元,包括物理网元和软件网元,都具备对染色报文进行镜像和统计的能力,可以精确定位每个监测点接收和发送的报文数,以及每个点的时延信息,是一种高精度的黑盒检测方法。基于染色的拨测方法,我们主动链路监控进行主动配置探针,主动编排策略,达到覆盖所有网元节点的探测目的,可以监控网络服务经过所有网元的服务可用性,同时得到全量网元的时延和丢包率指标。主动链路监控以染色报文的拨测作为测量方法,可以做到比传统黑盒监控更精细化的监控效果,不仅监控云服务的质量,更能覆盖的所有网元的转发质量,更大化的保障租户业务流质量。
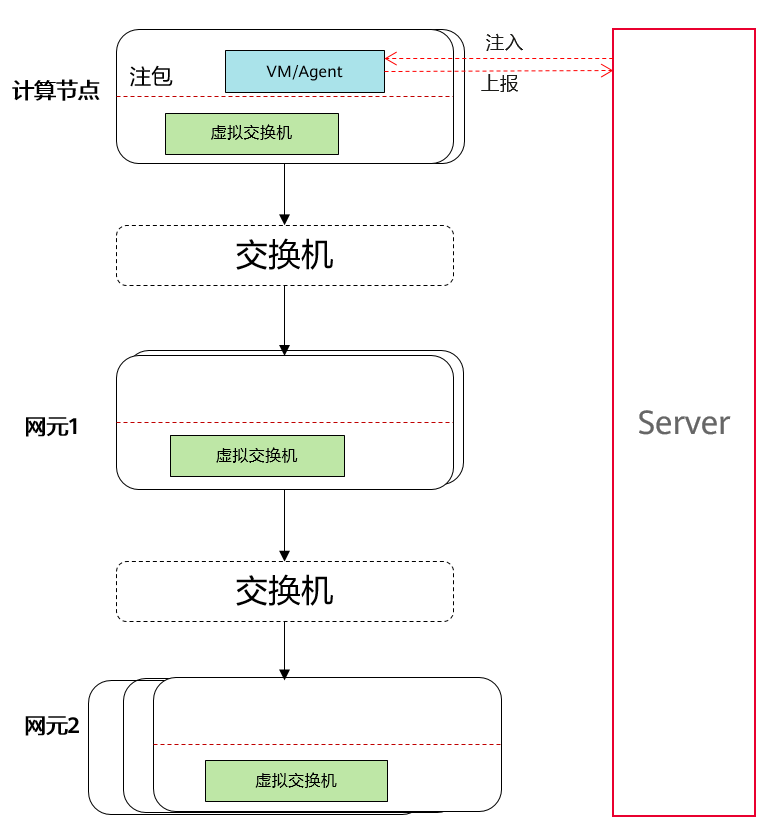
图1 传统黑盒拨测
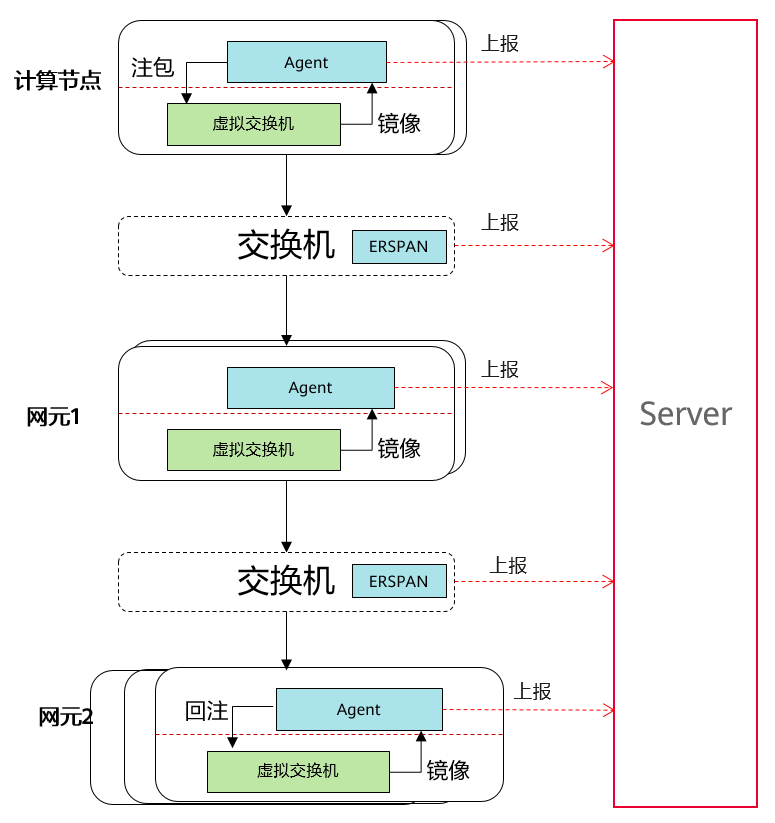
图2 基于染色报文的拨测
三、系统架构
主动链路监控整体系统架构如图3所示,主要包括Server端和Agent端。Server端用于根据云服务维度和监控场景生成策略列表和创建拨测任务,agent端用于报文注入和镜像报文收集。
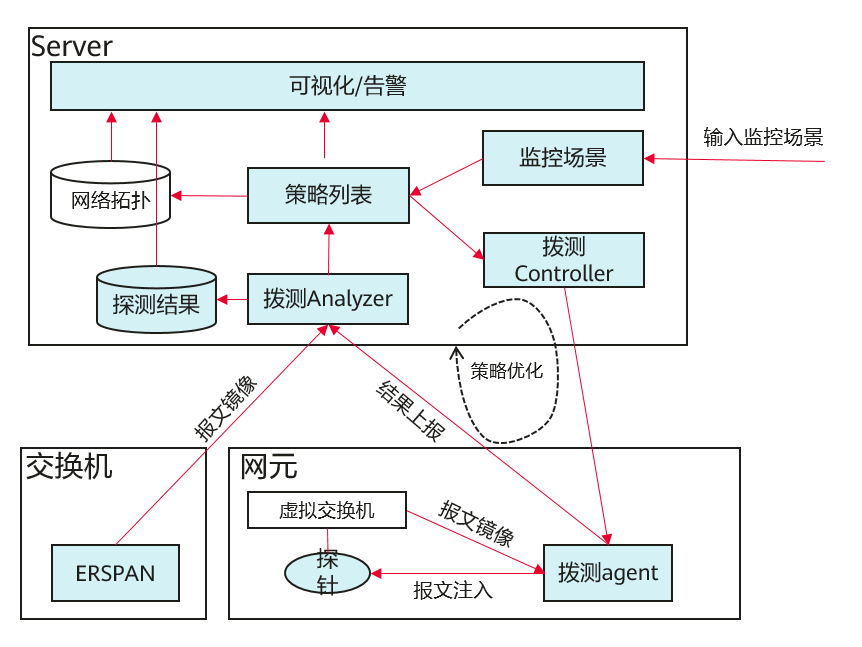
图3 主动链路监控系统架构
监控场景:包括日常监控场景和升级监控场景,日常监控是一个持续监控的过程,主要侧重于监控面广,持续迭代和优化;升级监控,侧重于快速给出某个网络服务的监控结果,需要针对某个网络服务进行快速迭代和升级前后对比。
网络拓扑:数据中心的网络拓扑,包括所有的交换机和所有的计算节点,软件网元的网口连接信息。
策略列表:包含所有要探测的链路的集合,一个策略对象是一个五元组信息,包括源探针IP,目的探针IP,协议,源端口和目的端口。
拨测Controller:按照策略列表下发拨测任务。
拨测Analyzer:收集拨测结果,并根据拨测结果对策略进行正向反馈优化,策略优化后可以覆盖更全的链路。
拨测Agent:对探针注入染色报文,并收集OVS的镜像报文。在所有的计算节点和网元节点部署。
ERSPAN:物理交换机通过ERSPAN的方式,把染色的拨测报文镜像到Analyzer,供Analyzer进行虚拟网络和物理网络的统一路径检测和分析。
四、关键技术
亮点1:策略优化
按照用户输入的监控场景和云服务列表,Server会生成一个默认的策略列表,但是每个客户现网的情况都不尽相同,初始创建的策略难点在于如何覆盖所有的网元,比如下面的图4,网元1_3和网元2_3并没有被探测到,达不到链路覆盖的效果。我们基于染色报文的拨测方法,提出策略优化的方案,Analyzer得到拨测结果后会进行分析,不断的迭代策略的五元组信息,按照不断的反馈和补偿,可以达到一条策略能够覆盖所有网元的目的,如图5所示。策略从图4的结果到图5的结果就是一个策略优化的过程。策略优化还有另外一种结果,那就是尝试了所有的可能后,始终无法覆盖到某个网元,比如图6中的网元1_3,出现这种情况我们有理由怀疑,网元1_3业务出现某种问题后触发了自身的自动隔离,这种情况不影响这个网络服务整体对外的可用性,只是性能或者服务等级下降,主动链路监控一样可以发现网络服务的亚健康问题。因此主动链路监控的策略优化机制,监控的不仅包括云服务的可用性,而且包括网元的可用性,监控粒度和精度比传统的黑盒监控要高很多。
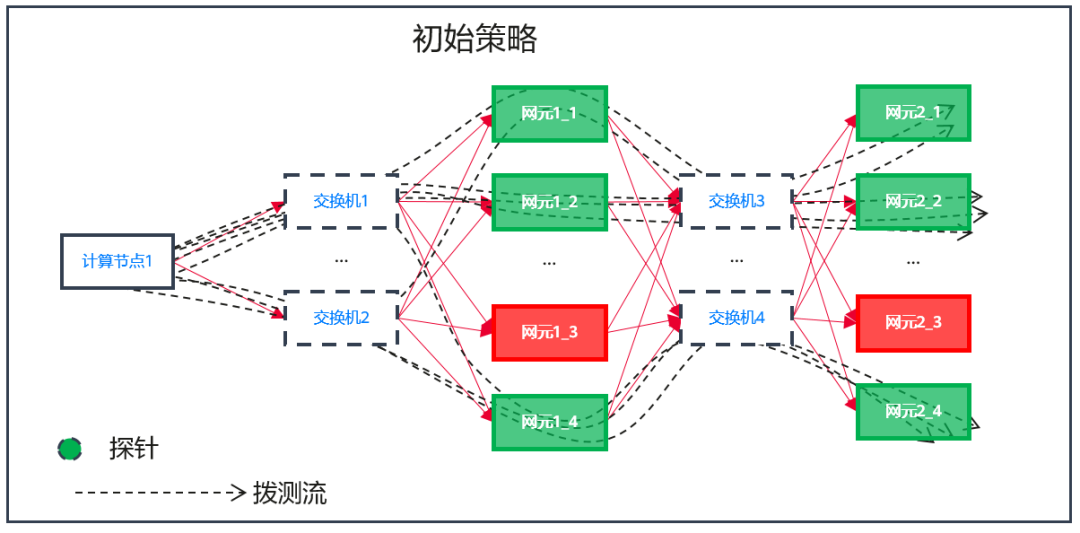
图4 初始策略
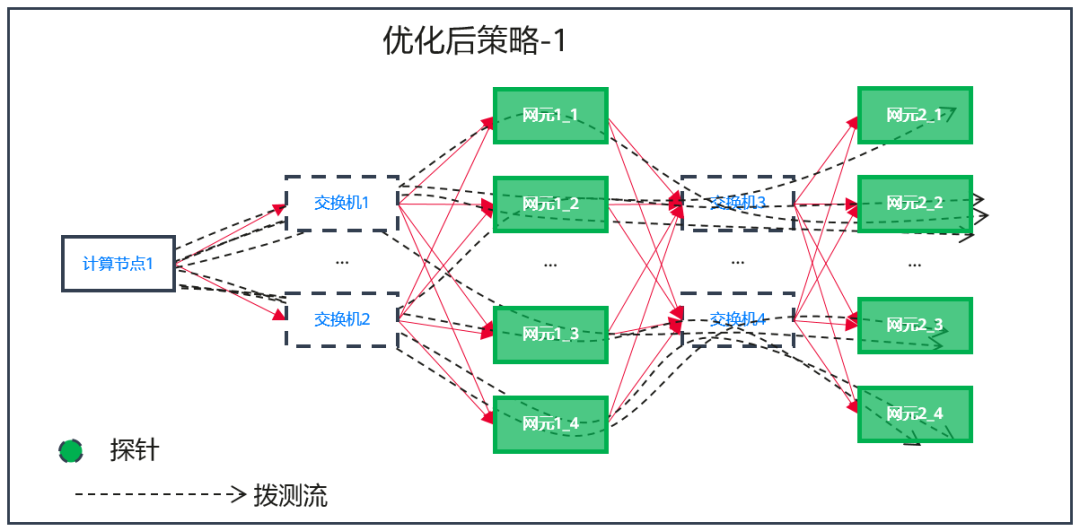
图5 优化后策略-1
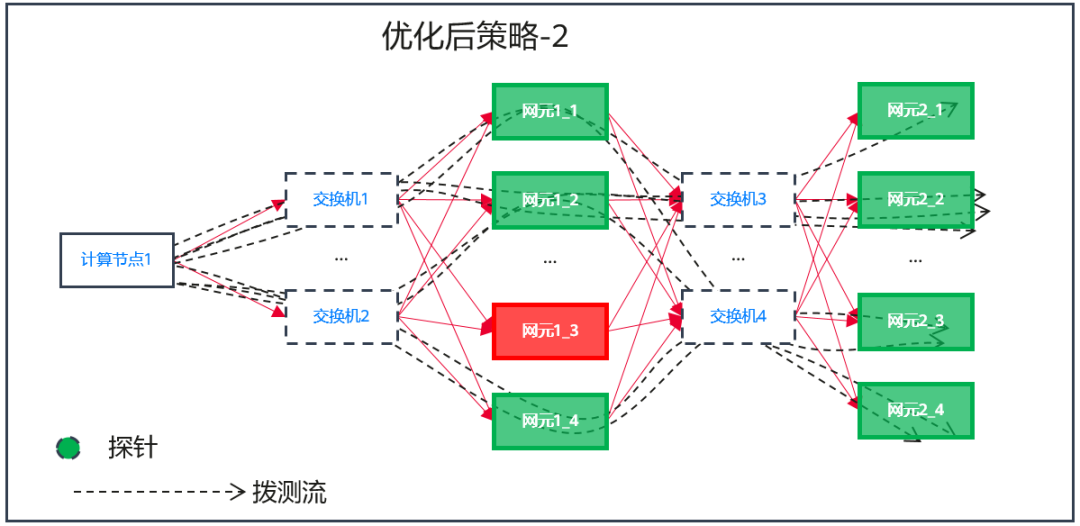
图6 优化后策略-2
亮点2:告警汇聚
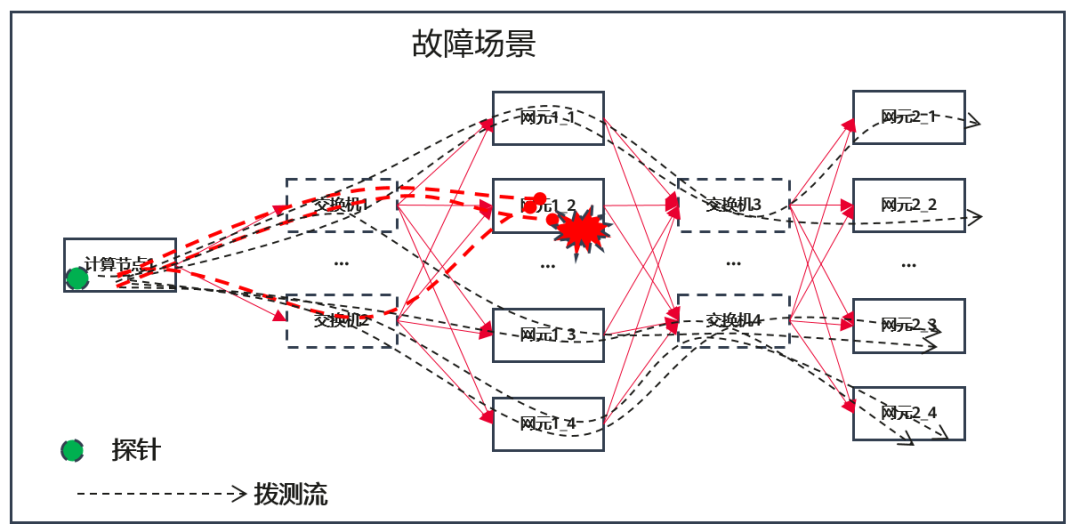
图7 故障场景在网元故障场景下,某个网元出现故障,由于网元是被所有节点和所有租户共同使用的,大量的主动链路监控拨测任务会定位到此网元,如何不做任何过滤直接上报,Server会产生大量的告警,这些告警的问题溯源是重复的,告警处理效率低。告警汇聚的过程,会把所有的故障点信息进行汇总分析,汇聚成统一故障点之后再上报,避免了大量重复告警上送,运维管理员根据上报的汇聚告警快速定界到故障点,得到故障的影响范围。
亮点3:可视化指标
为了展示测量数据和异常检测结果,主动链路监控设计可视化指标,包括两部分,虚拟链路的时延、丢包率指标和网元的时延、丢包率指标。虚拟链路是包含多个路径的,比如VPC的服务,包括的是计算节点的虚拟交换机到其他计算节点的虚拟机交换机的路径。图8中的每个原点表示某个计算节点的探针,两个网点之间的线表示两个探针之间的路径,这个路径是包括两边的OVS和中间的物理交换机,同时通过策略优化,每个网卡和每个物理交换机也会被覆盖到。线是绿色表示指标正常,如果指标异常,图8中的连线会红色展示。点击其中的某条路径,可以查看这个路径的丢包率和时延指标,可以查看最近30分钟,近一小时,近一天以及最长最近一个月的指标。
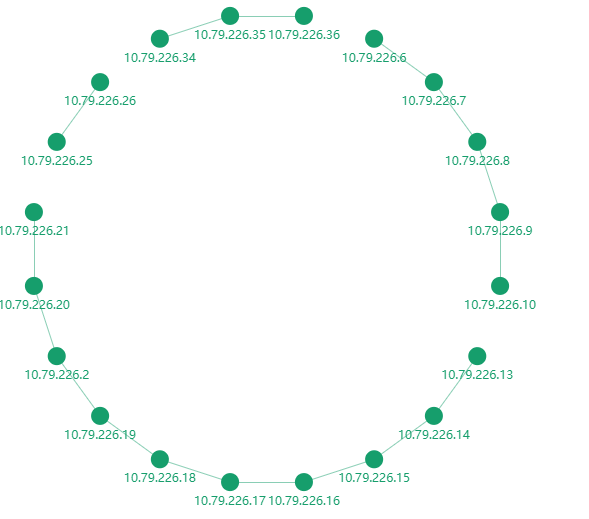
图8 VPC服务链路质量展示
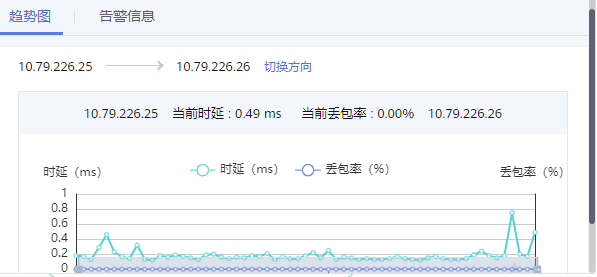
图9 路径指标展示图10和图11展示的是网元的丢包率和时延指标,如果一种网元类型有多个,会分别展示每个的时延和丢包率指标。
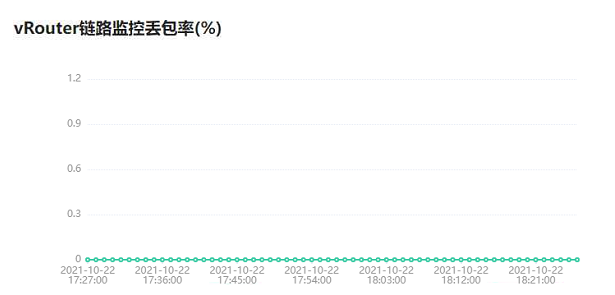
图10 网元丢包率
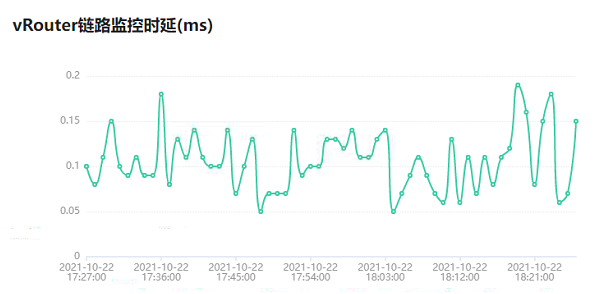
图11 网元时延
最后
主动链路监控基于染色报文的探测方案,改善了传统黑盒监控,只能监控网络服务SLA,没法监控网元级服务SLA的弊端,采取主动探测和策略优化的方法,做到尽可能覆盖每个服务和每条路径,最大可能的探测到客户实际业务流的每条路径,尽早的发现网络质量问题,切实保障客户业务质量。
原文标题:【大架光临】云网络的守护神,主动链路监控
文章出处:【微信公众号:华为开发者社区】欢迎添加关注!文章转载请注明出处。
责任编辑:pj
-
网络监控
+关注
关注
0文章
110浏览量
21762 -
云数据中心
+关注
关注
0文章
21浏览量
4663
原文标题:【大架光临】云网络的守护神,主动链路监控
文章出处:【微信号:Huawei_Developer,微信公众号:华为开发者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论